Object Detection
- Object Detection
1.1) Detection a single object
1.2) Detecting Multiple Objects: Sliding Window
1.3) Region Proposals - R-CNN: Region-Based CNN
2.1) Train-time
2.2) Test-time
2.3) Comparing Boxes: Intersection over Union (IoU)
2.4) Overlapping Boxes: Non-Max Suppression (NMS)
2.5) Evaluating Object Detectors: Mean Average Precision (mAP) - Fast R-CNN
3.1) 설명
3.2) Cropping Features: RoI Pool
3.3) Cropping Features: RoI Align
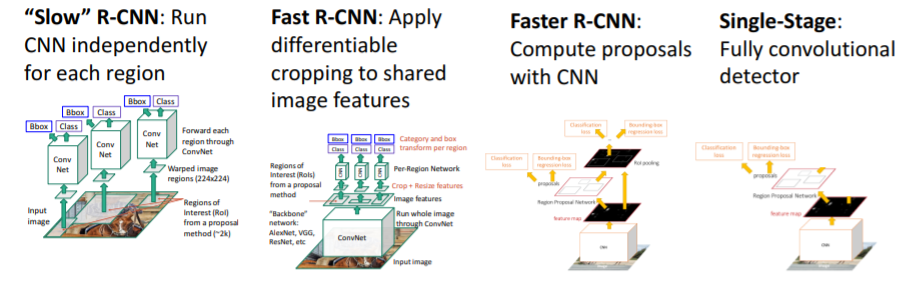
3.4) Fast R-CNN vs "Slow" R-CNN - Faster R-CNN: Learnable Region Proposals
4.1) 설명
4.2) Region Proposal Network (RPN)
4.3) 4 Losses
4.4) 성능
4.5) Single-Stage Object Detection - Object Detection: Lots of variables!
5.1) Open-Source Code
Summary
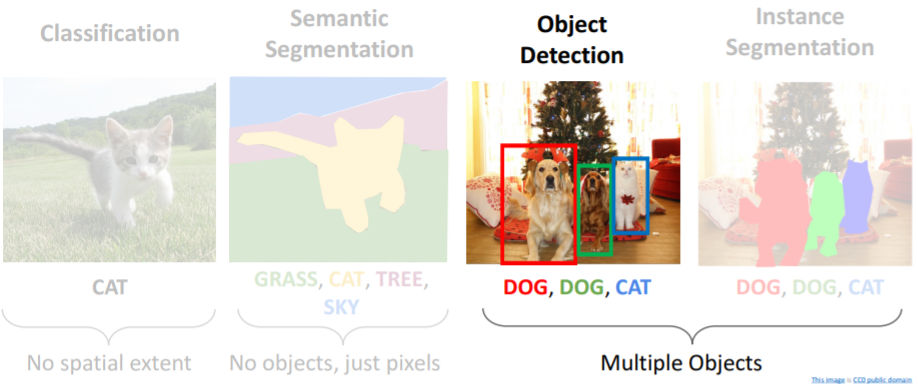
1. Object Detection
 Object Detection은 single RGB 이미지를 입력으로 받아서 objects set을 감지한다.
Object Detection은 single RGB 이미지를 입력으로 받아서 objects set을 감지한다.
각 object는 1. Category label, 2. Bounding box를 갖는다. (bounding box의 x,y는 박스의 중심점이다) Object Detection은 Image classification에 비해 어려운 점이 있다.
Object Detection은 Image classification에 비해 어려운 점이 있다.
- Multiple outputs : 한개의 이미지만 분류했던 image classfication과 달리 이미지 당 여러 종류의 objects를 감지해야한다.
- Multiple types of output : category label과 bounding box 두개의 output을 갖는다.
- Large images : 이미지 분류에서는 224x224면 충분했지만 여러 종류의 object를 감지해야하기 때문에 고해상도의 이미지를 필요로 한다. 따라서 더 많은 계산과 시간이 들어간다.
1.1) Detection a single object
먼저 간단하게 하나의 object만 감지하는 상황을 보자. 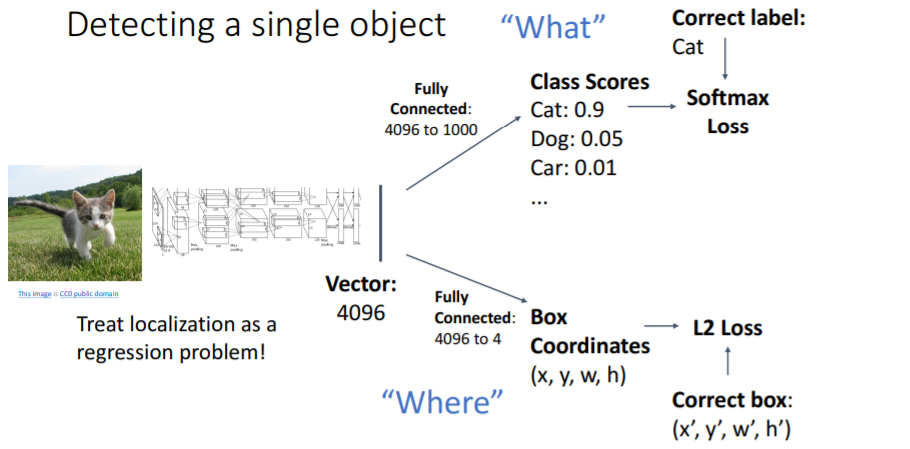 기본적으로 vgg나 resnet 등의 CNN을 통과시켜 feature vectors를 얻는다. 그리고 single object detection task에서는 2가지 task branch를 수행한다.
기본적으로 vgg나 resnet 등의 CNN을 통과시켜 feature vectors를 얻는다. 그리고 single object detection task에서는 2가지 task branch를 수행한다.
- 4096 1000 fc-layer을 통해 "What" 클래스인지 찾아낸다. 기본적인 image classification과 같다.
- 4096 4 fc-layer을 통해 "Where" 박스의 좌표를 찾는다. 이는
L2 Loss또는regression loss등을 사용하여 계산한다.
이렇게 하면 category label과 bounding box 두 개의 loss가 발생한다. 그러나 gradient descent를 위해 single loss가 필요하다. 따라서 이 두 loss를 weighted sum하여 final loss를 계산한다.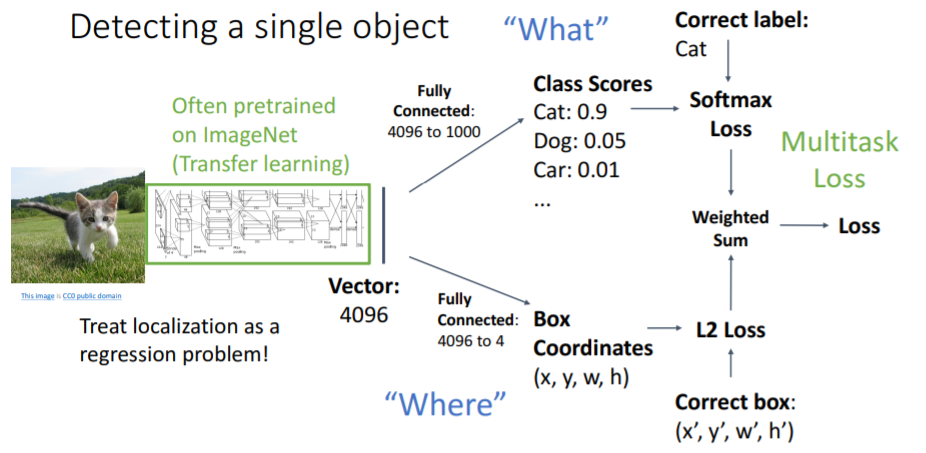 이렇게 하나의 네트워크에서 여러 Loss를 조합하는 loss를
이렇게 하나의 네트워크에서 여러 Loss를 조합하는 loss를 Multitask Loss라고 하며 각각 loss의 중요도에 따라 잘 tuning해주어야한다.
그러나 실제로는 하나의 이미지에서 여러 objects를 감지해내는 것이 중요하다. 또한 이처럼 이미지마다 감지할 objects의 수가 다르다. 고양이는 하나의 물체만 감지하면 되지만 아래 오리들은 많은 수의 오리를 감지해야한다.
또한 이처럼 이미지마다 감지할 objects의 수가 다르다. 고양이는 하나의 물체만 감지하면 되지만 아래 오리들은 많은 수의 오리를 감지해야한다.
1.2) Detecting Multiple Objects: Sliding Window
CNN은 image classification에 활용된다. 따라서 우리는 object detection을 CNN을 활용한 classification으로 환원하여 문제를 해결할 수 있다. 여기에서는 기본 classification에서 background라는 class를 하나 더 추가한다.
그리고 입력 이미지의 매우 많은 다른 지역에 각각 CNN을 적용하여 그 지역이 dog인지 cat인지 background인지 분류한다.
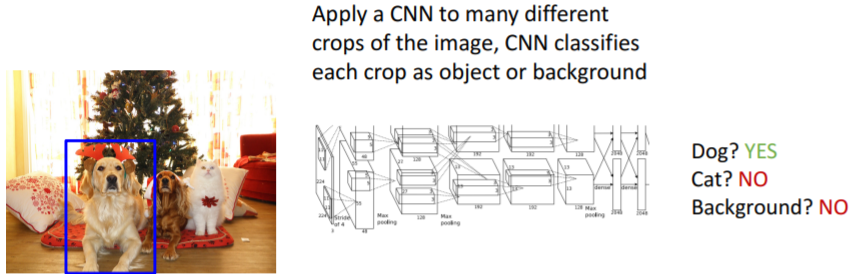
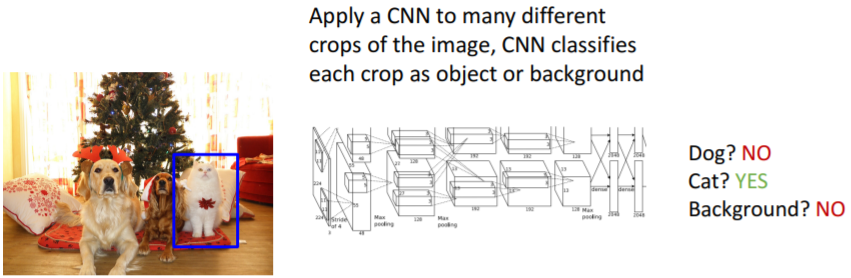 이렇게 보면 간단해보이지만 사실 문제가 하나 있다.
