데이터분석을 위해 리뷰데이터가 필요할 때가 있죠!
네이버쇼핑에서 녹즙의 리뷰를 최근 1년치만 수집한다고 해봅시다.
※ 로컬에서 하느냐, 서버에서 하느냐, 코랩에서 하느냐에 따라 코드가 달라집니다.
이번 포스팅은 로컬 기준입니다.
0. 크롤링 이해하기
크롤링은 자동화 매크로같은 개념이라서 내가 수작업으로 클릭할 것을 스크립트로 짜주는 것을 의미합니다.
클릭할 것을 어떻게 스크립트로 옮기냐구요?
홈페이지에서 보이는 각각의 정보들은 각자의 태그가 있어요. 기본적으로는 위치에 따라 달라요. 내가 원하는 정보에 해당하는 태그만 쏙쏙 뽑아서 코드로 옮기면 됩니다.
그 태그를 어떻게 보냐구요?
수집하려는 홈페이지를 띄운 상태에서 F12키를 누르면 개발자모드가 나옵니다.
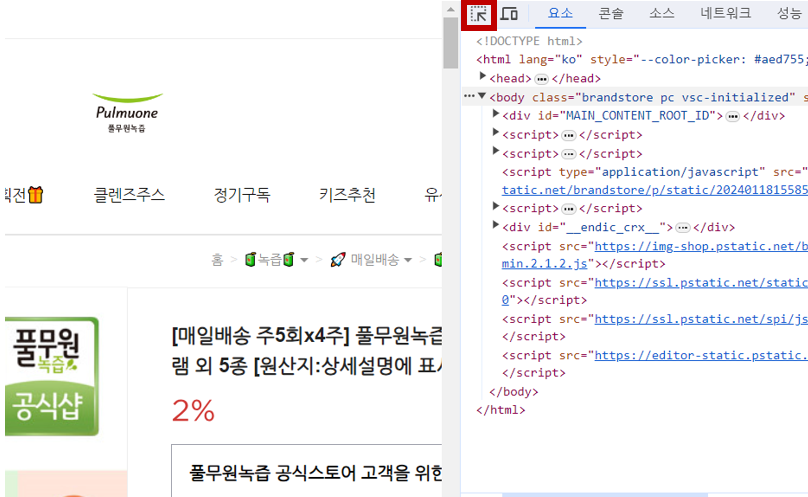
상단에 보이는 버튼을 눌러준 뒤 홈페이지에 마우스오버를 하면
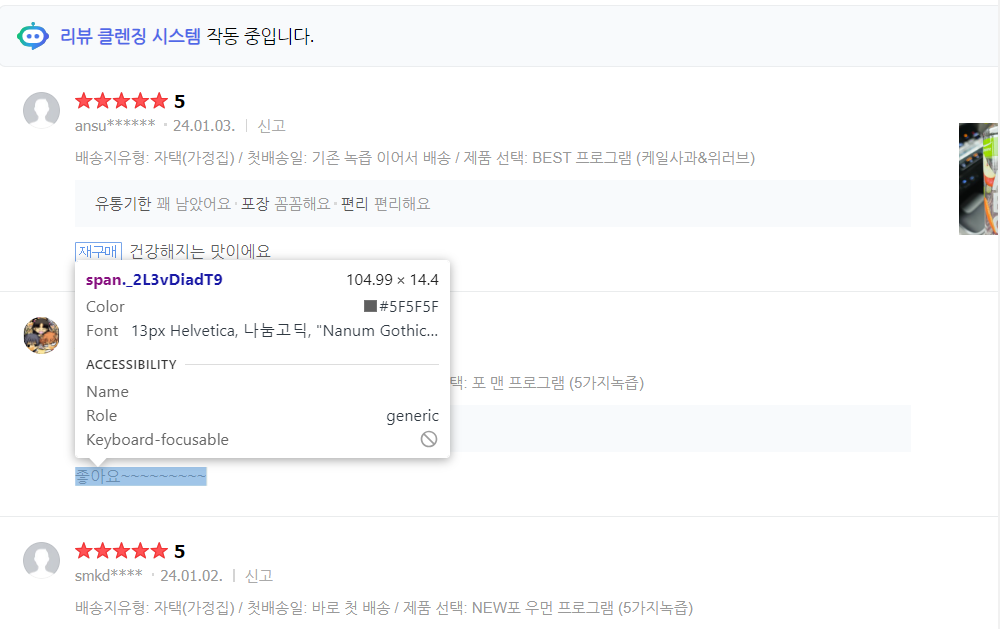
다음과 같이 각 위치마다의 태그정보가 나옵니다.
