Intro.
2024년 1월 27일 빅데이터 연합동아리 BOAZ의 컨퍼런스에 다녀왔다!
(친절하게도 컨퍼런스 내용을 유튜브로도 업로드 해주셨다.)
대학교 재학시절 관심이 있었는데 이렇게 컨퍼런스를 참관할 수 있어서 굉장히 기대가 되었다.

모든 발표하나하나 다 유익하고 좋았지만, 이번 포스팅에서는 평소 궁금했었던 추천시스템을 기업과 실제 연계한 발표였던
REC팀의 <캠핏 데이터를 활용한 캠핑장 추천 시스템 구현>과
콜라보아즈팀의 <고객 세그멘테이션 기반 개인 맞춤형 추천시스템 for 루빗>을 회고해보고 관련 개념을 정리해보았다.
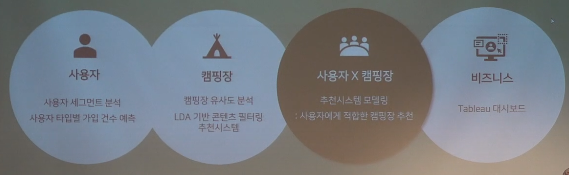
A. 캠핏 데이터를 활용한 캠핑장 추천 시스템 구현
** 캠핏은 다양한 캠핑장 확인 및 예약/캠핑용품 공구가 가능한 캠핑전용서비스이다.
분석 순서
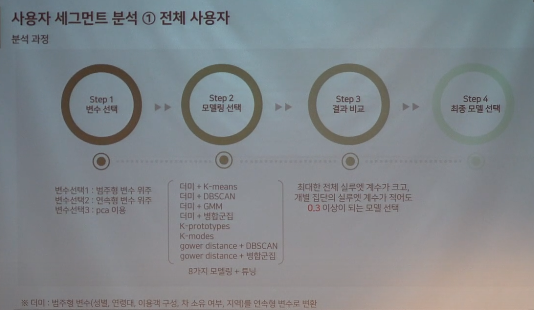
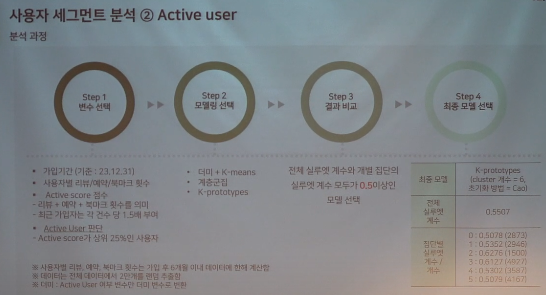
1-(1).사용자 세그먼트 분석-전체 사용자
- 군집분석 방법에는 K-Means, DBSCAN, GMM, FCM 등이 있다.
- REC팀에서는 8가지 모델링+튜닝방법을 사용했다.
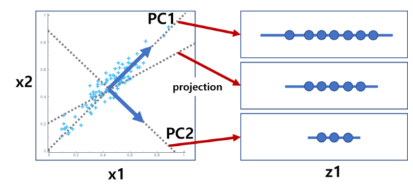
- 변수 선택

