
1. Intro
Flamingo: a Visual Language Model for Few-Shot Learning
멀티모달 학습 분야에서는 Contrastive Learning 기반의 비전-언어 모델(CLIP)과 이미지 캡셔닝 및 VQA(Visual Question Answering) 모델(BLIP)과 같은 다양한 접근법이 등장하고 있습니다.
CLIP은 이미지와 텍스트 간의 유사도를 측정하여 이미지 분류(classification) 및 텍스트 기반 이미지 검색(image retrieval)과 같은 작업에서 뛰어난 성능을 보였으나 텍스트를 직접 생성할 수 없는 한계가 있습니다.
CLIP은 only-encoder 구조로 동작하며, 이미지와 텍스트를 단순히 매칭하는 방식이기 때문에 단일 모달리티 입력만 처리 가능합니다.
반면, BLIP은 이미지 캡셔닝(Image Captioning)과 VQA 같은 생성형 멀티모달 작업에서 강점을 보이며, 사전 학습된 대형 언어 모델을 활용하여 입력된 이미지 기반으로 텍스트 생성이 가능합니다. 하지만 fine-tuning이 필수적이어서 few-shot learning이 어렵고, 이미지와 텍스트가 혼합된(interleaved) 데이터 처리에 한계가 있습니다.
BLIP은 이미지를 기반으로 텍스트를 생성할 수 있지만, 특정 데이터셋에 맞춰 추가 학습이 필요하다는 제약이 존재합니다.
이러한 한계를 극복하기 위해 Flamingo 모델이 등장하였습니다. Flamingo는 사전 학습된 대형 언어 모델과 비전 모델을 cross-attention을 통해 결합하여, few-shot learning이 가능한 VLM(Visual Language Model)을 제안합니다.
기존 모델과 달리, Flamingo는 fine-tuning 없이도 다양한 멀티모달 작업을 수행할 수 있으며, 이미지와 텍스트가 혼합된 형태의 데이터(multimodal data)도 자연스럽게 처리 가능합니다. 이를 통해 open-ended VQA, close-ended VQA, 이미지 캡셔닝 등 다양한 작업에서 우수한 성능을 보여줍니다.
Open-ended VQA: 사전 정의된 정답 집합에 얽매이지 않고, 자유로운 형식의 텍스트로 답변을 생성하는 방식입니다.
Close-ended VQA: 여러 선택지 중 하나를 고르거나, 사전에 정의된 정답 집합 내에서만 답변하는 방식입니다.
Flamingo 모델은 cross-attention을 통해 사전 학습된 비전 및 언어 모델을 연결합니다. 이를 통해 입력 데이터를 하나의 모달리티가 아닌 언어(텍스트)와 시각(이미지/비디오) 데이터를 결합하는 멀티 모달 데이터를 입력으로 사용 가능합니다. Flamingo 모델은 CLIP과 비슷하게 대규모 웹 기반의 이미지-텍스트 페어 데이터(corpora)를 활용해 학습되었습니다. 이를 통해 few-shot learning 기반의 VQA, 이미지 캡셔닝 등의 다양한 Task에 빠르게 적응하고 우수한 성능을 발휘합니다. 재미있는 점은 Open-ended VQA와 Close-ended VQA에 구애 받지 않고 답변을 적절하게 생성한다는 점 입니다.