마치 이름은 김철수이지만 제 3자에서 볼 때 00회사의 00층의 00부서에 있는 사원 이렇게 정형화되는 것처럼요!
원하는 정보에 해당하는 html 코드에서 마우스오른쪽버튼클릭>복사>selector복사 클릭하면 해당 정보를 가져올 수 있어요. XPath 등으로도 가능한데 우선은 가장 보편적인 방법인 selector복사를 이용해줄게요.
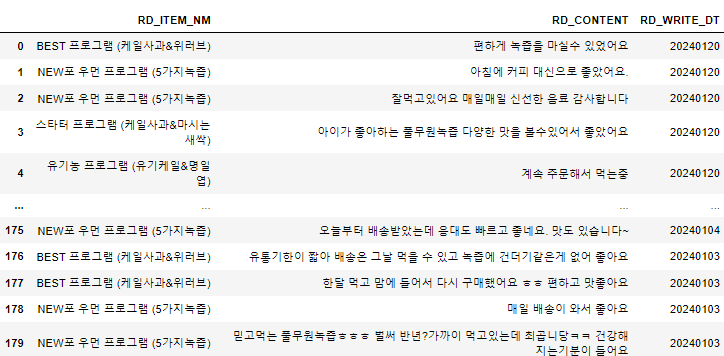
⭐크롤링을 처음 할 때 놓치기 쉬운 POINT:태그 선택 범위
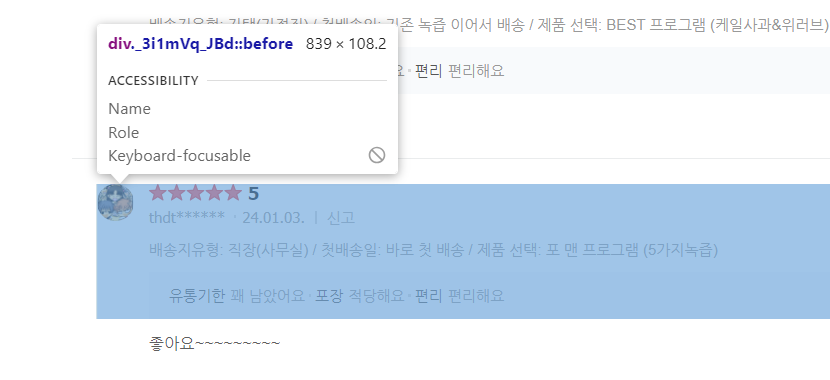
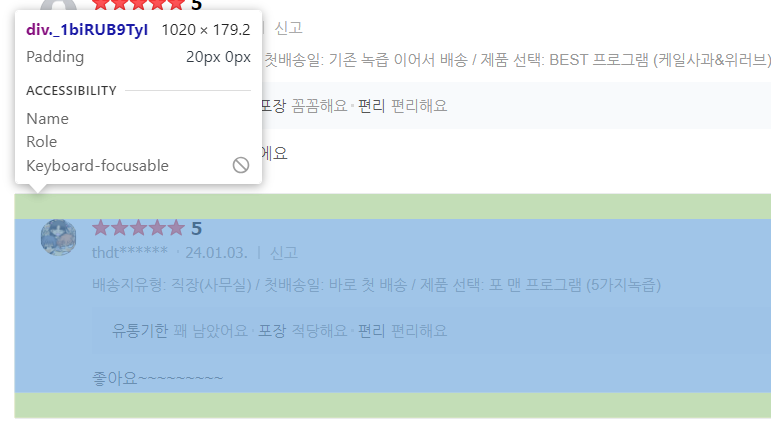
1과 2의 차이가 느껴지나요? 마우스오버를 살짝만 해도 적용되는 범위가 달라집니다.