이렇게 보면 간단해보이지만 사실 문제가 하나 있다.
HxW의 이미지에 얼마나 많은 box가 있는가? 매우 많다... 너무 많다... 800x600에서 이를 계산하려면 58million 박스들이 필요하다. 이를 계산할 방도는 없다. 계산이 가능하다고 해도 같은 object를 매우 많은 박스에서 검출하는 문제도 발생할 것이다.
매우 많다... 너무 많다... 800x600에서 이를 계산하려면 58million 박스들이 필요하다. 이를 계산할 방도는 없다. 계산이 가능하다고 해도 같은 object를 매우 많은 박스에서 검출하는 문제도 발생할 것이다.
1.3) Region Proposals
1.2)의 문제를 해결하기 위한 방법이다.
모든 박스를 만드는 대신, candidate regions를 만든다. 이미지의 모든 objects를 커버할 수 있도록 하는 regions를 선택한다.(set of candidate regions) candidate regions를 만드는 알고리즘은 여러가지 존재하지만 그중 가장 유명한 방법은
candidate regions를 만드는 알고리즘은 여러가지 존재하지만 그중 가장 유명한 방법은 Selective Search이다.
region proposals 알고리즘을 사용하여 입력으로 넣는 여러 딥러닝 모델을 보자.
2. R-CNN: Region-Based CNN
2.1) Train-time
object detection과 딥러닝에서 매우 유명한 논문이다. 우선 input이미지를 준비하고 region proposal 알고리즘을 사용하여 약 2000개의 region proposals를 뽑아낸다.(=RoI)
우선 input이미지를 준비하고 region proposal 알고리즘을 사용하여 약 2000개의 region proposals를 뽑아낸다.(=RoI)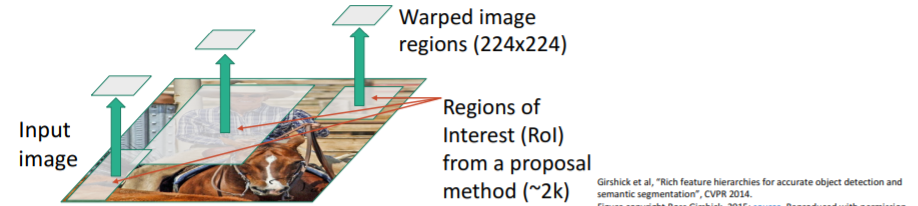 뽑아낸 region proposals는 크기들과 가로-세로 비율들이 다르므로 이들을 모두 224x224 이미지로 warping시킨다.
뽑아낸 region proposals는 크기들과 가로-세로 비율들이 다르므로 이들을 모두 224x224 이미지로 warping시킨다.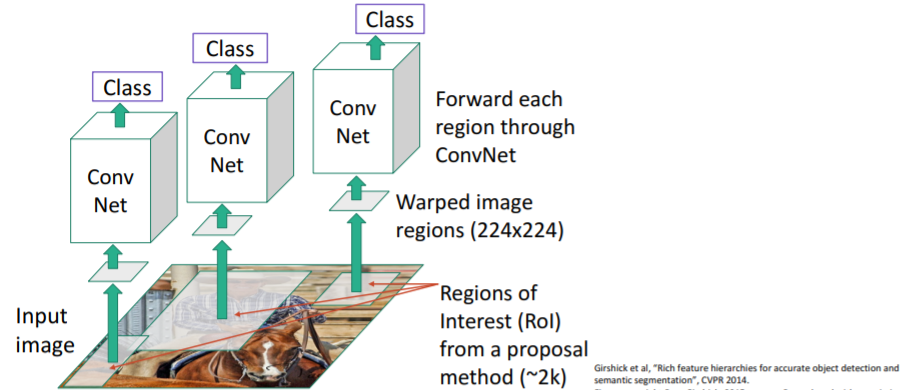 그리고 warping시킨 이미지들을 각각 Conv Net에 통과시켜 class score을 계산한다. 이 score은 background인지, ~카테고리인지 알려준다.
그리고 warping시킨 이미지들을 각각 Conv Net에 통과시켜 class score을 계산한다. 이 score은 background인지, ~카테고리인지 알려준다.
그런데 만약 뽑아낸 region proposals들이 우리가 detect하고 싶은 object 위에 존재하지 않는다면 어떻게 할 것인가? 또한 region proposal 알고리즘 black-box의 형태로, region proposals 박스들을 학습시킬 수 없다. 따라서 아래와 같은 방법을 사용한다.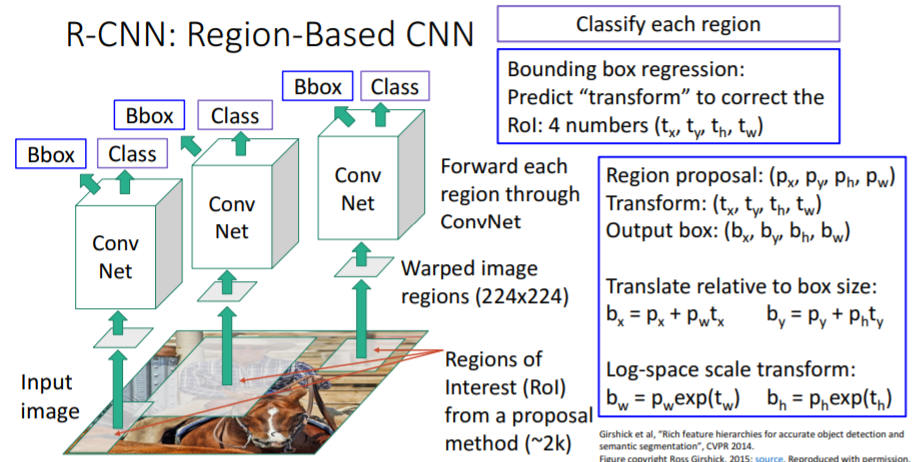 region proposals 박스들을 학습시킬 수 없는 문제를 해결하기 위해 위에서 봤던 것처럼
region proposals 박스들을 학습시킬 수 없는 문제를 해결하기 위해 위에서 봤던 것처럼 Multitask Loss를 사용한다.
그리고 bounding box regression을 사용하여 뽑아내었던 region proposal box들을 bounding box로 transform시켜준다. 이를 통해 region proposals들이 조금 더 object에 fitting되도록 수정한다.
Conv Net을 통해 얼마나 transform시킬지 를 출력하고 기존 region proposal의 coordinate인 를 transform시켜준다.
로 transform시켜 최종 output box를 출력한다. 위와 같이 box size와 log-space scale에 관련지어 x,y값을 transform하는 이유는 초기에 이미지를 warp하기 때문이라고 한다. (직관적으로만 이해됨. warp된 비율만큼 중심점을 이동시키려는 듯)
2.2) Test-time
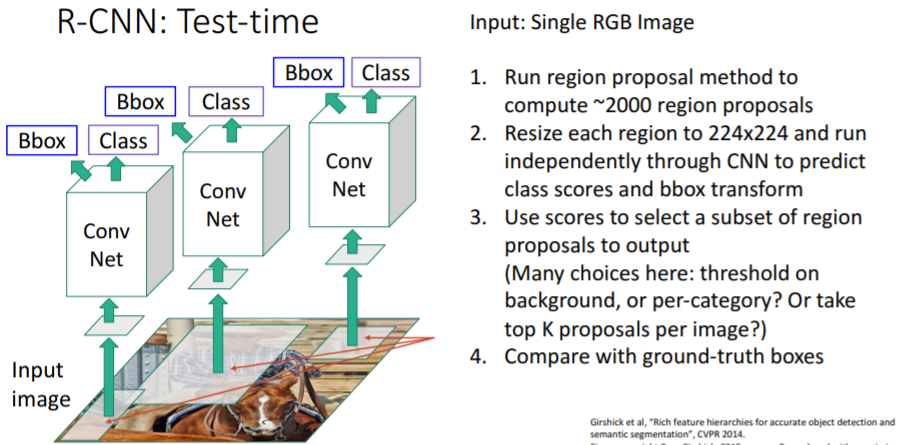
R-CNN의 test-time이다.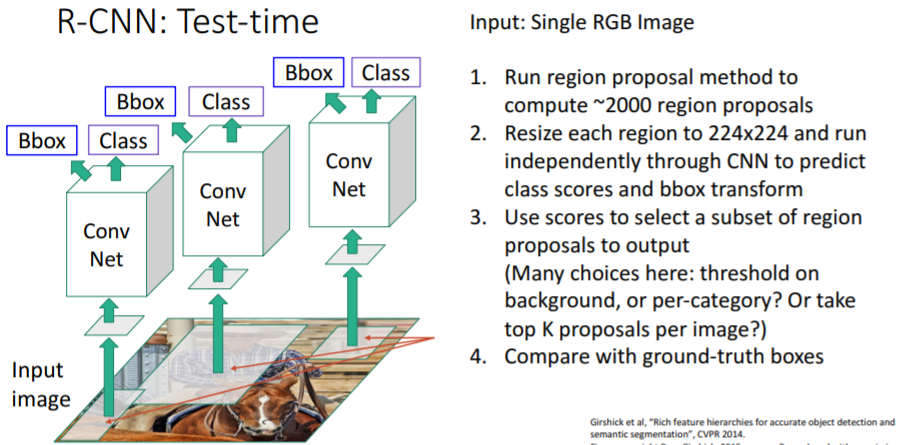
Input : single RGB 이미지
- selective search 알고리즘을 사용하여 2000개의 region proposals를 뽑아낸다.
- 각 region proposals를 224x224 사이즈로 warping하고 이들을 각각 CNN에 통과시켜
class scores와bbox transform을 예측한다. - class scores를 사용하여 우리가 원하는 object subsets를 선택하여 최종 output으로 출력한다. 이는 어떤 어플리케이션에 사용할지에 따라 달라질 수 있다. object subsets를 선택하는 방법에는 여러가지가 있다.
- background또는 카테코리별로 threshold를 주거나
- K개의 가장 높은 proposals를 찾거나 등등..
- output을 평가하기 위해 gt boxes와 비교한다.
