Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications
Haowen Xu · Wenxiao Chen · Nengwen Zhao · Zeyan Li · Jiahao Bu · Zhihan Li · Ying Liu · Youjian Zhao · Dan Pei · Yang Feng · Jie Chen · Zhaogang Wang · Honglin Qiao
Proceedings of the 27th International Conference on World Wide Web (WWW), 2018
Abstract
- web application의 KPI(핵심 성과 지표)에서 이상 징후를 감지할 수 있음
- KPI는 사용자 행동과 스케줄에 크게 영향받음 > 계절성 패턴을 보임
- 주로 레이블이 없는 데이터
- Donut: VAE 기반 비지도 학습 이상징후 알고리즘 제안
1. Introduction
- Donut의 세가지 핵심 기술
- Modified ELBO
- Missing data injection
- MCMC Imputation
- VAE 학습시에 정상/비정상 데이터 모두 학습
- KDE(Kernel Density Estimation) 해석 제안 > VAE 기반 이상 감지 알고리즘 중 최초로 견고한 이론적 설명
- 잠재 z-공간에서 시간 기울기 효과 발견 > 계절성 KPI에서 Donut의 효과성 입증
2. Background and Problem
2.1 Context and Anomaly Detection in General
KPI 요소
- 계절성: 비즈니스 KPI는 유저 행동에 영향 많이 받음
- local variation:
- KPI curve의 모양은 매 사이클에서 같지 않음 (유저의 행동은 날마다 달라짐)
- “seasonal KPIs with local variations”
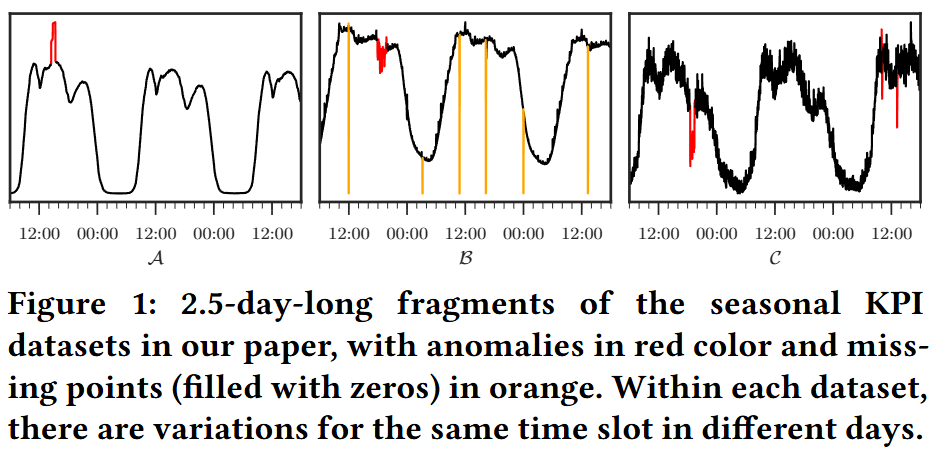
- increasing trend : Holt-Winters, Time Series Decomposition으로 확인 가능
- noise: 독립이면서 평균 0인 가우시안 분포를 따른다고 가정 > 정확한 값보다는 분포에 집중
Normal Patterns
- 1) seasonal patterns + local variations
- 2) statistics of Gaussian noises
용어
- anomaly: 이상치. sudden spikes/dips 등
- abnormal: anomaly + missing points(null)
2.2 Previous Work
- Traditional Statistical Models
- 전문가가 개입해야함.