내가 원하는 정보 이상으로 수집되지 않도록 적절한 태그를 잘 찾아보세요!
1.환경세팅
필요한 라이브러리를 호출해줍니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
# selenium import
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from datetime import datetime, timedelta
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager브라우저를 세팅해줍니다.
options = webdriver.ChromeOptions() # 크롬 옵션 객체 생성
# options.add_argument('headless') # headless 모드 설정 -> 해당 옵션 적용 시 PDF 다운 불가
options.add_argument("window-size=1920x1080") # 화면크기(전체화면)
options.add_argument("disable-gpu")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
options.add_argument('--no-sandbox') 크롬드라이버를 다운받고 다운받은 경로를 입력해줍니다.
chrome_driver_path = r'<경로입력>'
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service = service, options=options)
# wait seconds...
driver.implicitly_wait(3)2.리뷰데이터 수집
2-(1).사이트 열기
수집하려는 사이트를 입력해줍니다.
# 수집하려는 사이트 경로 입력
driver.get('https://brand.naver.com/pmogreenjuice/products/6157332427')
time.sleep(3)
time.sleep()를 중간중간 써주는 이유는,
로딩되고 있는데 다음 코드를 실행해버리면 코드 수행을 못하기 때문입니다.
마치 '빨간옷을 입어라'고 명령해서 옷을 주섬주섬 입고 있는데
다 입지도 않았는데 갑자기 '단추를 잠가라'고 하면 명령을 수행하지 못하는 것이죠.
그래서 명령을 수행할 동안 잠시 쉬어주는 겁니다. 얼마나 자주 쉴지는 코드짜기 나름입니다
여기까지 실행했다면 크롬창이 열려야 합니다.
(서버환경에서 코드를 실행하는 것이라면 크롬창이 실행은 되고 있으나 창이 열리지 않아요!)
다음으로 넘어가볼까요?
2-(2).버튼 클릭하기
리뷰 버튼을 클릭해줍니다.
driver.find_element(By.CSS_SELECTOR,'#content > div > div.z7cS6-TO7X > div._27jmWaPaKy > ul > li:nth-child(2) > a').click()
time.sleep(3)최근 1년치만 다운 받을 것이니 최신순 버튼을 클릭해줍시다.
# 최신순 버튼 클릭
driver.find_element(By.CSS_SELECTOR,'#REVIEW > div > div._2LvIMaBiIO > div._2LAwVxx1Sd > div._1txuie7UTH > ul > li:nth-child(2) > a').click()
time.sleep(3)2-(3).한 페이지에서 보이는 리뷰 한꺼번에 수집하기
클릭클릭해서 리뷰가 보이는 페이지로 왔으니 이제 본격적으로 리뷰를 쓸어담아봅시다.
복붙의 경우 직접 일일히 드래그하며 수집해야했겠지만 크롤링은 한페이지에서 보이는 리뷰를 몽땅 긁을 것이예요.
1페이지 수집 > 2페이지로 이동 > 2페이지 수집 > 3페이지로 이동 ... >마지막 페이지로 이동>마지막 페이지 수집
이런 반복이 계속 되겠죠? 그 과정을 반복문으로 만들어 수집할 것입니다.
우선은 1페이지에서의 리뷰를 수집하는 코드부터 돌아가는지 보고
그 다음에 반복문으로 만들어봅시다요
수집할 정보는 리뷰 작성 날짜,상품명,리뷰내용입니다.
⭐Tip!
사람이라면 a사람이 작성한 날짜,상품명,리뷰내용 수집, b사람이 작성한 날짜, 상품명, 리뷰내용 수집 .. 이렇게 스크롤 순으로 수집해야겠다고 생각하겠지만
코드로 짤 때는 일단 날짜 한꺼번에 수집하고->상품명 한꺼번에 수집하고->리뷰 내용 한꺼번에 수집하는 순서로 하는게 더 좋아요.
