
Attention
- Sequence-to-Sequence with RNNs
1.1) 문제점 및 해결방안 - Sequence-to-Sequence with RNNs and "Attention"
2.1) 설명
2.2) 예시
2.3) 정리 - Image Captioning with RNNs and Attention
3.1) 설명
3.2) 예시 - Attention Layer
4.1) 설명
4.2) Similarity function
4.3) Multiple Query vectors (이해 잘 안됐음..)
4.4) Separate Input vectors into key and value
4.5) 요약 - Self-Attention Layer
5.1) 설명
5.2) Input의 순서를 바꾼다면? - Masked Self-Attention Layer
- Multihead Self-Attention Layer
- Example: CNN with Self-Attention
- Three Ways of Processing Sequences
- Transformer
10.1) 설명
10.2) Transfer Learning
Summary
1. Sequence-to-Sequence with RNNs
자난 강의 RNN에서 다루었던 Seq-to-Seq에 대해 자세히 다룬다.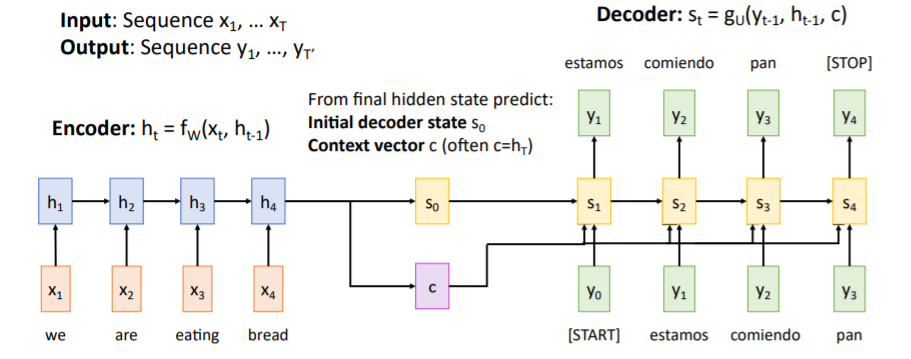 먼저 첫
먼저 첫 Encoder에서는 input sequence를 입력받아 를 업데이트하고, 최종적으로 계산한 를 사용하여 Decoder의 initial hidden state 와 Context vector 를 만든다.
Context vector
input sequence를 요약한 것으로
Decoder의 매 step마다 넣어준다. Encoded sequence와 Decoded sequence 사이에서 정보전달의 역할을 한다.
Ddecoder에서는 와 input token인 [START]를 가지고 을 계산한다.
그 다음부터는 과 이전 step의 output, 그리고 context vector 를 받아 를 계산하기를 반복하고 [STOP] token을 출력할때까지 반복한다.
1.1) 문제점 및 해결방안
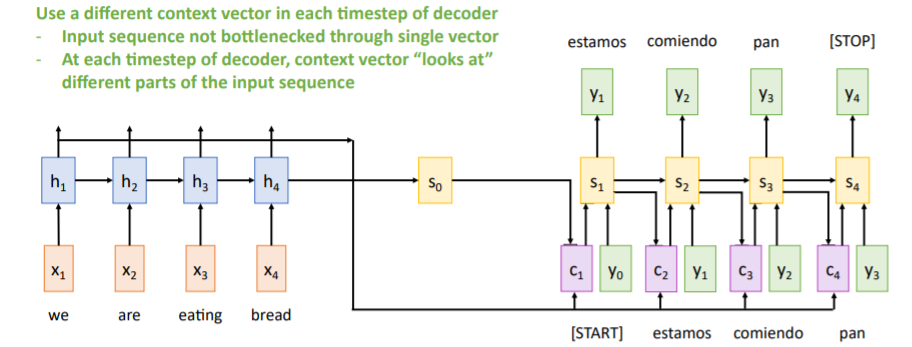
그러나 만약 Sequence가 1000 길이만큼 또는 책 한권일만큼 길어진다면 문제가 발생한다. 이렇게 긴 sequence를 그저 하나의 Single Context vector 로 요약하기에는 부족하다. 즉, 정보손실이 발생한다. 강의에서는 Input sequence bottlenecked through fixed-sized vector. What if T=1000?이라고 문제점을 소개하고 있다.
해결방안
use new context vector at each step of decoder!
Single Context vector을 사용하지 않고 매 step마다 새로운 context vector을 사용하거나 생성한다.
2. Sequence-to-Sequence with RNNs and "Attention"
2.1) 설명
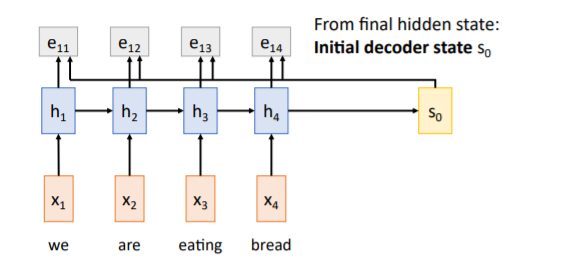
Encoder부분은 기존과 비슷하지만, alignment score이라는 개념을 도입하였다.
(scalar) alignment score
fully connected network로, decoder의 현재 시점에서 encoder의 어떤 시점에 집중해야하는지에 대한 score이다.
위 예시에서는 initial state 와 encoder의 각 hidden state를 대응하여 decoder에서 hidden state 에 대한 output을 생성할 때 encoder의 어떤 hidden state가 중요한 역할을 하는지에 대한 점수를 계산한다.