- 다수결, 정규화 등의 앙상블 기법도 크게 도움되지 않음
- Supervised Ensemble Approaches
- user feeedback을 라벨로, traditional detector의 output인 anomaly score를 feature로 이용
- 좋은 label에 의존성이 강함. computational cost 너무 많이 사용
- Unsupervised Approaches and Deep Generative Models
- one-class SVM, K-Means, GMM, KDE, VAE 등과 같은 비지도 learning algorithm이 많음
- KPI 데이터는 주로 normal data > 라벨 없이도 학습 가능
2.3 Problem Statement
- Unsupervised: 레이블이 전혀 없는 상황에서도 이상을 탐지
- Deep Generative Models: VAE(Variational Auto-Encoder)를 핵심 구성 요소로 활용하여 데이터의 정상 패턴을 학습
- Solid Theoretical Explanation: 제안하는 알고리즘의 동작 원리에 대한 명확한 이론적 근거를 제시
- Leveraging Occasional Labels: 완전하지는 않더라도 간헐적으로 사용 가능한 레이블 정보가 있다면 이를 활용하여 성능을 더욱 향상
2.4 Background of Variational Auto-Encoder
VAE: Variational Auto Encoder
-
잠재 변수 (Latent Variable )
- 데이터 의 숨겨진 특징이나 압축된 표현을 나타내는 변수
- 의 사전 분포 는 일반적으로 평균 0, 분산 1인 다변량 단위 가우시안 분포 로 설정
-
가시 변수 (Visible Variable )
관측되는 실제 데이터(KPI 시계열 데이터)를 나타내는 변수 -
생성 모델 (Generative Model)
- 잠재 변수 가 주어졌을 때 가시 변수 가 생성될 확률을 모델링하는 구조
- Neural Network(파라미터 )로부터 유도되며, 의 형태는 task 요구사항에 따라 달라짐
