
1. Intro
https://arxiv.org/abs/1502.03044
본 논문은 ViT가 나오기 이전에 Attention을 바탕으로 이미지 캡션을 생성하는 방법을 소개하고 있다.
기존의 방법론은 다음과 같다.
- 이미지에서 객체를 식별하고 이를 정의된 탬플릿에 채워넣는 방식
예: [객체]가 [장소]에 있다.🤦♂️
탬플릿 이외의 복잡한 문장을 생성하지 못함
-
검색과 위키피디아를 활용한 캡션 생성
🤦♂️
이미지와 관련 없는 내용이 존재하며 새로운 상황에 일반화가 되지 않는 문제가 존재 -
CNN+RNN의 조합
이미지의 주요 정보를 벡터로 압축하여 RNN에 전달 후 텍스트를 생성🤦♂️
- 공간적 정보를 잃고 모든 영역이 동일한 중요도를 갖음
- 단일 벡터의 고정된 구조로 인해 다양한 문장 구조를 생성하거나 세부 사항을 반영하기 어려움
- 객체의 존재 여부에 초점이 맞춰져있어 관계 모델링에 취약
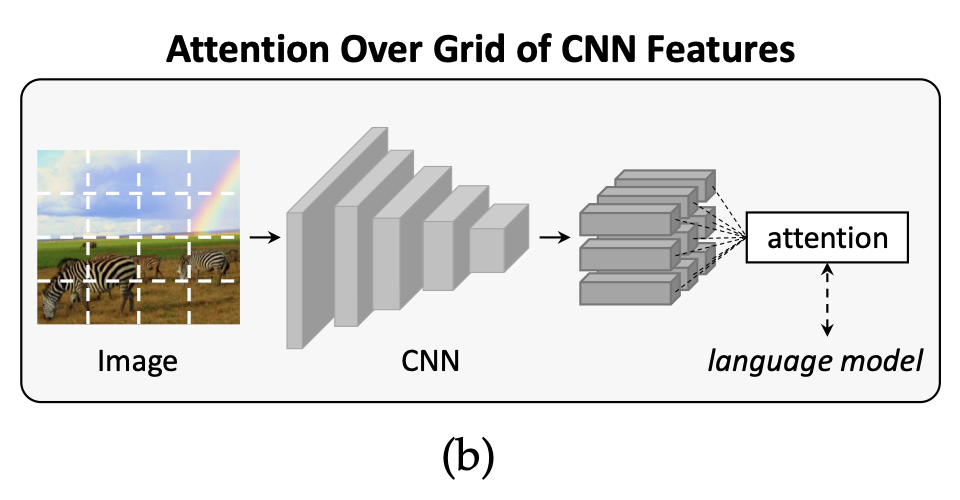
2. Vision Attention
그렇다면 이러한 문제점들을 어떻게 극복하였을까?
논문은 단일벡터가 아닌 2D activation maps으로 대체해 language model에 공간 정보도 제공하는 방법을 최초로 사용하였다.
논문의 목표는 1개의 이미지에 대한 캡션을 생성하는게 목표이다.
캡션은 단어 시퀀스 y = {y1, y2, ..., yc}로 표현되며,
yi는 i번째 단어로 𝐾-차원의 실수 벡터 공간에 속하는 one-hot encoding 벡터이다.
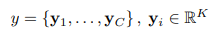
이를 위한 전체 과정을 살펴보자
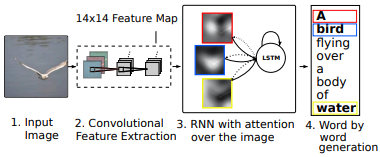 입력 -> Encoder(CNN) -> Decoder(RNN+Attention) -> 출력
입력 -> Encoder(CNN) -> Decoder(RNN+Attention) -> 출력
2-1. Encoder
Pre-trained CNN(ResNet-101)을 통해 Feature vector(annotation vector)를 뽑아 이를 RNN의 입력으로 사용해야 하는데 여기서 의문점이 발생한다.
어떻게 CNN의 공간적 구조를 보존하여 RNN에게 전달을 해야 하는가?
논문에서는 중간 계층에서 추출된 특징 맵을 사용해 정보를 보존하였다.