2. Approach
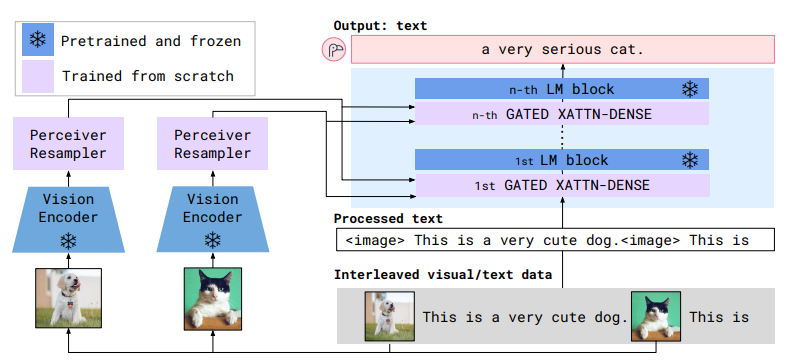
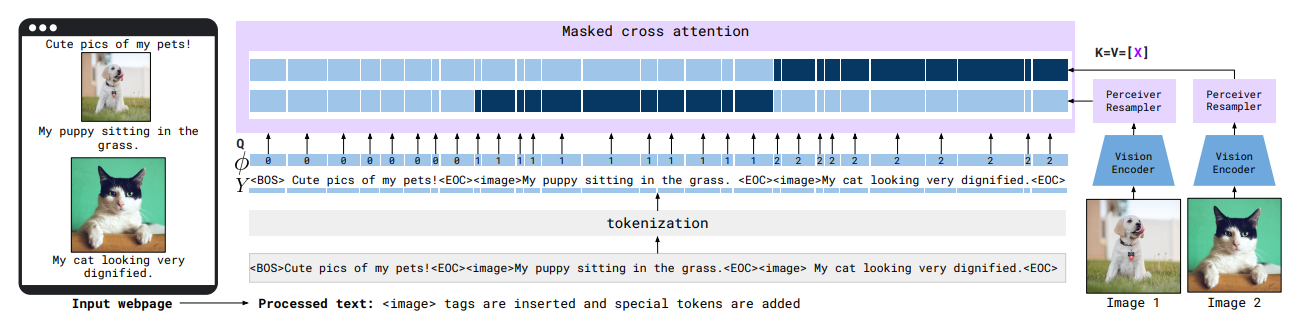
Flamingo는 텍스트와 이미지 또는 비디오가 혼합된 입력(interleaved input)을 받아, 이를 문맥적으로 이해하고 자연스러운 텍스트를 생성할 수 있는 Visual Language Model(VLM)입니다. 기존의 멀티모달 모델과 달리, 이미지와 텍스트를 독립적으로 처리하는 것이 아니라, 시퀀스 내에서 자연스럽게 섞인(interleaved) 정보를 반영할 수 있도록 설계되었습니다. 이를 위해 사전 학습된 비전 및 언어 모델을 효과적으로 결합하는 구조를 갖추고 있으며, 핵심적인 아키텍처와 동작 과정은 다음과 같습니다.
I. 비전 인코더 (Pretrained Vision Encoder)
입력된 이미지는 하나의 Vision Encoder를 통해 특징을 추출하며, 비디오의 경우 프레임 단위로 분할한 후 개별 이미지처럼 처리됩니다. 이 과정에서 공간-시간적(spatio-temporal) 특징을 포함한 feature map이 생성됩니다.
위 그림에서는 Vision Encoder가 2개로 표시되어 있지만, 이는 여러 이미지를 순차적으로 처리하는 과정을 나타낸 것입니다. 실제로는 모든 입력 이미지를 하나의 Vision Encoder가 공유하여 처리합니다.
II. Perceiver Resampler
Vision Encoder에서 생성된 feature map은 크기가 크고 복잡하여, 언어 모델과 직접 결합하기 어렵습니다. 이를 해결하기 위해 Perceiver Resampler가 중요한 정보를 압축하여, 고정된 크기의 이미지 토큰(visual tokens)으로 변환합니다.
🤔 차원 축소를 진행하는 과정에서 필요한 정보만 유지될까?
정보 병목(Information Bottleneck) 원리에 따르면, 모델은 입력된 모든 정보를 그대로 보존하는 대신, 태스크 수행에 결정적으로 필요한 정보만 선택적으로 유지하도록 학습됩니다.
즉, Perceiver Resampler가 차원을 줄이면서도 중요한 특징을 보존할 수 있도록 최적화된다는 것입니다. 따라서 선형 투영 등의 과정에서 일부 정보 손실이 발생할 수 있지만, 학습 과정에서 유용한 특징만을 추출하고 유지하도록 모델이 조정됩니다.
III. GATED XATTN-DENSE Layer (Gated Cross-Attention Dense Layer)
Perceiver Resampler에서 변환된 이미지 토큰은 Cross-Attention Layer를 통해 언어 모델과 결합됩니다. 기존 사전 학습된 언어 모델을 수정하지 않고, 언어 모델 내부 계층 사이에 Cross-Attention Layer를 삽입하는 방식을 사용하여 시각적 정보를 통합합니다.
Gating Mechanism을 적용하여 시각적 정보가 필요한 경우에만 반영되도록 설계되었습니다.
즉, 모델이 스스로 판단하여 이미지 정보를 활용할지 결정하며, 불필요한 경우에는 기존 언어 모델처럼 동작합니다.