- 전체 생성 모델은 로 정의
-
사후 분포 (True Posterior)
- 가시 변수 가 주어졌을 때 잠재 변수 의 진정한 사후 분포를 의미
- 분석적으로 다루기 어렵거나 계산 불가능한 경우가 많음 > 그러나 훈련 및 예측에 필요함
-
근사 사후 분포 (Approximated Posterior)
- 계산하기 어려운 진정한 사후 분포 를 근사하기 위해 도입된 구조
- 또 다른 Neural Network(파라미터 )를 통해 학습되며, 일반적으로 형태의 가우시안 분포로 가정
- 여기서 와 는 로부터 Neural Network에 의해 도출됨
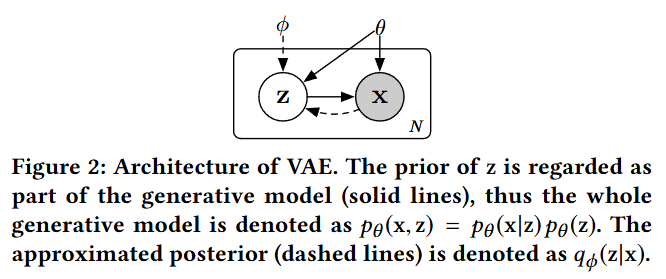 실선: 생성 모델
실선: 생성 모델
- 잠재 공간 z에서 데이터 공간 x로의 매핑을 의미
- Decoder 역할
점선: 근사 사후 분포
- 데이터 공간 x에서 잠재 공간 z로의 매핑을 의미
- Encoder 역할
1) SGVB: Stochastic Gradient Variational Bayes
VAE 학습에 주로 사용되는 변이 추론(variational inference) 알고리즘
- 근사 사후 분포(approximate posterior) 와 generative model 를 ELBO(Evidence Lower Bound)를 최대화하는 방식으로 동시에 훈련
- Stochastic Gradient Descent과 같은 최적화 기법을 사용하여 ELBO 기댓값 근사
2) ELBO: Evidence Lower Bound
- VAE의 궁극적인 목표: 잠재 변수 가 주어졌을 때 관측된 데이터 가 모델에 의해 생성될 확률인 주변 로그 우도(marginal log-likelihood) 를 최대화하는 것 > 계산하기 매우 어려움
- ELBO = 의 계산 가능한 하한
- ELBO 최대화 = 간접적으로 최대화
- Monte Carlo Integration (몬테카를로 적분)을 통해 기댓값을 근사
3. Architecture
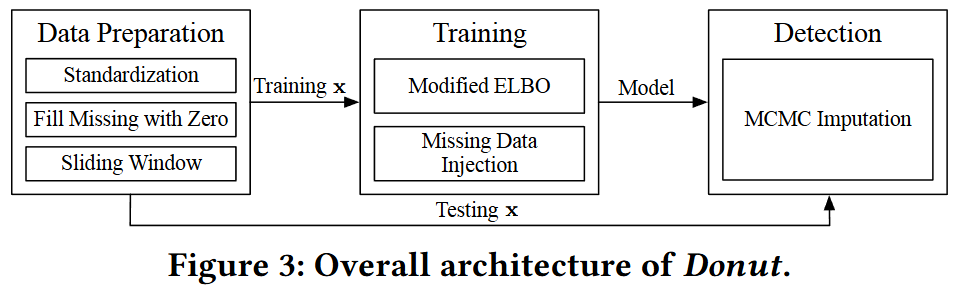