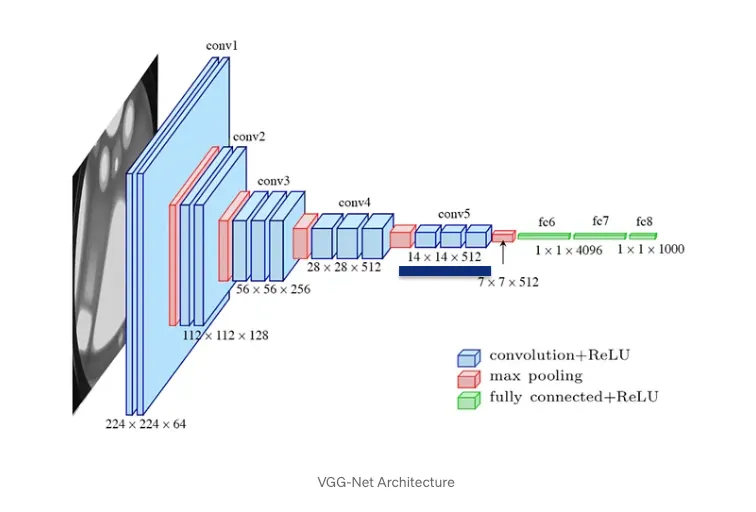
그렇다면 FC레이어 직전의 특징맵을 활용하지 않는 이유는 무엇일까?
위의 특징 맵은 이미지의 전체적인 맥락 또는 전반적인 특징을 요약한 정보로 분류를 위한 정보(전역 정보)가 들어있다.
예시: "이 이미지는 고양이가 포함된 사진이다." 와 같이 고양이의 위치가 아닌 존재 유무에 관한 정보가 들어있다. 즉, 특정 영역에 초점을 맞춰 고양이만 뚫어져라 봄
중간 계층에서 추출된 특징 맵은 해상도가 상대적으로 낮기 때문에 세부적인 위치 정보까지 확인할 수 있게 된다.
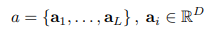
중간 계층의 출력 𝑎는 여러 개의 annotation vectors로 구성되며 각 벡터 ai는 시각적 특징 벡터 차원인 D에 속한다.
필자는 여기서 위화감을 느꼈다. 3차원 행렬인 CNN을 2차원 행렬인 RNN으로 어떻게 변환하였는가? 답은 아래와 같다.
예시로 224x224x3 크기의 이미지가 들어왔다고 가정해보자 이때 CNN을 거치며 이미지의 크기는 작이지며 정보가 요약되고 필터의 크기는 커지며 특징이 많아져
14x14x512 라는 중간 계층의 특징맵이 나왔다고 가정하면 이 벡터는 14x14 크기와 512개의 시각적 특징(엣지, 텍스쳐, 색 등)을 가진 이미지라 표현할 수 있으며
14 x 14 = 196을 통해 벡터로 분해가 가능해지며 이를 통해 a1은 좌측 상단의 패치로 a196은 우측 하단의 패치로 표현이 가능해지게 된다.
이제 512차원에 속하는 196개의 벡터를 RNN에 입력해보자
2-2. Decoder
전체적인 흐름은 아래의 그림과 같다.
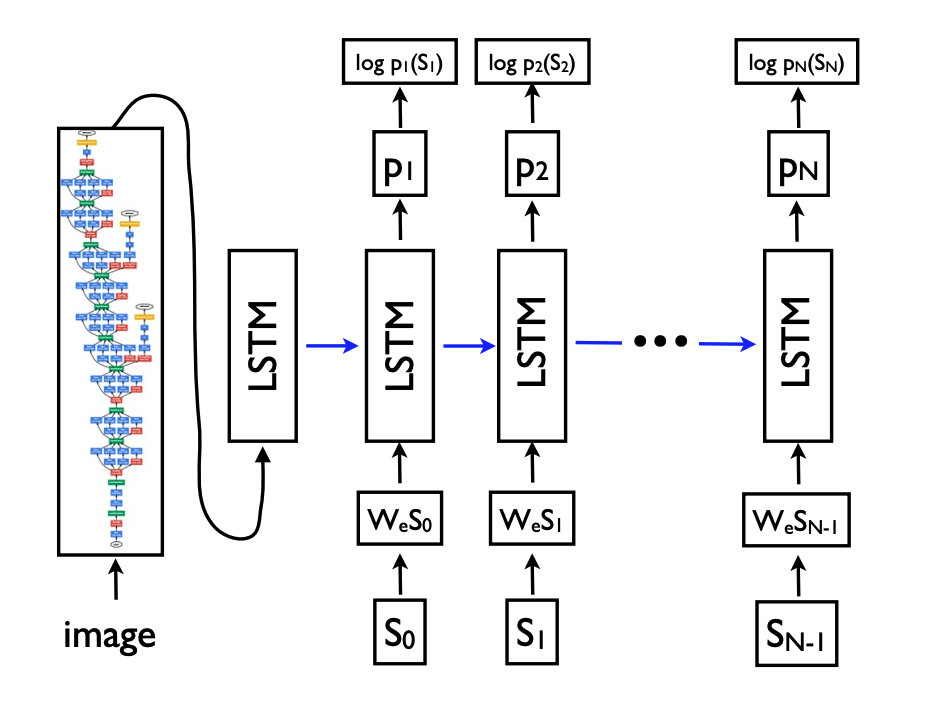
논문에서 사용되는 LSTM의 구조는 아래와 같다.