2.3) Comparing Boxes: Intersection over Union (IoU)
bounding boxes를 비교하는 방법이다.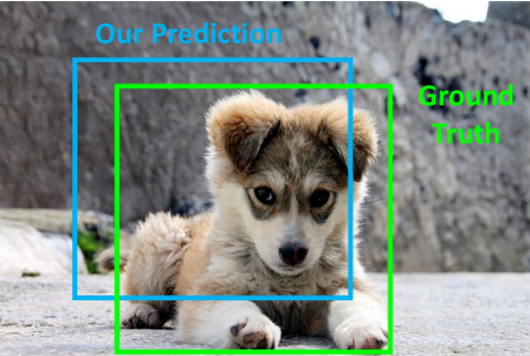 예측한 bounding box와 gt box간의 차이를 어떻게 측정하는가?
예측한 bounding box와 gt box간의 차이를 어떻게 측정하는가?
으로 계산하고 이는 0 ~ 1의 값을 갖는다.
- IoU > 0.5 : decent
- IoU > 0.7 : pretty good
- IoU > 0.9 : almost perfect
이런 식으로 판단한다.
그런데 위 그림에서 Area of Union을 나타내는 보라색 부분이 좀 잘못나온듯? Union이면 오른쪽위랑 왼쪽 아래 안겹치는 부분들은 빠져야될 듯.
2.4) Overlapping Boxes: Non-Max Suppression (NMS)
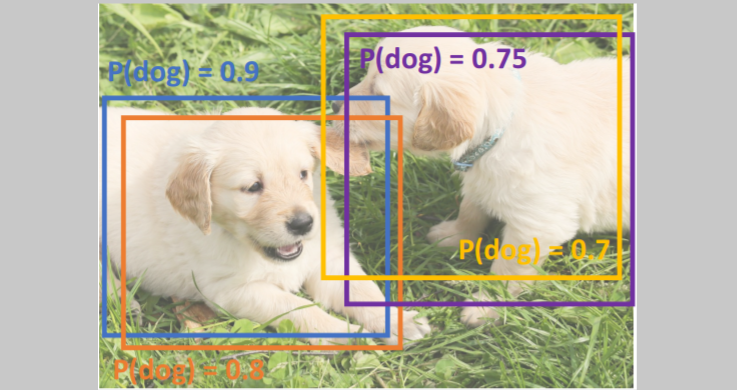 object detectors는 겹치는 boxes를 출력하기도 한다. 즉 동일 object에 대해 여러 output boxes를 출력한다. 이를 해결하기 위해
object detectors는 겹치는 boxes를 출력하기도 한다. 즉 동일 object에 대해 여러 output boxes를 출력한다. 이를 해결하기 위해 Non-Max Suppression (NMS)라는 알고리즘을 사용한다. 구현 방식은 여러가지지만 greedy알고리즘을 사용하여 간단히 구현할 수 있다고 한다.
- bounding box마다 image classification score이 나올텐데 이들의 점수들을 내림차순으로 정렬하고 가장 높은 score을 가진 box를 선택한다.(다음 반복부터는 남은 box중 그 다음으로 높은 score을 가진 box를 선택한다.)
- 가장 높은 score을 가진 bounding box와 다른 boxes들(더 낮은 score을 갖는) 간의 IoU를 계산하고 설정한 threshold보다 높은 값을 가지면 제거한다.
- boxes가 남아있다면 1번부터 반복한다.
이를 진행하면 아래와 같은 결과가 나온다. 이 방식은 거의 항상 잘 작동하지만 약간의 문제가 있다.
이 방식은 거의 항상 잘 작동하지만 약간의 문제가 있다. 이와 같이 많은 higly overlapping boxes가 나오는 상황에서 좋은 boxes를 제거할 수도 있다.
이와 같이 많은 higly overlapping boxes가 나오는 상황에서 좋은 boxes를 제거할 수도 있다.
2.5) Evaluating Object Detectors: Mean Average Precision (mAP)
IoU를 사용해서 각 boxes들 끼리 비교하는 metric 이외에,
object detector이 test set에서 얼마나 잘 작동하는지를 평가하는 overall performance metric이다.
- 모든 test set이미지를 가지고 object detector을 돌린다.
non-max suppression을 사용하여 overlapping boxes를 제거한다.
이렇게 되면 각 test set 이미지에 대해 감지한 여러 boxes들이 남을 것이다. 그리고 이들 boxes는 각 카테고리 별로 classification score을 가질 것이다.- 각 카테고리별로
Average Precision을 계산한다. 이는 한 카테고리에서 전체적으로 얼마나 잘 하고 있는지를 나타낸다. - 그리고
Precision vs Recall Curve를 그린다.
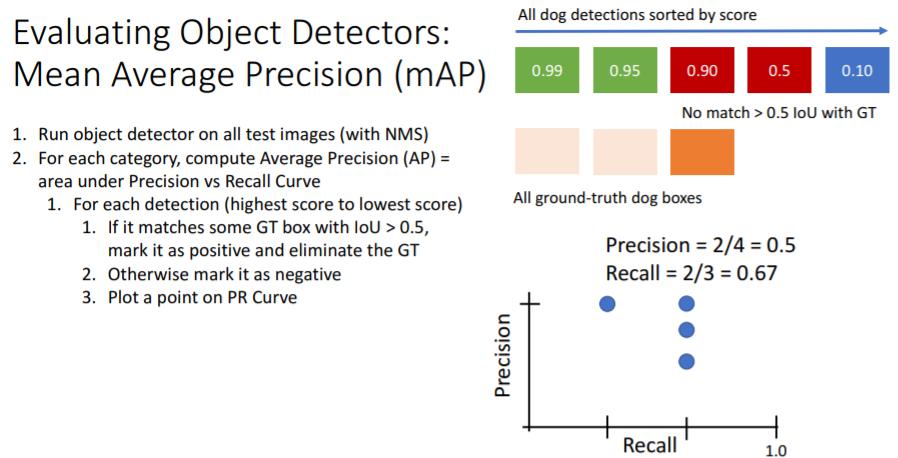
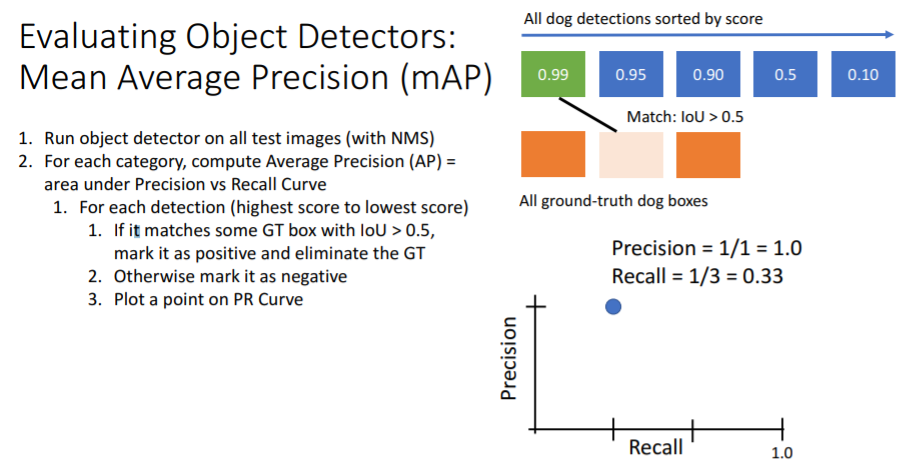 각 카테고리별로 수행하는데 우선 개 카테고리의 과정을 보면 개 카테고리에 대한 boxes의 classification score이 있을 것이다. 이를 내림차순으로 정렬하고 가장 높은 score을 가진 detection과 모든 GT들을 IoU로 비교하여 값이 0.5가 넘는 GT가 있다면 그 detection을 True Positive으로 설정한다.
각 카테고리별로 수행하는데 우선 개 카테고리의 과정을 보면 개 카테고리에 대한 boxes의 classification score이 있을 것이다. 이를 내림차순으로 정렬하고 가장 높은 score을 가진 detection과 모든 GT들을 IoU로 비교하여 값이 0.5가 넘는 GT가 있다면 그 detection을 True Positive으로 설정한다.
위 그림에서는 첫번째 detection만 봤으므로 이고 그 detection이 GT와 IoU>0.5 인 GT가 있으므로 TP이다. 따라서 이다.
그리고 개를 나타내는 boxes는 총 3개가 있어야 하므로 이고 그 중 1개의 detection이 정답이었으므로 이다.
첫번째 detection은 GT와 비교하여 정답이었으므로 정답을 맞춘 GT는 GT들 집합에서 삭제한다.