3.1 Network Structure
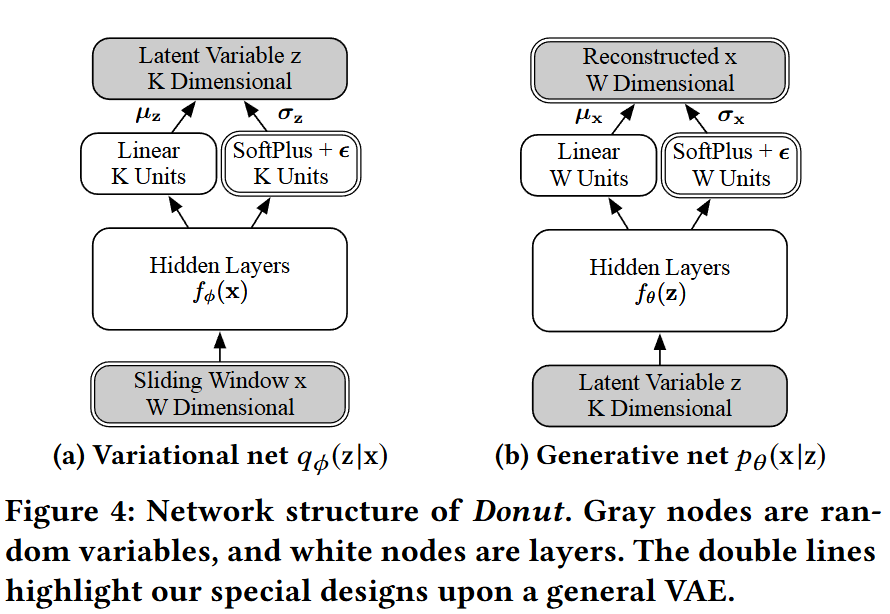
- Hidden Layer: 입력 와 잠재 변수 로부터 각각 hidden feature 추출
- Linear: 추출된 특징을 선형 레이어 통해 평균 벡터 구함
- SoftPlus + : 추출된 특징을 통해 표준편차 벡터를 구함
3.2 Training
- 결측치,이상치 대체 안함
- 생성 모델(generative model)이 다른 알고리즘으로 생성된 데이터로 훈련되는 것은 모순적임
- VAE보다 약한 알고리즘으로 대체하면 성능 떨어짐
- 결측치를 단순 0으로 채움
- ELBO를 수정하여 이상치/결측치 기여 제외하는 방식 사용 > M-ELBO (Modified ELBO)
- M-ELBO
- 윈도우 내에 비정상적인 점이 포함되어 있더라도, Donut이 정상적인 점들을 정확하게 재구성하도록 훈련시킴
- 훈련 과정에서 정상적인 데이터 포인트 중 일부(λ 비율)를 무작위로 0으로 설정하여 마치 결측점처럼 만듦 > data augmentation과 같은 효과
- Donut: VAE + M-ELBO + 결측치 주입
3.3 Detection
- Donut은 학습된 VAE를 사용하여 MCMC 기반 결측치 대체
- 이상 점수 계산할 때, prior expectation 대신 reconstruction probability 를 사용
- MCMC: Markov Chain Monte Carlo
- 테스트 윈도우를 관측된 부분과 결측된 부분으로 나눔
- 잠재변수와 재구성 샘플을 얻고, 관측된 부분은 고정, 결측된 부분을 재구성된 값으로 대체
- 이 과정을 반복하면 재구성된 값이 점점 정상에 가까워짐
- 충분히 많은 반복을 통해 편향을 줄이고 더 정확한 재구성 확률을 얻음
4. Evaluation
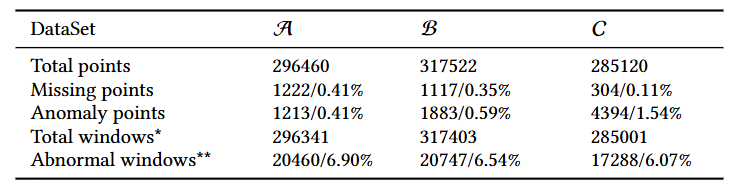
Overall Performance
- Donut은 완전 비지도 학습(0%)에서도 지도학습인 Opperntice 보다 높은 점수
