[EECS 498-007 / 598-005] 강의정리 - 16강 Detection and Segmentation
[CS231n] + [EECS 498-007 / 598-005]

Detection (part2) and Segmentation
- Training R-CNN
1.1) "Slow" R-CNN
1.2) Fast R-CNN
1.3) Faster R-CNN - Cropping Features
2.1) RoI Align - Detection without Anchors: CornerNet
- Semantic Segmentation
4.1) Semantic Segmentation Idea: Sliding Window
4.2) Semantic Segmentation: Fully Convolutional Network
4.3) In-Network Upsampling: “Unpooling”
4.4) In-Network Upsampling: Bilinear Interpolation
4.5) In-Network Upsampling: Bicubic Interpolation
4.6) In-Network Upsampling: “Max Unpooling”
4.7) Learnable Upsampling: Transposed Convolution - Instance Segmentation
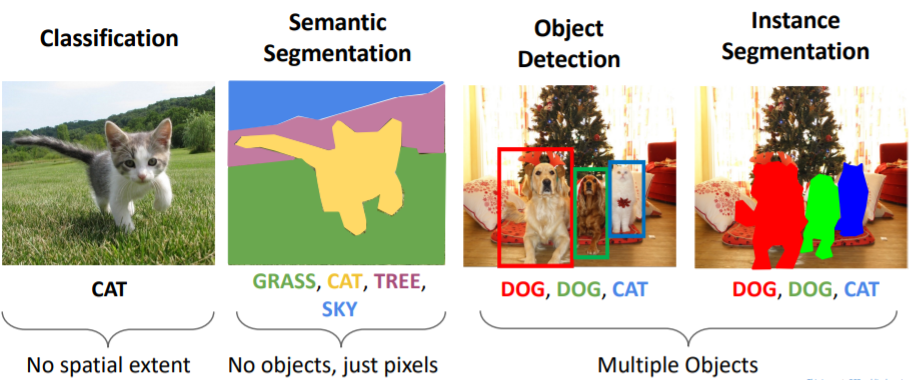
5.1) Computer Vision Tasks
5.2) Computer Vision Tasks: Instance Segmentation
5.3) Mask R-CNN - Panoptic Segmentation
6.1) Beyond Instance Segmentation
6.2) Beyond Instance Segmentation: Panoptic Segmentation - Human Keypoints
7.1) Mask R-CNN
7.2) Joint Instance Segmentation and Pose Estimation - General Idea: Add PerRegion “Heads” to Faster / Mask R-CNN!
8.1) Dense Captioning: Predict a caption per region!
8.2) 3D Shape Prediction: Predict a 3D triangle mesh per region!
Summary
1. Training R-CNN
1.1) "Slow" R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation
사실 강의를 봐도 아주 자세히 이해하기 힘들어서 논문을 보고 공부해야 알 것 같다. 시간나면 공부해보는걸로..
근데 R-CNN을 굳이 봐야되나..?
지난 강의에 이어서 설명되는 부분이다. training time에서 어떻게 진행되는지 설명한다.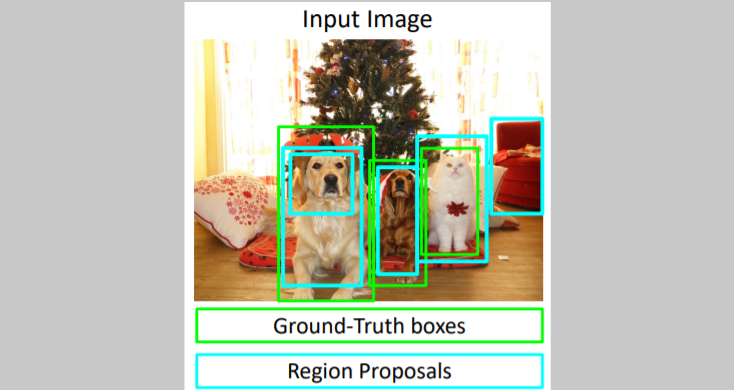 우선 input image(train이므로 GT boxes와 각 boxes의 class가 주어진다)가 들어온다. 그리고 selective search를 통해 region proposals를 구한다.
우선 input image(train이므로 GT boxes와 각 boxes의 class가 주어진다)가 들어온다. 그리고 selective search를 통해 region proposals를 구한다. 각 interation마다 region proposals이
각 interation마다 region proposals이 positive인지 negative인지 neutral인지 GT boxes와 비교하여 결정한다.
위 그림에서 초록색 box는 GT boxes이고, region proposals와 비교하여 IoU를 계산한다. 그리고 positive, negative, neutral을 분류한다. 오른쪽 빨간 region proposals는 GT boxes와 비교하여 IoU<0.3 이었기 때문에 negative이며, 이는 그 region안에 object가 없다는 뜻이다. 그리고 neutral은 GT boxes의 부분으로 negative는 아니지만 positive가 되기에는 너무 멀다고 판단되는 region proposal이다.
0.3값은 hyper parameter로, cross validation으로 설정한다.
train과정에서는 neutral로 분류된 boxes를 무시한다. 그리고 positive와 negative에 대해서만 학습한다. 그리고
그리고 positive와 negative인 region proposals들을 crop하고 224x224 사이즈로 resize한다. 그리고 각 region proposals를 CNN에 통과시켜 output을 계산한다.
그리고 각 region proposals를 CNN에 통과시켜 output을 계산한다.
positive boxes에 대해서는 class target과 box transform을 output으로 출력하고
negative boxes에 대해서는 class target만 output으로 출력한다. target box로 regress시킬 필요가 없기 때문이다.
positive boxes는 각각에 맞는(paired) GT boxes로 regress된다.
1.2) Fast R-CNN
Fast R-CNN paper
 R-CNN에서 GT boxes와 region proposals와 IoU로 비교하여
R-CNN에서 GT boxes와 region proposals와 IoU로 비교하여 positive, negative, neutral로 분류하는 과정과 이후 class target, box transform을 output으로 출력하는 것은 동일하다.
다른 것은 warping과 CNN의 순서를 바꾼 것뿐.
1.3) Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
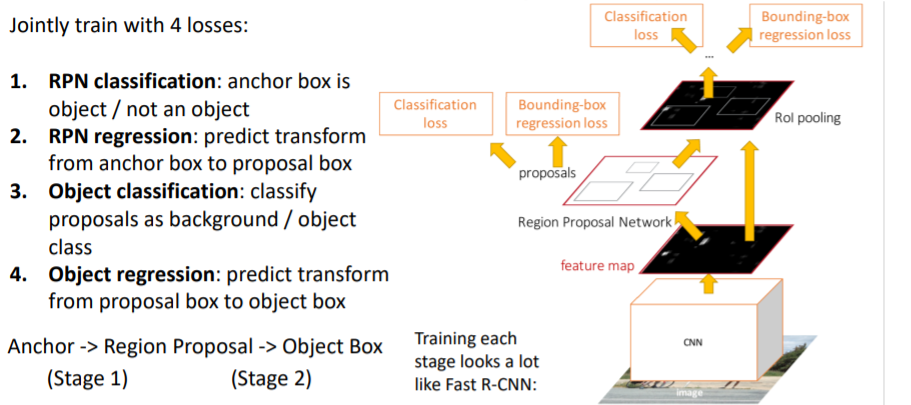 Faster R-CNN에서는 2 stages가 존재한다.
Faster R-CNN에서는 2 stages가 존재한다.
Stage 1
- 전체 이미지에서 fixed size의 anchor boxes 생성한다.
- boxes를 region proposal boxes로 transform시킨다.(regress시킨다)
Stage 2
- region proposals를 최종 output boxes로 transform시킨다.
 우선 fixed size의 anchor boxes가
우선 fixed size의 anchor boxes가 positive, negative, neutral인지 분류한다. 그리고 positive와 negative만을 사용한다. 이 부분은 R-CNN, Fast R-CNN에서와 동일하다.
그러나 다른 점은 기존에는 selective search를 통해 region proposals를 뽑아냈지만, 여기서는 hyperparameter로 설정한대로 fixed size anchor boxes를 사용한다. 또한 RPN에서는 binary classification 을 진행한다.(object인지 아닌지) 그리고 RPN을 통해 얻은 region proposals를 가지고 학습하는 Stage 2는 Fast R-CNN과 동일하다.
그리고 RPN을 통해 얻은 region proposals를 가지고 학습하는 Stage 2는 Fast R-CNN과 동일하다.
RPN Loss Function
RPN은 각 anchor box마다 binary classification을 수행한다.(object가 있는지 없는지) 이를 분류하기 위해서는 anchor box에 positive label이 있어야 한다. positive label은
- GT box와 IoU가 0.7이 넘는 anchor box
- 1번을 만족하는 box가 없다면 GT와 IoU가 가장 큰 anchor box
를 통해 부여한다. 그리고 negative label은
- IoU가 0.3보다 작은 anchor box이다.
neutral은 제외한다.
그리고 Loss function은
이다.