그리고 나머지 detection들도 차례대로 진행하면 아래와 같이 그래프를 그릴 수 있다.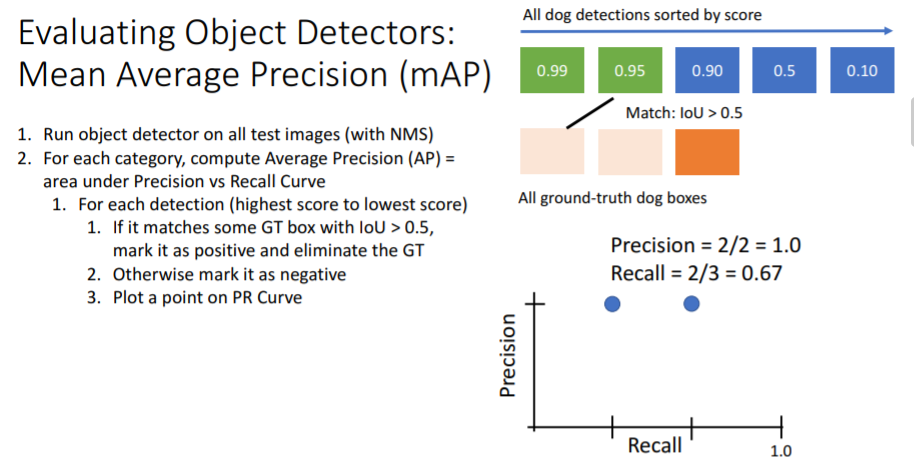
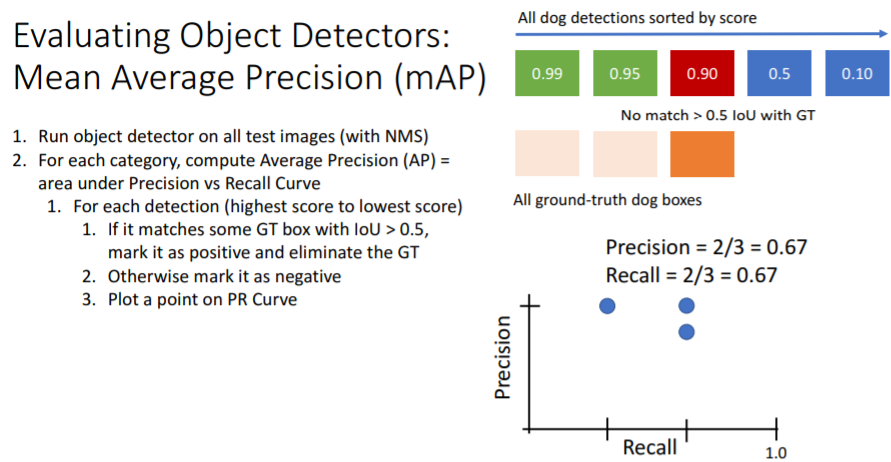
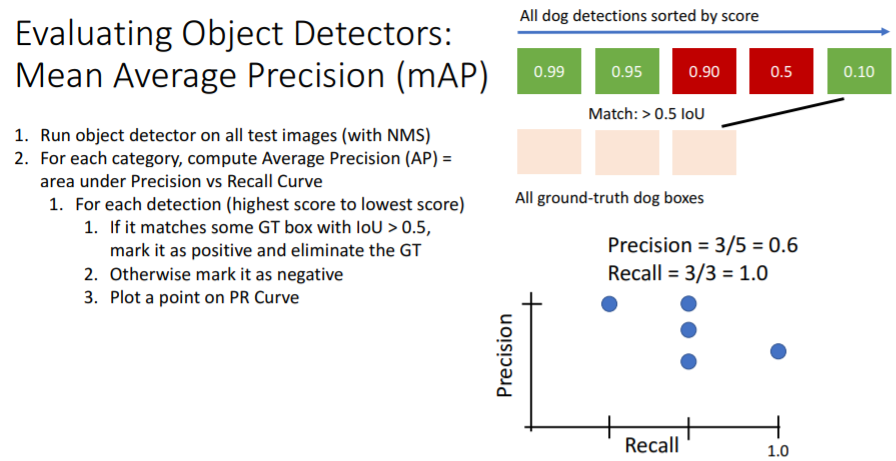 그리고 이들을 이어주어 PR curve를 만들고 area 넓이인
그리고 이들을 이어주어 PR curve를 만들고 area 넓이인 Average Precision (AP)을 구하면 아래와 같다.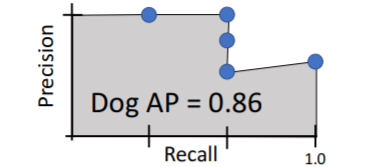
AP는 어떤 것을 의미하는가?
AP=1.0 이라는 것은 가장 높은 scores를 갖는 detections이 모두 true positive이고, true positive를 받은 detections 사이에서 false positive는 없으며 overlapping detections(duplicate detections) 또한 없다는 의미이다(모든 detections가 GT와 대응됨).
즉, scores로 정렬된 detections에서 tp | tp | fp | tp 는 존재할 수 없다.
AP=0.0 이 될수록 안 좋은 detector이다. 앞서서는 개 카테고리에 대한 예시였고, 이제 모든 카테고리에 대해 위 과정을 거쳐서 AP 값을 계산한다. 그리고 이들의 mean값을 구한 것이
앞서서는 개 카테고리에 대한 예시였고, 이제 모든 카테고리에 대해 위 과정을 거쳐서 AP 값을 계산한다. 그리고 이들의 mean값을 구한 것이 mAP이다. 그리고 threshold=0.5 뿐만 아니라 다른 값들로도 주어서
그리고 threshold=0.5 뿐만 아니라 다른 값들로도 주어서 mAP를 계산한다.
Precision vs Recall
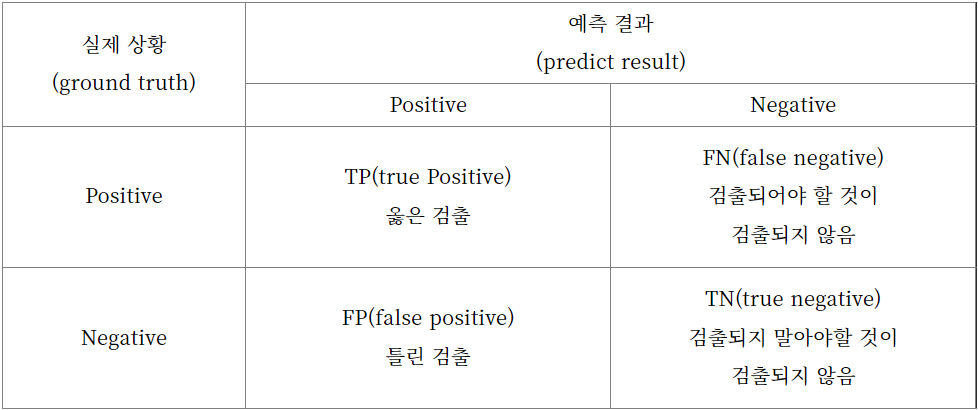 그리고
그리고
로 계산한다.
- Precision : 모델이 Positive라고 예측한 것 중에서 실제로 Positive한 비율
- Recall : 실제 Positive 에서 모델이 Positive라고 예측한 비율
3. Fast R-CNN
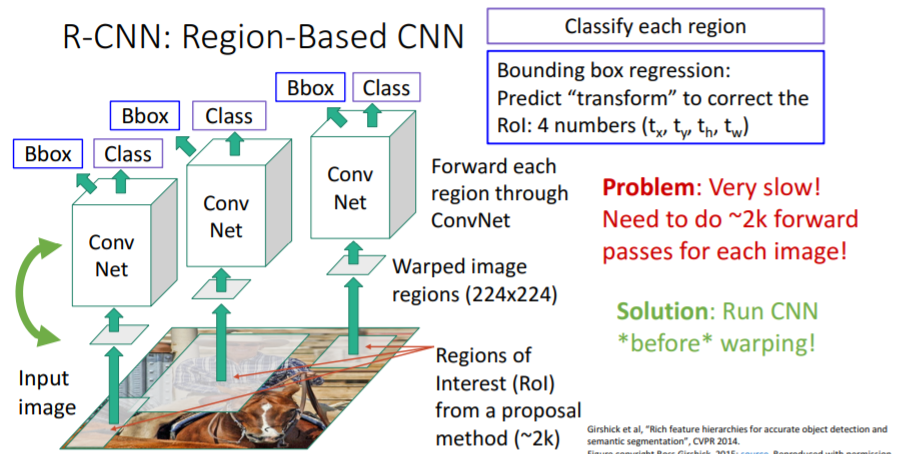 앞서 2.에서 설명한
앞서 2.에서 설명한 R-CNN은 문제가 하나 있다. 뽑아낸 2000개의 region proposals을 forward pass로 2000번 CNN에 넣어야 한다. 매우 느리다!
이를 해결하기 위해 CNN과 warping의 순서를 바꾼다.
3.1) 설명
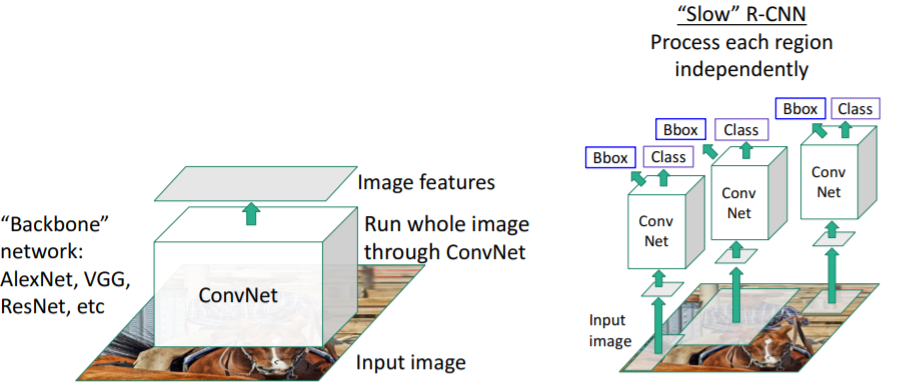 기존 R-CNN처럼 region proposals를 각각 CNN에 넣는 것이 아니라 전체 이미지를 fc-layer이 없이 Conv-layer만 있는 single CNN에 넣는다. 그 결과 feature map을 얻을 수 있다.
기존 R-CNN처럼 region proposals를 각각 CNN에 넣는 것이 아니라 전체 이미지를 fc-layer이 없이 Conv-layer만 있는 single CNN에 넣는다. 그 결과 feature map을 얻을 수 있다.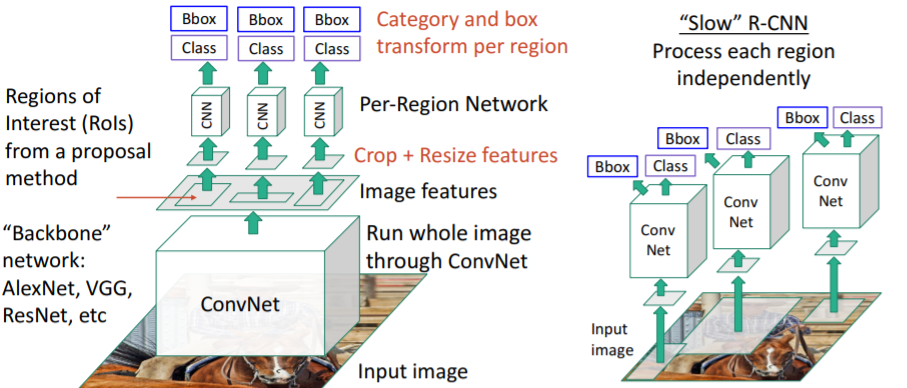 그리고 이 feature map 상에서 selective search와 같은 방식으로 region proposals를 뽑아낸다.
그리고 이 feature map 상에서 selective search와 같은 방식으로 region proposals를 뽑아낸다.
