
1. Intro
CLIP: Contrastive Language-Image Pretraining
본 논문에서는 이미지와 텍스트라는 서로 다른 모달리티의 데이터를 융합하여, 두 영역 간의 의미적 연관성을 효과적으로 학습하고 새로운 데이터나 개념에 대해서도 우수한 성능을 보이는 모델, CLIP (Contrastive Language-Image Pretraining)을 제안합니다.
최근 자연어처리(NLP) 분야에서는 대규모 사전학습을 통해 지도학습 없이도 다양한 태스크를 성공적으로 수행할 수 있는 반면, 컴퓨터 비전은 여전히 라벨링된 데이터셋에 크게 의존하고 있습니다.
이로 인해 새로운 도메인이나 데이터에 대한 적응력과 일반화 능력에서 차이가 발생합니다.
이번 글 에서는 NLP 분야에서 입증된 학습 기법들이 컴퓨터 비전에도 어떻게 적용될 수 있는지를 살펴보고, 그 대표적 사례로 주목받는 CLIP 모델에 대해 알아보고자 합니다.
1-1. 자연어처리 학습 방식
자연어처리 분야에서는 초기부터 방대한 양의 raw text를 활용해 모델을 사전 학습하는 기법들이 꾸준히 발전해 왔습니다. 이러한 접근법은 모델이 특정 태스크에 국한되지 않고 다양한 문제를 해결할 수 있도록 일반적인 언어의 패턴과 구조를 학습하는 데 중점을 두고 있습니다.
특히, task-agnostic 학습과 Text-to-text 접근법을 통해 모델의 범용성과 유연성이 크게 향상되었습니다.
I. Task-agnostic 학습
특정 태스크에 종속되지 않고 다양한 문제에서 활용 가능한 일반적 패턴을 학습합니다.
예시)
Masked Language Modeling (MLM)은 문장에서 일부 단어를 가리고 이를 예측함으로써, 언어의 구조와 의미에 대한 일반적인 패턴을 학습하도록 설계되었습니다.
II. Text-to-text 접근법
모든 태스크를 동일한 텍스트 입력-출력 형식으로 변환해 처리합니다.
예시)
번역, 요약, 문서 분류 등 서로 다른 태스크를 동일한 포맷으로 처리함으로써,
별도의 모델 구조를 설계할 필요 없이 하나의 통합된 방식으로 문제를 해결할 수 있습니다.
이러한 발전 덕분에, GPT-3와 같은 모델은 라벨링된 데이터셋 없이도 다양한 태스크에서 우수한 성능을 발휘할 수 있게 되었습니다.
1-2. 컴퓨터 비전
반면, 컴퓨터 비전 분야는 여전히 라벨링된 데이터셋에 의존한 지도 학습 방식에 머무르고 있습니다.
이로 인해 다음과 같은 문제들이 발생합니다.
I. 새로운 데이터
기존 모델들은 학습한 데이터셋에서 최적화된 방식으로만 작동하도록 설계되었습니다.
즉, 새로운 도메인이나 기존과 전혀 다른 유형의 데이터가 들어오면 성능이 급격히 저하됩니다.
이는 기존 모델이 훈련된 데이터셋 내에서만 잘 작동하도록 설계되었기 때문입니다.
따라서 새로운 데이터가 주어질 때 이를 위해 이를 위한 추가적으로 학습이 필요합니다.
하지만 데이터가 추가될 때마다 다시 학습을 진행하는 것은 매우 비효율적인 방식입니다.
예시)
ImageNet 모델을 새로운 데이터셋에서 평가했을 때 성능이 11~14% 감소 (Recht et al., 2019)
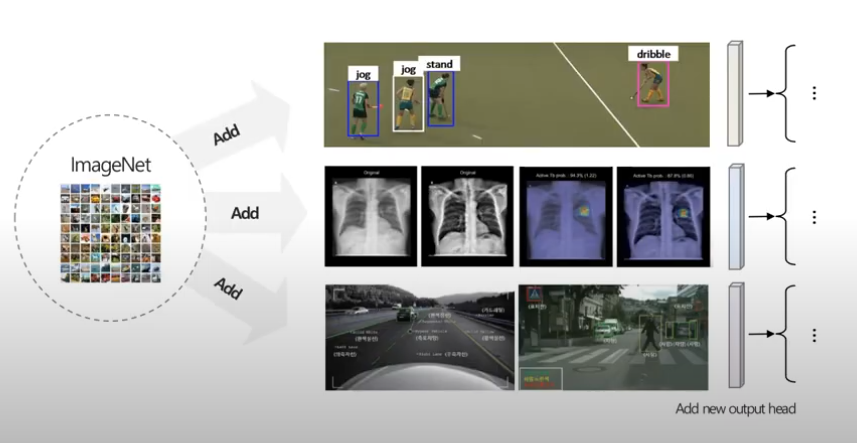
II. 일반화
기존 데이터와 약간의 차이가 있는 데이터가 들어오면 일반화 성능이 크게 떨어지는 문제가 있습니다. 즉, 학습된 데이터와 비슷한 개념을 포함한 데이터임에도 불구하고 모델이 제대로 분류하지 못하는 경우가 많습니다.
이는 기존 모델이 데이터셋의 특정한 특성(조명, 배경, 스타일 등)에 의존하여 학습되었기 때문입니다. 즉, 훈련된 데이터셋 내에서는 잘 작동하지만, 실생활에서는 다양한 변형이 존재하므로 일반화 성능이 낮아지는 한계가 존재합니다.
이를 위해 추가적인 데이터 수집과 학습이 필요하다는 문제가 있습니다.
예시)
ImageNet에서 학습된 모델은 다양한 고양이 품종을 구분할 수 있지만, 야생 고양이나 그림 형태의 고양이를 정확하게 분류하지 못할 가능성이 높습니다.
즉, 작은 변형(조명 변화, 색 변화)에도 모델이 쉽게 속습니다. (Hendrycks et al., 2019)

III. 데이터 라벨링
지도 학습(Supervised Learning) 기반의 기존 모델들은 사람이 직접 라벨링한 데이터를 필요로 합니다. 즉, 모델이 학습할 데이터를 제공하려면 대량의 이미지에 사람이 직접 레이블을 지정하는 작업이 필요합니다.
이는 현실적으로 매우 비효율적인 방식이며, 새로운 데이터셋을 만들 때마다 막대한 시간과 비용이 소요됩니다.