- 는 번째 anchor box가 object일 확률
- 는 anchor box가 positive이면 1, negative(배경)이면 0
- 는 object/!object에 대한 로그 손실
2. Cropping Features
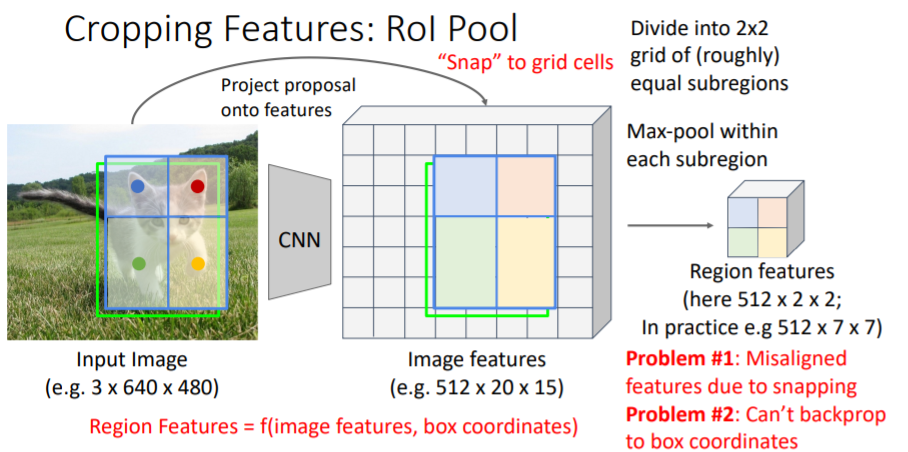 지난 강의에서
지난 강의에서 RoI Pool이라는 방법을 다루었었다. 그러나 문제점이 있었다.
2.1) RoI Align
위의 문제를 해결하기 위해 snapping을 삭제한다.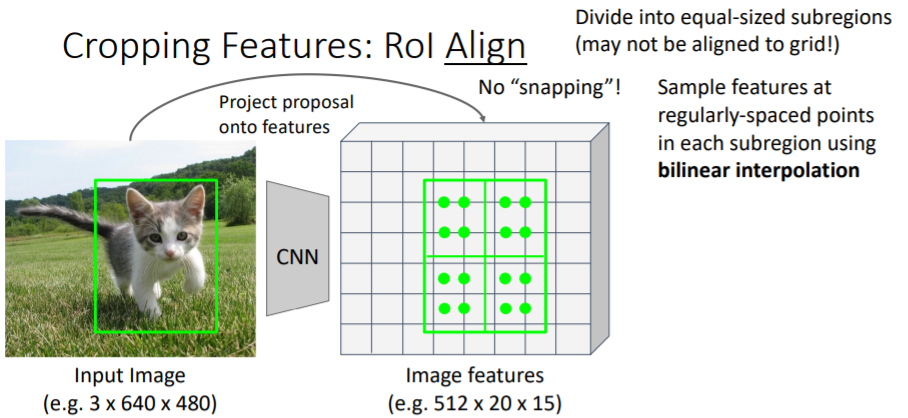 우선 region proposals를 feature grid에 project시킨다. 여기에서 snapping시키는 대신에 projected region proposal을 같은 사이즈의 sub regions로 나누고 각 regions에서 같은 수의 samples를 추출한다.
우선 region proposals를 feature grid에 project시킨다. 여기에서 snapping시키는 대신에 projected region proposal을 같은 사이즈의 sub regions로 나누고 각 regions에서 같은 수의 samples를 추출한다.
그러나 snapping을 하지 않았기 때문에 feature grid에 맞지 않는 문제가 발생한다. 이를 해결하기 위해 bilinear interpolation을 사용하여 grid 사이를 채운다.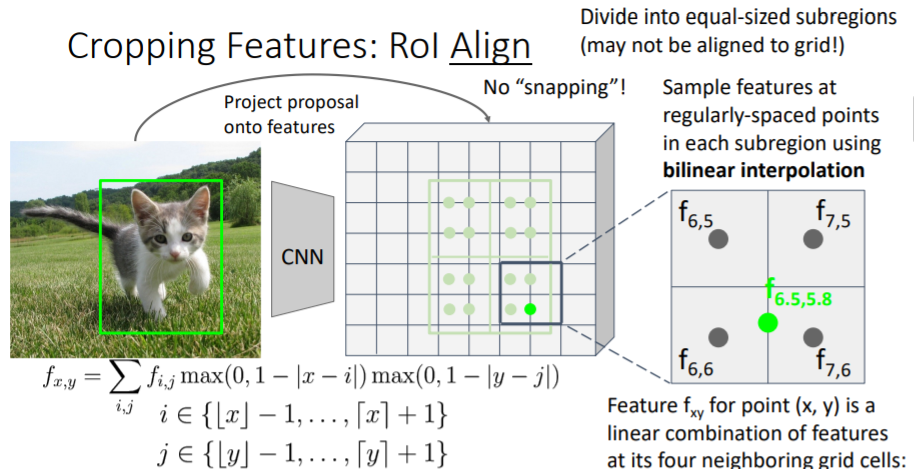 오른쪽 아래의 sub region을 살펴보자. 여기에서 우리는 4개의 samples를 추출하려고 한다.
오른쪽 아래의 sub region을 살펴보자. 여기에서 우리는 4개의 samples를 추출하려고 한다.
그 중 오른쪽 아래의 sample은 실제 좌표값 을 갖는다. 따라서 가까운 4개의 grid cell의 feature값을 사용하여 interpolate한다. 거리에 따라 weight를 주는 방식으로 feature값을 sum한다. 과정은 아래와 같다.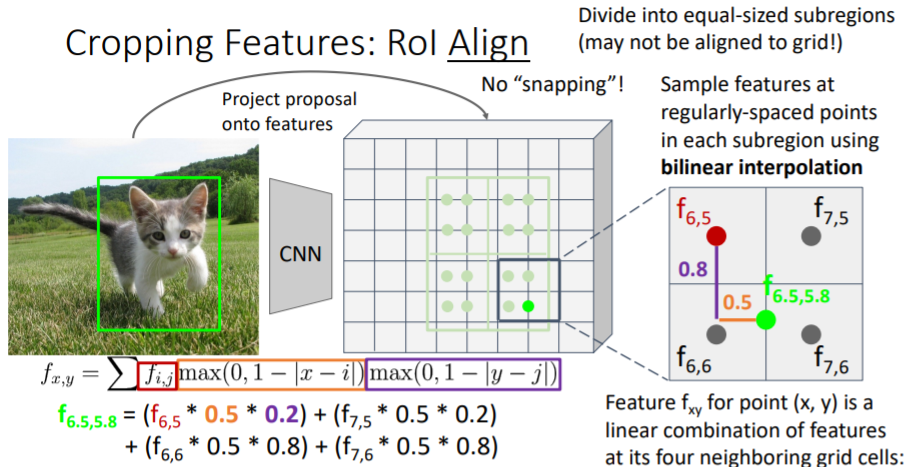
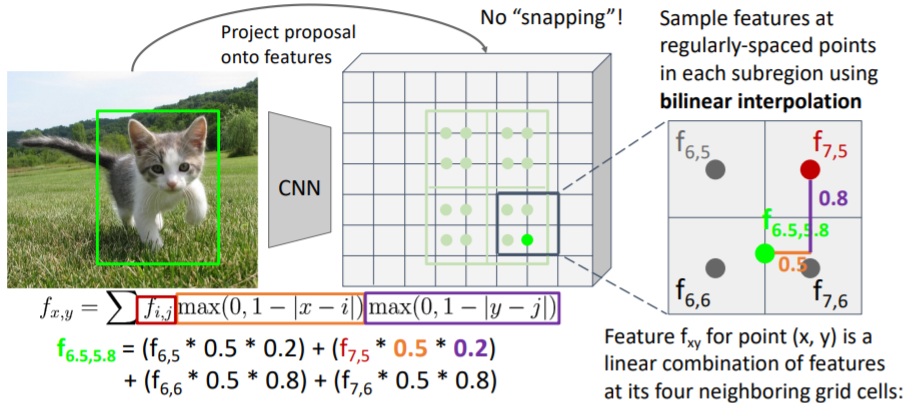
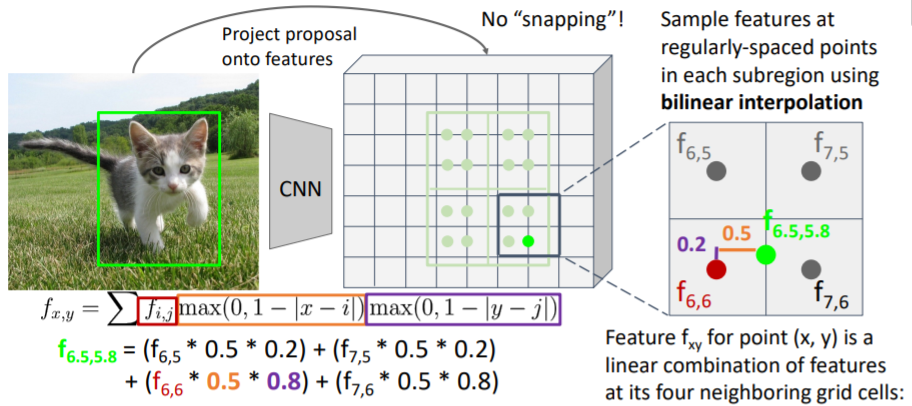
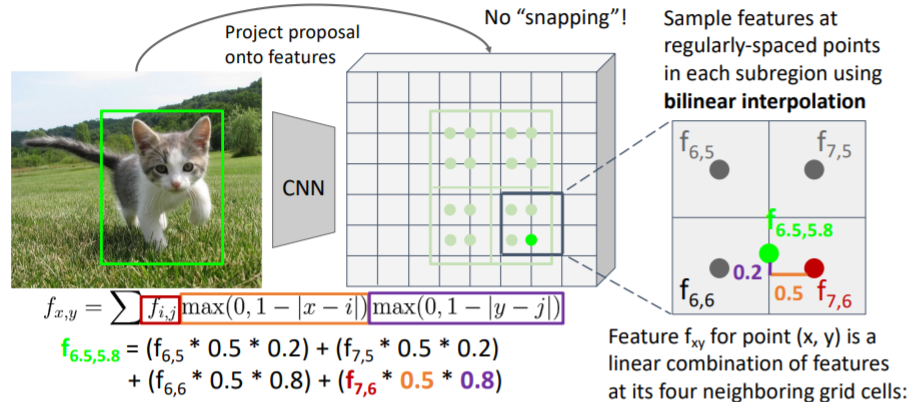 이는 미분 가능하기 때문에 backprop이 가능하다.(정확한 좌표값으로)
이는 미분 가능하기 때문에 backprop이 가능하다.(정확한 좌표값으로)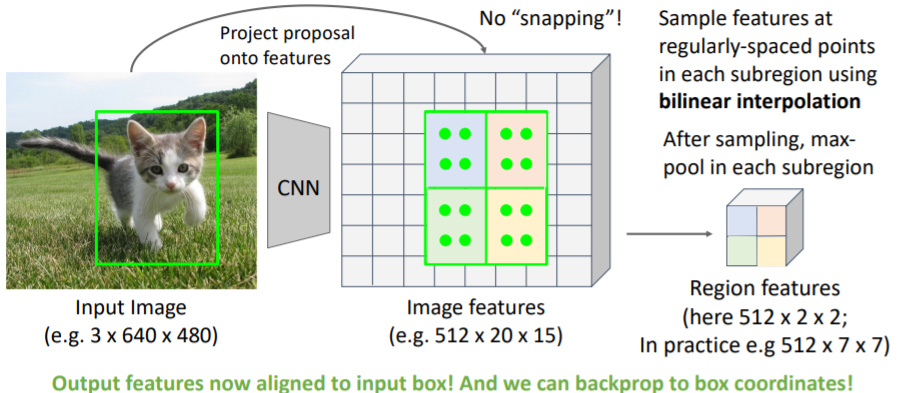
 그리고 각 sub region을 max-pool하여
그리고 각 sub region을 max-pool하여 region features를 구한다.