이러한 구조 덕분에 Flamingo는 텍스트만 입력되면 일반적인 언어 모델처럼 동작하고, 이미지가 함께 입력될 경우에는 시각적 정보를 활용하여 텍스트를 생성하는 유연한 방식을 따를 수 있습니다.
IV. 사전 학습된 대형 언어 모델 (Frozen Pretrained Language Model)
Flamingo는 기존 사전 학습된 언어 모델의 파라미터는 그대로 유지하면서, 추가된 Cross-Attention Layer를 통해 시각적 정보를 활용하여 텍스트를 생성합니다. 텍스트 입력만 주어질 경우, 일반적인 언어 모델처럼 동작하고 이미지가 함께 입력되면, 해당 정보를 활용하여 더 풍부한 텍스트를 생성하는 방식을 따릅니다.
🤔 그렇다면 주어진 데이터를 바탕으로 다시 학습하면 더 좋은 성능을 낼 수 있지 않을까?
재학습을 진행하면 성능이 향상될 수 있습니다. 하지만, 대규모 모델을 다시 학습하는 것은 엄청난 자원과 비용이 필요합니다. 게다가, Flamingo는 이미 텍스트 생성 능력을 갖춘 사전 학습된 대형 언어 모델을 사용하므로, 추가적으로 시각적 정보를 잘 반영하는 것만으로도 충분히 자연스러운 텍스트 생성을 수행할 수 있습니다.
Flamingo의 이러한 구조 덕분에, 기존 Vision-Language 모델들이 단순한 이미지-텍스트 매칭에 집중했던 것과 달리, Flamingo는 텍스트 내에서 이미지가 어떤 의미를 갖고 있는지까지 고려하여 문맥을 이해하고 적절한 응답을 생성할 수 있습니다.
이제 각 구성 요소에 대해 자세히 알아보도록 하겠습니다.
2-1. Vision Encoder
Flamingo는 Normalizer-Free ResNet (NFNet-F6)을 사용하며, 이 Vision Encoder는 사전 학습된 후 동결(frozen)되어 활용됩니다. 즉, 학습 시 Vision Encoder의 파라미터는 업데이트되지 않고, 사전 학습된 특징을 그대로 사용하여 입력 이미지의 표현을 추출합니다.
사전 학습
Vision Encoder는 처음(Scratch)부터 Language Encoder와 공동으로 학습되며, 이 과정에서 텍스트 인코더(Language Encoder)로 Transformer 대신 BERT 모델을 적용하여 텍스트 임베딩을 생성합니다. 이때 Vision과 Language 데이터 쌍은 공유되는 embedding space위에 표현됩니다.
실제 Flamingo 모델에서는 Vision Encoder의 가중치만 사용하고, Language Encoder는 사용하지 않습니다.
Contrastive Learning 과정에서는 이미지와 텍스트가 각각 Vision Encoder와 Language Encoder(BERT)로 변환된 후, 공유된 임베딩 공간으로 투영(projection)되어 L2 정규화를 거칩니다. 이후, Contrastive Loss를 적용하여 학습이 진행되며, CLIP과 유사하게 Text-to-Image Loss 및 Image-to-Text Loss의 두 가지 대조 손실을 사용하여 훈련됩니다.
이러한 과정을 통해 이미지와 언어 모델 간 관계를 최적화하여, 언어 모델이 시각적 정보를 자연스럽게 받아들일 수 있도록 설계되었습니다.
하이퍼파라미터
- 이미지 해상도: 288 × 288
- 공유 임베딩 공간 크기: 1376
- 배치 크기: 16,384
- 총 학습 스텝: 120만(각 스텝당 2개의 그래디언트 계산 단계 포함)
- 하드웨어: TPUv4 512개 사용
- 학습률 스케줄: 초기 10⁻³에서 선형적으로 0까지 감소
- 최적화 알고리즘: Adam 사용
- 데이터 증강: 랜덤 색상 변화 및 수평 반전 적용
| CLIP | Flamingo | |
|---|---|---|
| Vision Encoder | ViT-B/32 또는 RN50 | NFNet-F6 |
| Language Encoder | Transformer 기반 텍스트 인코더 | BERT |
| Contrastive Learning 목적 | 이미지-텍스트 유사도 학습 (이미지 검색 및 분류) | 이미지와 언어 모델 간 관계 학습 (VLM 최적화) |
| 데이터셋 | LAION-400M 등 웹 기반 이미지-텍스트 쌍 | ALIGN 및 LTIP 데이터셋 사용 |
| 출력 형태 | 이미지-텍스트 유사도 벡터 | 언어 모델과 결합할 수 있는 Feature Map |
입출력
I. 이미지 입력
Vision Encoder는 입력된 이미지를 처리하여 (Height, Width, Channel) 형태의 2D Feature Map을 출력합니다.