이들 feature region proposals를 crop하고 resize하여 각각을 작은 CNN에 통과시켜 output을 계산한다.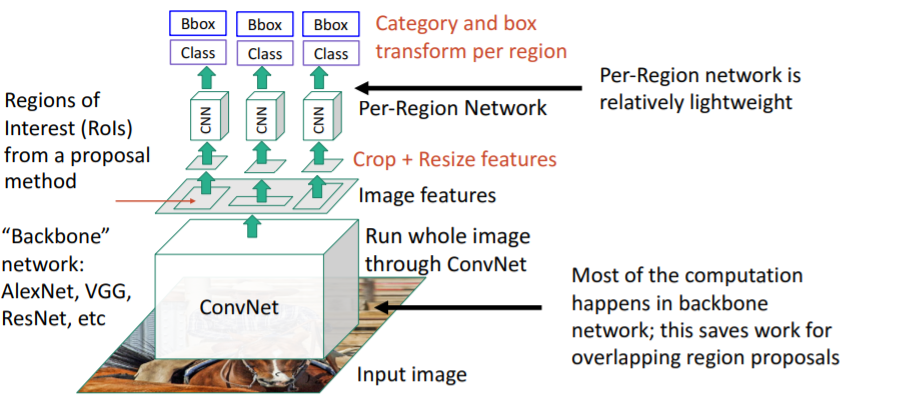 이 방식이 빠른 이유는 대부분의 계산이 아래 Backnone network에서 일어나는데, 이렇게 하면 overlapping region proposals에 대해 반복적으로 계산할 필요없이 한번 계산하면 끝나기 때문이다.
이 방식이 빠른 이유는 대부분의 계산이 아래 Backnone network에서 일어나는데, 이렇게 하면 overlapping region proposals에 대해 반복적으로 계산할 필요없이 한번 계산하면 끝나기 때문이다.
그리고 위의 CNN인 per-region entwork는 상대적으로 매우 가볍고 작다.
여러 종류의 backbone에서의 예시
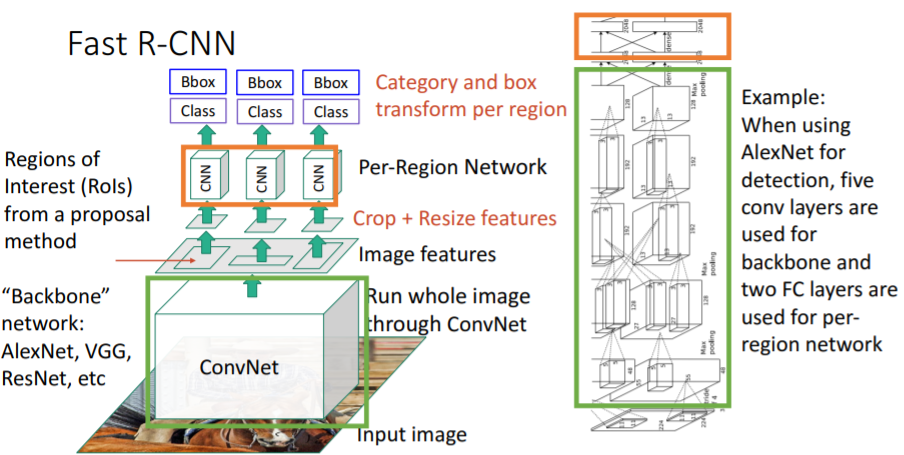 backbone으로
backbone으로 AlexNet을 사용한 예시이다.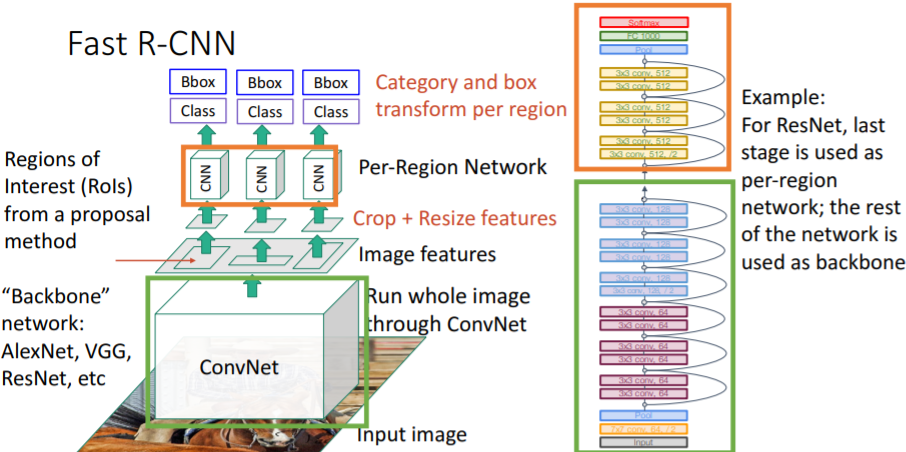 backbone으로
backbone으로 ResNet을 사용한 예시이다.
한번 계산한 값들을 region proposals에 share할 수 있기 때문에 계산을 매우 아낄 수 있다.
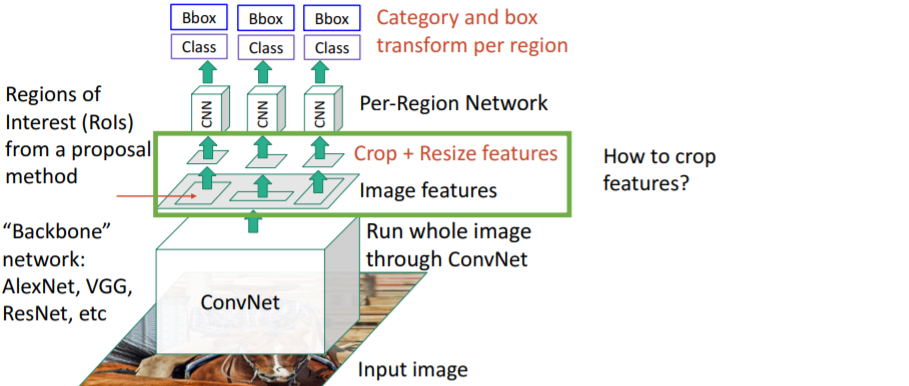 그렇다면 어떻게 features를 crop시키는가? backbone까지 backprop이 되어야 하기 때문에 미분 가능하도록 crop시켜야한다.
그렇다면 어떻게 features를 crop시키는가? backbone까지 backprop이 되어야 하기 때문에 미분 가능하도록 crop시켜야한다.
3.2) Cropping Features: RoI Pool
feature map에서 바로 region proposals를 뽑아낼 수는 없다.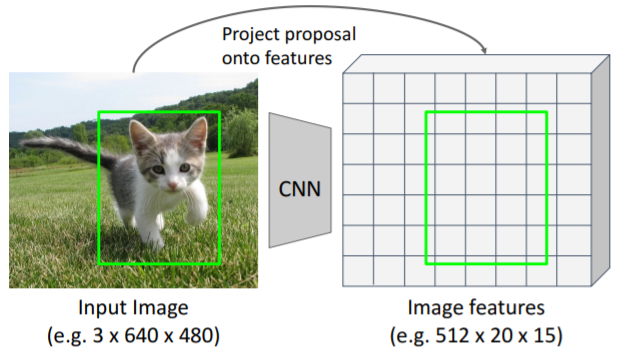 따라서, 기존 input 이미지에서 알고리즘을 통해 region proposals를 뽑아내고, 이를 feature map에 맞도록 매핑시킨다.
따라서, 기존 input 이미지에서 알고리즘을 통해 region proposals를 뽑아내고, 이를 feature map에 맞도록 매핑시킨다.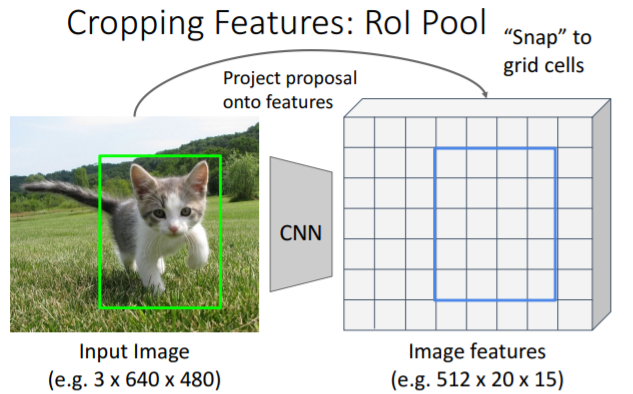 그런데 그냥 매핑시키게 되면 feature grid에 완벽히 맞지 않기 때문에 feature map에 맞게끔
그런데 그냥 매핑시키게 되면 feature grid에 완벽히 맞지 않기 때문에 feature map에 맞게끔 snap시켜야 한다.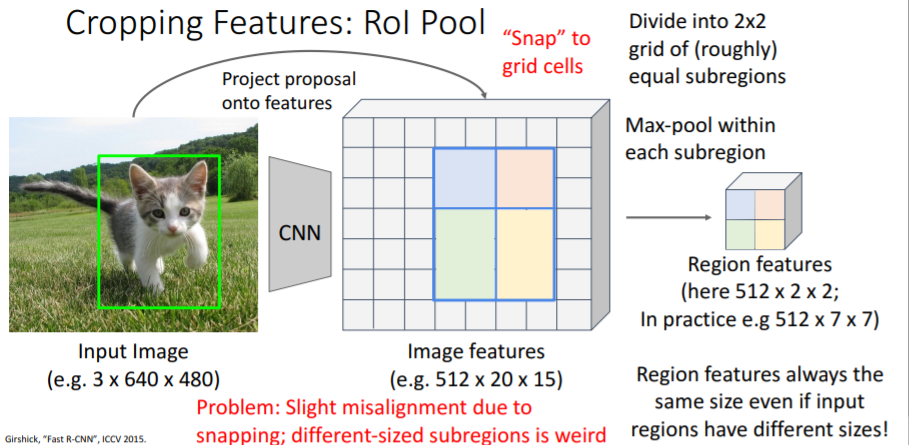 그리고 대략 2x2의 sub regions로 이를 나누고, 각 sub region에 Max-pool을 진행하여 region features를 구한다.
그리고 대략 2x2의 sub regions로 이를 나누고, 각 sub region에 Max-pool을 진행하여 region features를 구한다.