우리가 홈페이지에 나온 리뷰데이터를 컬럼이 날짜,상품명,리뷰내용인 테이블로 만들거잖아요? 행별로 수집하는게 아니라 열별로 수집하는게 코드 관점에서 더 간단하답니다.
‼css선택자에서 수집한 데이터 중 필요한 부분만 추출하기
상품명의 경우 상품명이 다른 정보에 같이 들어있어 상품명만 뽑는 작업이 필요해요.
패턴을 보면 문장 뒤에서 유통기한 정보가 계속 딸려나오네요
패턴을 찾아서 뒷부분은 공백으로 대체 후 find()를 사용해 '제품선택 : ' 이후의 단어만 추출하도록 해주면 됩니다.
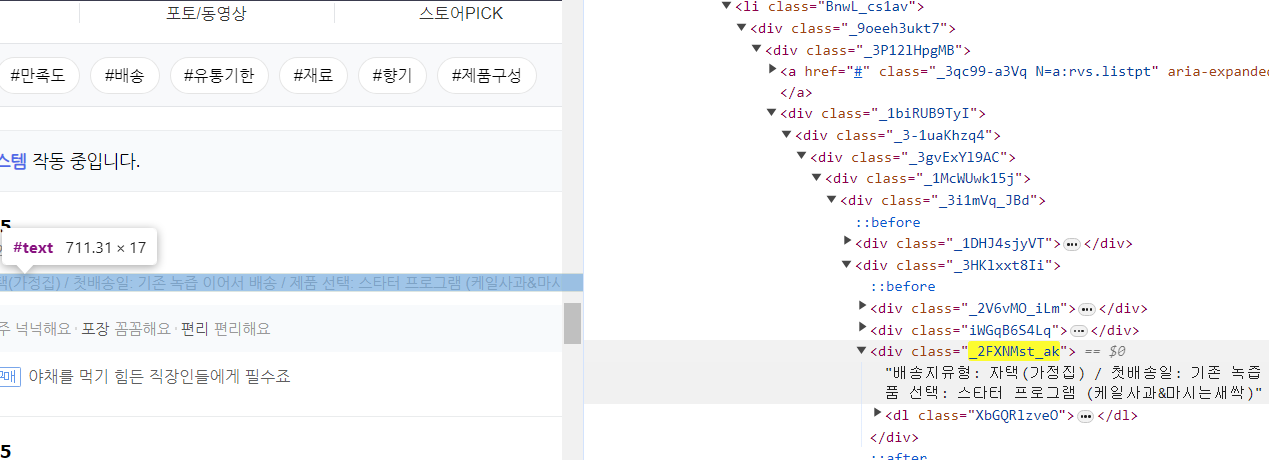

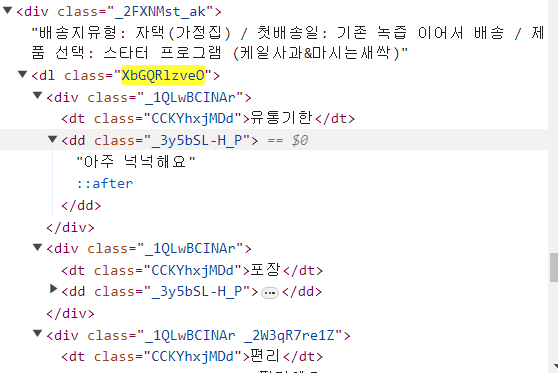
파이썬 코드를 통해 이해해볼까요?