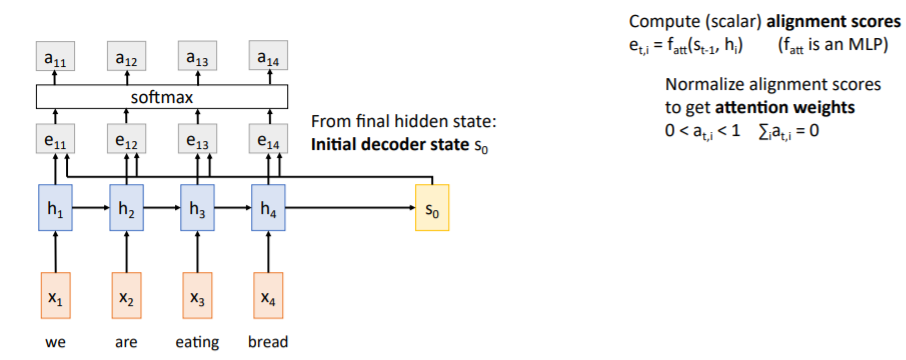 그리고 alignment scores를 softmax함수에 통과시며 확률분포로 만든다. 이렇게 생성된 값들 는 각각 0 ~ 1 값을 가지며 모두 더하면 1이 된다. 이들을
그리고 alignment scores를 softmax함수에 통과시며 확률분포로 만든다. 이렇게 생성된 값들 는 각각 0 ~ 1 값을 가지며 모두 더하면 1이 된다. 이들을 attention weights라고 하고 encoder의 각 hidden state를 얼마나 반영할지에 대한 weights로 작용한다.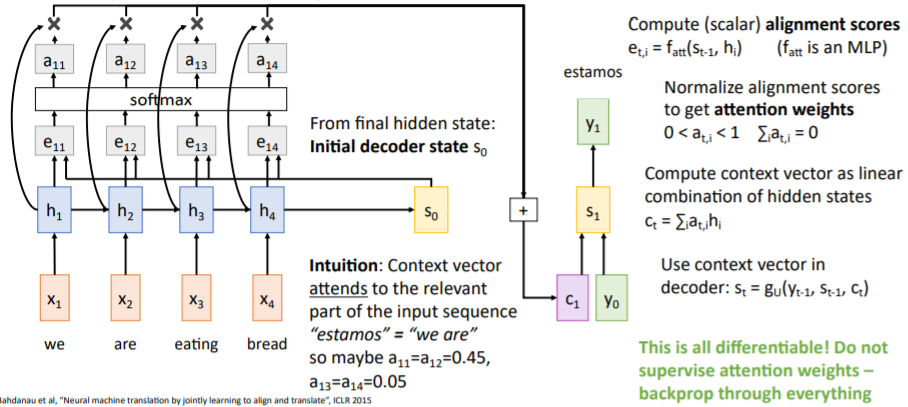 그리고
그리고 Attention weights와 hidden states를 weighted sum하여 시점의 new context vector 를 계산한다.
이는 미분가능하기 때문에 네트워크가 스스로 어떤 부분에 집중해야하는지 학습할 수 있다. 어떤 부분에 집중해야하는지 supervise할 필요가 없다.
이후 과정은 아래 그림들과 같다.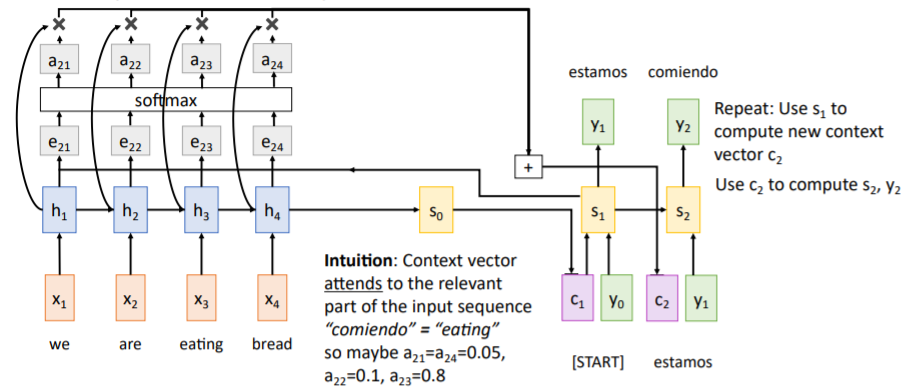
2.2) 예시
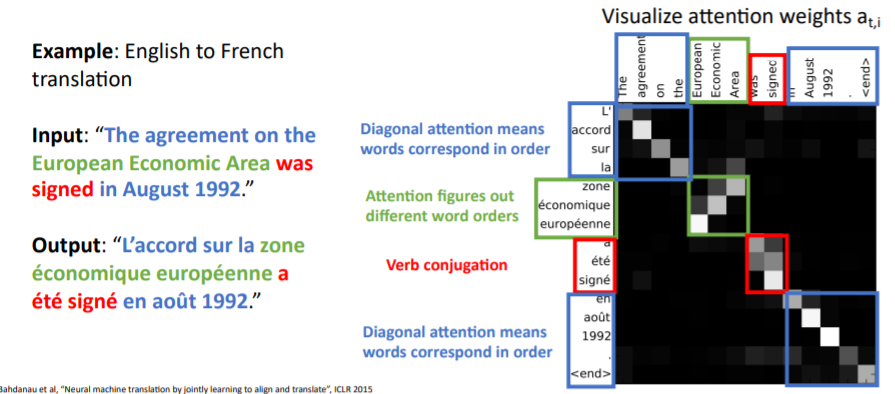 영어 프랑스어 번역 시 attention weights를 나타낸 것이다. 각 시점별로 어떤 state에 집중하고 있는지 볼 수 있다.
영어 프랑스어 번역 시 attention weights를 나타낸 것이다. 각 시점별로 어떤 state에 집중하고 있는지 볼 수 있다.
2.3) 정리
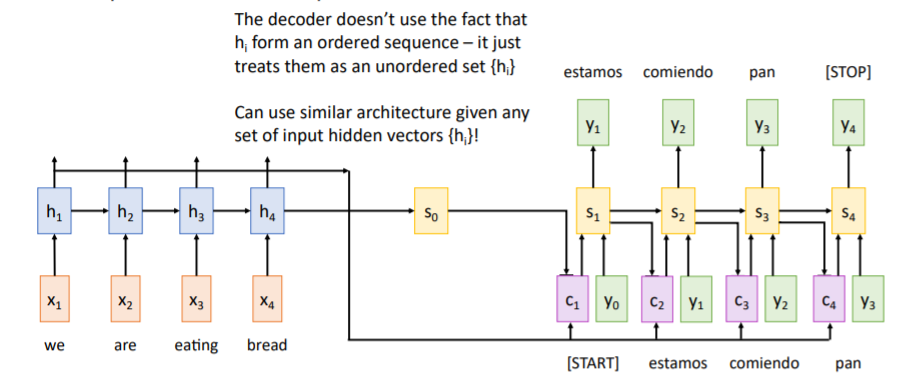 위에서 설명했던 attention 매커니즘은 사실 input sequence와는 상관이 없다. 그저
위에서 설명했던 attention 매커니즘은 사실 input sequence와는 상관이 없다. 그저 decoder이 input의 어느 state에 집중할 것인지를 계산하기 때문에 정렬되어있을 필요가 없다.
이 때문에 input이 sequence가 아닌 다른 종류의 이더라도 이 attention 매커니즘을 사용할 수 있다.