- KPI 데이터가 부드러울수록(A > B > C) Donut의 상대적 이점이 더 크게 나타남 >> Donut 기법들이 윈도우 내에 이상치가 있더라도 신뢰할 수 있는 재구성 확률을 생성하는 능력을 강화하기 때문
- Donut-prior의 낮은 점수로 확인할 수 있는 reconstruction probability 사용의 효과성
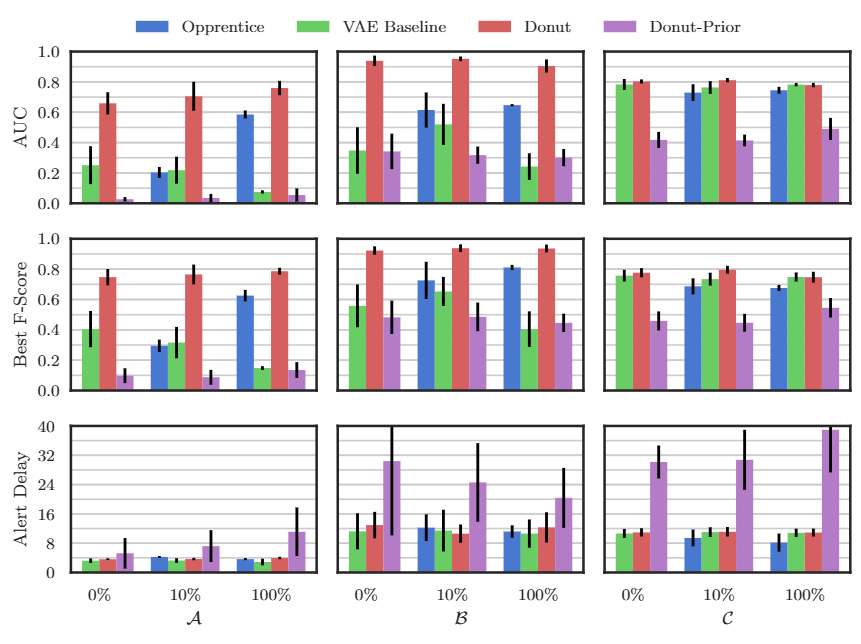
Effects of Donut Techniques
- M-ELBO로 훈련 데이터에 이상치가 포함되어 있더라도, Donut이 해당 윈도우 내의 정상 포인트들을 정확하게 재구성하도록 훈련
- VAE기반 이상감지 모델이 정상/비정상 데이터를 모두 포함하는 데이터셋에도 효과적으로 '정상 패턴'학습
- 성능 향상 매우 큼
- Missing Data Injection으로 훈련 과정에서 정상 데이터 포인트의 일부 ( 비율)를 의도적으로 0으로 설정하여 결측치를 주입
- M-ELBO의 효과를 증폭시키는 데이터 증강 방법
- 성능 향상이 아주 크진 않음. 그러나 권장
- MCMC Imputation으로 이상 감지 단계에서 테스트 윈도우 에 결측치 를 보완
- 테스트 윈도우에 결측치가 있을 때 발생할 수 있는 잠재 변수 의 편향을 줄여, 보다 정확한 재구성 확률을 계산
- 성능 저해하는 경우 없음. 항상 권장
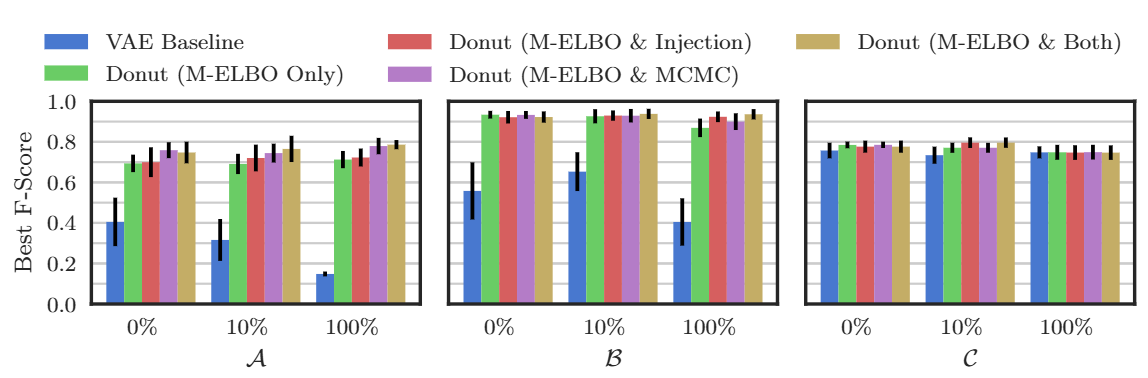
Impact of K
 K: VAE 잠재공간의 차원 수
K: VAE 잠재공간의 차원 수
- 입력데이터의 정상 패턴을 압축적으로 표현하는 역할
- 너무 작은 K: underfitting, Sub-optimal equilibrium (잠재공간 겹치거나 잘못 정렬)
- 너무 큰 K: 재구성 확률 구하기 힘들어짐
- 경험적으로 선택해야함
- A, B, C와 유사한 KPI의 경우 를 5에서 10 사이로
5. Analysis
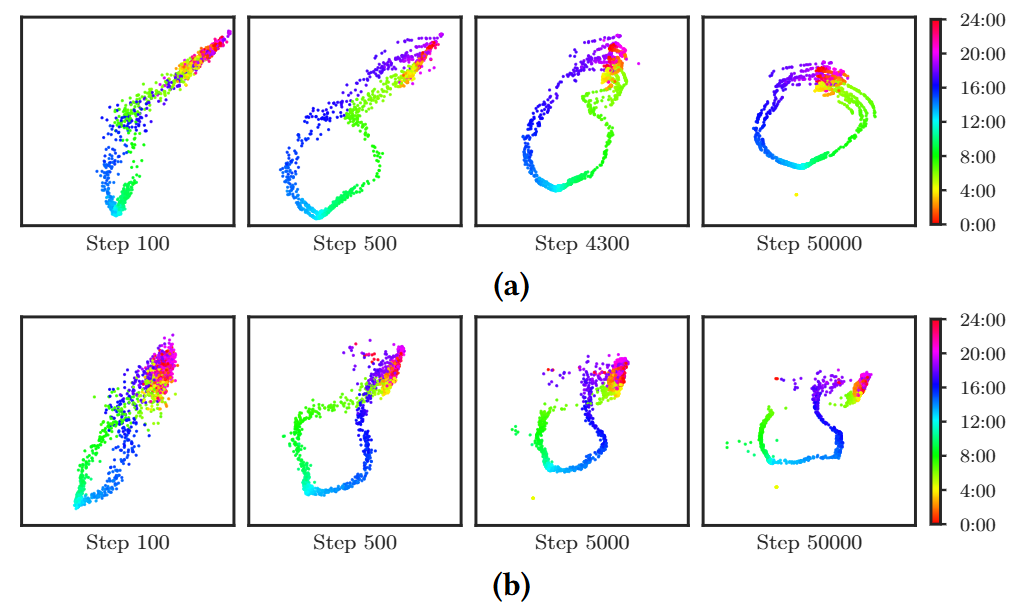
5.1 KDE Interpretation
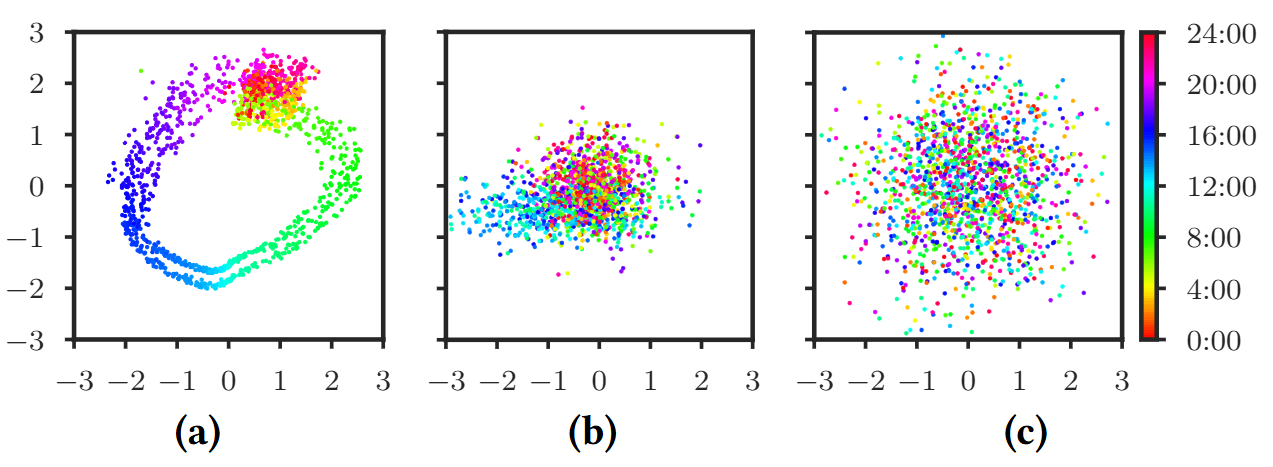 (a): Donut (b): untrained VAE (c): VAE