This is differentiable! Upstream gradient for sampled feature will flow backward into each of the four nearest-neighbor gridpoints
Output features now aligned to input box! And we can backprop to box coordinates!
snapping되지 않았기 때문에 실제 input 이미지에서의 input box 좌표로 backprop이 가능하다.
이거 assignment 5에서 구현해야된다고 함.. 강의 다 듣고 과제 해보려고 했는데 무섭다 ㄷ ㄷ
3. Detection without Anchors: CornerNet
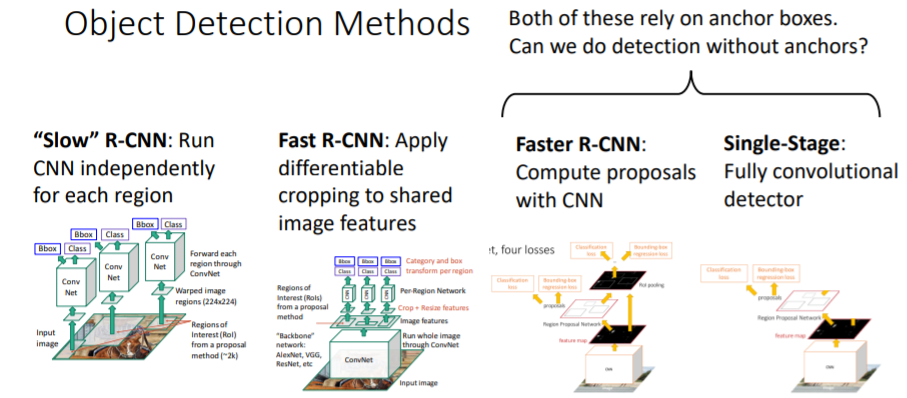 Faster R-CNN과 Single-stage는 여전히 anchor boxes에 의존한다.
Faster R-CNN과 Single-stage는 여전히 anchor boxes에 의존한다.
그렇다면 anchor box없이 detection을 진행할 수 있을까?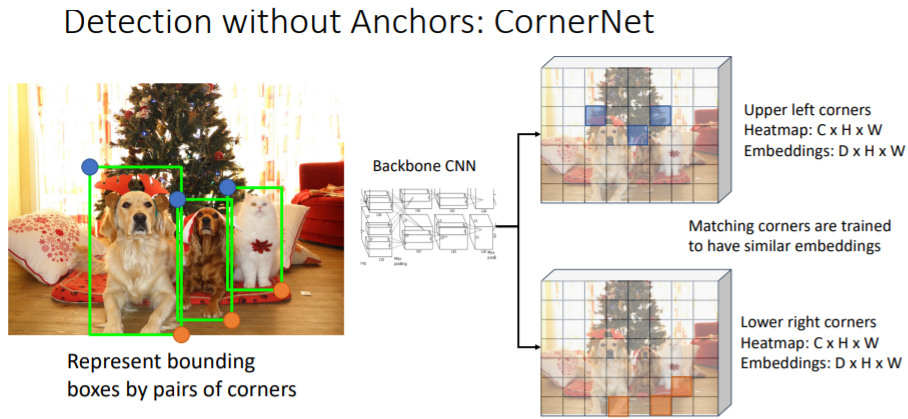 bounding boxes를
bounding boxes를 왼쪽 위(upper left corner), 오른쪽 아래(lower right corner)의 point pair로 표현한다.
어떤 pixel이 upper left corner point로 적합한지에 대한 확률,
어떤 pixel이 lower right corner point로 적합한지에 대한 확률을 살핀다.
자세한 내용은 설명하지 않았다.
CornerNet: Detecting Objects as Paired Keypoints 논문
자세한 내용은 여기에서.
4. Semantic Segmentation
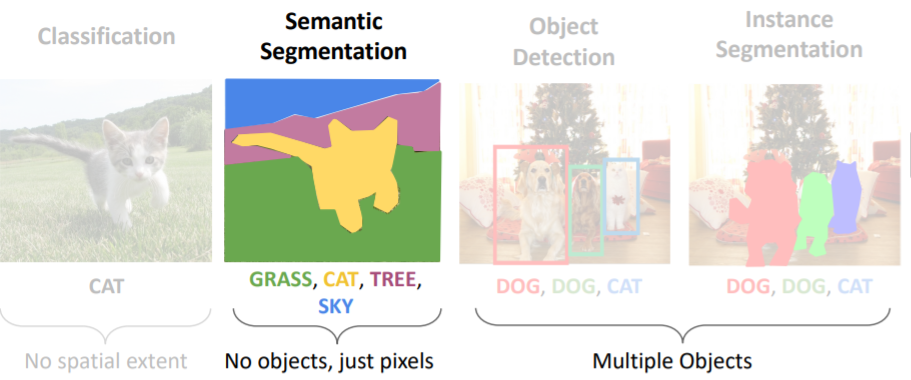
 semantic segmentation에서 우리가 하고 싶은 것은 이미지의 모든 pixel을 카테고리 레이블로 라벨링 하는 것이다. 인스턴스를 구분하는 것이 아니라 그저 pixel에만 집중한다. 예를 들어 오른쪽 그림에서 두 마리의 소를 따로 구분하여 감지하지 않는다.
semantic segmentation에서 우리가 하고 싶은 것은 이미지의 모든 pixel을 카테고리 레이블로 라벨링 하는 것이다. 인스턴스를 구분하는 것이 아니라 그저 pixel에만 집중한다. 예를 들어 오른쪽 그림에서 두 마리의 소를 따로 구분하여 감지하지 않는다.
4.1) Semantic Segmentation Idea: Sliding Window
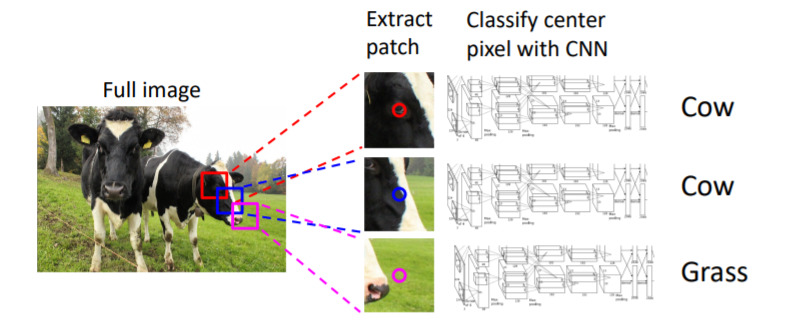 이미지의 각 픽셀에 대해 주변부를 포함한 작은 patch를 추출한다. 그리고 이 patch를 CNN에 넣어 category label을 예측한다. 이를 반복한다.
이미지의 각 픽셀에 대해 주변부를 포함한 작은 patch를 추출한다. 그리고 이 patch를 CNN에 넣어 category label을 예측한다. 이를 반복한다.
Problem: Very inefficient! Not reusing shared features between overlapping patches
따라서 이 방식은 거의 사용하지 않는다.