3. Image Captioning with RNNs and Attention
3.1) 설명
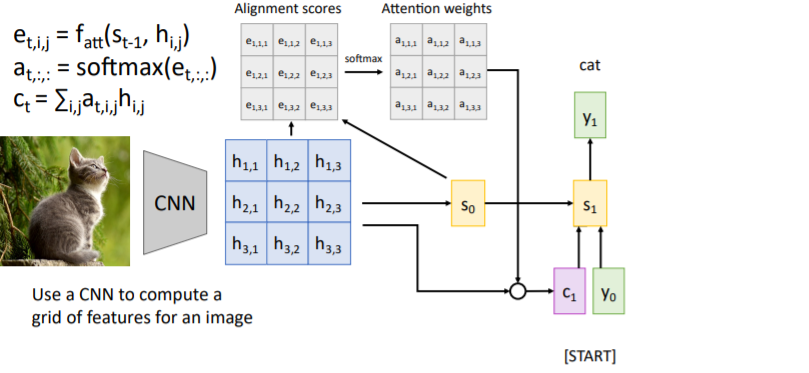 문장 변역과 같은 방식이다. CNN을 통과시켜서 나온 이미지 feature map의 각 spatial features와
문장 변역과 같은 방식이다. CNN을 통과시켜서 나온 이미지 feature map의 각 spatial features와 decoder의 hidden states를 대응하여 alignment scores를 계산하고 softmax를 통과시켜 attention weights를 계산한다. 그리고 이들과 feature map을 weighted sum하여 context vector을 계산한다. 과정은 아래와 같다.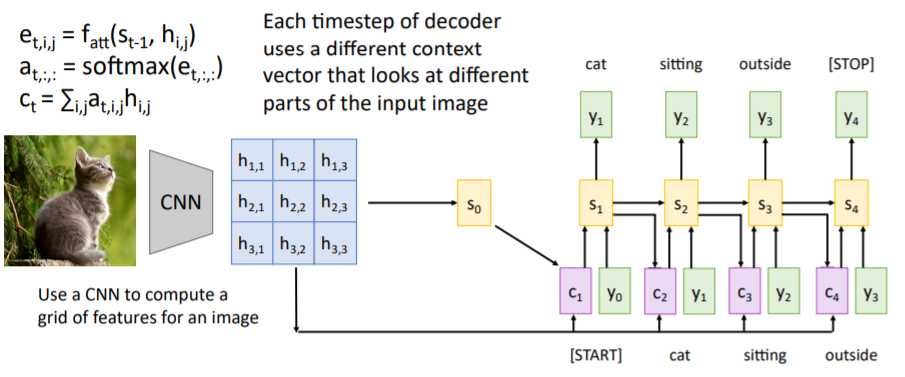
3.2) 예시


4. Attention Layer
4.1) 설명
Attention 매커니즘을 더욱 많은 task에 적용하기 위해 일반화를 시킨다.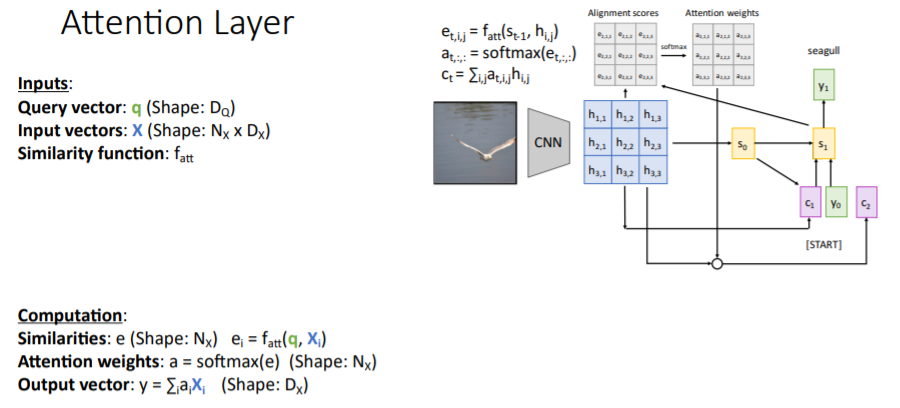 기존에 살펴본 attention 매커니즘을 조금 일반적으로 정의하고 있다.
기존에 살펴본 attention 매커니즘을 조금 일반적으로 정의하고 있다.
- Inputs:
- Query vector :
decoder의 hidden state로, 을 나타낸다. - Input vectors :
encoder의 각 hidden states의 collection으로 이다. - Similarity function : query vector와 input vector을 대응하여 중요도를 파악한다.
- Query vector :
- Computation:
- Similarities : query vector와 input vectors간의 similarities를 계산하여 alignment scores를 계산한다.
- Attention weights : alignment scores를 softmax에 통과시킨다.
- Output vector : input vectors와 attention weights의 weighted sum
4.2) Similarity function
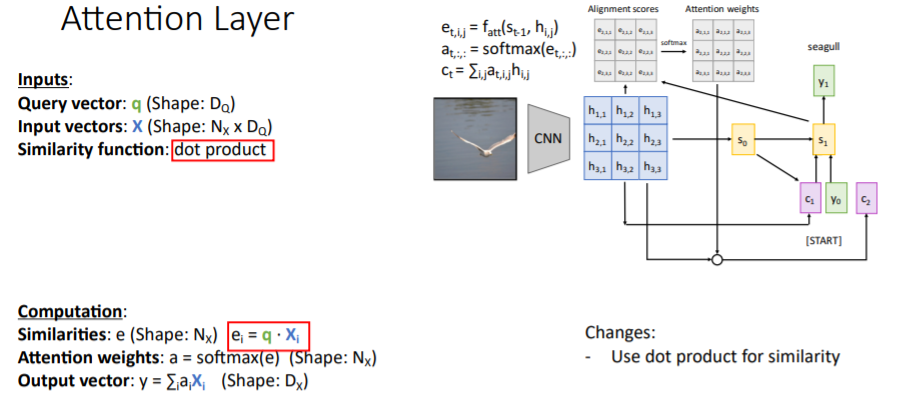 이전에는 라는 similarity MLP를 사용하였지만, 그저 둘 사이의 dot product를 사용하는 것이 더 효율적이고 잘 수행된다는 것이 밝혀졌다.