(a): Donut (b): untrained VAE (c): VAE
- Donut에서는 정상 데이터 에 대한 사후 분포(posterior) 가 '시간 경사(time gradient)'를 보임
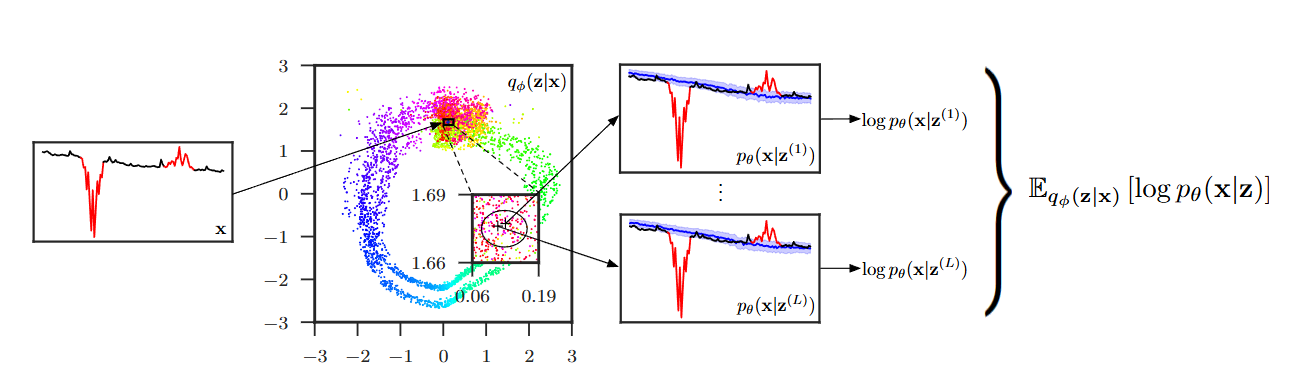
- VAE에 입력되는 시계열 데이터 x를 슬라이딩 윈도우 방식으로 생성
- 입력 x가 VAE의 인코더를 통해 2차원 잠재공간 z로 매핑
- 다양한 색상은 시계열 데이터의 시간대를 나타냄
- 비슷한 시간대의 데이터가 잠재공간에서 서로 가까이 군집을 이루는 "시간 기울기(Time Gradient)" 현상
- Donut은 x에 이상이 있더라도 정상패턴 z를 찾아내도록 학습
- 잠재공간 z에서 샘플링된 여러 z값들을 VAE의 디코더에 넣어, 원본 x를 재구성
- 각 z샘플은 'density estimation kernel' 생성> z가 나타내는 정상 패턴과 입력 x가 얼마나 일치하는지 평가
- 최종 이상 감지 점수: 샘플링된 모든 z에 대한 평균
- 점수를 weighted Kernel Density Estimation, KDE로 해석 > 낮을수록 이상치
5.2 Find Good Posteriors
좋은 사후 분포(좋은 Posterior) = 비정상적인 x가 주어져도 모델이 x에 내재된 정상 패턴과 유사한 패턴을 추론
- Donut은 M-ELBO를 통해 train 때 정확히 정상 포인트를 reconstruct
- Missing Data Injection은 M-ELBO 효과를 증폭
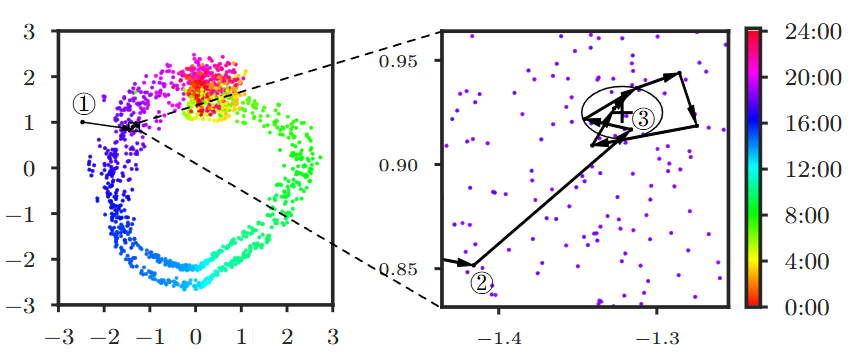
- MCMC를 통해 detection 상황에서 반복을 통해 더 나은 posterior를 도출
5.3 Cause of Time Gradient
-
유사한 데이터의 유사한 표현: VAE는 기본적으로 입력 데이터의 “정상 패턴”을 학습함. 시간 시계열 KPI 데이터는 보통 연속적인 시점에서 유사한 패턴을 보임에 따라, 모델은 이 유사성을 잠재 공간에 반영하려 함.