- 분석 결과

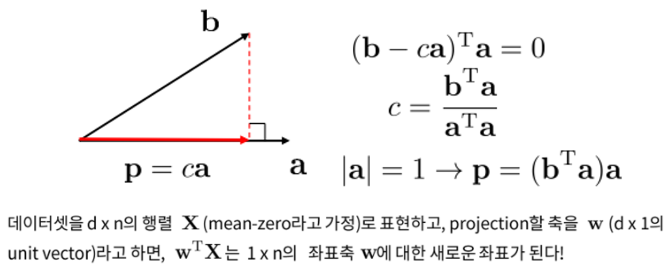
PCA(Principal Component Analysis, 주성분 분석. for 차원축소)
- 고차원 데이터 집합이 주어졌을 때 원래의 고차원 데이터와 가장 비슷하면서 더 낮은 차원 데이터를 찾아내는 방법
- 다차원의 특징벡터로 이루어진 데이터의 variance(원본 정보)를 유지하면서 낮은차원으로 축소
활용
- 얼굴인식
- 특징점을 추출하기 좋음
- 목표 : 중요 성분 순서대로 추출
데이터의 분산을 가장 잘 설명해주는(=projection하였을 때 가장 넓게 퍼져있는=projection하였을 때 variance를 최대화하는) 축을 찾음
linear model이 projection역할을 함
⭐ projection 이후의 분산을 최대화하는 축 w를 찾는 것
= 공분산 행렬을 고윳값 분해(Eigendecomposition)하고, 가장 큰 고윳값 람다1에 해당하는 고유벡터 v1을 찾는 것한계
- PCA는 초점이 variance를 줄이기 위한 축을 찾는 것
→ classification에는 비효과적일 수 있음
→ 데이터의 분포가 non-Gaussian일 때 잘 안됨
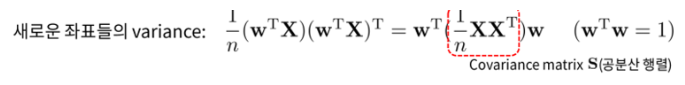
실루엣계수
- 군집 클러스터링 평가 척도
- 각 데이터별로 동일 군집에 포한 점들끼리의 거리는 가깝고, 다른 군집 간의 거리는 멀수록 군집화가 잘된 것으로 판단
범위
- -1~1사이의 값
좋은 군집화의 조건
- 기본적으로는 1에 가까울수록 군집화가 잘되었다고 판단
- 하지만 전체 실루엣 계수의 평균값과 개별 군집의 평균의 편차가 너무 크면 안됨.
1-(2).사용자 세그먼트 분석-전체 사용자
2.사용자 타입별 가입건수 예측
- 💡예측 방법에는 기존의 데이터를 활용해 머신러닝 모델링을 통해 예측할 수도 있지만 모형을 통해 산출할 수도 있다.
- 성장곡선 모형 중 bass 모형 활용
성장곡선모형
종류
- 바스 모형
- 신제품 판매 예측에 널리 사용됨.
🔍👀텍스트신제품의 경우 데이터가 부족해서 처음 n개월동안은 단순이동평균을 사용하는 등의 방법론만 알고 있었는데, 이러한 모형을 사용한 예측도 고려해봐야겠다.
- 신제품/기술을 출시했을 때, 제품을 구입/사용하는 고객은 혁신/모방으로 분류될 수 있으며, 채택 속도와 시기는 혁신정도와 고객간의 모방 정도에 따라 결정된다는 것을 전제로 함.- 곰페르츠 모형
- 로지스틱 모형
3.캠핑장 유사도
- 유사도 판단 기준은 각도, 거리, 비율 등이 있다.