이전에는 라는 similarity MLP를 사용하였지만, 그저 둘 사이의 dot product를 사용하는 것이 더 효율적이고 잘 수행된다는 것이 밝혀졌다.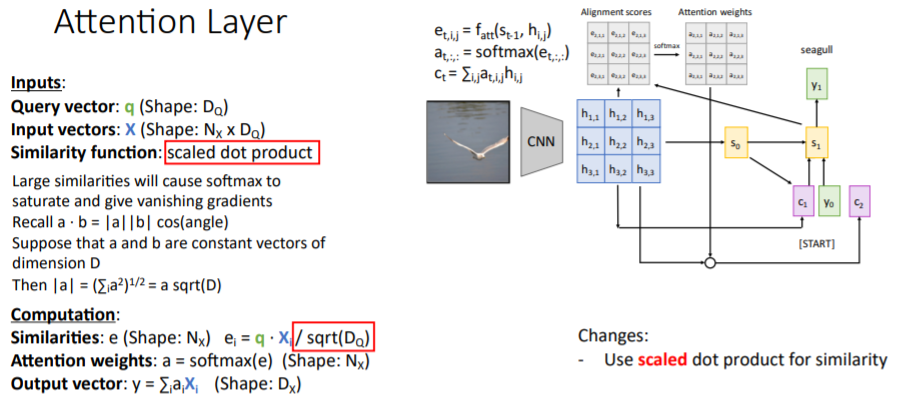 이후에는 scaled dot product를 사용하여 similarity를 계산하였다. dot product를 진행하고 query vector과 input vectors의 dimension인 로 나누어준다.
이후에는 scaled dot product를 사용하여 similarity를 계산하였다. dot product를 진행하고 query vector과 input vectors의 dimension인 로 나누어준다.
어떤 시점에서의 alignment score 가 매우 크면, softmax를 통과하고 난 뒤의 distribution을 보았을 때 매우 뾰족하고 나머지는 매우 완만한 그래프가 될 것이다. 즉 뾰족한 지점을 제외하면 gradient가 0에 가까워져 vanishing gradient가 나타난다.
그리고 만약 두 벡터가 high dimension을 가지면 dot product를 했을 때 매우 큰 값을 가지므로 이를 scaling시켜주기 위해 로 나누어준다.
4.3) Multiple Query vectors (이해 잘 안됐음..)
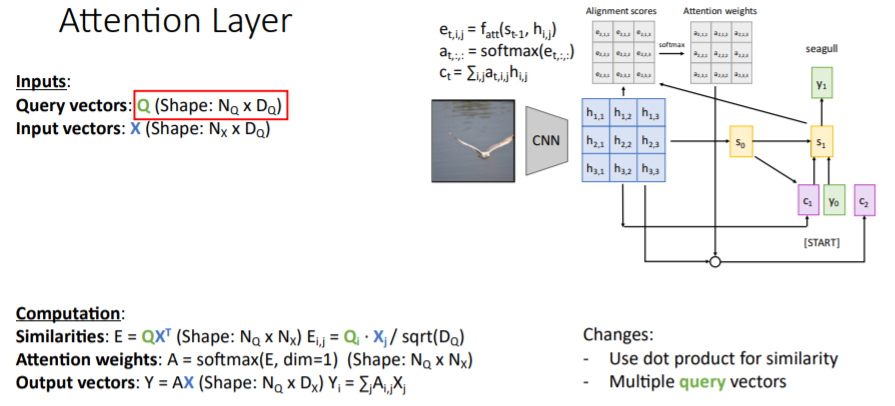 기존과 같이 single query vector 을 받아서 계산하는 것이 아니라 query vectors set 를 input으로 받아서 모든 similarity scores(alignment scores)를 scaled dot product 계산 한번으로 계산한다. output vectors는 모든 weighted sum을 한번에 출력한다.
기존과 같이 single query vector 을 받아서 계산하는 것이 아니라 query vectors set 를 input으로 받아서 모든 similarity scores(alignment scores)를 scaled dot product 계산 한번으로 계산한다. output vectors는 모든 weighted sum을 한번에 출력한다.
이거 행렬 사이즈랑 방식이 잘 이해 안됨
4.4) Separate Input vectors into key and value
기존에 input vectors 는 similarity scores를 계산하면서 query vectors와 dot product를 진행할 때 사용되고, 또 weighted sum(output 꼐산)을 진행할 때 또다시 같은 input vectors가 사용되었다.
같은 input vectors를 두 번 사용하는 것을 막기 위해 input vectors를 learnable한 key matrix와 value matrix로 나누었다. 그리고 이 둘을 사용하여 input vectors 를 key vectors와 value vectors로 transform시켰다.
key vectors는 simiarity scores를 계산할 때 사용되어, 각 query vector와 각 key vector을 비교한다.
value vectors는 output을 계산할 때 사용된다. 계산 과정은 아래 그림과 같다.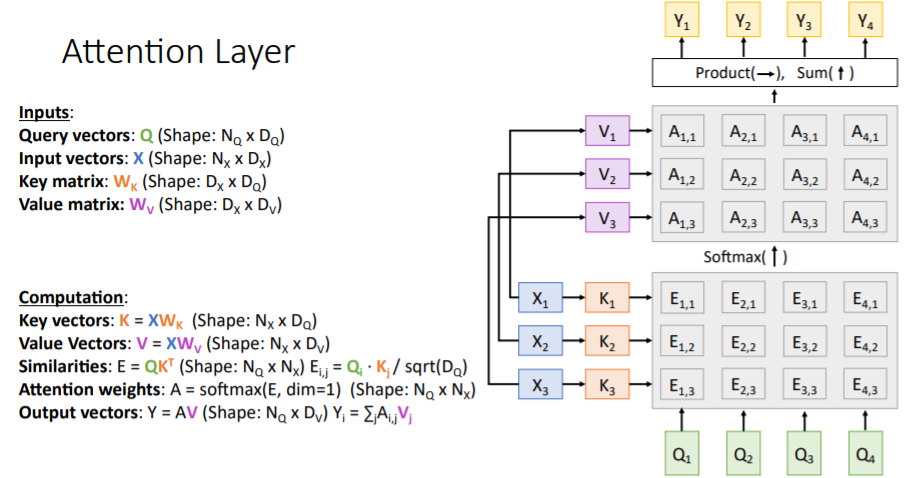
왜??
이를 사용함으로써 모델이 input data를 사용함에 있어서 flexibility를 더 갖는다고 한다.(?)
query vector은 모델이 "I want to search for this thing and then hopefully it needs to get back information which is different from the already knew" 라고 생각한다고..
4.5) 요약
Attention layer은 매우 일반화된 layer으로, 하나는 query이고 다른 하나는 input이라고 생각되는 두개의 데이터셋을 갖고 있다면 이 layer을 사용하여 계산할 수 있다.