-
Sliding Window 사용: Donut은 KPI 데이터를 슬라이딩 윈도우로 잘라서 VAE 입력으로 사용함. 이로 인해 연속적인 윈도우들은 서로 매우 유사한 부분이 많아짐.
-
ELBO(손실 함수)의 작용:
- 재구성(Reconstruction): VAE는 주어진 입력 𝑥을 잘 재구성하도록 학습함. 서로 다른 패턴의 입력이 같은 𝑧로 매핑되면 재구성이 어려워지므로, 모델은 다른 패턴을 가진 𝑥에 대해서는 다른 𝑧를 사용하도록 ‘밀어내는’ 경향을 가짐.
- 규제(Regularization): VAE의 ELBO에는 잠재 변수 𝑧의 분포를 특정 형태(예: 가우시안)로 유지하려는 항과, 𝑧 분포가 너무 좁아지지 않게 하려는 항(엔트로피)이 포함됨. 이들은 𝑧-공간이 무질서하게 섞이지 않고 일관된 구조를 가지도록 유도함.
-
학습 과정의 동역학: 재구성 및 규제 항들의 복합적인 ‘밀고 당기기’ 작용과 무작위 초기화, 점진적인 학습률 감소 등의 훈련 과정이 합쳐짐에 따라, 최종적으로 유사한 𝑥들은 가까이, 다른 𝑥들은 멀리 떨어져 정렬되는 시간 기울기 구조가 자연스럽게 형성됨.
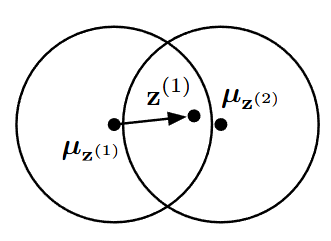
5.4 Sub-Optimal Equilibrium
- Donut과 같은 VAE 기반 모델은 입력 x를 잠재변수 z로 매핑한 뒤, x로 재구성
- 가끔 매핑함수가 최적이 아닌, 국소 최적점으로 수렴 > z 공간의 배치가 비효율적/ 실제 패턴 반영 못하는 상태
- (b)처럼 특정 시점이 다른 시점을 뚫고 지나가면, 초록색 점에 해당하는 영역이 두개의 분리된 영역으로 나뉘어, 시간적 연속성인 "time gradient"가 깨짐
- 레이블 되지 않은 이상치가 포함되어 있으면, 훈련과정이 더 불안정해지고, 우연히 더 나은 평형 상태로 이끌 수 있음 > 완전한 레이블이 오히려 불이익
- 잠재 차원 K가 충분히 크면 z공간에서 확장될 수 있는 자유도 증가 > 나쁜 배치가 발생할 가능성을 줄임
6. Conclusion
- 계절성 KPI의 이상 감지를 위해 VAE 기반의 비지도 이상 감지 알고리즘인 Donut을 제안
- Modified ELBO, Missing Data Injection for training, MCMC Imputation for detection 덕분에 뛰어난 성능
시사점
- dimension reduction 기반 이상 탐지 기법은 재구성을 활용해야 함
- generative model을 사용한 이상 탐지에서는 정상 데이터뿐만 아니라 비정상데이터도 함께 학습해야 함