4.2) Semantic Segmentation: Fully Convolutional Network
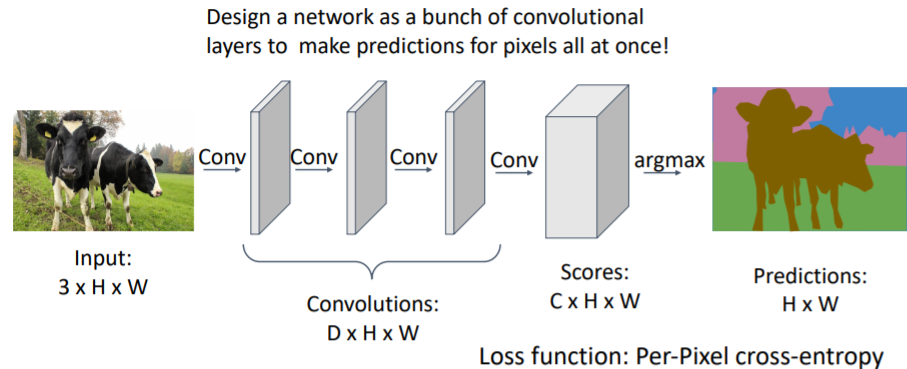 pooling layer등 없이 그저 Conv layer만 쌓여있는 Fully convolutional network를 사용한다.
pooling layer등 없이 그저 Conv layer만 쌓여있는 Fully convolutional network를 사용한다.
일정 크기의 input이미지를 넣으면 네트워크를 통과하여 나온 output은 input과 같은 크기의 분할된 이미지이다. 이때 C는 category label 개수이다.
그리고 마지막 scores layer은 각 픽셀마다 category label score을 갖는다. 각 픽셀에서 softmax를 사용하여 그 픽셀이 어떤 label인지 판단한다.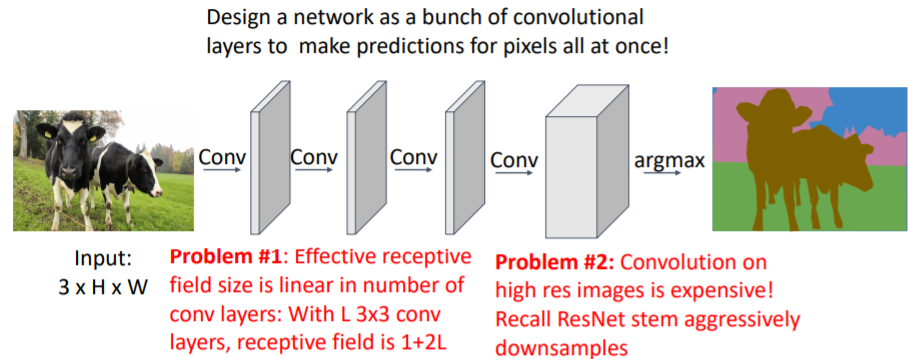 그러나 문제점이 존재한다.
그러나 문제점이 존재한다.
- 3x3, pad 1, stride 1인 conv layer을 계속 사용하여 쌓기 때문에 receptive field의 크기는 1+2L로 linear하게 증가한다. 따라서 input 이미지가 클 수록 더 깊은 conv layer가 필요하다.
- 고해상도 이미지에서 conv는 매우 비싸다.
따라서 downsampling이 필요하다.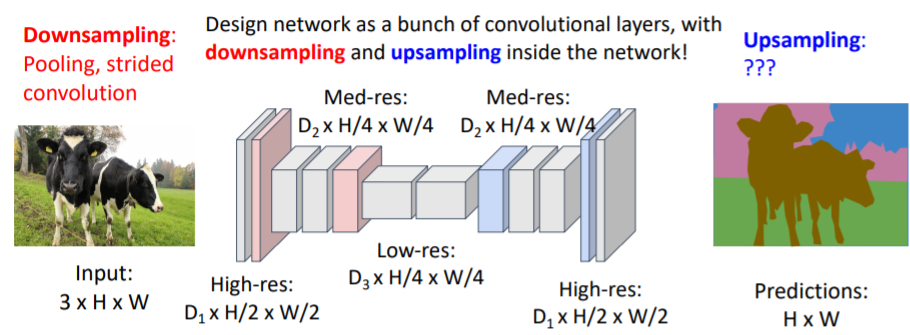 pooling과 stride 등을 사용하여
pooling과 stride 등을 사용하여 downsampling을 하게 되면 더 간단하게 큰 receptive field를 얻고, 계산 과정도 줄일 수 있다.
그렇다면 upsampling은 어떻게 하는가?
4.3) In-Network Upsampling: “Unpooling”
downsampling은 주로 pooling이라고 하기 때문에 upsampling은 unpooling이라고 한다.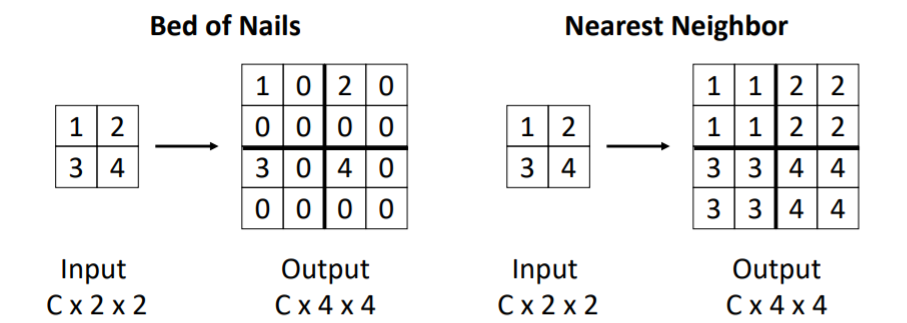
bed of nails방식은 aliasing문제 등으로 거의 사용하지 않는다.
4.4) In-Network Upsampling: Bilinear Interpolation
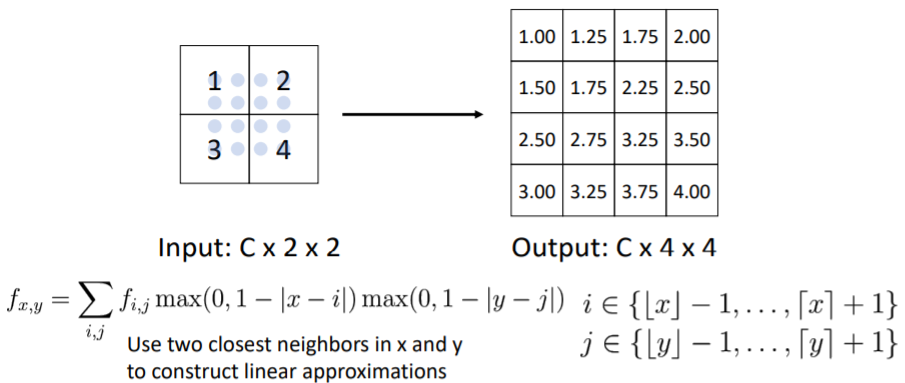
bilinear interpolation을 사용하여 upsampling을 하기도 한다. 이는 더 부드러운 upsampling을 가능하게 한다.
4.5) In-Network Upsampling: Bicubic Interpolation
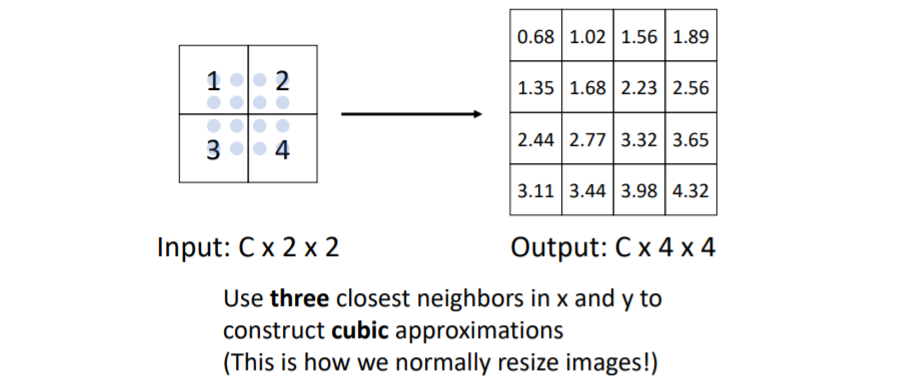 거의 다 이 방식을 사용한다.
거의 다 이 방식을 사용한다.
4.6) In-Network Upsampling: “Max Unpooling”
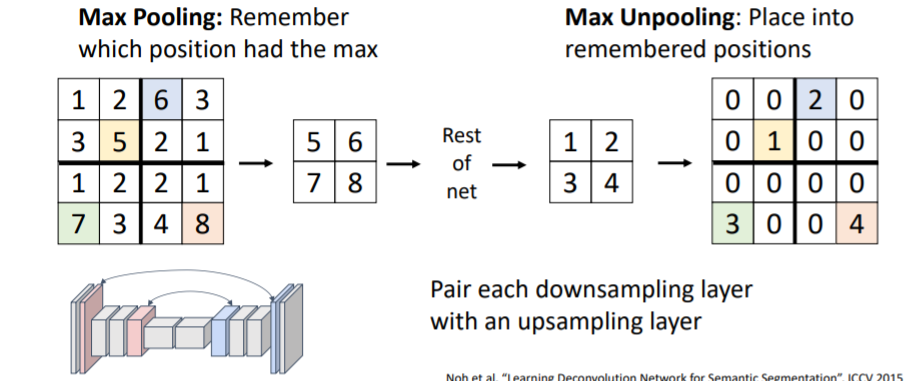 downsampling과 upsampling을 짝지어서 downsampling했던 좌표를 기억하여 그 자리에 다시 값을 넣어 upsampling시켜준다. 이는 max pooling으로 downsample한 경우에 적용 가능하다.
downsampling과 upsampling을 짝지어서 downsampling했던 좌표를 기억하여 그 자리에 다시 값을 넣어 upsampling시켜준다. 이는 max pooling으로 downsample한 경우에 적용 가능하다.