II. 비디오 입력
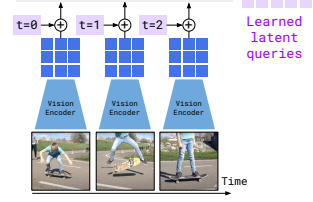
비디오 데이터의 경우, 초당 1프레임(1 FPS)씩 샘플링하여 개별 이미지처럼 처리한 후, 각 프레임의 Feature Map에 Temporal Embedding을 추가해 프레임 간의 순서 정보를 보존하는 3D Spatio-Temporal Feature을 출력합니다.
III. Output 변환
2D 또는 3D 데이터는 Flatten되어 1D 시퀀스로 변환되고 Perceiver Resampler를 통해 언어 모델과의 융합을 위한 최종 형태로 전달됩니다.
🤔 이미지는 보통 3D 텐서가 기본 아닌가요?
일반적인 이미지 데이터는 (Height, Width, Channel) 형태의 3D 텐서 구조를 갖습니다.
하지만, "Feature Map"이라는 용어는 공간적 특징(Height × Width)에 초점을 맞추는 표현이며, 최종 출력은 (Height, Width, Channel) 형태의 3D 텐서가 됩니다.
2-2. Perceiver Resampler
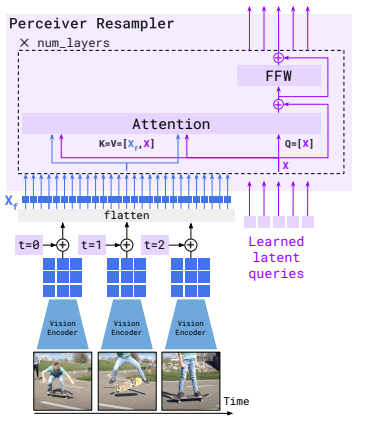
Flamingo의 Perceiver Resampler는 Vision Encoder에서 출력된 Feature Map을 고정된 개수(논문에서는 64개)의 시각적 토큰(Visual Tokens)으로 변환하는 핵심 모듈입니다. 입력된 이미지나 비디오의 크기(Feature Map)가 다르더라도 일정한 크기의 시각적 표현을 생성하여 언어 모델과 쉽게 결합할 수 있도록 변환하는 역할을 합니다.
Vision Encoder와 동결된(frozen) 언어 모델을 연결하는 중요한 가교 역할을 하며, 연산량을 최적화하면서도 시각적 정보를 효과적으로 유지하는 기능을 수행합니다.
Vision Encoder에서 추출된 Feature Map은 기본적으로 가변 크기의 고차원 데이터(Height × Width × Channel) 형태를 가지는데, 이러한 Feature Map을 언어 모델과 함께 처리하려면, 일정한 크기의 벡터로 변환하는 과정이 필요합니다. Perceiver Resampler는 이러한 역할을 수행하며, 고정된 크기의 시각적 표현을 생성함으로써 언어 모델이 시각적 정보를 효율적으로 처리할 수 있도록 돕습니다.
학습 과정
Flamingo의 Perceiver Resampler 모듈의 학습 과정은 다음과 같습니다.
I. 초기
- Perceiver Resampler는 64개의 학습 가능한 Latent Queries를 사용하여 Vision Feature와 Cross-Attention을 수행합니다.
- 초기에는 이 Latent Queries가 무작위 벡터(Random Vectors)로 설정되어 있으며, 입력 데이터와 아무런 연관이 없는 상태입니다.
II. 학습
- Vision Encoder에서 추출된 Flatten된 Feature Map(Key & Value)와 Latent Queries(Query) 간의 Cross-Attention이 수행됩니다.
- Attention Score를 통해, Feature Map에서 중요한 정보를 강조하고 불필요한 정보를 억제하는 방향으로 학습이 진행됩니다.
- 이를 통해, Latent Queries는 점점 중요한 시각적 정보를 요약하는 벡터로 최적화됩니다.