5. Self-Attention Layer
5.1) 설명
Attention layer의 특별한 case로, query없이 input vectors 만 입력으로 받아서 input vectors 끼리 비교한다.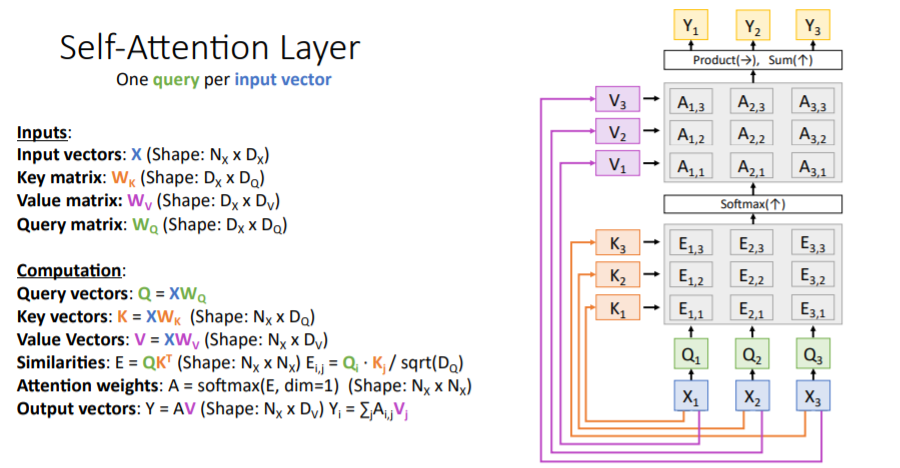 input vectors를
input vectors를 key matrix와 value matrix를 사용하여 transform한 것과 같이 query 가 없는 이 상황에서 query를 만들어주기 위해 learnable한 query matrix를 사용한다. 이를 사용하여 input vectors를 query vectors로 만들어준다.
5.2) Input의 순서를 바꾼다면?
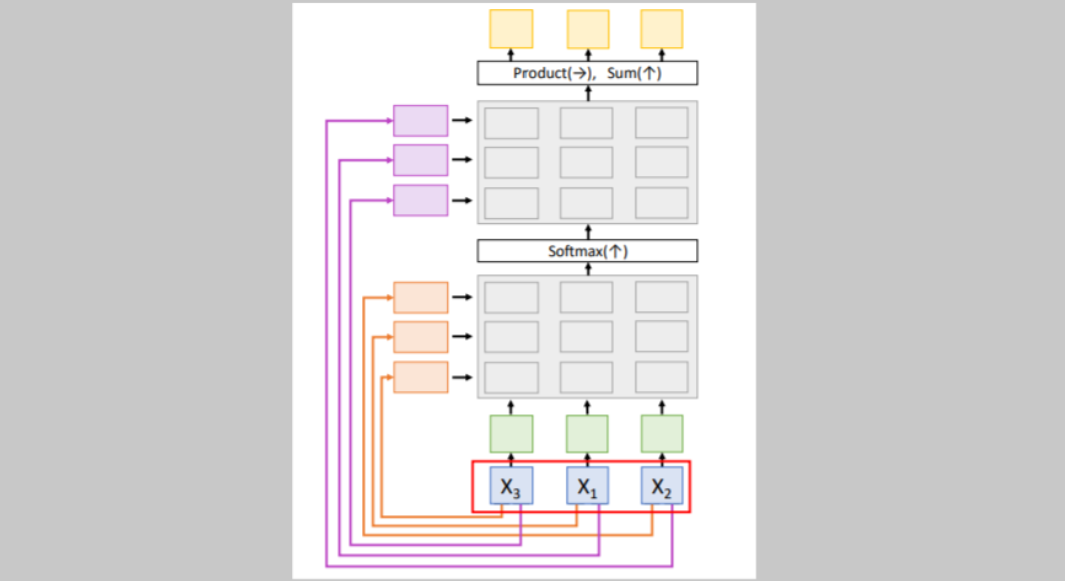 만약 위와 같이 input vectors의 순서를 바꾸면 어떻게 될까?
만약 위와 같이 input vectors의 순서를 바꾸면 어떻게 될까?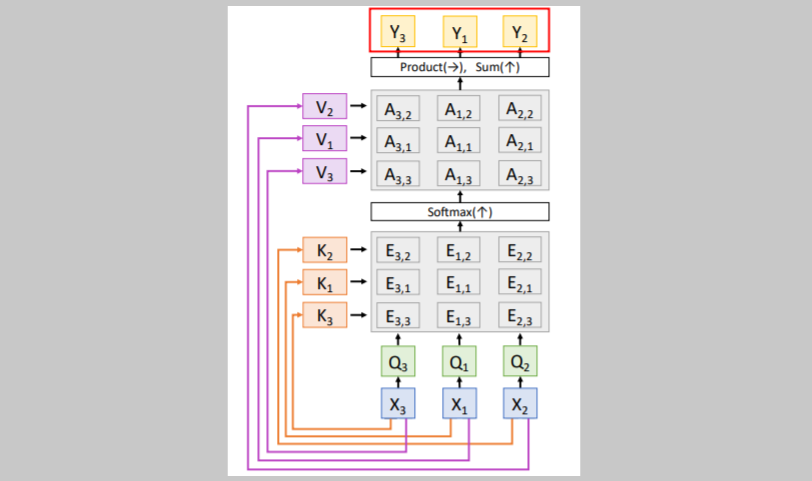 위 그림과 같이
위 그림과 같이 queries, keys, similarities, attention weights, values, outputs는 모두 같은 값이지만 바뀐 input vectors의 순서에 맞게 값들의 순서가 바뀔 것이다.
그래서?
결국 self-attention매커니즘은 Permutation Equivariant하다.
즉, permutaion을 , self-attention을 라고 했을 때,
이다. permutaion을 하고 self-attention을 하나, self-attention을 하고 permutation을 하나 서로 같다는 뜻이다.
self-attention은 input 순서에 영향받지 않는다.
self attention doesn't "know" the order of the vectors it is processing!
순서가 중요한 task인 경우에는?