예시)
실제로 ImageNet(1.4M 개의 이미지) 데이터셋을 구축하는 과정에서는 수만 명의 크라우드소싱 작업자가 참여해야 했으며, 수십만 개의 이미지를 사람이 직접 검토하고 라벨링하는 과정이 필요했습니다.ImageNet 데이터셋을 구축하는 데 25,000시간 이상의 인력이 필요합니다. (Russakovsky et al., 2015)
1-3. 다양한 방법론
“자연어처리처럼 라벨 없이 학습할 수는 없을까?”라는 의문에서 출발하여, 컴퓨터 비전 분야에서도 라벨링 없이 효과적으로 학습할 수 있는 방법에 대한 연구가 시작되었습니다.
초기 연구에서는 지도학습 없이 이미지 표현을 학습하려는 다양한 접근법이 제안되었으나, 그 성능은 기존 지도학습 방식에 비해 크게 뒤처졌습니다.
예시)
“Learning Visual N-Grams from Web Data” (Li et al., 2017)은 웹 데이터만을 사용해 학습한 결과, ImageNet 분류 정확도가 11.5%에 머무는 한계를 보였습니다.반면, 최신 최고 성능 모델인 Self-training with Noisy Student (Xie et al., 2020)는 지도학습 기반 모델로서 88.4%의 정확도를 달성하며 큰 차이를 나타냈습니다.
이와 같이, 텍스트 정보를 활용하여 이미지 표현을 학습하는 초기 방법론은 다른 접근법에 비해 성능이 좋지 않아 연구가 활발하게 진행되지 않았습니다.
이처럼 텍스트 정보를 활용해 이미지 표현을 학습하려는 초기 시도들은 기대에 미치지 못해 연구가 제한적이었으나, 이후 Weak Supervision 방식을 도입하면 라벨 없이도 효과적으로 모델을 학습시킬 수 있다는 가능성이 제시되었습니다.
초기의 Weak Supervision 기반 모델들은 대체로 약 20만 개의 이미지를 사용하여 학습하였고 이 역시 성능에 한계가 있었습니다.
그러던 도중 데이터의 규모(scale)를 대폭 확장하면 이러한 한계를 극복할 수 있다는 아이디어가 등장하게 되었습니다.
2. CLIP
이러한 아이디어를 바탕으로, 웹에서 손쉽게 수집한 방대한 데이터를 활용하여 4억 개의 이미지-텍스트 페어를 구축하는 접근법이 도입되었습니다.
이 방법은 단순히 이미지에서 특징을 추출하는 전통적인 방식에서 벗어나, 텍스트와 이미지를 동시에 학습하여 두 모달리티 간의 연관성을 효과적으로 포착하는 데 중점을 두고 있습니다.
특히, 기존의 ConVIRT (Contrastive Visual Representation Learning) 접근법을 확장한 형태로 개발된 것이 바로 CLIP입니다.
CLIP은 기존 컴퓨터 비전 모델들이 대규모 라벨링 데이터셋에 의존해 학습하는 것과 달리, 자연어 설명을 활용해 이미지를 학습함으로써 Zero-shot Learning이 가능하도록 설계되었습니다.
이제 CLIP의 구조와 학습 방식에 대해 자세히 알아보기 전에, 우선 어떤 방식으로 데이터를 수집했는지부터 살펴보겠습니다.
2-1. 데이터 수집
CLIP은 OpenAI가 구축한 WebImageText(WIT) 데이터셋을 기반으로 학습되었으며, 데이터 수집 과정은 다음과 같습니다.
I. 웹 크롤링(Web Scraping) 활용
인터넷에서 자연어 설명과 함께 등장하는 이미지를 자동으로 수집합니다.
예시)
블로그, 뉴스 기사, SNS, Wikipedia 등에서 데이터를 확보합니다.
II. 검색 기반 필터링(Query-based Filtering)
특정 단어를 포함하는 이미지-텍스트 쌍을 검색하여 수집합니다.
즉, 단순히 웹에서 무작위 데이터를 가져오는 것이 아니라 키워드를 기반으로 관련성 높은 이미지-텍스트 쌍을 필터링하여 수집하는 방식입니다.
이 과정에서 CLIP은 Wikipedia에서 추출한 500,000개 이상의 단어 및 구문을 검색 키워드로 활용하여 보다 다양한 데이터를 확보합니다.
예시)
"dog"이라는 키워드를 검색하면 강아지 관련 이미지와 설명이 포함된 데이터만 선택됩니다.
"Eiffel Tower" 키워드가 포함된 경우, 해당 구조물과 관련된 이미지와 설명을 자동으로 매칭하여 수집됩니다.
III. 데이터 정제 및 품질 관리
수집된 데이터의 품질을 유지하기 위해 불필요한 데이터를 제거하는 과정을 거칩니다.
- 텍스트 설명이 의미 없는 데이터(예: "IMG_1234")인 경우 필터링합니다.
- 자동 생성된 메타데이터(예: 카메라 설정 정보) 및 불필요한 정보를 제거합니다.
- 영어 기반의 데이터만 사용하여 모델을 학습합니다.
위의 과정을 통해 CLIP은 사람이 직접 라벨링한 데이터가 아니라, 웹에서 자연스럽게 생성된 이미지-텍스트 데이터를 활용하여 학습된다는 점에서 기존 비전 모델들과 차별화됩니다.
2-2. 대조 학습
이렇게 데이터를 모은 후, 이제 학습 방법에 대해 고민해야 했습니다.
기존의 ImageNet 데이터셋처럼 Cross Entropy Loss를 사용해 학습할 수 없는 문제가 발생합니다. 자연어가 정해진 라벨과 달리 특정하게 구분되지 않는 시퀀스 데이터이기 때문입니다. 각 이미지에 매칭된 설명 문장이 모두 다르므로, Softmax로 구분하는 방식의 학습 방법은 적용할 수 없습니다.
이러한 문제를 해결하기 위해 최종적으로 채택한 방법은 Contrastive Learning (대조 학습)입니다.
대조 학습은 지도 학습에서 같은 클래스에 속하는 예제들은 서로 비슷한 특성을 가져야 하고, 다른 클래스의 예제들은 구분되어야 한다는 가정을 바탕으로 학습됩니다.
다음으로, 지도 학습, 자기 지도 학습 및 CLIP에서 활용된 자연어 감독 방식에 대해 살펴보겠습니다.
I. 지도 학습 (Supervised Learning)
지도 학습에서는 명시적인 클래스 라벨을 활용하여 데이터를 학습합니다.
이때 배치 내의 각 샘플은 하나의 기준점(Anchor)으로 사용됩니다. 기준점을 중심으로, 동일한 클래스에 속하는 다른 샘플들은 positive pair로 간주되어 서로 끌어당겨지도록(pull),
기준점과 다른 클래스에 속하는 샘플들은 negative pair로 지정되어 서로 멀어지도록(push) 학습됩니다.