III. Latent Queries 생성
- 학습이 완료되면, Perceiver Resampler는 Vision Encoder에서 입력되는 다양한 크기의 Feature Map을 처리하면서도, 항상 64개의 시각적 토큰을 생성할 수 있도록 최적화됩니다.
- 이 과정에서, 언어 모델과 잘 결합될 수 있도록 필요한 정보만을 유지하는 방향으로 학습됩니다.
동작 과정
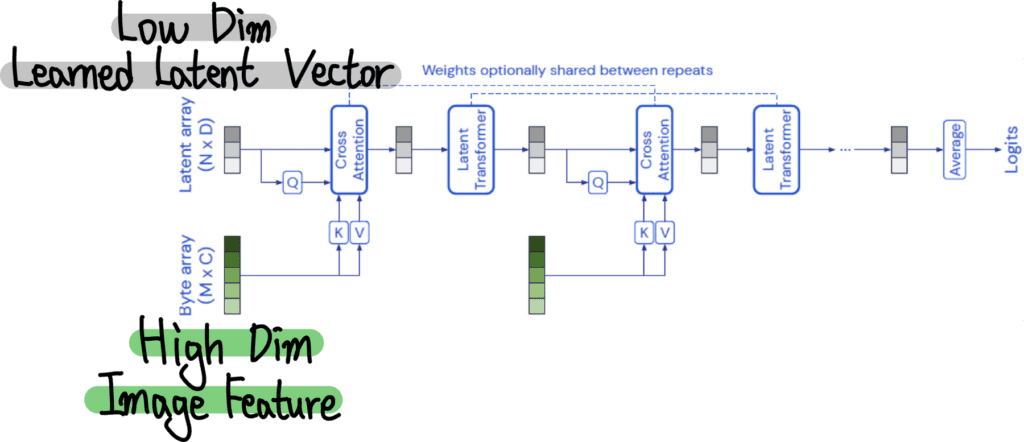
I. Feaute Map Flatten
Vision Encoder는 이미지는 2D Feature Map 비디오는 3D Feature Map형태로 데이터를 출력합니다.
Perceiver Resampler는 이를 Transformer 기반 모델에서 처리할 수 있도록 Flatten 과정을 거쳐 1D 시퀀스로 변환합니다.
II. Cross-Attention
Flatten된 Feature Map은 크기가 크고 정보량이 많기 때문에, 이를 압축하여 중요한 정보를 추출하는 과정이 필요합니다.
Perceiver Resampler는 사전 정의된 64개의 Latent Queries를 활용하여, Feature Map과 Cross-Attention을 수행하는 방식으로 중요한 정보를 선택적으로 추출합니다.
🤔 무엇을 Q, K, V로 설정해야 할까?
- Query (Q): Latent Queries
- Key (K) & Value (V): Vision Encoder에서 Flatten된 Feature Map
Cross-Attention을 수행하면서 Latent Queries는 Feature Map에서 중요한 정보를 강조하고 불필요한 정보를 억제해서 Feature Map에서 중요한 정보만 추출합니다.
III. 최종적으로 64개의 시각적 토큰을 출력
Cross-Attention을 수행한 후, Perceiver Resampler는 고정된 64개의 시각적 토큰을 생성하며, 이를 Gated Cross-Attention Layer로 전달합니다.
이 시각적 토큰들은 언어 모델과 결합할 수 있도록 최적화된 형태로 변환되며, 이후 텍스트와 이미지 간의 관계를 학습하는 과정으로 이어집니다.
2-3. GATED XATTN
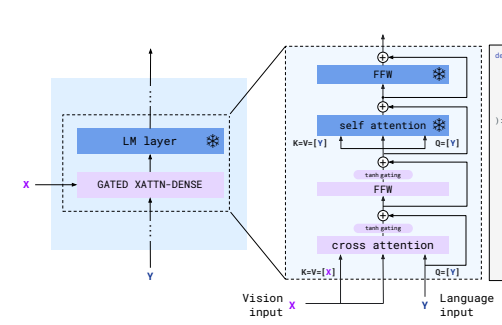
def gated_xattn_dense(
y, # input language features
x, # input visual features
alpha_xattn, # xattn gating parameter – init at 0.
alpha_dense, # ffw gating parameter – init at 0.
):
"""Applies a GATED XATTN-DENSE layer."""