# 1. 셀레니움으로 html가져오기
html_source = driver.page_source
# 2. bs4로 html 파싱
soup = BeautifulSoup(html_source, 'html.parser')
time.sleep(0.5)
# 3. 리뷰 정보 가져오기
reviews = soup.findAll('li', {'class': 'BnwL_cs1av'})
# 4. 한페이지 내에서 수집 가능한 리뷰 리스트에 저장
for review in range(len(reviews)):
# 4-1.리뷰작성일자 수집
write_dt_raw = reviews[review].findAll('span' ,{'class' : '_2L3vDiadT9'})[0].get_text()
write_dt = datetime.strptime(write_dt_raw, '%y.%m.%d.').strftime('%Y%m%d')
# 4-2.상품명 수집
# 4-2-(1) 상품명이 포함된 css 선택자 입력
item_nm_info_raw = reviews[review].findAll('div', {'class' : '_2FXNMst_ak'})[0].get_text()
# 4-2-(2) re.sub() 를 활용해 dl class="XbGQRlzveO"부분부터 추출한 문장을 공백으로 대체
item_nm_info_for_del = reviews[review].findAll('div', {'class' : '_2FXNMst_ak'})[0].find('dl', {'class' : 'XbGQRlzveO'}).get_text()
# 4-2-(3) re.sub(pattern, replacement, string) : string에서 pattern에 해당하는 부분을 replacement로 모두 대체
item_nm_info= re.sub(item_nm_info_for_del, '', item_nm_info_raw)
# 4-2-(4) find() : 문자열 순서 (인덱스) 반환 : find()를 활용해 '제품 선택 : '이 나오는 인덱스 반환
str_start_idx = re.sub(item_nm_info_for_del, '', item_nm_info_raw).find('제품 선택: ')
# 4-2-(5) 제품명만 추출. strip(): 공백 제거
item_nm = item_nm_info[str_start_idx + 6:].strip()
# 4-3. 리뷰내용 수집
review_content_raw = reviews[review].findAll('div', {'class' : '_1kMfD5ErZ6'})[0].find('span', {'class' : '_2L3vDiadT9'}).get_text()
review_content = re.sub(' +', ' ',re.sub('\n',' ',review_content_raw ))
# 4-4. 수집데이터 저장
write_dt_lst.append(write_dt)
item_nm_lst.append(item_nm)
content_lst.append(review_content)2-(4) 반복문을 통해 여러 페이지의 리뷰 한꺼번에 수집하기
이 단계에서는 페이지를 이동하는 내용이 추가되었다고 생각하면 됩니다.

2페이지 버튼 selecter code
#REVIEW > div > div._2LvIMaBiIO > div._2g7PKvqCKe > div > div > a:nth-child(3)
3페이지 버튼 selector code
#REVIEW > div > div._2LvIMaBiIO > div._2g7PKvqCKe > div > div > a:nth-child(4)
이런 규칙이라면 10페이지 버튼 selector code는
#REVIEW > div > div._2LvIMaBiIO > div._2g7PKvqCKe > div > div > a:nth-child(11)이겠죠
11페이지부터는 다시 1페이지버튼과 selector code가 동일합니다
코드로 표현하면 다음과 같습니다.