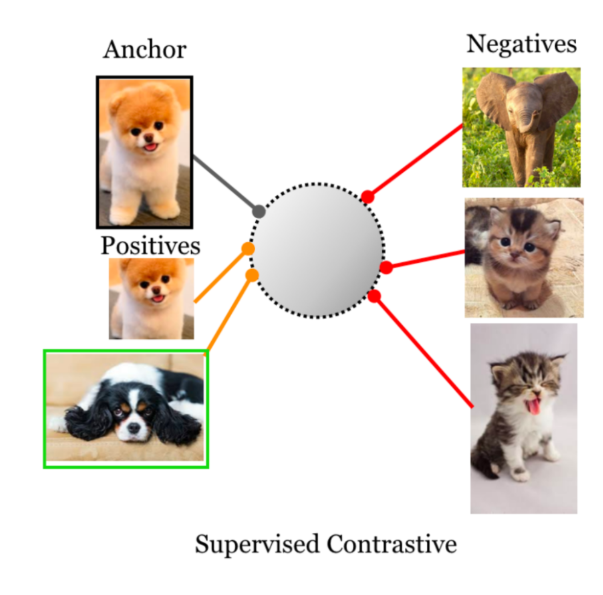
이러한 개념을 바탕으로 만들어진 손실 함수인 SCL(Supervised Contrastive Loss)는 다음과 같이 계산됩니다.
: 번 샘플의 임베딩 벡터
: 와 같은 라벨을 가진 positive 샘플들의 인덱스 집합
: 배치에서 를 제외한 모든 샘플 (즉, positive와 negative 모두 포함)
: 온도 파라미터로, 유사도 분포의 민감도를 조절합니다.
: 코사인 유사도 (Cosine similarity)
이를 통해 배치 내의 각 샘플은, 자신과 같은 클래스에 속하는 다른 샘플들과의 유사도는 높이고, 다른 클래스에 속하는 샘플들과의 유사도는 낮추도록 학습됩니다.
🤔 내적 vs 코사인 유사도
내적은 두 벡터의 크기와 방향을 모두 반영합니다.
즉, 벡터의 방향(패턴, 특징 등)의 유사성뿐만 아니라, 벡터의 크기(활성화 강도, 연관성의 강도)도 함께 고려합니다.
이로 인해, 동일한 방향을 가지더라도 한 벡터의 크기가 더 크면 내적 값은 더 커지게 됩니다.코사인 유사도는 각 벡터를 정규화하여 계산되므로, 벡터의 크기의 영향을 제거하고 오직 방향만 반영합니다.
즉, 벡터가 나타내는 의미적 패턴이나 특징의 일치도만을 비교합니다.정리해 보자면, SCL에서는 샘플 간 얼마나 강하게 닮았는가는 불필요하고, 오직 샘플들이 '닮았다는 사실'이 중요하기 때문에 코사인 유사도를 사용하여 샘플의 구분을 명확하게 수행합니다.
II. 자기 지도 학습 (Self-Supervised Learning)
자기 지도 학습은 명시적인 라벨 없이 데이터 자체에서 학습 신호를 생성하여 모델이 스스로 의미 있는 표현을 학습하도록 하는 방법입니다. 특히, 라벨링된 데이터가 부족하거나 확보하기 어려운 상황에서 효과적입니다.
이 방식에서는 각 원본 데이터(Anchor)를 다양한 augmentation 기법(크롭, 회전, 색상 변화 등)을 통해 여러 버전으로 생성합니다. 한 원본 샘플의 여러 변형은 서로 positive pair로 서로 다른 원본의 변형은 negative pair로 처리됩니다.

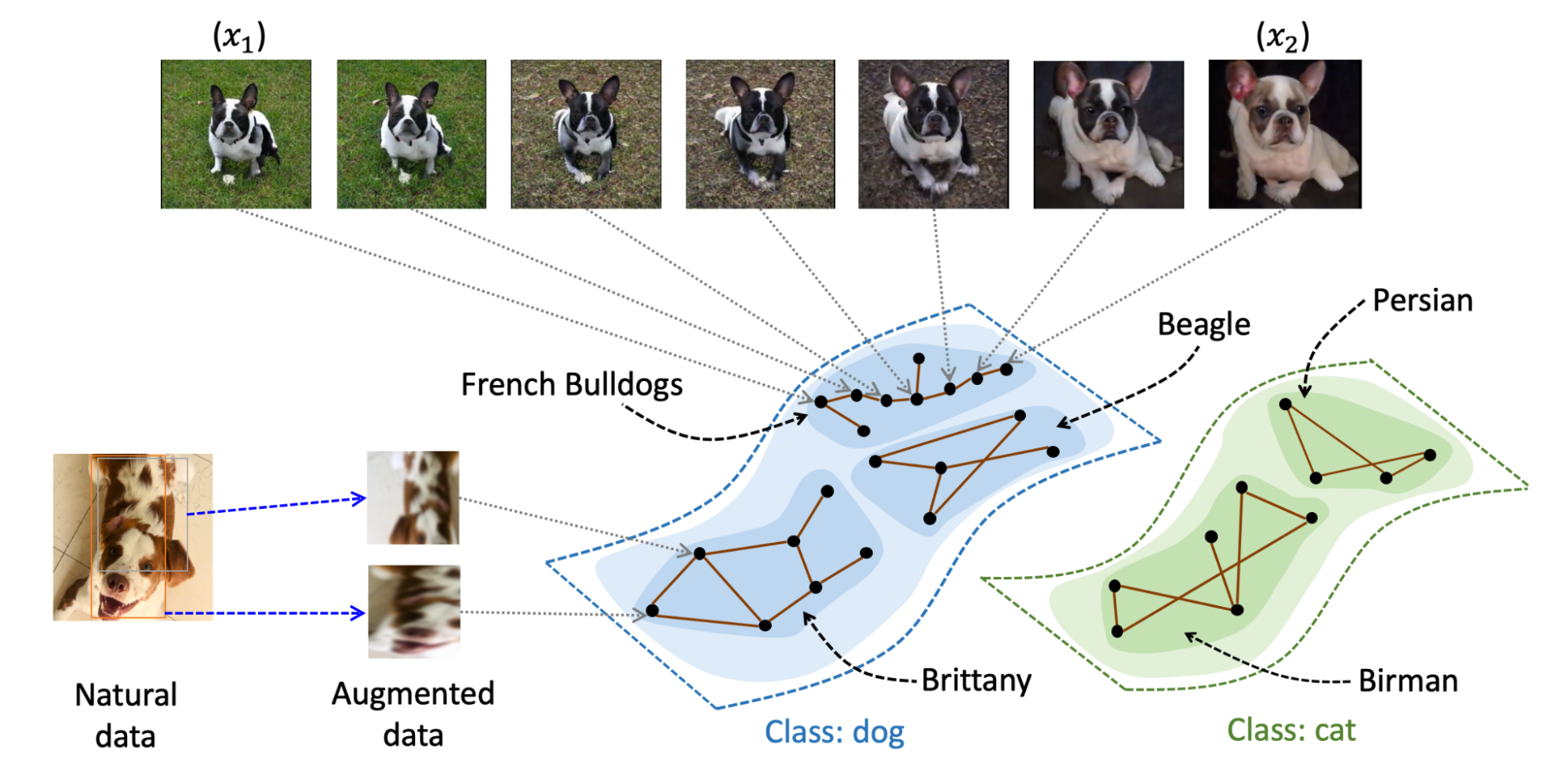
자기 지도 학습에서는 이러한 개념을 바탕으로 손실 함수를 정의합니다.