# 1. Gated Cross Attention
y = y + tanh(alpha_xattn) * attention(q=y, kv=x)
# 2. Gated Feed Forward (dense) Layer
y = y + tanh(alpha_dense) * ffw(y)
# Regular self-attention + FFW on language
y = y + frozen_attention(q=y, kv=y)
y = y + frozen_ffw(y)
return y # output visually informed language features
Flamingo의 Gated XAttn-Dense Layer(Gated Cross-Attention Dense Layer)는 Perceiver Resampler에서 생성된 64개의 시각적 토큰(Visual Tokens)을 언어 모델과 결합하는 핵심 모듈입니다.
기존의 텍스트만 처리하던 Transformer 기반 모델에서 이미지 정보를 추가해 정보를 처리하기 위해 Cross-Attention Layer를 삽입 하였으며 Gating Mechanism을 적용하여 시각적 정보가 필요한 경우에만 반영될 수 있도록 최적화되었습니다.
여기서 주의해야 할 점은 기존 언어 모델 블록(LM blocks)은 동결(frozen)된 상태로 유지되며, 새롭게 추가된 Gated XAttn-Dense Layer만 학습 가능한 상태로 추가됩니다.
동작 과정
I. Cross-Attention Layer
기존의 Transformer 언어 모델은 Self-Attention만 수행하여 텍스트 간 관계를 학습합니다.
하지만, Flamingo에서는 새로운 Cross-Attention Layer를 삽입하여, Perceiver Resampler에서 생성된 시각적 정보를 통합할 수 있도록 확장하였습니다.
즉, 기존의 Self-Attention만 수행하는 구조에서 Self-Attention + Cross-Attention이 결합된 구조로 변경되었습니다.
✅ Cross-Attention 수행 방식
- Query (Q): 언어 모델에서 처리 중인 텍스트 토큰
- Key (K) & Value (V): Perceiver Resampler에서 생성된 64개의 시각적 토큰
- 출력: 텍스트와 이미지 정보를 통합하여 언어 모델의 Hidden Representation을 업데이트
Cross-Attention을 수행함으로써, 언어 모델은 텍스트와 시각적 정보 간의 연관성을 학습하며,
이미지에서 추출된 중요한 정보가 텍스트 생성에 어떻게 기여해야 하는지 파악할 수 있습니다.
II. 모달리티 융합
Gated XAttn-Dense Layer의 핵심은 텍스트와 이미지 정보가 어떻게 연관되어 있는지를 학습하는 Cross-Attention 메커니즘입니다.
기존 Transformer의 Self-Attention은 입력된 텍스트 간의 관계를 학습하는 역할을 수행하지만,
Flamingo의 Cross-Attention은 텍스트와 이미지 사이의 연관성을 학습하는 역할을 담당합니다.
✅ Cross-Attention에서 학습되는 정보
- 주어진 텍스트(예: "이 그림 속 동물은 무엇인가?")가 어떤 시각적 정보와 연관이 있는지 학습
- Perceiver Resampler에서 생성된 64개의 시각적 토큰 중 어떤 정보가 가장 중요한지 Attention Score를 기반으로 선택
- 이 과정에서, Attention Score가 높은 시각적 토큰이 더 강조되고, 낮은 시각적 토큰은 억제됨
✅ Cross-Attention 수식 개념 (Scaled Dot-Product Attention)
Cross-Attention은 Transformer 모델의 Attention 메커니즘과 동일하게 다음과 같이 정의됩니다.
여기서,
- Q (Query): 언어 모델의 Hidden Representation (텍스트 토큰 임베딩)
- K (Key) & V (Value): Perceiver Resampler에서 생성된 64개의 시각적 토큰
✅ Cross-Attention이 수행하는 과정
1. 텍스트 임베딩(Query)과 시각적 토큰(Key, Value) 간의 유사도를 계산
2. Attention Score를 통해, 텍스트와 연관성이 높은 시각적 정보를 강조
3. 강조된 시각적 정보를 반영하여 언어 모델의 Hidden Representation을 업데이트
4. 업데이트된 Hidden Representation이 텍스트 생성 과정에서 활용됨
결과적으로, 텍스트와 시각적 정보 간의 연관성이 모델 내에서 학습되며, 이를 통해 보다 정밀한 텍스트 생성이 가능해집니다.