4.7) Learnable Upsampling: Transposed Convolution
앞서 설명한 upsampling방식들은 fixed function으로 학습가능하지 않다. Transposed Convolution은 learnable 방법으로 때때로 사용한다고 한다.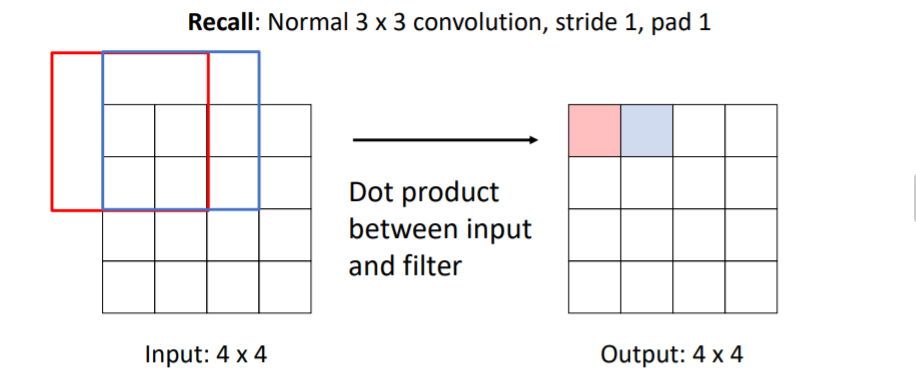 우선 convolution과정을 살펴보자. 기본적인 3x3, stride 1, pad 1인 conv filter을 사용하면 위와 같고,
우선 convolution과정을 살펴보자. 기본적인 3x3, stride 1, pad 1인 conv filter을 사용하면 위와 같고,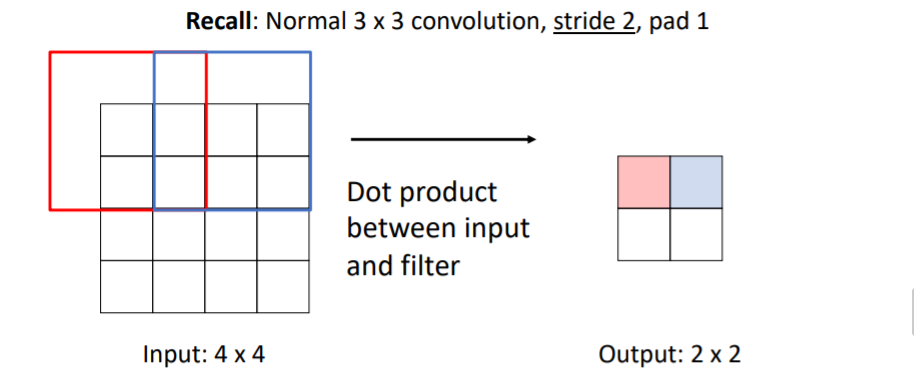 3x3, stride 2, pad 1를 사용하면 위와 같다.
3x3, stride 2, pad 1를 사용하면 위와 같다.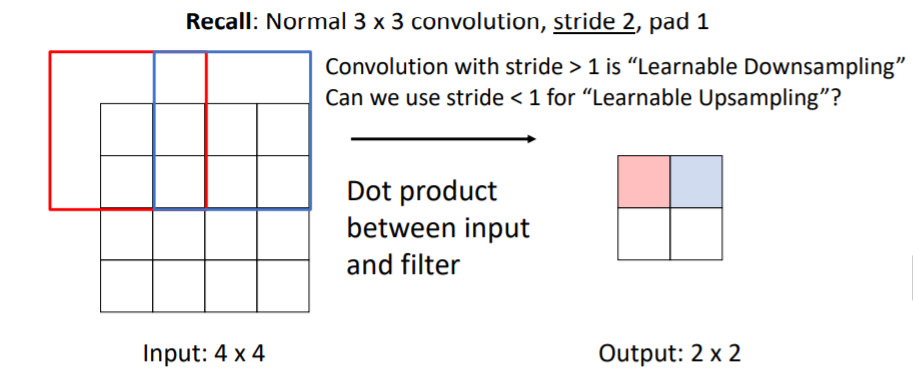 보통 conv filter를 stride > 1을 사용하면 Learnable Downsampling을 수행한다.
보통 conv filter를 stride > 1을 사용하면 Learnable Downsampling을 수행한다.
그렇다면 stride < 1을 사용하면 Learnable Upsampling을 할 수 있을까?
이 방법이 convolution transpose이다.
a. Transposed Convolution 설명
말이 stride < 1이지 사실 그냥 upsampling하면서 동일한 pixel을 여러번 겹치게 sliding하면서 채워나간다? 이런 의미인 것 같다. 아래 설명을 보면 느낌이 올 것이다.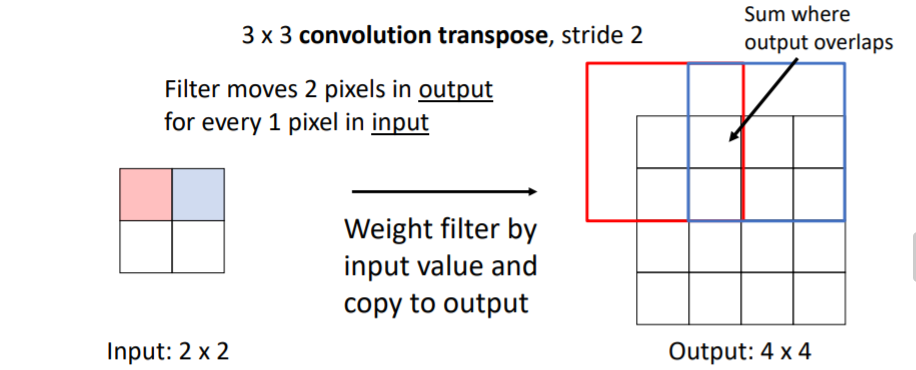 downsampled된 input이 주어지면 pixel을 하나씩 sliding한다. 이 input의 1pixel 값을 input value라고 하자.
downsampled된 input이 주어지면 pixel을 하나씩 sliding한다. 이 input의 1pixel 값을 input value라고 하자.
위 그림에서 우리는 3x3 convolution transpose, stride 2인 filter을 사용하기로 했기 때문에 이 3x3 filter에 있는 각각의 9개의 weight와 input value를 곱하여 4x4의 output의 알맞은 위치에 복사한다.
filter끼리 겹치는 곳은 겹치는 값들의 합으로 넣는다.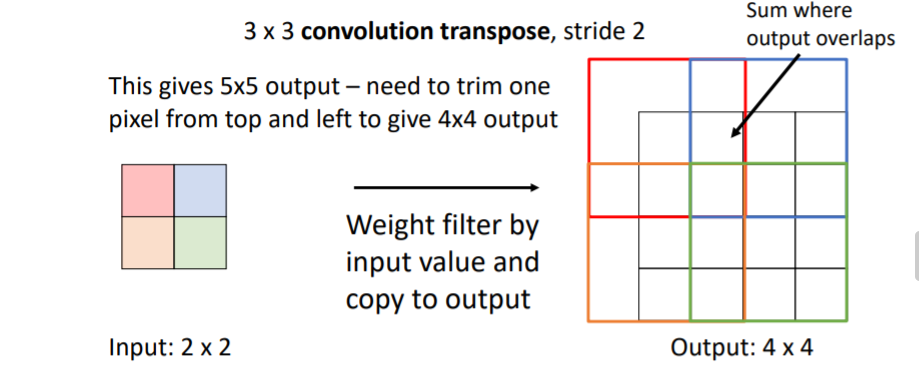
b. Transposed Convolution: 1D example
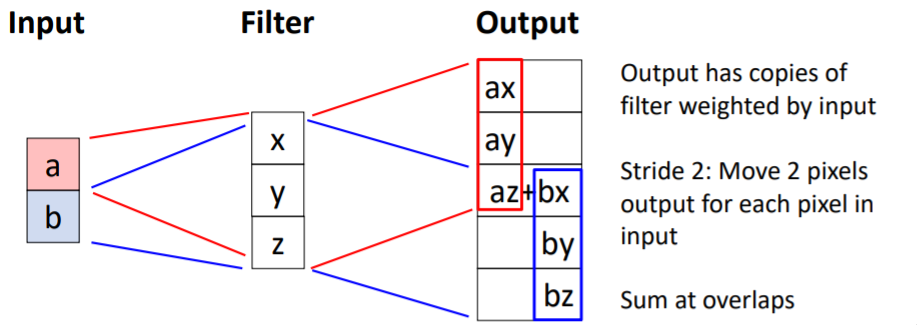 input으로 2x1의 벡터가 주어지고 3x1의 filter을 적용했다고 해보자. 그러면 output은 input value와 filter weight의 곱이 알맞은 위치에 복사되고 겹치는 부분은 그들의 합으로 값을 갖게 된다.
input으로 2x1의 벡터가 주어지고 3x1의 filter을 적용했다고 해보자. 그러면 output은 input value와 filter weight의 곱이 알맞은 위치에 복사되고 겹치는 부분은 그들의 합으로 값을 갖게 된다.
c. Convolution as Matrix Multiplication (1D Example)
Transposed convolution이라는 이름이 붙여진 이유가 등장한다. 기본적인 convolution 연산은 위와 같이 matrix multiplication으로 나타낼 수 있다.