: 의 임베딩 벡터
: 원본 샘플 로부터 생성된 다양한 augmented view들을 포함하는 positive 집합
: 배치 내에서 를 제외한 모든 샘플 (positive와 negative 모두 포함)
: 온도 파라미터
: 코사인 유사도(Cosine similarity)
이 방식은 라벨 없이 데이터 augmentation을 통해 생성된 다양한 샘플 간의 내재된 구조와 의미적 패턴을 학습하게 하며, 대규모 데이터를 활용할 수 있기 때문에 데이터 확보 비용을 절감하고 모델의 강건성을 높일 수 있습니다.
다만, 라벨이 없어 서로 다른 원본 데이터 간에 의미적으로 유사한 경우에도 negative로 잘못 처리되는 false negative 문제가 발생할 수 있습니다.
🤔 비슷한 유형의 데이터들을 어떻게 처리할까?
클러스터링 기법
임베딩 공간에서 데이터 샘플들을 의미적으로 그룹화하는 방법입니다.
비슷한 특징이나 패턴을 공유하는 샘플들을 하나의 클러스터로 묶어, 서로 매우 유사한 샘플들이 강제로 negative pair로 처리되지 않도록 합니다.
그 결과, 동일 클래스의 샘플들은 임베딩 공간에서 서로 가깝게 모여 클러스터를 형성하며, 서로 다른 클래스의 샘플들은 멀어져 모델이 각 클래스의 경계를 명확히 인식할 수 있게 됩니다.
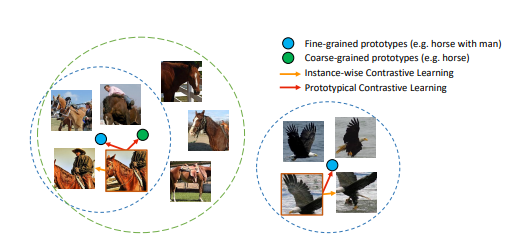
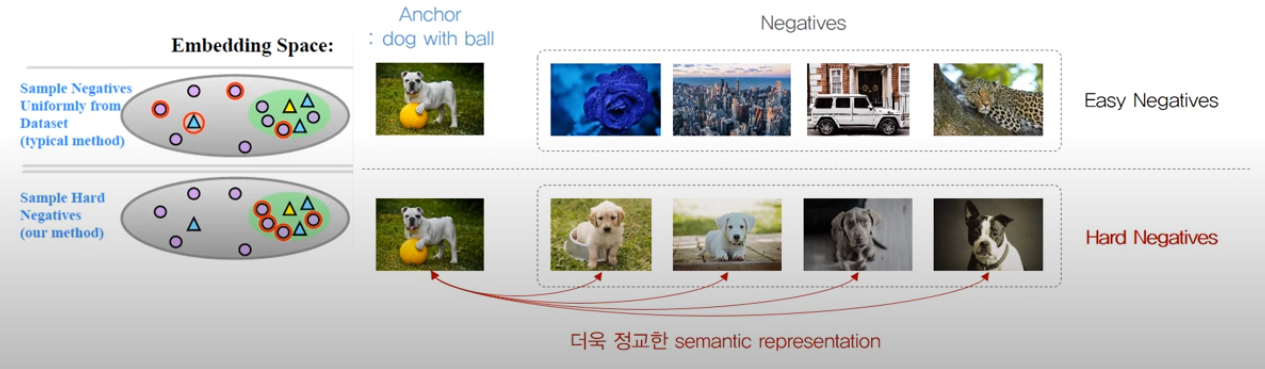
하드 네거티브 마이닝
배치 내에서 기준 샘플과의 유사도가 예상보다 높은 negative 샘플들을 선별하여 별도로 다루는 방법입니다.
모델이 쉽게 구분할 수 있는 negative는 그대로 두고, 구분하기 어려운 하드 네거티브에 대해 추가 학습 신호를 제공합니다.
False Negative Cancellation
False Negative를 제거하거나, Positive로 포함하는 방법입니다.
잘못된 Negative Pair를 제거하고, 임베딩 공간에서 더욱 정확한 표현 학습을 가능하게 합니다.
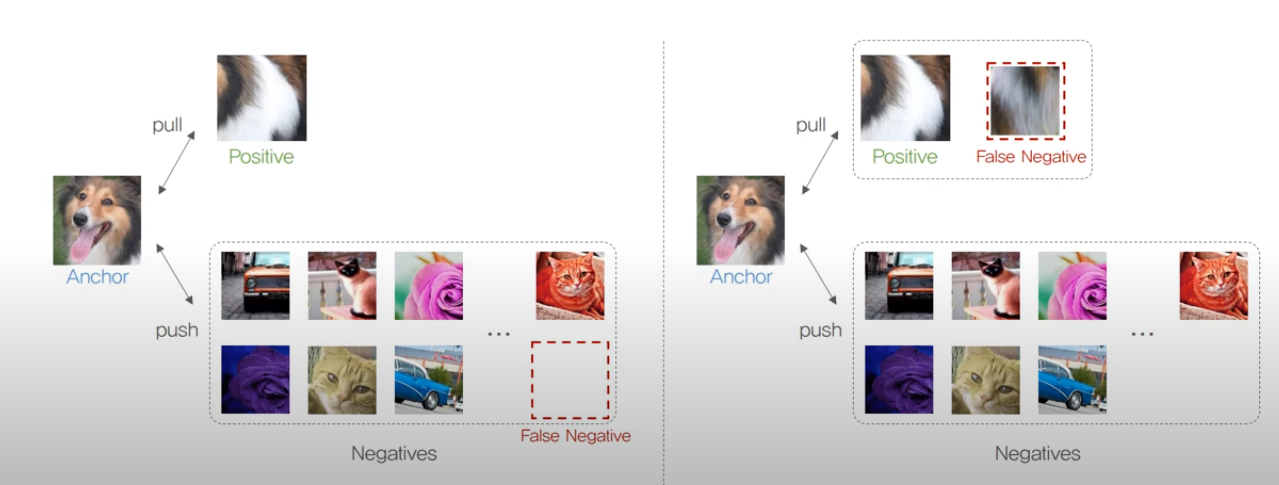
III. 자연어 감독 (Natural Language Supervision)
CLIP은 명시적인 라벨 없이도 웹에서 수집된 이미지와 그에 자연스럽게 연결된 텍스트(캡션)을 활용합니다.