이를 통해 다른 사이즈의 region proposals에 대해서도 모두 같은 사이즈의 region features를 구할 수 있다.
그러나 snapping을(이동시켰음) 했기 때문에 기존 box로부터 약간의 misalignment 발생하고; 다른 사이즈를 갖는 sub regions도 조금 이상하다는 문제점이 있다. 또한 snapping을 시켰기 때문에 bounding box의 coordinates로 backprop을 시킬 수 없다. coordinates가 항상 feature grid에 맞게 snap되기 때문이다.
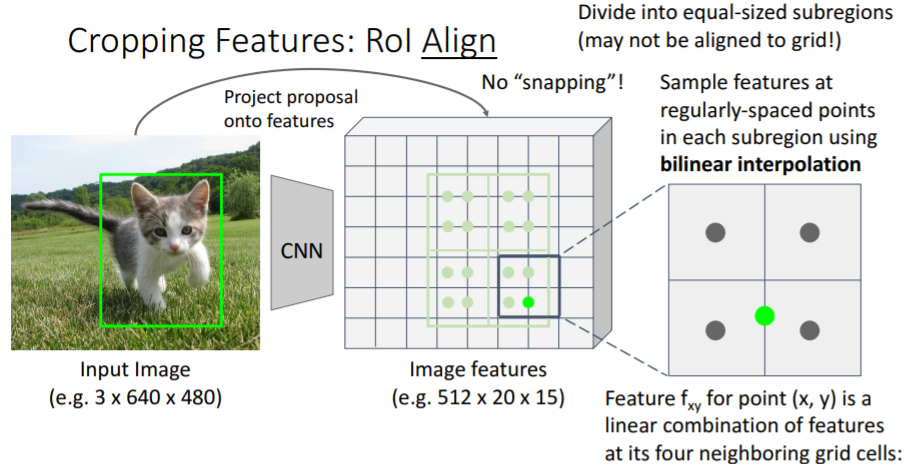
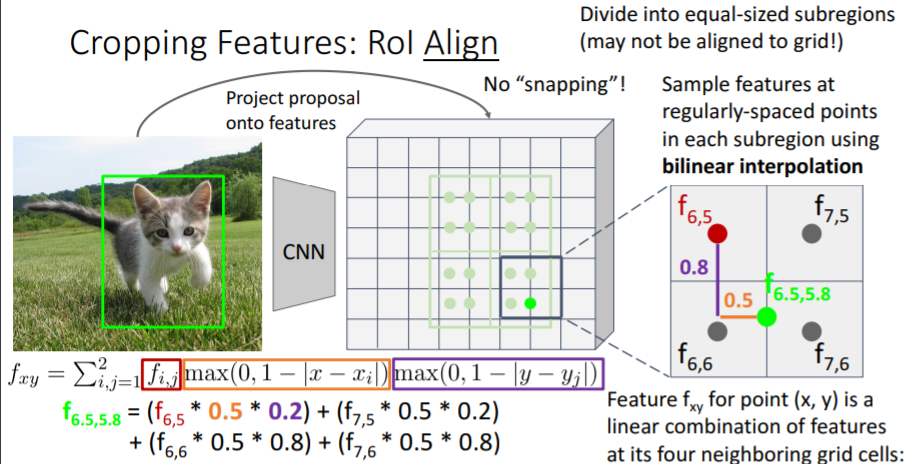
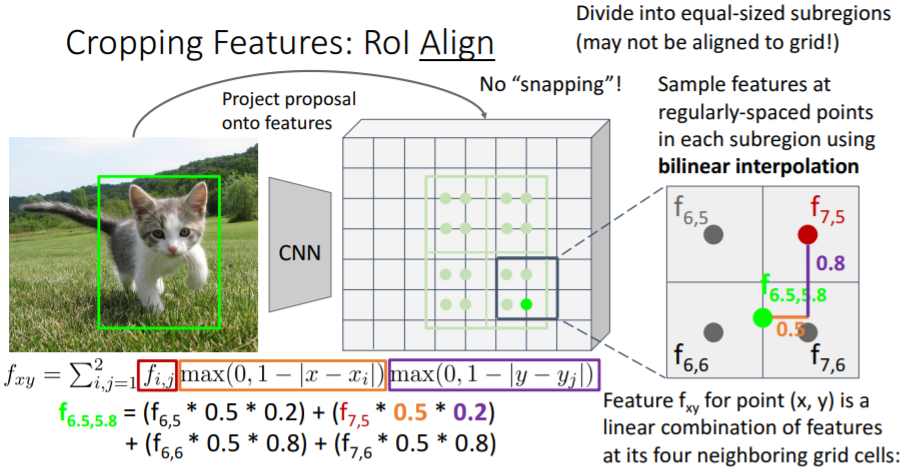
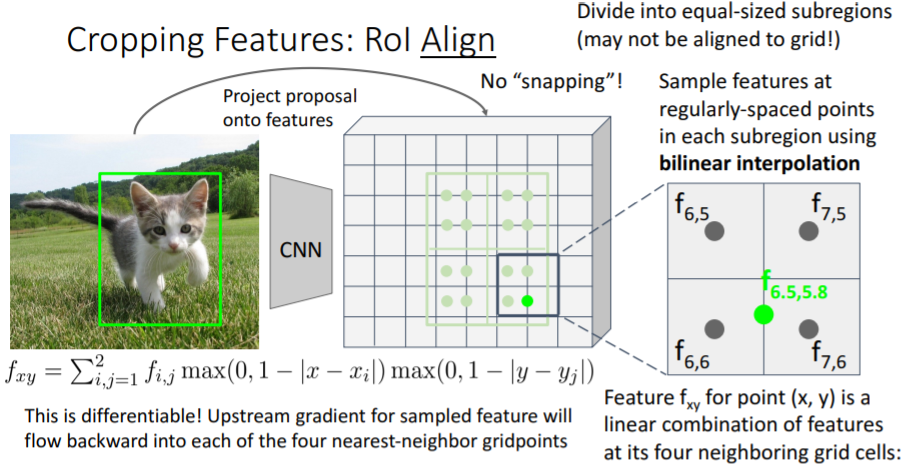
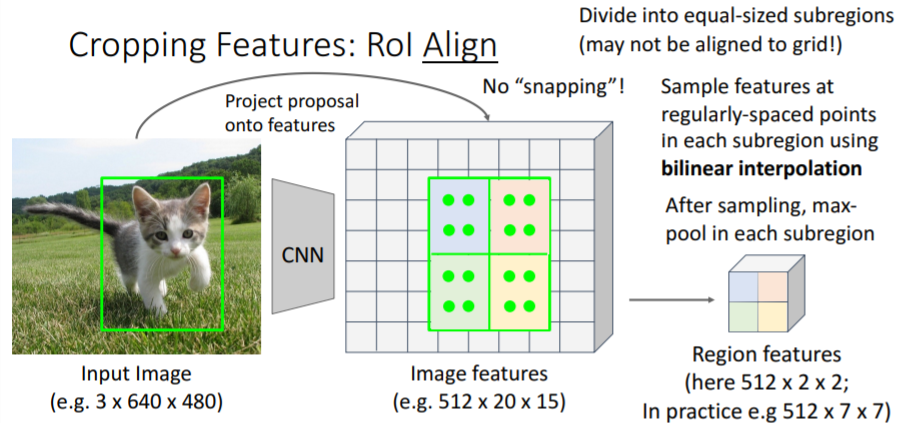
3.3) Cropping Features: RoI Align
위의 문제를 해결하기 위해 조금 더 복잡한 방식인 RoI Align을 사용하기도 한다.
그러나 강의에서는 넘어갔다. 강의자료만 넣어놓겠다.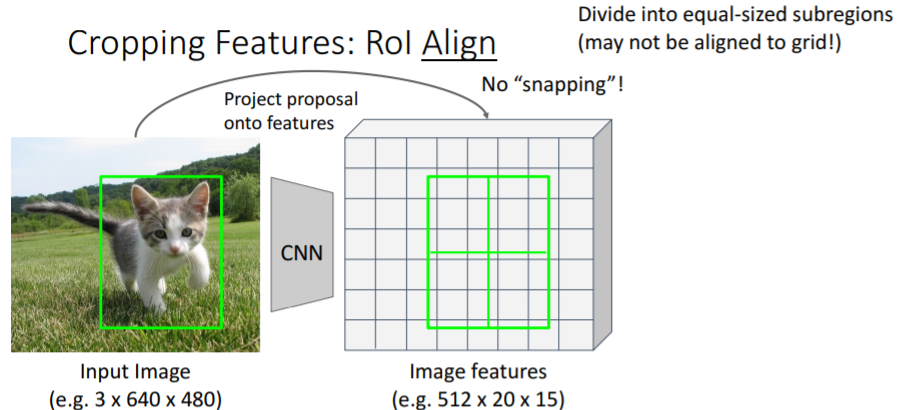
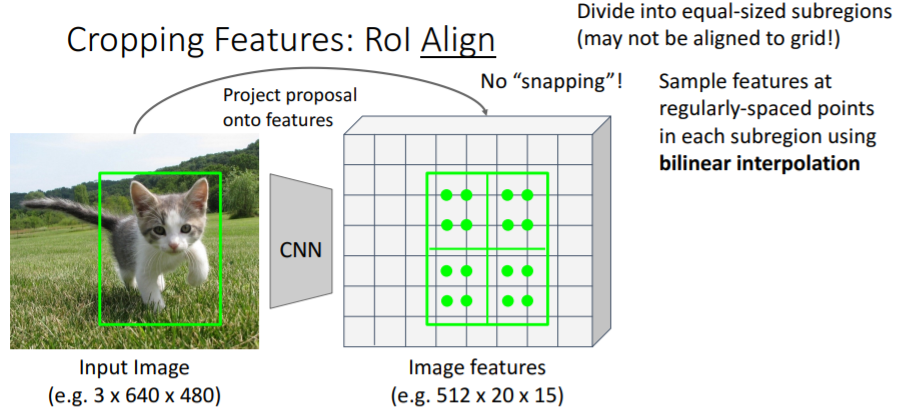
3.4) Fast R-CNN vs "Slow" R-CNN
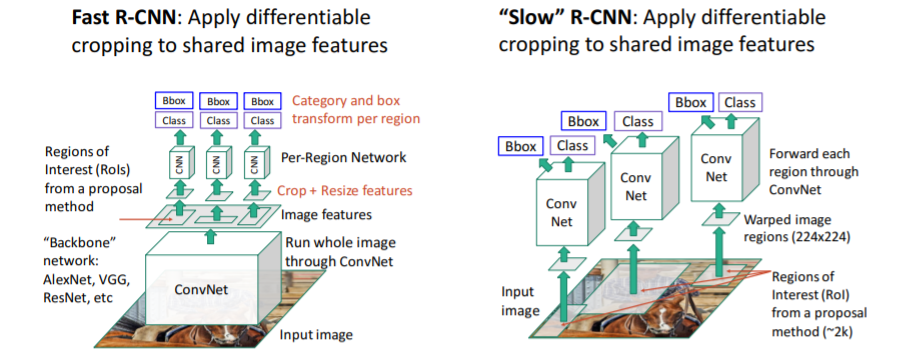 Fast R-CNN은 서로 다른 region proposals에 대하여 image features를 share하기 때문에 훨씬 빠르다.