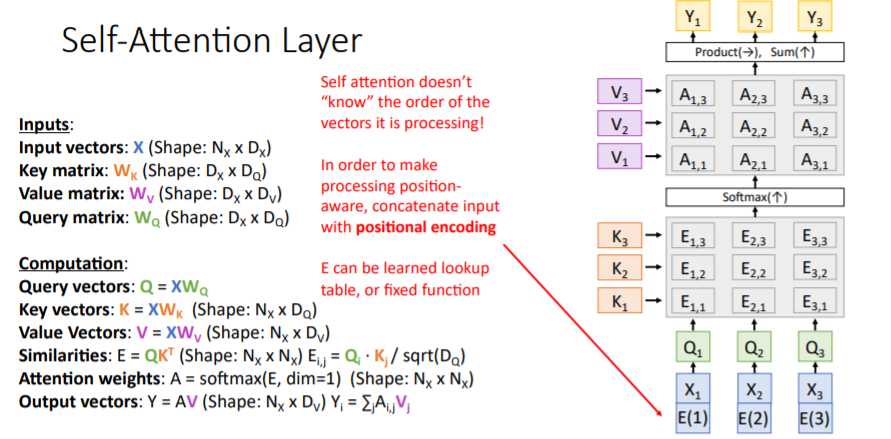 기본적으로 모델은 input의 순서를 모르기 때문에 순서가 중요한 task에서는 우리가 순서를 알려주어야한다.
기본적으로 모델은 input의 순서를 모르기 때문에 순서가 중요한 task에서는 우리가 순서를 알려주어야한다.
이때, positional encoding을 통해 input vector에 position정보를 주어 순서를 알려준다.
Attention is All you need 논문에서는 아래와 같은 positional encoding을 사용한다.
6. Masked Self-Attention Layer
Language modeling과 같이 과거의 states만 보고 싶은 경우에 해당한다. 기본적으로 self-attention은 input vector와 다른 모든 states간에 비교를 진행한다. 그러나 우리는 input vector이전의 states에만 집중하고 싶다.
이때, model이 과거의 정보만 볼 수 있도록 집중하지 않아야 할 부분에 값을 부여하여 softmax를 통과한 attention weights가 0이 되도록 하고 해당 position을 참고할 수 없도록 한다.
7. Multihead Self-Attention Layer
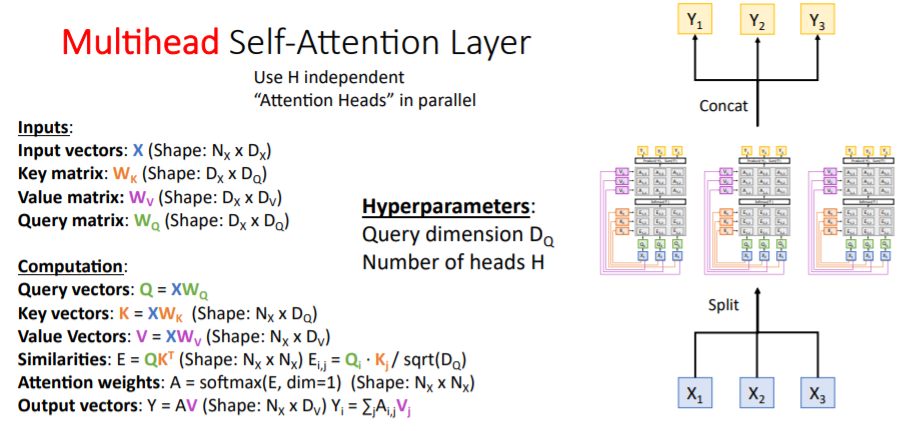 H개의 독립된 self-attention layer을 병렬로 처리한다.
H개의 독립된 self-attention layer을 병렬로 처리한다.
여기 더 공부해봐야할듯
8. Example: CNN with Self-Attention
self-attention을 CNN에 적용하면 어떨까?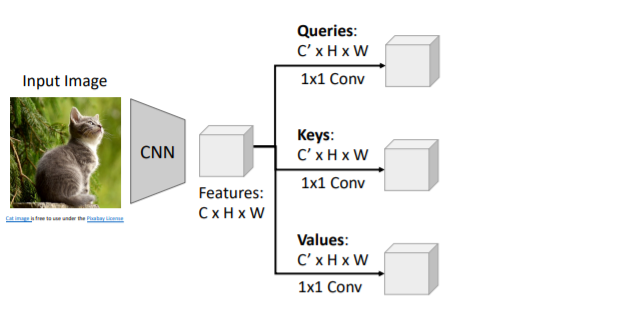 CNN으로 feature vectors를 계산하고, 이들을 1x1 Conv를 통해
CNN으로 feature vectors를 계산하고, 이들을 1x1 Conv를 통해 Queries, Keys, Values로 transform해준다.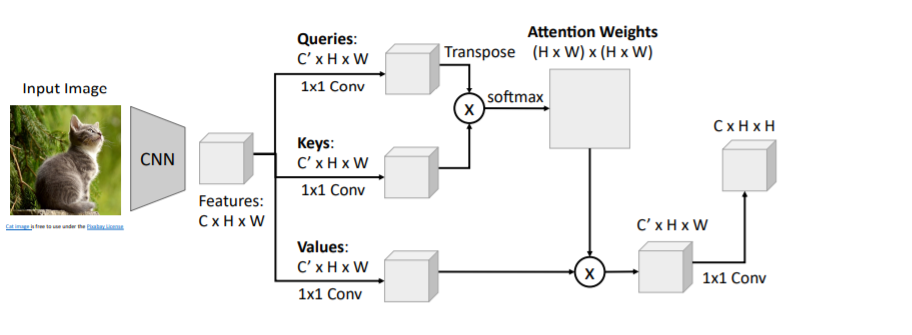
Queries와 Keys를 inner product한 뒤, softmax를 통과시켜 attention weights를 계산한다. 그리고 Values와 weighted sum을 하여 새로운 feature vector()을 생성한다.
그리고 input features와 채널수를 맞추기 위해 1x1 Conv를 사용한다.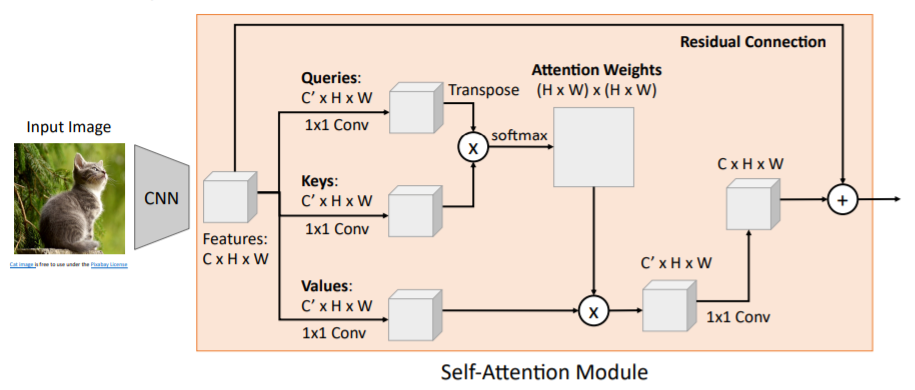 위와 같이 Residual Connection을 적용하기도 한다. 이는 하나의 모듈로써 neural network를 만들 때 하나의 layer로 사용할 수 있다.