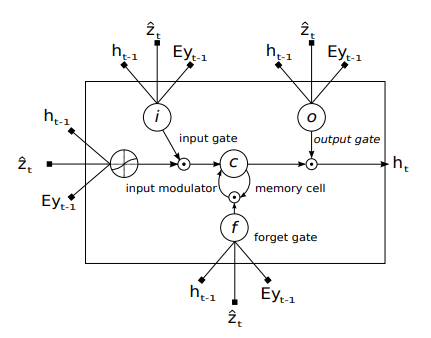
해당 그림에서 Z와 Ey가 등장하는데 하나하나 천천히 풀어보겠다.
우선 Ey는 Encoder에서 생성된 Context vector로 이미지 정보를 의미한다.
Z는 아래의 수식과 같이 ai와 𝑎i의 값을 function에 넣에 구한 값이다.
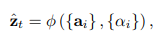
이때 ai는 annotation vector이고 𝑎i는 attention score이다.
그렇다면 function은 무엇이고 attention score는 어떻게 구해야 할까?
아래의 수식을 살펴보면 알 수 있다.
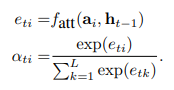
attention function과 annotation vector, 이전 hidden state를 활용하고 이를 softmax를 통해 확률값으로 변환하면 𝑎i를 구할 수 있게 되는것이다.
자 우리가 일반적으로 알고 있는 attention score를 구하는 수식은 키와 쿼리의 내적을 통해 유사도를 구하는 방식이다. 그러나, annotation vector와 h를 내적하는 순간 이미지의 정보(공간적 의미와 정보)를 잃기 때문에 두 값이 명시되어 있는 방법인 Additive Attention 방법을 사용해야 하며 방법은 아래와 같다.
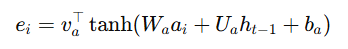
W, U, v는 학습 가중치에 해당하며 a와 h에 곱해주는 이유는 두 개의 차원이 다르기 때문에 차원 일치를 통한 계산을 위해 곱해준다.
a가 512차원이고 h가 256차원일 경우
W가 256x512이고 a가 512일 경우 둘이 곱해주면 256차원의 열벡터로 변하게 된다.
마지막으로 하나 하나의 어텐션 스코어를 알기 위해 전치행렬을 곱해준다.
위의 과정은 현재 단어를 생성하기 위해 필요한 이미지의 정보를 요약한 벡터인
context vector z를 구하기 위한 과정이다.
이제 해당 이미지 정보 z, 이전의 hidden state h(t-1), 이전에 생성된 단어(초기는 SOS토큰)를 입력으로 받아 새로운 hidden state h(t)를 계산하고 해당 값을 softmax를 통과시켜 다음 단어를 생성한다.

초기값은 아래와 같다.
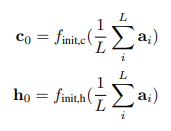
이제 EOS 토큰이 나올 때까지 위의 과정을 반복하면 이미지에 대한 캡션이 생성된다.
3. Learning Mechanisms
위 논문은 특이하게 학습 방향성을 두가지 제시해 주었다. 바로 Soft Attention과 Hard Attention이다. 해당 방법에 대한 빠른 이해를 위해 아래 그림부터 살펴보자

위의 그림이 Soft이고 아래가 Hard이다.