Fast R-CNN은 서로 다른 region proposals에 대하여 image features를 share하기 때문에 훨씬 빠르다.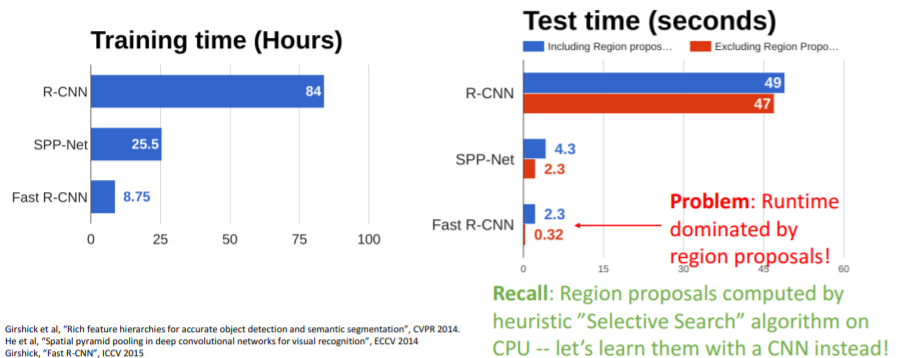 Fast R-CNN은 매우 빠른 속도를 갖지만 여전히 문제가 있다. Fast R-CNN에서 대부분의 시간(거의 90%)은 region proposals를 계산하는데 사용된다. CPU에서 계산되는 이 휴리스틱한 selective search 알고리즘 때문이다.
Fast R-CNN은 매우 빠른 속도를 갖지만 여전히 문제가 있다. Fast R-CNN에서 대부분의 시간(거의 90%)은 region proposals를 계산하는데 사용된다. CPU에서 계산되는 이 휴리스틱한 selective search 알고리즘 때문이다.
그래서 region proposals계산을 CNN에서 하도록 하는 방법이 필요하다.
4. Faster R-CNN: Learnable Region Proposals
4.1) 설명
Selective search를 사용해서 region proposals를 계산하지 않고 CNN에서 region proposals를 predict할 수 있도록 CNN을 학습시킨다.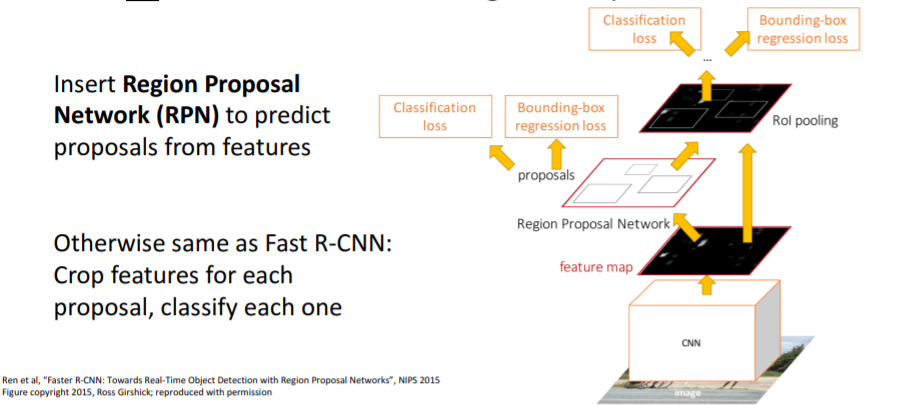 Fast R-CNN에서와 같은 backbone network를 통과시킨 후
Fast R-CNN에서와 같은 backbone network를 통과시킨 후 Region Proposal Network (RPN)이라는 또 다른 작은 네트워크를 추가한다. 이는 region proposals를 predict할 수 있다.
backbone network를 통과시켜 나온 feature map을 RPN에 통과시켜 region proposals를 predict하고, 뽑은 region proposals를 가지고 Fast R-CNN에서 했던 것과 모두 같은 방식으로 나머지 과정을 처리한다.
Fast R-CNN과의 차이는 RPN밖에 없다.
4.2) Region Proposal Network (RPN)
 Fast R-CNN에서처럼 backbone network에 통과시켜 feature map을 얻는다.
Fast R-CNN에서처럼 backbone network에 통과시켜 feature map을 얻는다.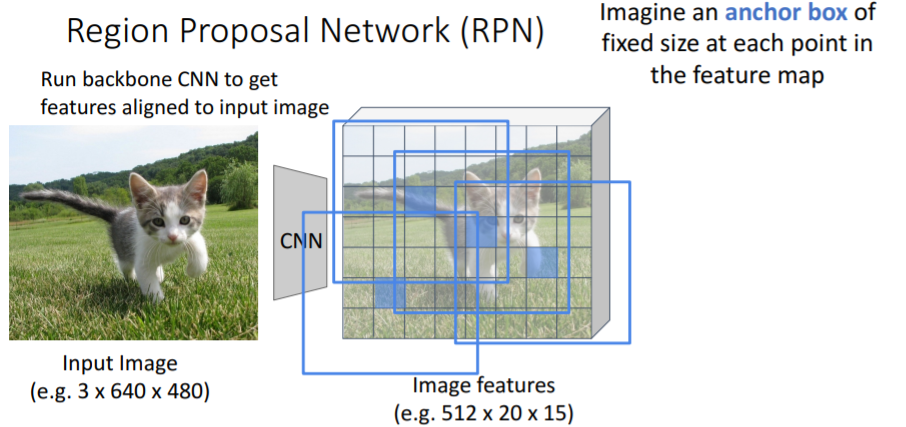 그리고 고정된 사이즈의 anchor box을 feature map의 모든 point에 사용한다.
그리고 고정된 사이즈의 anchor box을 feature map의 모든 point에 사용한다.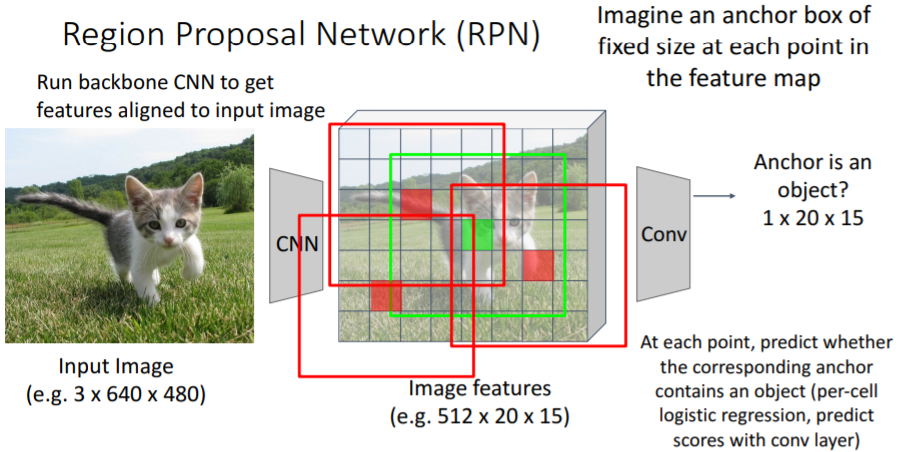 각 anchor box들에서 이들 anchor box들이 object를 포함하는지 안하는지 CNN을 통해 binary classify한다.
각 anchor box들에서 이들 anchor box들이 object를 포함하는지 안하는지 CNN을 통해 binary classify한다.
그러나 이러한 anchor box는 이미지 내의 object에 poor하게 fit될 것이다. 따라서 box transforms을 사용한다.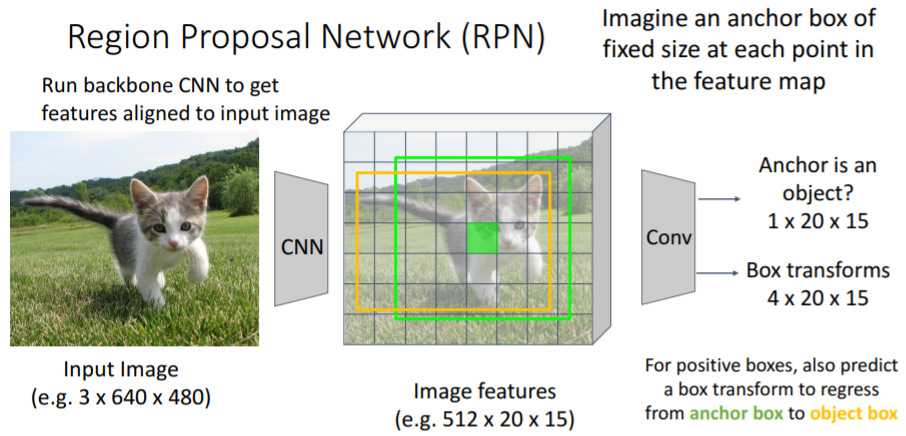 positive boxes에 대해 box transform 또한 predict하여 anchor box를 proposal box로 regression시킨다.
positive boxes에 대해 box transform 또한 predict하여 anchor box를 proposal box로 regression시킨다.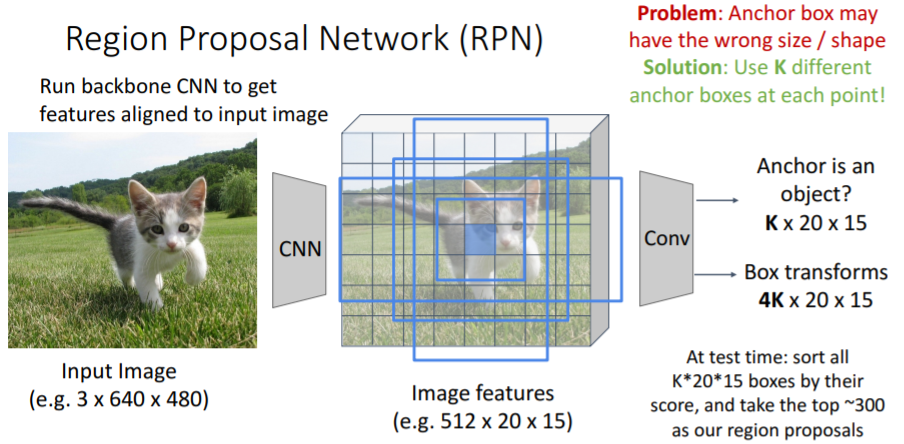 하나의 고정된 사이즈의 anchor box만을 사용하면 모든 종류의 object에 잘 fit하기에 충분하지 않다. 따라서 대신에 K개의 서로 다른 anchor boxes(다른 크기, 다른 가로세로 비율)를 각 feature map point에서 사용한다.