여기서 각 이미지와-텍스트 쌍이 하나의 positive pair로 간주되어, 두 모달리티가 동일한 임베딩 공간에서 서로 가깝게 배치되도록 학습됩니다. 반면, 서로 다른 이미지-텍스트 쌍은 negative pair로 처리되어 임베딩 공간에서 서로 멀어지도록 조정됩니다.
: 번 이미지 혹은 텍스트 샘플의 임베딩 벡터
: 이미지 또는 텍스트 와 자연스럽게 연결된, 즉 동일 원본의 캡션 또는 augmentation 결과로 구성된 positive 집합
: 배치 내에서 를 제외한 모든 샘플(positive와 negative 모두 포함)
: 온도 파라미터
: 코사인 유사도 (Cosine similarity)
이 손실 함수를 통해 이미지와 텍스트(캡션)는 동일한 의미 정보를 공유하도록 임베딩 공간 내에서 정렬되고, 서로 다른 이미지-텍스트 쌍은 분리됩니다. 이렇게 하면 모델은 이미지와 텍스트 사이의 의미적 연결 고리를 자연스럽게 익히게 되어, 다양한 도메인과 표현 방식에서도 공통된 특징을 잘 파악할 수 있습니다.
이로써 CLIP은 사전에 학습하지 않은 새로운 개념이나 클래스에도 유연하게 대응할 수 있는 범용적인 표현을 획득하며, Zero-Shot Classification과 같은 작업에서 뛰어난 성능을 발휘하게 됩니다.
Zero-Shot
모델이 사전 학습 데이터에 없는 새로운 개념이나 클래스를 추가 학습 없이 이해하는 능력을 의미합니다.예시)
"얼음 위를 걷는 북극곰"이라는 문장을 직접 학습한 적이 없더라도, "곰"과 "얼음"에 대한 개념을 이미 습득했다면 이에 맞는 이미지를 찾아낼 수 있습니다.
결과적으로 자연어 감독 방식을 통해 새로운 데이터, 일반화, 데이터 라벨링 비용에 대한 문제를 해결하게 됩니다.
지금까지 다뤄온 Contrastive Learning은 이미지라는 단일 모달리티에 초점을 맞추어 학습되었기 때문에 하나의 벡터만 고려하면 되었습니다. 하지만 자연어 감독 방식에서는 이미지와 텍스트라는 서로 다른 모달리티를 함께 다루게 됩니다.
즉, 두 가지 모달리티에 대해 각각의 벡터를 생성하고 이를 비교해야 합니다.
이에 대한 방법은 CLIP의 모델 구조(Model Architecture)에서 다루도록 하겠습니다.
2-3. 모델 구조
CLIP은 이미지와 텍스트 같은 서로 다른 모달리티에서 정보를 추출해, 동일한 임베딩 공간에 정렬하는 방식을 채택합니다. 이를 위해 CLIP은 이미지 인코더와 텍스트 인코더를 별도로 구성한 후, 각 모달리티에서 추출한 특징을 학습 가능한 선형 프로젝션을 통해 동일한 차원의 벡터로 매핑합니다.
🤔 서로 다른 모달리티는 어떻게 비교할까요?
이미지와 텍스트에서 추출한 임베딩은 각각 차원이나 분포가 다를 수 있으므로, 이를 동일한 임베딩 공간에 맞추는 과정이 필요합니다.
CLIP은 이를 위해 각 인코더의 출력에 학습 가능한 선형 프로젝션 계층을 적용합니다.
이 선형 프로젝션은 형태의 완전 연결(FC) 층을 통해 수행됩니다.이렇게 이미지와 텍스트 임베딩을 동일한 차원(예: 512차원)으로 변환하면, 두 모달리티 간의 내적이나 코사인 유사도를 계산할 수 있어 대조 학습의 핵심인 의미적 정렬을 효과적으로 수행할 수 있습니다.
참고: 선형 변환은 정보를 재구성하거나 차원을 맞추며, 학습 가능한 매핑을 통해 중요한 특징을 강조하는 데 주로 사용됩니다.
I. 이미지 인코더 (Image Encoder)
이미지의 특징을 효과적으로 추출하기 위해 두 가지 주요 아키텍처로 CNN 기반의 ResNet과 Vision Transformer(ViT) 기반 모델을 실험했습니다.
ResNet
ResNet-50 등 기존 CNN 구조를 활용하여 이미지 특징을 추출하였고 여러 변형 모델로 스케일을 조절해 연산 효율성을 높였으며RN50,RN101,RN50x4,RN50x16,RN50x64모델을 사용하였습니다.
하지만, Zero-shot Transfer와 같은 일반화 성능에서는 한계가 있었습니다.
ViT
Transformer 기반의 ViT는 이미지를 고정 크기의 패치로 분할한 후, 각 패치를 시퀀스로 처리하여 전체 이미지에 대한 정보를 동시에 학습해 장기적 의존성을 학습할 수 있어 Zero-shot Transfer 성능에서 우수한 결과를 보였습니다.
ViT-B/32,ViT-B/16,ViT-B/14모델을 사용하였습니다.
하지만, 연산량과 메모리 요구량이 상대적으로 증가하였습니다.
CLIP은 ResNet과 ViT라는 두 가지 상이한 이미지 인코더를 활용해, 멀티모달 학습의 효과를 다양한 모델 아키텍처에서 검증하였으며, ViT 기반 모델이 Zero-shot 성능 면에서 특히 뛰어난 결과를 나타냄을 확인할 수 있었습니다.