4-(1).캠핑장 추천 시스템-LDA 기반 콘텐츠 필터링
- LDA방식을 통해 분류한 뒤 평가지표를 Precision, Recall로 하여 결과를 확인해보았을 때, 정확도가 높지 않았다고 한다.
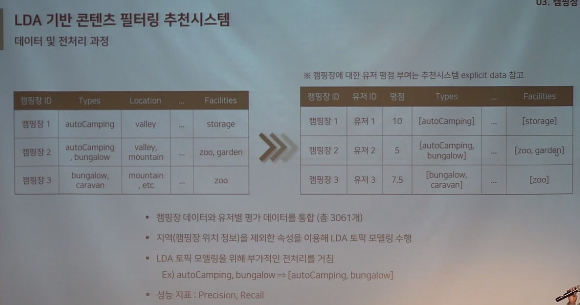
⭐LDA
- Latent Dirichlet Allocation
- 문서 내에 어떤 토픽이, 어떤 비율로 구성되어 있는지 분석해주는 확률 기반 모델링 방법
활용
- 제품 리뷰에서 토픽 자동 분류
4-(2).캠핑장 추천 시스템-사용자 기반
- 접근방법을 달리하여, 사용자의 리뷰데이터와 예약데이터를 활용해 평점데이터 생성
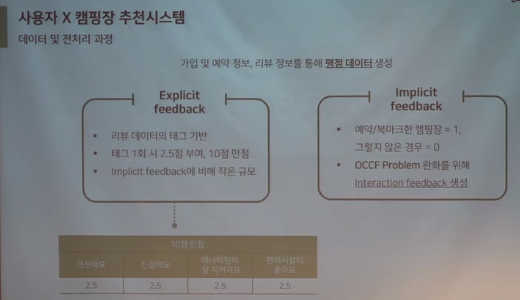
- Explicit data : 고객이 호불호를 직접적으로 표현한 데이터 (ex. 리뷰,좋아요 등)
- Implicit data : 고객이 호불호를 간전적으로 표현한 데이터 (ex. 검색기록, 구매내역 등)
👀 Implicit data를 다룰 때의 문제점은 유저의 행동에 대한 '의도'를 잘못 해석할 수 있다는 점이다. -> implicit의 경우 여러 선택 가능한 상황에서 선호도를 확인할 수 있는 부분을 고려해야 함.
OCCF Problem (One Class Collaborative Filtering)
정의
- '긍정'표현이 없는 데이터를 어떻게 해석할 것인가에 대한 문제
- 원인 몰라서인지, 비선호로 인한 것인지 알 수 없음
➡ REC팀의 경우 고객들이 고려할 캠핑장 수가 적다는 것을 근거로 '비선호'로 취급하였다.


-
사용모델: 1. CF 2.MF

-
평가지표 : NDCG
- 각 상품의 평점/상호작용 점수와 해당 상품의 순위에 따라 가중치 부여하여 점수 계산
- 정규화NDCG
-Normalized Discounted Cumulative Gain
-예측한 추천 목록을 사용자의 선호도 순으로 정렬
5.결과
1) CF

2) MF
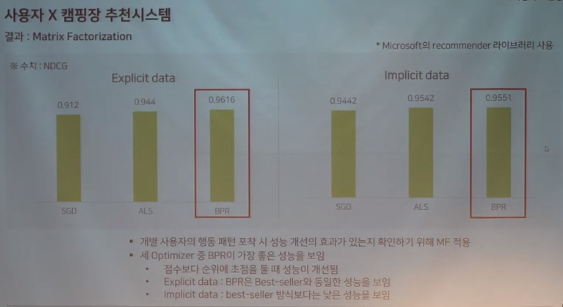
3) 최종

추천시스템에서 고려해야 할 사항 및 알아야할 개념, 추천시스템에서 활용하는 지표에 대해 일차적으로 학습하고 기존 데이터를 활용하여 implicit, explicit을 구분하여 의사결정에 필요한 새로운 데이터셋을 만든 점, 논리의 흐름을 이해할 수 있는 자료였다👍
B. 고객 세그멘테이션 기반 개인 맞춤형 추천시스템 for 루빗
** 루빗은 하루 루틴(감정)을 기록하면서 관리하는 셀프멘탈케어 앱서비스라고 한다.

분석순서
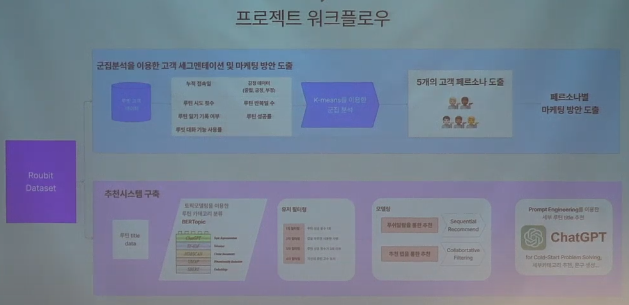
콜라보아즈팀은 크게 1) 군집분석을 이용한 고객 세그멘테이션 및 마케팅 방안 도출, 2)추천시스템 구축을 하였는데, 여기서는 추천시스템에 포커스하기로!
- 루틴title date를 수집해서 -> BERTopic 방식으로 토픽모델링-> 유저 필터링을 통해 모델링에 사용할 데이터 산정 -> 추천 모델링 -> chatGPT 프롬프트엔지니어링을 이용한 세부카테고리 추천&문구 생성