하나의 고정된 사이즈의 anchor box만을 사용하면 모든 종류의 object에 잘 fit하기에 충분하지 않다. 따라서 대신에 K개의 서로 다른 anchor boxes(다른 크기, 다른 가로세로 비율)를 각 feature map point에서 사용한다.
4.3) 4 Losses
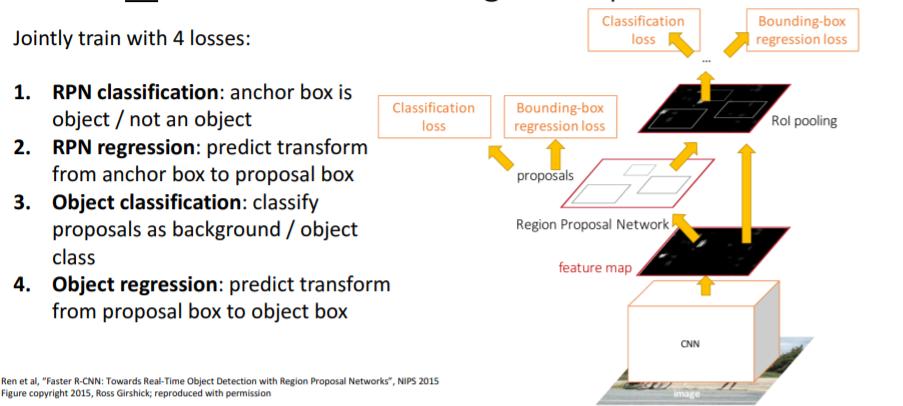 위와 같이 4개의 Loss가 존재하고 이들을 통해 학습한다.
위와 같이 4개의 Loss가 존재하고 이들을 통해 학습한다.
- RPN classification Loss : anchor box가 object를 포함하는지 안하는지
- RPN regression Loss : anchor box를 proposal box로 regress시키는 transforms를 학습
- Object classification Loss : background / objects 의 class를 분류
- Object regression Loss : proposal box를 최종 object box로 regress시키는 transforms를 학습
4.4) 성능
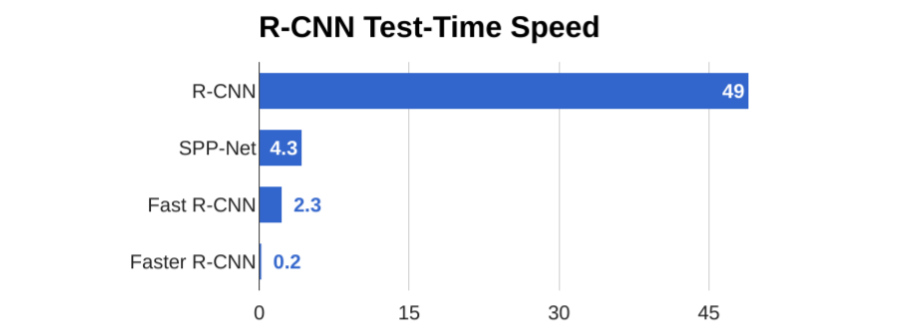 매우 빠른 것을 볼 수 있다.
매우 빠른 것을 볼 수 있다.
4.5) Single-Stage Object Detection
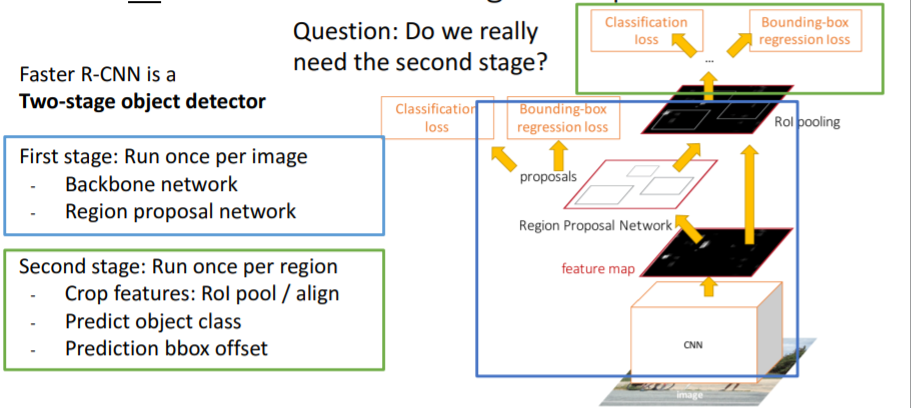 Faster R-CNN은 위 그림처럼 Two-stage object detector이다.
Faster R-CNN은 위 그림처럼 Two-stage object detector이다.
그런데 정말로 이렇게 두개의 stage로 나눌 필요가 있을까? 첫번째 stage에게 모든것을 시킬 수는 없을까?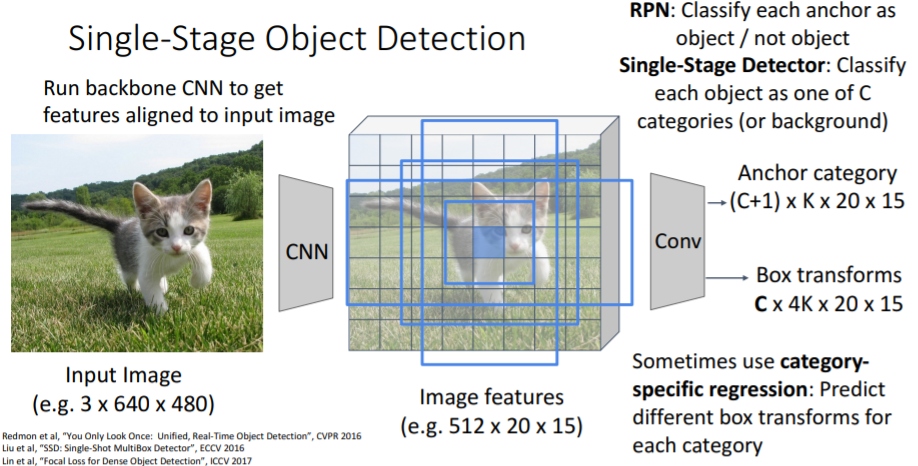 기존 Faster R-CNN의 첫번째 stage (RPN)에서 각 anchor box에 대해 object를 포함하는지/안하는지 binary classify한 것 대신에 여기에서 모든 카테고리에 대해 full classify한다.
기존 Faster R-CNN의 첫번째 stage (RPN)에서 각 anchor box에 대해 object를 포함하는지/안하는지 binary classify한 것 대신에 여기에서 모든 카테고리에 대해 full classify한다.
각 anchor box를 C개의 카테고리 + background로 분류한다. 이는 CNN을 통해 진행한다.
때때로 카테고리별로 다른 box transforms를 학습하는 category-specific regression을 사용하기도 한다.
5. Object Detection: Lots of variables!
Object detection은 매우매우 복잡하고 task에 따라 매우 매우 많은 choices가 있다. 그리고 매우 많은 hyperparameter이 있다.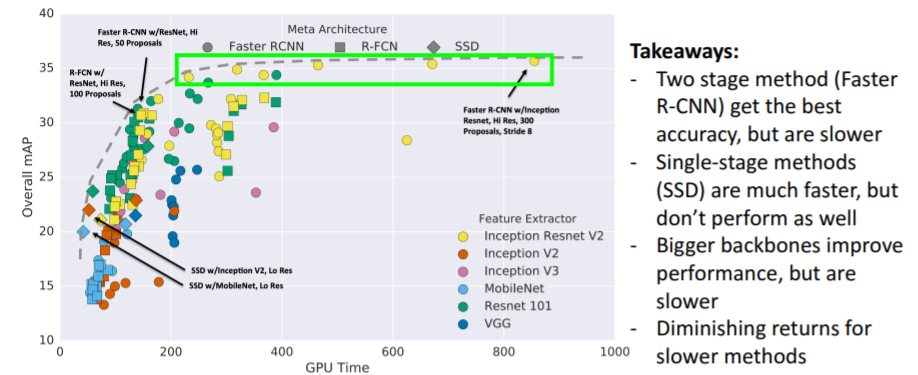 다양한 detection 방식이 존재하고 이에 대한 Takeaways이다.
다양한 detection 방식이 존재하고 이에 대한 Takeaways이다. 2017년 이후에 성능 향상을 위한 새로운 방식들이 또 등장하였다.
2017년 이후에 성능 향상을 위한 새로운 방식들이 또 등장하였다.
Huang et al, “Speed/accuracy trade-offs for modern convolutional object detectors”, CVPR 2017
5.1) Open-Source Code
A5 과제를 하는게 아니라면 오픈소스를 사용하도록...
-
TensorFlow Detection API:
https://github.com/tensorflow/models/tree/master/research/object_detection
Faster R-CNN, SSD, RFCN, Mask R-CNN -
Detectron2 (PyTorch):
https://github.com/facebookresearch/detectron2
Fast / Faster / Mask R-CNN, RetinaNet
Summary