II. 텍스트 인코더 (Text Encoder)
CLIP의 텍스트 인코더는 Transformer 모델을 사용하여 문장을 벡터로 변환합니다.
하지만 일반적인 Transformer는 모든 단어(토큰) 간의 관계를 계산해야 하므로, 문장이 길어질수록 연산량이 급격히 증가하는 문제가 있습니다.
이 문제를 해결하기 위해 CLIP을 Sparse Transformer 기법을 적용하여 불필요한 연산을 줄이면서도 중요한 정보는 유지하도록 설계하였습니다.
Sparse Transformer
일반 Transformer는 문장 내 모든 단어를 서로 연결하여 관계를 학습합니다.
하지만 Sparse Transformer는 중요한 단어들끼리의 관계만 선택적으로 학습하며 선택 기준은 Attention Score를 바탕으로 이루어집니다.예시)
"The dog is playing in the park"라는 문장이 주어졌을 때
Transformer는"The"→"dog","is","playing","in","the","park"모든 단어를 연결합니다.
Sparse Transformer는"dog"→"playing","park"의미적으로 관련 있는 단어들만 선택적으로 연결합니다.
필요한 정보만 집중적으로 학습하는 방식을 통해 더 적은 연산으로도 뛰어난 성능을 유지할 수 있게 되었습니다.
3. Loss
CLIP은 이미지와 텍스트 간의 관계를 학습하기 위해 대조 학습을 사용합니다.
각 모달리티(이미지와 텍스트)는 전용 인코더를 통해 벡터로 변환되고, 이 벡터들은 동일한 차원의 공통 임베딩 공간에 매핑됩니다.
이후, 모든 이미지-텍스트 쌍 간의 코사인 유사도(cosine similarity)를 계산하여, 올바른 쌍(Positive Pair)의 유사도는 높이고, 잘못된 쌍(Negative Pair)의 유사도는 낮추도록 모델을 학습시킵니다.
입력으로 텍스트와 이미지를 모두 처리하기 위해 다음 두 방향의 손실 함수가 사용됩니다
이미지 → 텍스트 Loss: 각 이미지 임베딩이 올바른 텍스트 임베딩과 높은 유사도를 가지도록 학습
텍스트 → 이미지 Loss: 각 텍스트 임베딩이 올바른 이미지 임베딩과 높은 유사도를 가지도록 학습
두 방향의 손실은 동일한 수식 구조를 가지며, 한 방향에 대한 수식을 아래와 같이 요약할 수 있습니다.
: i번째 이미지의 임베딩 벡터
: i번째 텍스트의 임베딩 벡터
: 이미지 와 텍스트 간의 코사인 유사도
: 온도 파라미터 (학습 가능한 스케일링 값)
: 배치 내의 샘플 수
텍스트 → 이미지 Loss도 동일한 구조로 계산됩니다. 최종 손실은 두 방향의 손실을 평균하여 다음과 같이 정의됩니다.
이 간단한 Loss 구조를 통해, CLIP은 이미지가 주어졌을 때 올바른 텍스트를, 텍스트가 주어졌을 때 올바른 이미지를 찾는 학습을 동시에 수행합니다.
IV. 코드 구현
위의 과정을 코드로 구현하면 아래와 같습니다.
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/24. 출력
CLIP의 출력 방식은 일반적인 텍스트 생성 모델과 다릅니다.
새로운 이미지를 입력하면, 사전에 정의된 라벨(텍스트) 중 가장 적합한 것을 선택하는 방식으로 동작하며, 새로운 문장을 생성하는 것이 아니라 가장 유사한 라벨을 찾는 방식을 사용합니다.
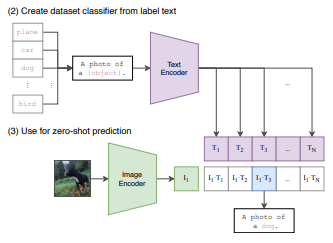
I. Pre-trained 모델을 활용한 예측
사전 학습된 이미지 및 텍스트 인코더를 활용하여, 입력된 데이터와 가장 적합한 텍스트 라벨을 찾습니다. 이를 위해 사용자는 모델이 비교할 수 있도록 평가하고자 하는 텍스트 라벨(프롬프트)을 사전에 정의해야 합니다.
🤔 왜 프롬프팅이 필요할까요?
CLIP은 Zero-shot Learning 방식으로 동작하므로, 특정 태스크에 대해 별도의 미세 조정(fine-tuning)을 거치지 않습니다.
대신, 사용자가 태스크에 적합한 후보 텍스트(예:"dog", "cat", "car"등)를 입력하면, 모델은 이들 중에서 입력 이미지와 가장 의미적으로 일치하는 라벨을 선택합니다.즉, 프롬프팅은 모델에게 “어떤 카테고리(또는 개념)를 고려해야 하는지”를 알려주는 역할을 합니다.
🤔 사용자의 요구사항이 무엇일지를 미리 알고 후보 텍스트를 정의할까요?
실제로, 표준 이미지 분류 태스크에서는 후보 텍스트가 이미 사전에 정의된 클래스 집합(예: ImageNet의 1000 클래스)으로 제공되므로, 사용자가 모든 가능한 후보를 일일이 정의할 필요는 없습니다.
다만, 오픈 도메인 환경이나 보다 다양한 개념을 다루는 상황에서는 기존의 클래스 집합만으로는 충분하지 않을 수 있습니다. 이 경우, 도메인 전문가의 지식을 활용하여 적절한 후보 프롬프트를 구성하거나 여러 프롬프트를 앙상블하는 방식으로 모델의 성능을 최적화할 수 있습니다.
또한, 최근 연구에서는 프롬프트 자동 생성 기법이 제안되어, 사용자가 모든 후보를 수동으로 정의하지 않아도 되는 방법들이 개발되고 있습니다.
II. 이미지와 텍스트 간 유사도 계산
새로운 이미지를 입력하면 이를 이미지 인코더에 넣어 벡터로 변환합니다.
마찬가지로, 사전에 정의된 라벨(텍스트)도 텍스트 인코더를 통해 벡터로 변환됩니다.
이후, 변환된 이미지 벡터와 모든 텍스트 벡터 간의 코사인 유사도(Cosine Similarity)를 계산하여, 가장 높은 유사도를 가진 텍스트를 해당 이미지의 라벨로 예측합니다.
III. 가장 적절한 텍스트 출력
유사도 점수가 가장 높은 텍스트를 최종 출력합니다.
즉, 모델이 새로운 문장을 직접 생성하는 것이 아니라, 사용자가 지정한 프롬프트(라벨) 중에서 가장 적절한 것을 선택하는 방식으로 동작합니다.