위와 같이 Residual Connection을 적용하기도 한다. 이는 하나의 모듈로써 neural network를 만들 때 하나의 layer로 사용할 수 있다.
9. Three Ways of Processing Sequences
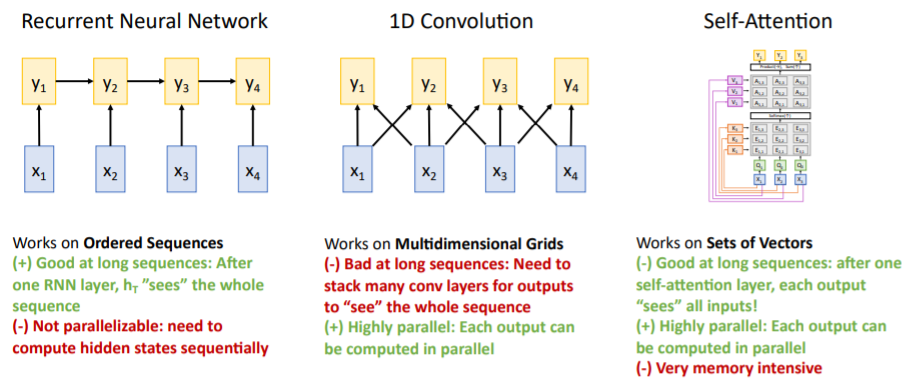
1. Recurrent Neural Network
- (+) hidden state 는 이전까지의 sequence에 영향을 받으며 이는 input sequences에 대한 요약된 정보라고 볼 수 있다.
- (+)
LSTM과 같은 모델은 매우 긴 sequence를 잘 다룰 수 있다. - (-) 을 계산하고, 를 계산하고, 을 계산하는 등 순차적으로 를 계산하므로 GPU를 병렬적으로 사용할 수 없다.
2. 1D Convolution
- (+) 각 output이 병렬적으로 계산될 수 있다. 각각의 kernel들을 독립적으로 연산할 수 있기 때문이다.
- (-) 그러나 위의 그림과 같은 상황에서는 output 는 3개의 input에만 영향을 받으며,
RNN처럼 많은 input sequences에 영향을 받기 힘들다. 그러기 위해서는 1D conv를 여러 층 쌓아야 하고 이는 long term sequences에 좋지 않다.
*3. Self-Attention
- (+) RNN과 같이 long sequences에 좋다. 모든 output은 모든 input에 영향을 받는다.
- (+) conv와 같이 병렬적이다. 각 output은 그저 큰 matrix 계산만 하면 된다.
- (-) 많은 메모리를 사용하지만 GPU가 좋아져서 그닥.
그래서 뭘 써야되는데?

10. Transformer
10.1) 설명
Attention is all you need논문에서는 self-attention만을 사용한 새로운 primitive block type인 transformer block을 제시하였다.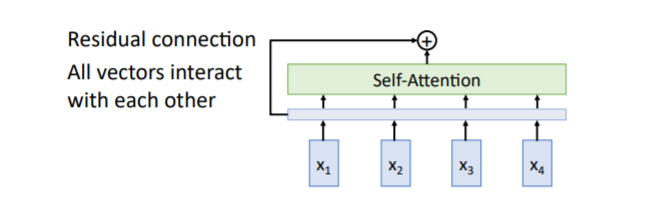 우선 input sequences를 입력받아 self-attention을 거친다. 이를 통해 모든 vectors는 각각의 다른 vectors와 interact할 수 있다. 그리고 gradient flow의 향상을 위해 residual connection을 적용한다.
우선 input sequences를 입력받아 self-attention을 거친다. 이를 통해 모든 vectors는 각각의 다른 vectors와 interact할 수 있다. 그리고 gradient flow의 향상을 위해 residual connection을 적용한다.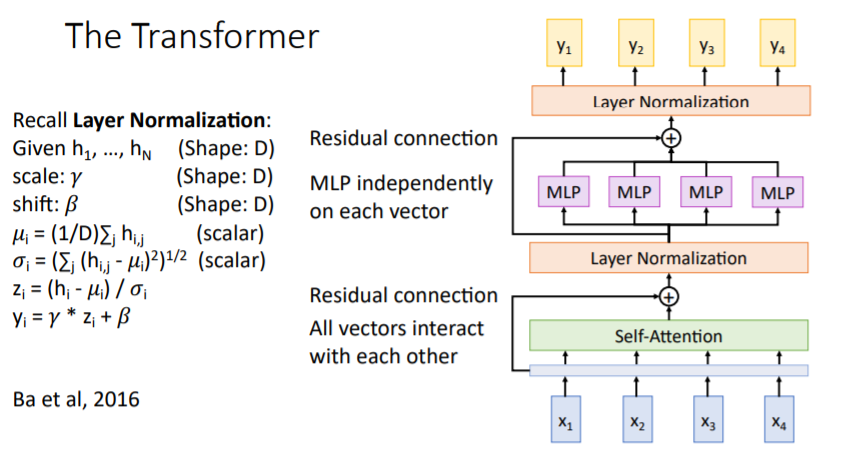 그리고
그리고 Layer Normalization을 거치는데, 이는 self-attention이 적용된 모든 vectors를 한번에 normalize하는 것이 아니라 vector들 각각 normalize하여 scale을 조정한다.
그리고 이들을 독립적으로 MLP에 통과시키고 residual connection을 적용하여 Layer Normalization을 한다.
Layer Normalization
Layer Normalization은 위 그림에서처럼 각 vectors에 대해 독립적으로 normalize한다.
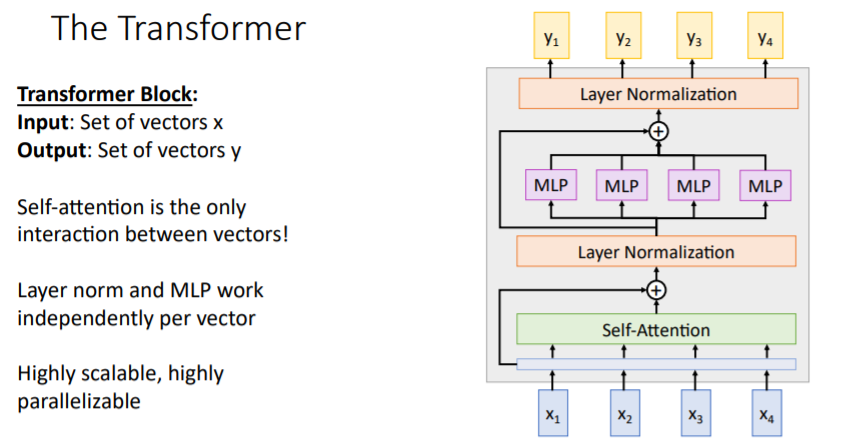 이를
이를 Transformer Block이라고 하며, vectors의 sequences를 다루는 커다란 모델을 만드는 데 기본 블록으로써 사용된다. # input vectors = # output vectors 이지만 dimension이 다르게 할 수 있다.
vectors 간의 interaction은 self-attention에서만 이루어지고 나머지 과정은 독립적이므로 병렬적으로 계산할 수 있다. Transformer blocks를 쌓아서 Transformer model을 만들 수 있다.