기본적인 convolution 연산은 위와 같이 matrix multiplication으로 나타낼 수 있다.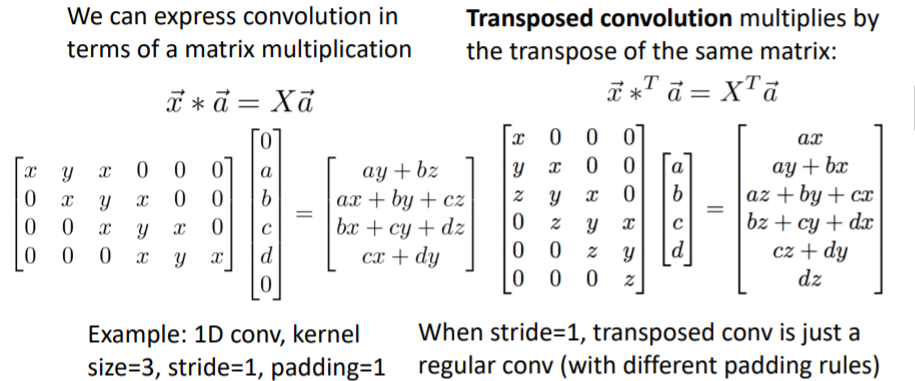 그리고 transposed convolution은 오른쪽 계산과 같이 기존 conv에서 transpose를 시킨 뒤 같은 연산을 수행하는 것과 같다.
그리고 transposed convolution은 오른쪽 계산과 같이 기존 conv에서 transpose를 시킨 뒤 같은 연산을 수행하는 것과 같다.
즉 stride=1인 경우에는 기본 conv와 transposed conv는 수학적으로 동일한 연산이다. 만약 stride > 1인 경우의 예시를 보면 아래와 같다.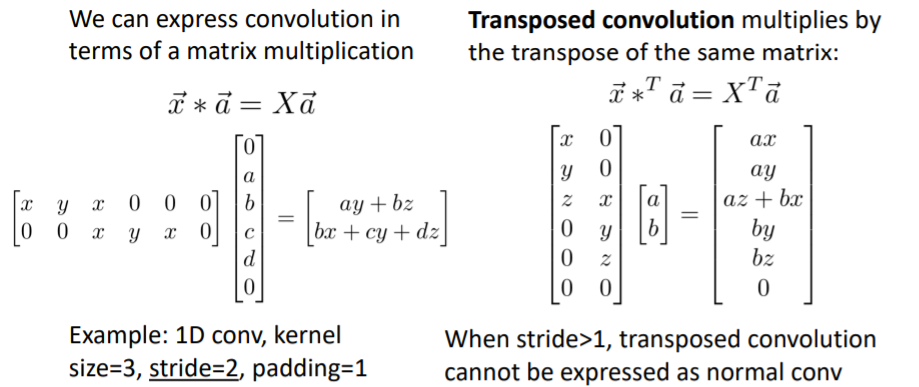 이 연산이 좋은 이유는 만약 transposed convolution 의 연산으로 forward pass를 수행했다면, backward pass는 기본 conv연산 이 된다.
이 연산이 좋은 이유는 만약 transposed convolution 의 연산으로 forward pass를 수행했다면, backward pass는 기본 conv연산 이 된다.
5. Instance Segmentation
5.1) Computer Vision Tasks
 지금까지 object detection, semantic segmentation 두가지의 computer vision tasks를 보았다.
지금까지 object detection, semantic segmentation 두가지의 computer vision tasks를 보았다.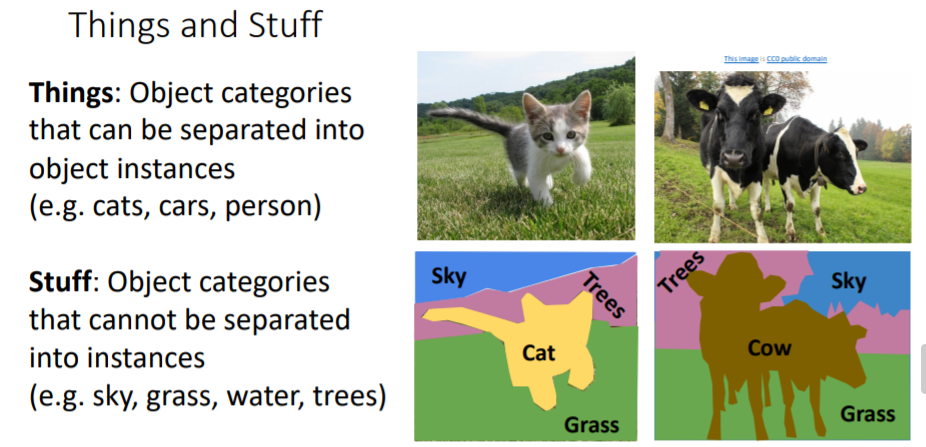 사람들은 보통 objects를 Things와 Stuff로 분류하기도 한다.
사람들은 보통 objects를 Things와 Stuff로 분류하기도 한다.
- Things : object instances로 구분지을 수 있는 object categories (cats, cars, person)
- Stuff : object instances로 구분지을 수 없는 object categories (sky, grass, water, trees)
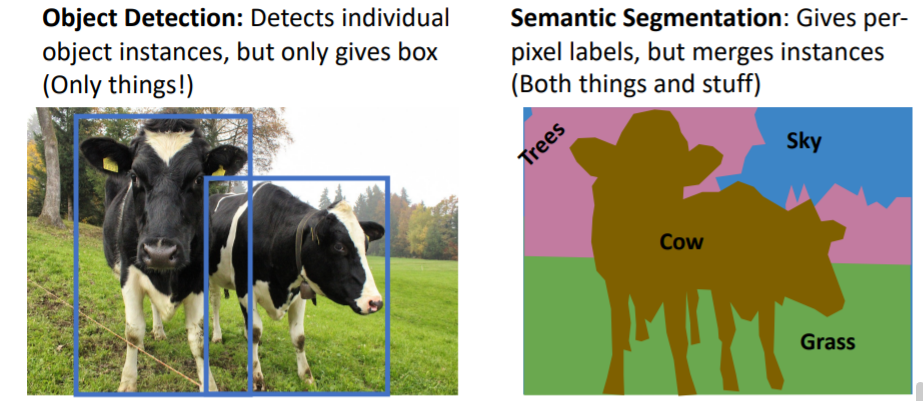 Object detection은 things만 다루고, Semantic Segmentation은 things와 stuff를 모두 다루지만 instances로 나누지 않기 때문에 의미는 없다.
Object detection은 things만 다루고, Semantic Segmentation은 things와 stuff를 모두 다루지만 instances로 나누지 않기 때문에 의미는 없다.
5.2) Computer Vision Tasks: Instance Segmentation
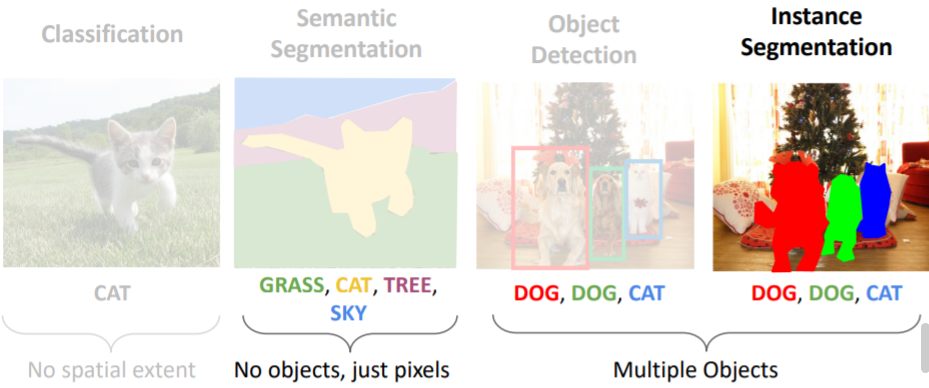
 Instance Segmentation은 하이브리드 task로, 이미지 내의 objects(things만)를 감지하고 이들을 pixel별로 segmentation한다.
Instance Segmentation은 하이브리드 task로, 이미지 내의 objects(things만)를 감지하고 이들을 pixel별로 segmentation한다.
즉 이를 통해 우리는 object detection을 하고 detected object에 대해 semantic segmentation을 진행한다.
5.3) Mask R-CNN
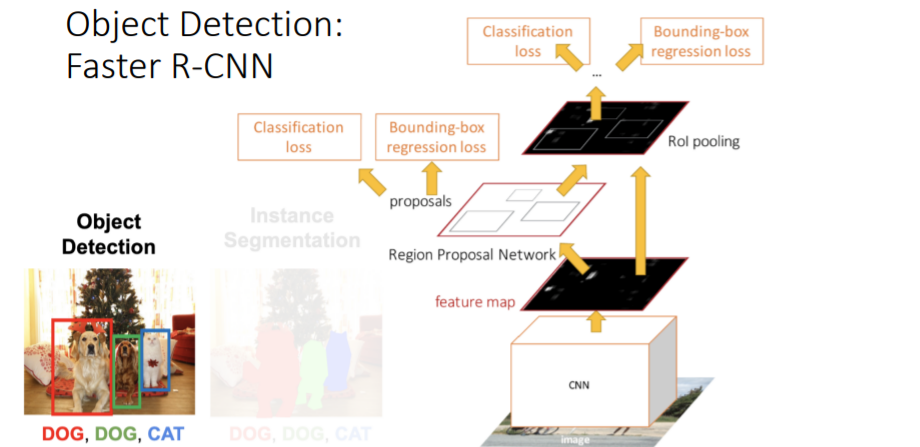 Instance Segmentation을 위해 우리는 기존 object detection에 사용했던 Faster R-CNN을 사용한다.