예시)
강아지 사진을 입력 이미지로 넣고 사용자가 정의한 텍스트 라벨:["dog", "cat", "car"]인 경우 가장 높은 유사도를 가진 라벨인"dog"를 출력합니다.
이러한 방식으로 CLIP은 라벨링이 없는 이미지에 대해, 사전 정의된 라벨 중 가장 적절한 텍스트를 예측하는 모델로 활용됩니다.
아래는 각 실험 및 한계점 섹션을 보다 명확하고 일관되게 다듬은 수정 버전입니다.
5. Experiments
5-1. Zero-shot Transfer
기존의 Zero-shot Transfer 방식(예: Visual N-Grams)과 비교하여, CLIP이 별도의 추가 학습 없이도 다양한 데이터셋에서 높은 성능을 보이는지를 평가했습니다.
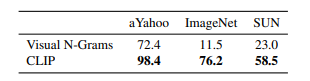
CLIP은 새로운 데이터셋에서도 추가 학습 없이 뛰어난 성능을 발휘했습니다.
ImageNet에서는 기존 모델의 11.5%에 비해 CLIP은 76.2%의 성능을 기록하여 약 6배 향상된 결과를 보였습니다.
기존 Visual N-Grams 방식은 특정 데이터셋에 최적화되어 작동하는 반면, CLIP은 이미지와 텍스트 쌍을 통한 개념 학습 덕분에 학습하지 않은 데이터에서도 효과적으로 일반화할 수 있음을 보여줍니다.
사실상, 이 실험은 기존 모델과의 직접 비교보다는 CLIP의 Zero-shot Transfer 능력을 검증하는 데 중점을 두었습니다.
5-2. Prompt Engineering
CLIP은 프롬프트 엔지니어링과 앙상블 기법을 활용하여 Zero-shot Transfer 성능을 최적화할 수 있습니다.
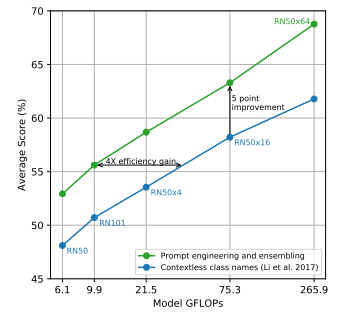
여러 프롬프트를 적용한 후, 예측 결과를 종합하면 평균 약 5%의 정확도 향상이 달성되었으며, 이는 기존 방법에 비해 연산량 대비 4배 효율적인 성능 개선으로 이어졌습니다.
5-3. Bias
CLIP과 지도학습 모델(예: ResNet-50)을 비교하여, 어떤 데이터셋에서는 강점을 보이고 어떤 도메인에서는 약점을 나타내는지 분석했습니다.
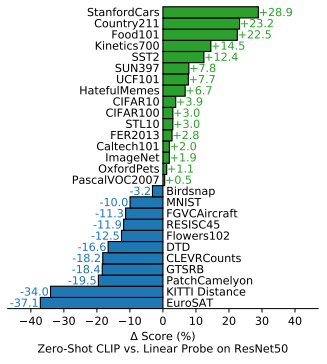
자동차, 음식, 스포츠 등 웹에서 자주 접할 수 있는 이미지 유형에서는 기존 모델 대비 평균 20% 이상의 성능 향상이 있었습니다.
하지만 위성 이미지(EuroSAT)나 의료 데이터와 같은 특수 도메인에서는 최대 37%까지 성능이 감소하는 결과를 보였습니다.
이는 CLIP이 웹 기반 데이터에서는 우수한 일반화 능력을 보이지만, 전문 도메인에서는 데이터 편향 및 특성 차이로 인해 성능 저하가 발생할 수 있음을 알 수 있습니다.
5-4. Few-shot
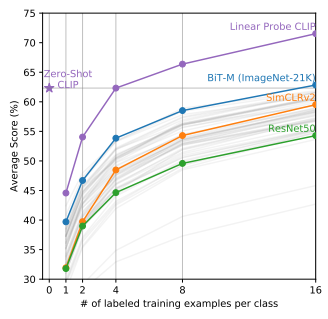
Zero-shot CLIP(보라색 선)은 별도의 미세 조정 없이도, 4-shot Linear Probe와 유사한 성능을 기록했습니다.
1-shot 설정에서는 단 하나의 라벨링된 데이터만 사용할 때 성능이 크게 떨어졌지만, 2-shot 이상에서는 성능이 안정적으로 유지되거나 점차 향상되었습니다.
🤔 왜 1-shot에서 성능이 급격히 감소할까요?
한 클래스에서 단 하나의 라벨링된 데이터만 제공될 경우, 해당 샘플의 특징에 모델이 과적합(overfitting)될 가능성이 매우 큽니다.
즉, 단일 예제가 그 클래스의 일반적인 특성을 충분히 대표하지 못하기 때문에, 모델은 해당 예제에 특화된 패턴만 학습하여 전체 데이터 분포를 반영하지 못합니다.
🤔 2-shot 이상부터 성능이 향상되는 이유는 무엇일까요?
두 개 이상의 라벨링된 샘플이 제공되면, 각 샘플이 약간씩 다른 특징과 변이를 포함하게 됩니다.
이를 통해 모델은 개별 샘플의 특이사항에 과도하게 의존하지 않고, 보다 일반적인 클래스의 패턴을 학습해 모델의 예측 성능이 더 안정적이고 향상됩니다.
CLIP은 라벨링 없이도 강력한 제로샷(Zero-shot) 성능을 보임으로써, 추가적인 라벨링 없이도 4-shot 수준의 성능을 달성할 수 있다는 점에서 뛰어난 일반화 능력을 입증했습니다.
5-5. 모델 비교
CLIP의 성능을 EfficientNet, ResNet, ViT, MoCo, BYOL 등 최신 모델들과 비교 분석했습니다.