1.루틴 title data 생성
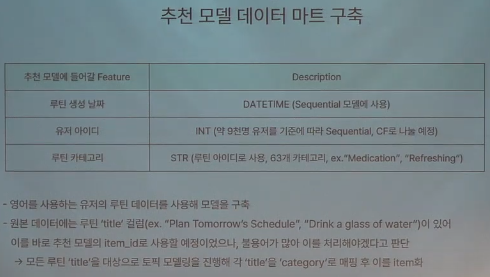
2.토픽모델링
-
불용어는 제거하고 표현은 다르더라도 루틴을 분류할 수 있도록 하기 위해서는 Topic Modeling을 해야 함.

-
이를 위해 콜라보아즈팀이 선택한 방법인 PCA, BART-TL, BERTopic 중에서 주제의 다양성& 주제의 일관성을 기준으로 했을 때, 가장 성능이 좋았던 BERTopic 선택

-
63개의 라벨로 대분류하여 63개의 item으로 추천 모델링 진행 이후 chatGPT Prompting을 이용해 세부적인 루틴 추천

- 🔎👀루틴 카테고리의 표현을 정교하게 하기 위해 chatGPT prompting 진행했다는 점이 인상적

3.유저필터링

4.추천 모델링
- 유저의 이전 히스토리를 파악해서 협업문구를 보내는 시점에 유저가 수행할 확률이 높은 task를 추천
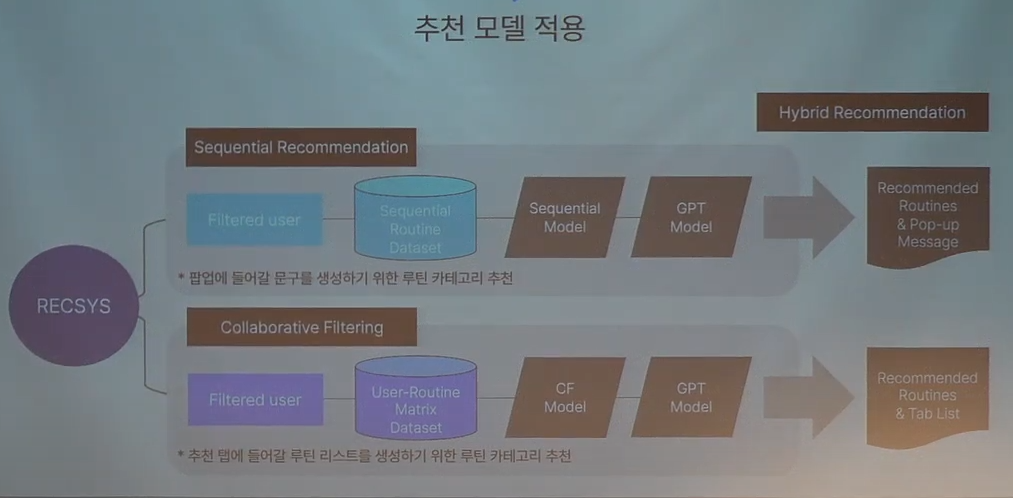
-
Sequential Recommendation:
유저의 히스토리를 통해 시간의 흐름에 따른 추천 -
Collaborative Filtering :
유저의 히스토리를 통해 유저가 수행할 확률이 높은 다양한 루틴 추천
5.Prompt Engineering을 통한 세부루틴 title 추천

6.시연 예시

Outro.
BOAZ는 모두 대학생&대학원생들로만 구성된 동아리인데, 다들 프로페셔널한 모습에 좋은 에너지를 얻을 수 있는 좋은 시간이었다. 관련 논문 등을 찾아보며 공부하는 것도 의미가 있지만 실제 기업데이터를 활용해 일련의 분석과정을 보는 것도 꽤 유익한 시간이었다.
무엇보다 직접 현장에 가서 보는 것에서 현장감, 기운을 얻었지만 역시 이렇게 다시 찬찬히 나의 속도로 정리하면서 소화하는 과정이 가장 중요한 것 같다.