Transformer blocks를 쌓아서 Transformer model을 만들 수 있다.
hyperparameter : (depth, block수), (self-attention에서.)
10.2) Transfer Learning
 Transformer은 NLP에서 Vision에서와 같이 pre-train의 개념을 쉽게 도입할 수 있게 하였다.(Vision에서 ImageNet으로 pre-train하고 우리의 task에서 fine-tune시키는 것 처럼.)
Transformer은 NLP에서 Vision에서와 같이 pre-train의 개념을 쉽게 도입할 수 있게 하였다.(Vision에서 ImageNet으로 pre-train하고 우리의 task에서 fine-tune시키는 것 처럼.)
매우 많은 text를 다운받아서 매우 큰 transformer model을 pre-train시킨다. 그리고 우리가 하고싶은 task(QA, translation 등)에 적용하여 fine-tune시킨다.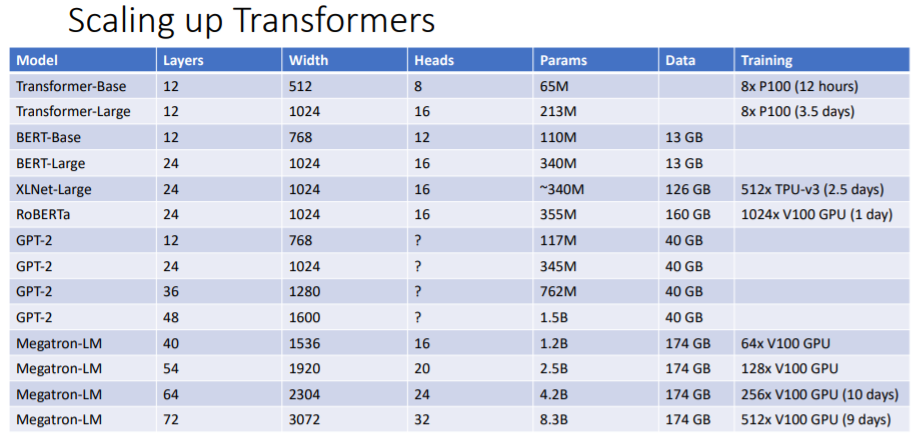
Transformer model을 기반으로 최근 많은 거대한 모델들이 등장했다. 모두 비슷한 구조로 되어있지만 layer의 수, query dimension, bigger multi-head, # parameters 등에서 다르며 train에 사용한 데이터의 수도 매우 거대한 것을 볼 수 있다.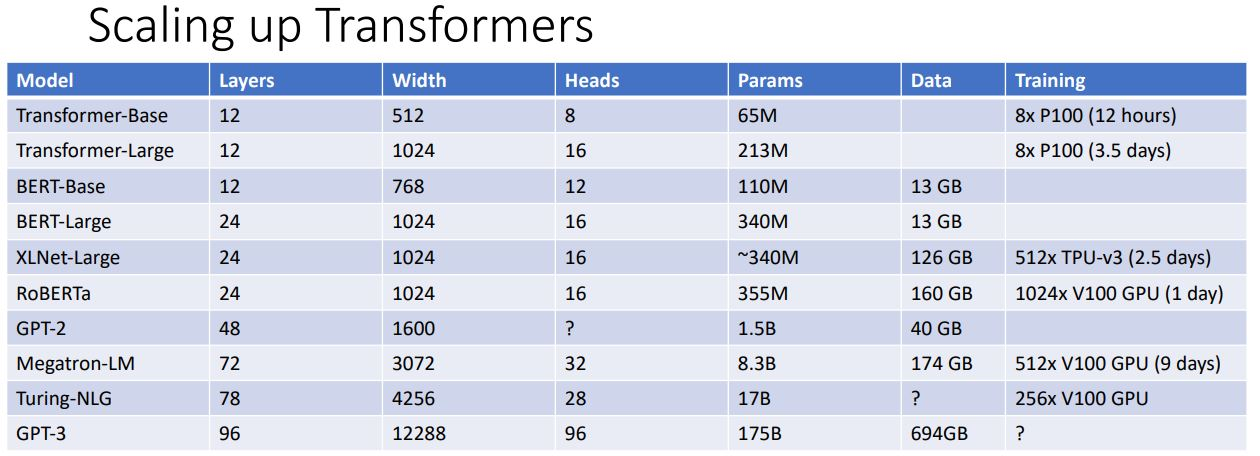
Summary
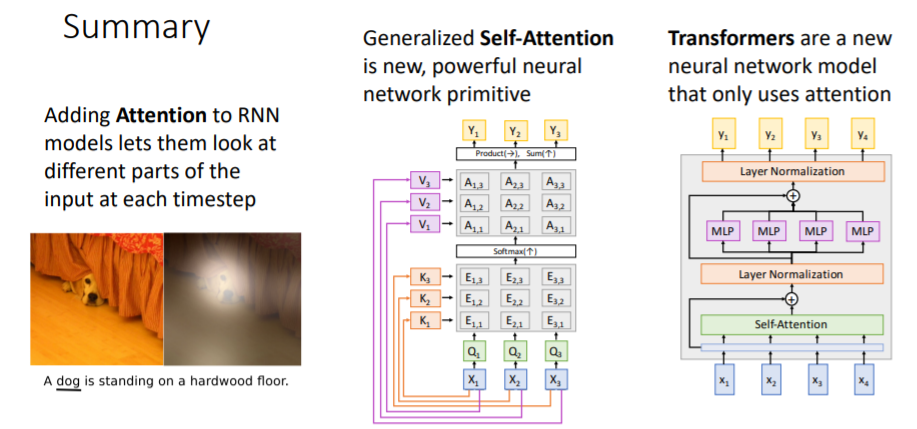

잘 보고가요~