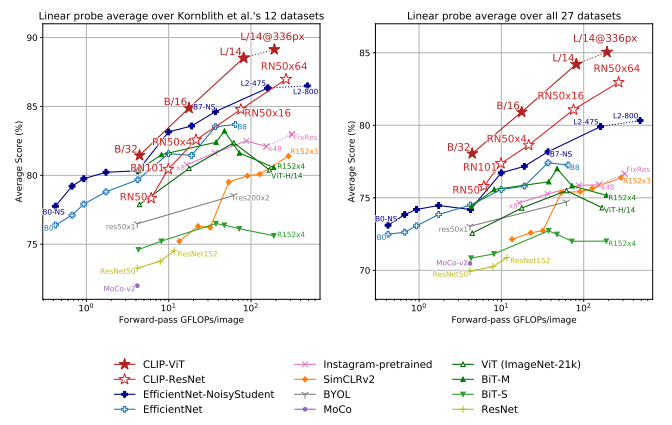
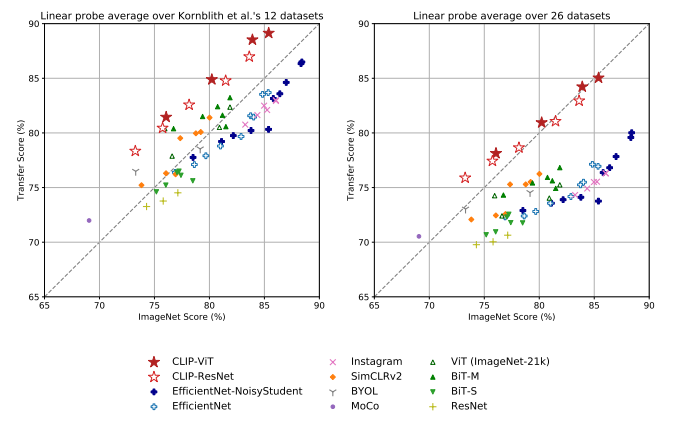
Linear Probe는 사전 학습된 모델이 학습한 Feature가 다양한 새로운 데이터에서 얼마나 잘 작동하는지를 평가하는 방법으로, Feature를 고정한 채 단순 선형 분류기를 학습하여 측정합니다.
CLIP-ViT(빨간색 별표) 모델들은 전반적으로 우수한 성능을 기록했습니다.
ResNet-50, EfficientNet 기반 모델은 특정 데이터셋에서는 강점을 보이지만, 전체적으로 CLIP 기반 모델이 더 뛰어난 일반화 능력을 보여주었습니다.
또한, 자기 지도 학습 방식인 SimCLRv2, MoCo, BYOL 모델들도 높은 성능을 보였으나, CLIP-ViT는 방대한 데이터 학습 덕분에 더욱 강력한 일반화 성능을 나타냈습니다.
5-6. Distribution Shift
모델이 특정 데이터셋에서 높은 성능을 보이더라도, 실제 환경에서는 데이터 분포가 달라지면 성능이 급격히 감소할 수 있습니다.
이러한 현상을 Distribution Shift(데이터 분포 변화) 문제라고 하며, 이는 모델의 일반화 능력을 평가하는 중요한 기준이 됩니다.
CLIP은 다양한 Distribution Shift 환경에서도 기존 ImageNet 모델에 비해 얼마나 강건한지(robustness)를 평가하였습니다.
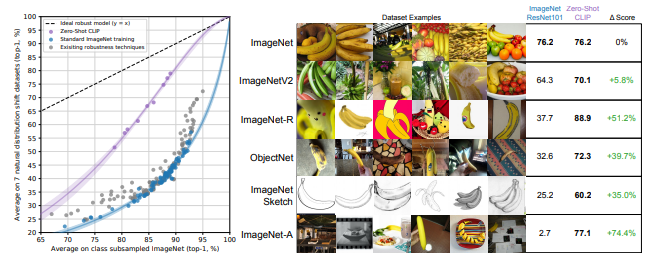
결과적으로, CLIP은 Distribution Shift 상황에서 성능 감소폭이 훨씬 적습니다.
점선(이상적인 모델)을 기준으로 보면, 기존 모델들은 데이터 분포 변화에 따라 성능이 급격히 떨어지는 반면, CLIP은 보다 안정적인 성능을 유지합니다.
즉, CLIP은 다양한 데이터 분포에서도 일관된 성능을 보이는 강건한 모델임을 알 수 있습니다.
🤔 어떻게 이러한 강건함을 유지할 수 있을까요?
CLIP은 웹에서 수집한 다양한 이미지-텍스트 데이터를 학습함으로써, 기존 모델이 단순히 이미지의 픽셀 정보에만 의존하는 것과 달리, 이미지와 텍스트 간의 관계를 학습하여 보다 개념적인 이해를 구축합니다.
예시)
CLIP은"바나나"라는 개념을 학습할 때 단순히 노란색 과일의 형태만 인식하는 것이 아니라, 그림, 렌더링, 스케치 등 여러 표현 방식에서도 바나나를 인식할 수 있도록 학습됩니다.
이러한 접근 방식 덕분에, CLIP은 특정 클래스 라벨에 국한되지 않고 새로운 데이터 환경에서도 강력한 성능을 발휘할 수 있습니다.
6. 한계점
I. 특수 도메인 성능 저하
CLIP은 주로 웹에서 수집된 이미지-텍스트 데이터를 기반으로 학습되었기 때문에, 의료, 과학, 위성 이미지 등 특수 도메인에서는 기대만큼의 성능을 발휘하지 못할 수 있습니다.
II. 저해상도 데이터 처리
CIFAR-10이나 CIFAR-100과 같은 저해상도 이미지 데이터에서는, 고해상도 데이터를 기반으로 학습된 기존 모델에 비해 상대적으로 낮은 성능을 보일 가능성이 있습니다.
III. 텍스트 프롬프트 민감도
모델의 예측 결과가 텍스트 프롬프트의 표현 방식에 크게 의존합니다. 즉, 동일한 개념이라도 프롬프트를 어떻게 작성하느냐에 따라 결과가 달라질 수 있는 문제가 있습니다.
IV. 높은 연산 비용
이미지와 텍스트를 각각 독립적인 인코더로 처리하기 때문에, 전체 모델의 연산 비용이 높아 실시간 응용이나 리소스가 제한된 환경에서는 부담이 될 수 있습니다.
V. 데이터 편향
웹 데이터 기반으로 학습되었기 때문에, 특정 문화권, 인종, 성별 등에 대한 편향이 모델에 내재될 가능성이 존재합니다.
논문을 살펴본 결과, 이미지와 텍스트 간의 양방향 관계를 일반화한 접근 방식이 매우 흥미로웠습니다. 다만, 여전히 프롬프트에 의존하고 문장보다는 단어 수준에서 유추하는 등의 한계가 있다고 느꼈습니다. 이러한 점이 현재 멀티모달 기술들이 어떻게 발전해왔고, 실제로 어디에 활용되고 있는지를 더 깊이 살펴보게 되는 계기가 된 것 같습니다.
[참고자료]
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Lanugage Supervision
https://taeyuplab.tistory.com/16
CLIP: Connecting Text and Images
https://youtu.be/dELmmuKBUtI?si=3BsbBiA3bJgGHRS1