# 현재 페이지
page_num = 1
page_ctl = 3
# 날짜
date_cut = (datetime.now() - timedelta(days = 365)).strftime('%Y%m%d')
while True :
print(f'start : {page_num} page 수집 중, page_ctl:{page_ctl}')
# 1. 셀레니움으로 html가져오기
html_source = driver.page_source
# 2. bs4로 html 파싱
soup = BeautifulSoup(html_source, 'html.parser')
time.sleep(0.5)
# 3. 리뷰 정보 가져오기
reviews = soup.findAll('li', {'class': 'BnwL_cs1av'})
# 4. 한페이지 내에서 수집 가능한 리뷰 리스트에 저장
for review in range(len(reviews)):
# 4-1.리뷰작성일자 수집
write_dt_raw = reviews[review].findAll('span' ,{'class' : '_2L3vDiadT9'})[0].get_text()
write_dt = datetime.strptime(write_dt_raw, '%y.%m.%d.').strftime('%Y%m%d')
# 4-2.상품명 수집
# 4-2-(1) 상품명이 포함된 css 선택자 입력
item_nm_info_raw = reviews[review].findAll('div', {'class' : '_2FXNMst_ak'})[0].get_text()
# 4-2-(2) re.sub() 를 활용해 dl class="XbGQRlzveO"부분부터 추출한 문장을 공백으로 대체
item_nm_info_for_del = reviews[review].findAll('div', {'class' : '_2FXNMst_ak'})[0].find('dl', {'class' : 'XbGQRlzveO'}).get_text()
# 4-2-(3) re.sub(pattern, replacement, string) : string에서 pattern에 해당하는 부분을 replacement로 모두 대체
item_nm_info= re.sub(item_nm_info_for_del, '', item_nm_info_raw)
# 4-2-(4) find() : 문자열 순서 (인덱스) 반환 : find()를 활용해 '제품 선택 : '이 나오는 인덱스 반환
str_start_idx = re.sub(item_nm_info_for_del, '', item_nm_info_raw).find('제품 선택: ')
# 4-2-(5) 제품명만 추출. strip(): 공백 제거
item_nm = item_nm_info[str_start_idx + 6:].strip()
# 4-3. 리뷰내용 수집
review_content_raw = reviews[review].findAll('div', {'class' : '_1kMfD5ErZ6'})[0].find('span', {'class' : '_2L3vDiadT9'}).get_text()
review_content = re.sub(' +', ' ',re.sub('\n',' ',review_content_raw ))
# 4-4. 수집데이터 저장
write_dt_lst.append(write_dt)
item_nm_lst.append(item_nm)
content_lst.append(review_content)
# 리뷰 수집일자 기준 데이터 확인(최근 1년치만 수집)
if write_dt_lst[-1] < date_cut :
break
# page 이동
driver.find_element(By.CSS_SELECTOR,f'#REVIEW > div > div._2LvIMaBiIO > div._2g7PKvqCKe > div > div > a:nth-child({page_ctl})').click()
time.sleep(3)
# 셀레니움으로 html가져오기
html_source = driver.page_source
# bs4로 html 파싱
soup = BeautifulSoup(html_source, 'html.parser')
time.sleep(0.5)
page_num += 1
page_ctl += 1
if page_num % 10 == 1 :
page_ctl = 3
print('done') 2-(5) 수집한 정보 csv로 변환하기
각각의 리스트에 날짜, 상품명, 리뷰내용을 담아준 것을 이제 데이터프레임에 담아서 csv로 export해봅시다.
result_df = pd.DataFrame({
'RD_ITEM_NM' : item_nm_lst,
'RD_CONTENT' : content_lst,
'RD_WRITE_DT' : write_dt_lst })
csv로 export
result_df.to_csv('./navershopping_review_data.csv', index = None, encoding = 'utf-8-sig')
여기까지 잘 따라왔나요?
수고하셨어요~~👍

3개의 댓글

안녕하세요, 해당 코드 이용해서 크롤링에 도움이 많이 되었습니다. 다만 최근에 selector 설정이 바뀐 것인지 페이지 전환할때 마지막 몇 페이지에서 에러가 났는데요.
'page_ctl' 값이 마지막 즈음에 이상해져서 이걸 불러오는데 error가 발생하는 것 같았습니다. 따라서 넘어갈 page 숫자 그대로를 가져오는 방법으로 바꾸어 보았습니다. 방법은 아래와 같습니다.
아래와 같이 설정한 후에
page_num = 1
page_ctl = 2
아래의 부분을
(( # page 이동 ))
driver.find_element(By.CSS_SELECTOR,f'#REVIEW > div > div._2LvIMaBiIO > div._2g7PKvqCKe > div > div > a:nth-child({page_ctl})').click()
아래 부분처럼 수정
xpath = f'//a[text()="{page_ctl}"]'
driver.find_element(By.XPATH, xpath).click()
그리고 아래 부분은 삭제
if page_num % 10 == 1 :
page_ctl = 3
이렇게 하니 더 이상 에러가 발생하지 않았습니다. 혹 저와 같은 문제를 겪고 있는 분께 도움이 될까 하여 올립니다.
너무 잘봤습니다
최고에요