Instance Segmentation을 위해 우리는 기존 object detection에 사용했던 Faster R-CNN을 사용한다.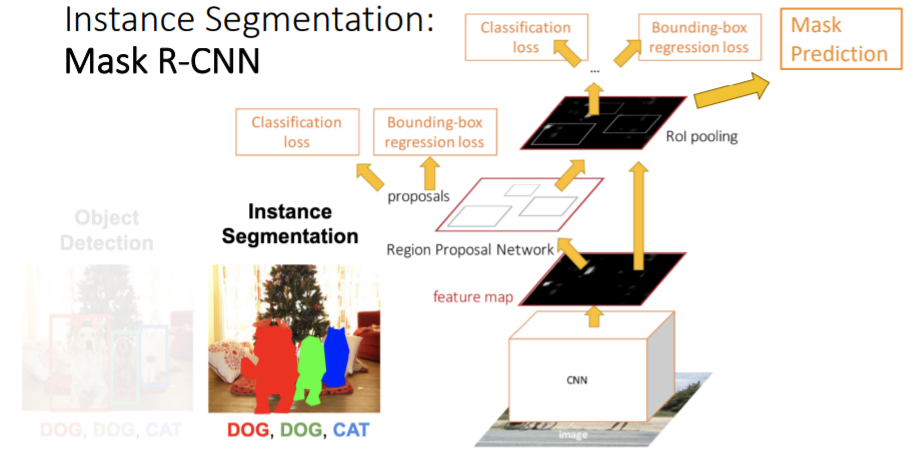 Faster R-CNN과 다른 점은 Mask Prediction 이라는 branch가 추가된 점이다. 이 Mask Prediction은 각 region proposal에서 foregrond/background semantic segmentation을 진행한다.
Faster R-CNN과 다른 점은 Mask Prediction 이라는 branch가 추가된 점이다. 이 Mask Prediction은 각 region proposal에서 foregrond/background semantic segmentation을 진행한다.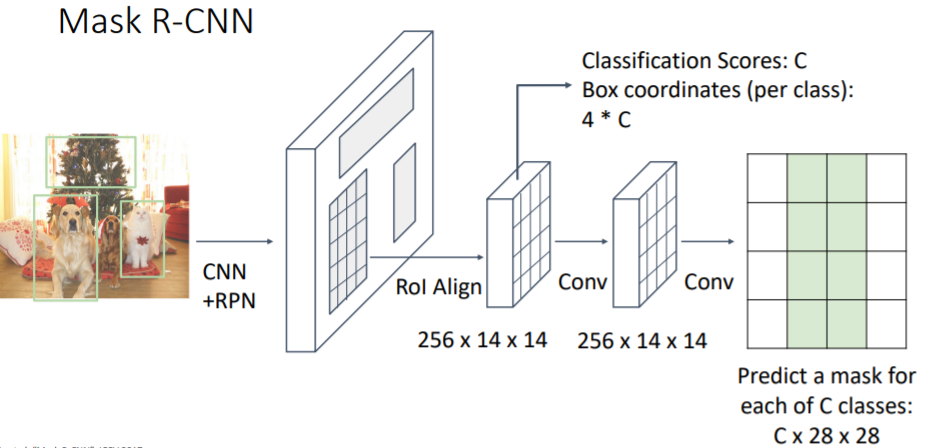 object detection과 semantic segmentation을 jointly하게 학습하는 것으로 보면 된다. detect한 object에 대해서 semantic segmentation을 진행한다.
object detection과 semantic segmentation을 jointly하게 학습하는 것으로 보면 된다. detect한 object에 대해서 semantic segmentation을 진행한다.
아래는 각 bounding box에 대해 segmentation mask가 어떻게 일어나는지에 대한 예시이다. bounding box가 가리키는 clas에 따라 segmentation masking을 하는 모습을 볼 수 있다.
bounding box가 가리키는 clas에 따라 segmentation masking을 하는 모습을 볼 수 있다. Mask R-CNN이 잘 작동하는 모습을 볼 수 있다. object detection을 통한 bounding boxes도 볼 수 있다. 그리고 각 bounding box에 해당하는 class에 대해 segmentation을 하는 모습도 볼 수 있다.
Mask R-CNN이 잘 작동하는 모습을 볼 수 있다. object detection을 통한 bounding boxes도 볼 수 있다. 그리고 각 bounding box에 해당하는 class에 대해 segmentation을 하는 모습도 볼 수 있다.
6. Panoptic Segmentation
6.1) Beyond Instance Segmentation
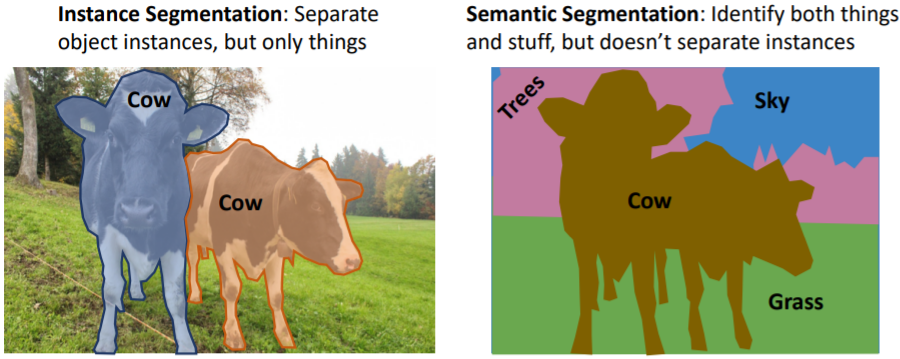 Instance Segmentation은 object instances를 구분하지만 things에 해당하는 object만 다룬다.
Instance Segmentation은 object instances를 구분하지만 things에 해당하는 object만 다룬다.
6.2) Beyond Instance Segmentation: Panoptic Segmentation
Panoptic Segmentation 논문
Panoptic Feature Pyramid Networks 논문
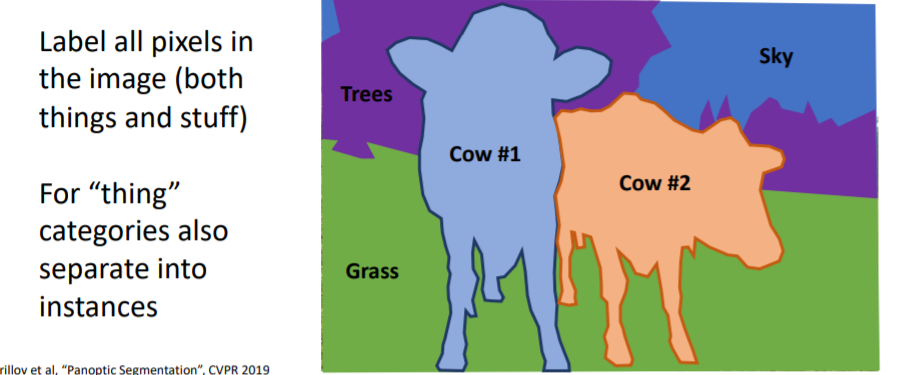 things와 stuff에 대한 모든 object를 pixel별로 라벨링한다. things에 대해서는 instances별로 구문한다.
things와 stuff에 대한 모든 object를 pixel별로 라벨링한다. things에 대해서는 instances별로 구문한다. 그리고 매우 잘 작동하는 것을 볼 수 있다.
그리고 매우 잘 작동하는 것을 볼 수 있다.
방법에 대해서는 자세히 다루지 않고 그냥 넘어갔다.
7. Human Keypoints
 사람을 segmentation하는 것 뿐만 아니라 사람의 pose와 keypoints의 위치까지 나타낼 수 있는 방법이다.
사람을 segmentation하는 것 뿐만 아니라 사람의 pose와 keypoints의 위치까지 나타낼 수 있는 방법이다.
7.1) Mask R-CNN
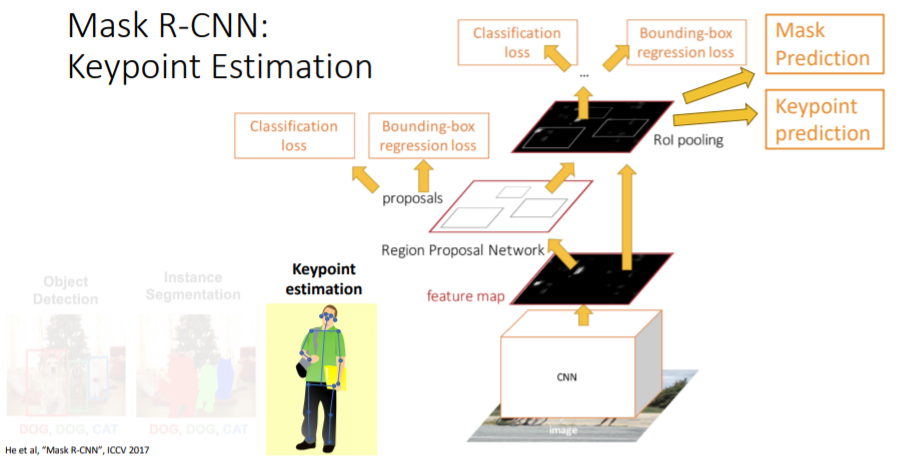 Mask R-CNN에 Keypoint prediction branch를 추가하여 이 task를 다룰 수 있다.