Soft는 가중치를 반영한 전체 Feature map을 보기 때문에 범위가 넓다는 사실을 알 수 있다.
Hard는 0과 1로 특정(one-hot encoding)해 Feature map을 정하기 때문에 일부 영역만 본다는 사실을 알 수 있다.
i. Soft Attention
위에서 소개한 방법은 soft Attention으로 각 위치의 가중치 𝛼i를 확률 분포로 표현해서 이를 annotation vectors를 평균적으로 반영하는 방법이다.
위의 방법은 연속적인 값으로 계산되기 때문에 미분이 가능해지며 Backpropagation이 가능해지는 장점이 있다.
ii. Hard Attention
해당 방법은 soft attntion을 통해 구한 attention score를 활용해 해당 셀이 0이될지 1이될지 확률을 구하여 0또는 1로 선택하는 방법이다.
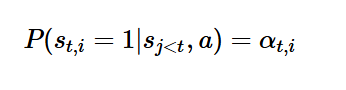

여기서 j는 이전 시점 전체를 의미하는 것입니다.
단순히 t-1, t-2를 사용하지 않은 이유는 LSTM 자체가 이전의 모든 정보를 반영해야하기 때문에 j라 표현을 한 것입니다.
즉, S𝑡,1가 1이 될 확률, S𝑡,2가 1이 될 확률, S𝑡,196이 1이 될 확률로 표현되고 이때 가장 높은 확률을 1로 표현하고 나머지를 0으로 표현하는 방법이다.
정리해 보자면 Soft Attention으로 계산된 확률 𝛼를 사용하여 특정 위치 𝑗를 샘플링하고 샘플링 결과로 나온 𝑗는 Hard Attention에서 1로 선택된 위치를 나타내게 되고 나머지는 0을 나타낸다.
위의 샘플링으로 인해 미분이 불가능해 강화학습을 진행한다.
학습의 안정성과 모델 구현의 용이함으로 인해 soft attention을 주로 사용
4. Loss
모델이 예측한 단어 분포와 실제 단어 y𝑡간의 차이를 활용한 Cross-Entropy Loss를 활용하였으며 전체 캡션의 손실은 각 단어 손실의 합으로 계산하였다.
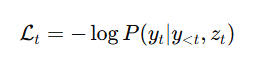
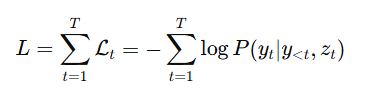
5. Experiments
5.1 데이터셋
- Flickr8k: 8,000개 이미지, 5개 캡션.
- Flickr30k: 30,000개 이미지, 5개 캡션.
- MS COCO: 82,783개 이미지.
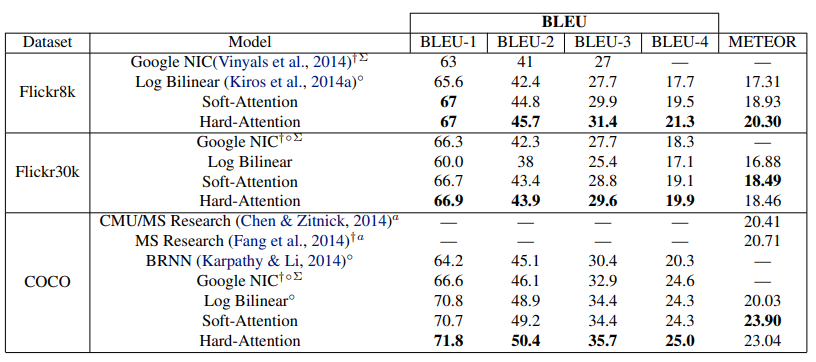
5.2 성능 평가
- 모델 성능은 BLEU와 METEOR 지표를 사용해 평가하였다.
- 제안된 모델은 유의미한 성능 향상을 이뤄냈으며 Hard Attention을 진행했을때
Soft Attention보다 더 좋은 성능이 나왔다.
5.3 결과
모델이 단어를 생성할 때 어떤 부분을 주목하는지 확인이 가능하다.
추가적으로 착시나 잘못 판단한 결과도 확인이 가능하며 모델이 어디를 주목해 어떤 결과를 도출했는지 판단이 가능하다.

이후 Graph-based Encoding을 통해 image regions을 이용한 graph 모델을 구축하는 등의 발전이 이루어집니다.