III. Tanh-Gating Mechanism
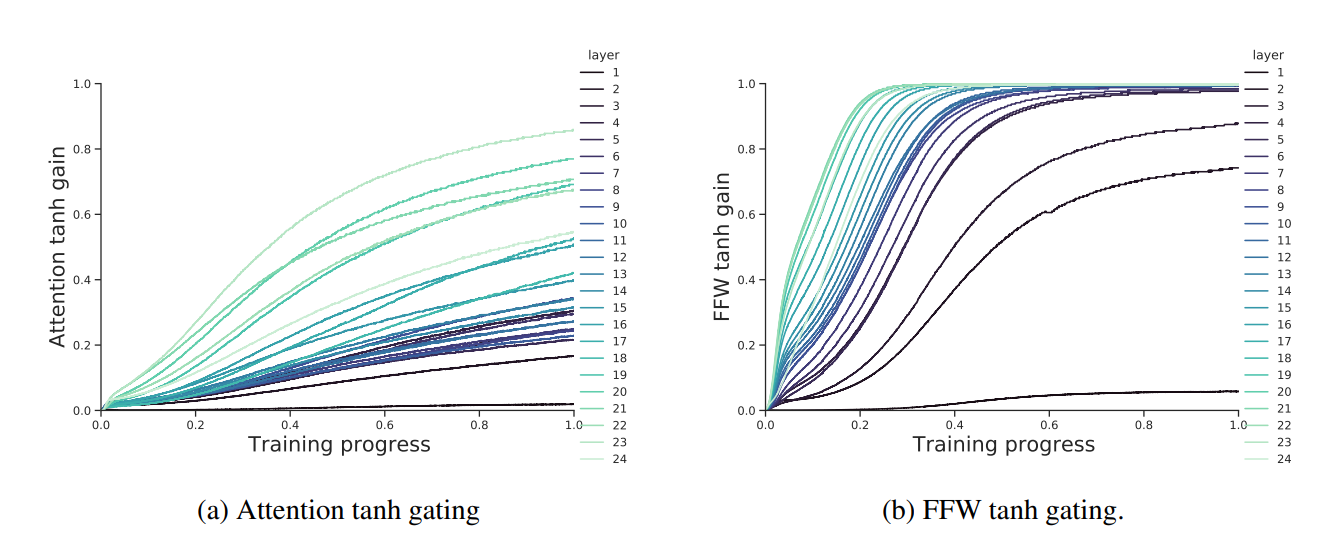
Flamingo에서는 기존의 언어 모델 성능을 유지하면서 시각적 정보를 점진적으로 반영할 수 있도록 Tanh-Gating Mechanism을 적용하였습니다.
✅ Tanh-Gating Mechanism의 역할
- Gated XAttn-Dense Layer의 출력을 기존 언어 모델에 추가할 때, Tanh(𝛼)로 조절하여 점진적으로 학습
- 학습 초기에 𝛼를 0으로 설정하여 Cross-Attention의 영향을 최소화
- 학습이 진행될수록, 𝛼가 점진적으로 증가하면서 Cross-Attention의 영향이 커짐
✅ Tanh-Gating Mechanism의 장점
- 기존 언어 모델을 방해하지 않고, 새로운 Cross-Attention Layer가 점진적으로 학습됨
- 학습 초기에 기존 모델의 성능을 유지하면서, 점진적으로 시각적 정보가 반영되도록 조정
학습 방식
✅ 1️⃣ Cross-Attention을 통해 텍스트와 시각적 정보 간의 매칭을 학습
- Perceiver Resampler에서 생성된 시각적 토큰과 언어 모델의 텍스트 토큰 간 Attention Score를 학습하여, 어떤 이미지 정보가 중요한지 파악
✅ 2️⃣ Gating Mechanism을 최적화하여, 시각적 정보 반영 여부를 동적으로 조절
- 학습 과정에서, 언어 모델이 시각적 정보를 어느 정도 반영해야 할지를 스스로 결정하도록 최적화
- 이를 통해, 언어 모델이 필요한 경우에만 시각적 정보를 활용하고, 불필요한 경우에는 기존 텍스트 생성 방식대로 동작
✅ 3️⃣ 최종적으로, 이미지와 텍스트 정보를 결합하여 자연스러운 텍스트를 생성하도록 학습
- 학습이 진행될수록, 언어 모델은 이미지에서 추출된 정보를 활용하여 더 정밀한 텍스트를 생성할 수 있도록 최적화
2-4. Pre-trained LM
2-5. Few-Shot Learning
참고자료
BLIP (2022) 논문 리뷰
https://velog.io/@choonsik_mom/BLIP-2022-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0#model-architecture--pretraining-objectives