Mask R-CNN에 Keypoint prediction branch를 추가하여 이 task를 다룰 수 있다.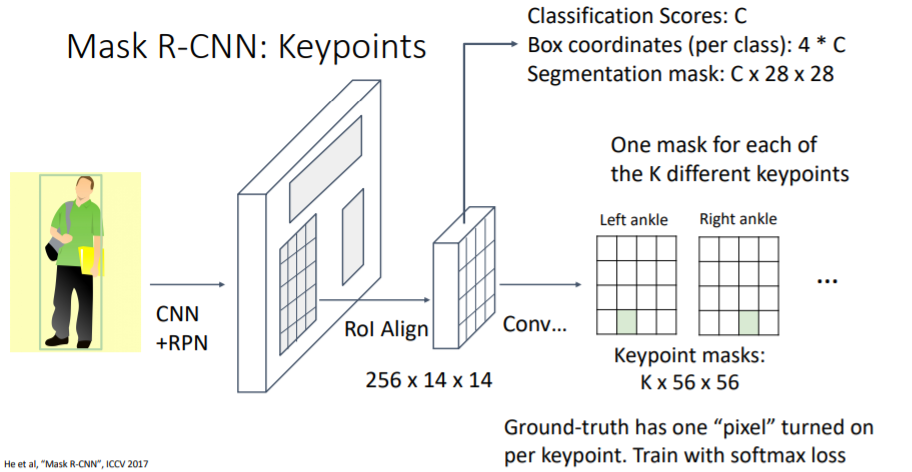 keypoint prediction branch에서는 K개의 서로 다른 keypoint mask를 씌운다(한개의 pixel로 이루어진 mask). 방법에 대해서는 자세히 다루지 않는다.
keypoint prediction branch에서는 K개의 서로 다른 keypoint mask를 씌운다(한개의 pixel로 이루어진 mask). 방법에 대해서는 자세히 다루지 않는다.
7.2) Joint Instance Segmentation and Pose Estimation
 Mask R-CNN을 가지고 Instance Segmentation과 Pose Estimation을 함께 잘 수행할 수 있다.
Mask R-CNN을 가지고 Instance Segmentation과 Pose Estimation을 함께 잘 수행할 수 있다.
8. General Idea: Add PerRegion “Heads” to Faster / Mask R-CNN!
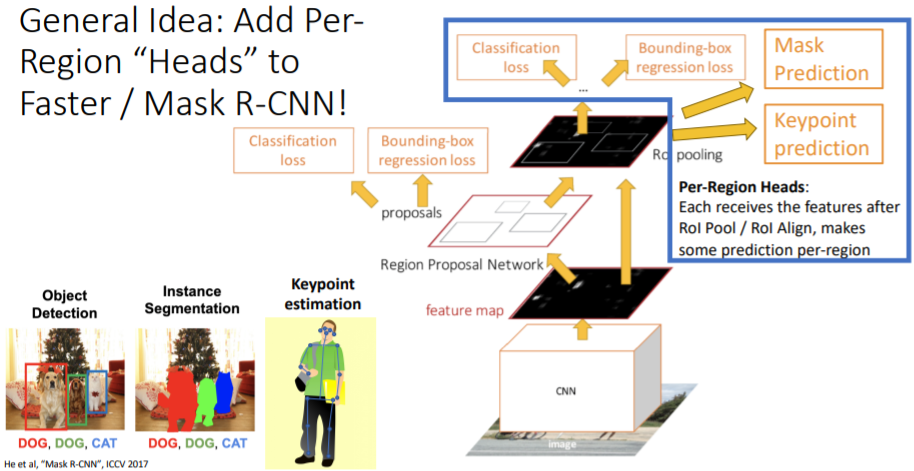 위에서 처럼 branch를 추가하는 방식을 사용하여 새로운 computer vision task에 적용할 수 있다. 새로운 cv task가 등장한다면 우리는 이를 object detection task로 우선 생각하고 원하는 결과를 얻기 위한 branch(head)를 추가하여 해결하는 방식으로 task를 해결할 수 있다.
위에서 처럼 branch를 추가하는 방식을 사용하여 새로운 computer vision task에 적용할 수 있다. 새로운 cv task가 등장한다면 우리는 이를 object detection task로 우선 생각하고 원하는 결과를 얻기 위한 branch(head)를 추가하여 해결하는 방식으로 task를 해결할 수 있다.
8.1) Dense Captioning: Predict a caption per region!
DenseCap: Fully Convolutional Localization Networks for Dense Captioning 논문
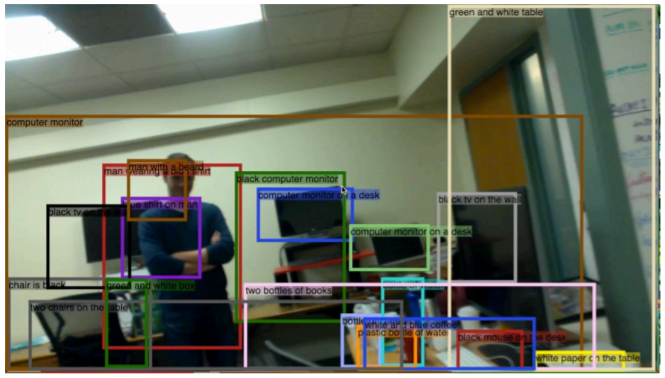
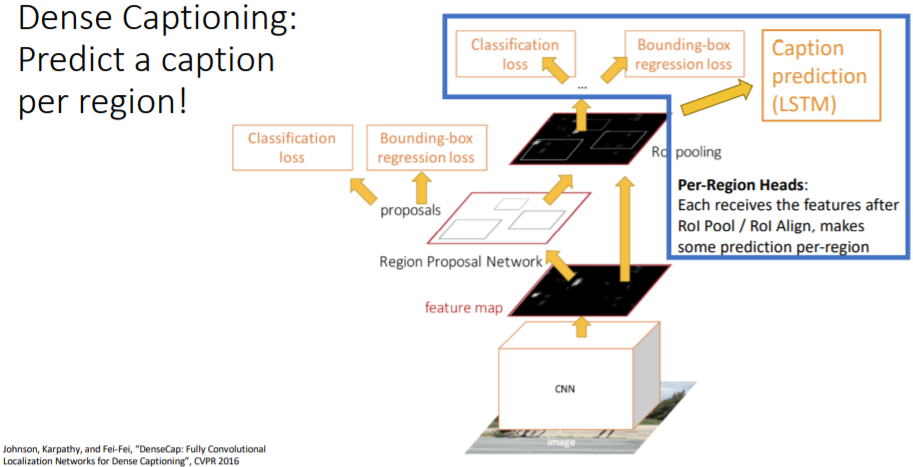 Mask R-CNN에 Caption prediction branch를 추가하여 아래와 같은 Dense Captioning을 수행할 수 있다. detect한 region에 대해 natural language로 설명하는 모습을 볼 수 있다.
Mask R-CNN에 Caption prediction branch를 추가하여 아래와 같은 Dense Captioning을 수행할 수 있다. detect한 region에 대해 natural language로 설명하는 모습을 볼 수 있다.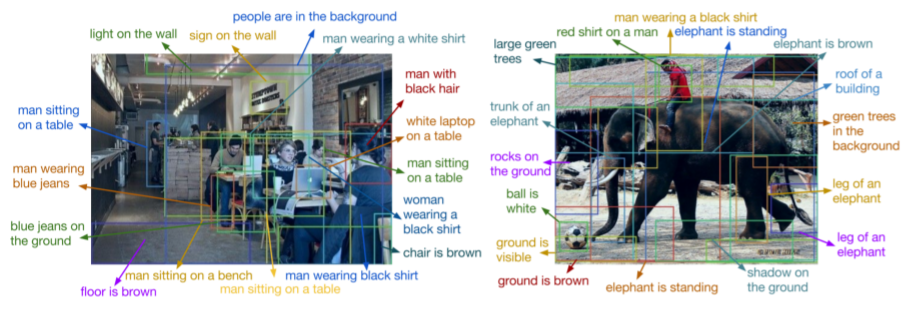
8.2) 3D Shape Prediction: Predict a 3D triangle mesh per region!
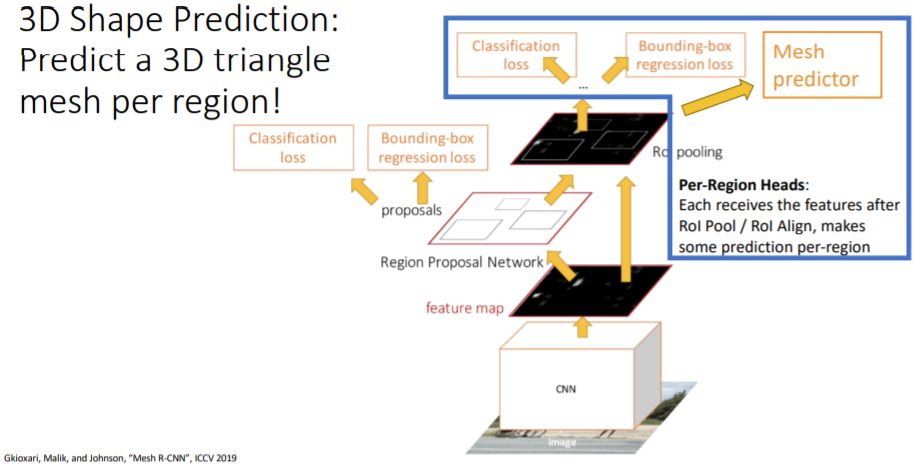 detect한 object에 대해 full 3d shape를 얻는 task이다.
detect한 object에 대해 full 3d shape를 얻는 task이다.
Summary