USAD: UnSupervised Anomaly Detection on Multivariate Time Series
Julien Audibert · Pietro Michiardi · Frédéric Guyard · Sébastien Marti · Maria A. Zuluaga
Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2020
Abstract
- 수많은 센서로부터 수집되는 시계열 데이터를 기반으로 정상 및 비정상 동작을 추론해야 함
- 기존의 전문가 기반 감독 방식은 속도가 느리거나 오류 발생 가능성이 높음
- 다변량 시계열 데이터를 위한 빠르고 안정적인 비지도 이상탐지 'USAD' 제안 > adversely trained autoencoder 기반
1. Introduction
- IT 시스템의 규모와 복잡성 증가로 인해 모니터링의 자동화가 필수적인 요구사항이 됨
- 센서에서 획득한 다양한 측정값(다변량 시계열 데이터)을 기반으로 정상/비정상
- 전통적인 이상탐지(k-means clustering, SVM 등): '차원의 저주' 문제
- RNN 기반: 시계열에 효과적이지만 계산 비용 높고 학슶시간 긺
- GAN 기반: 모드 붕괴, 비수렴과 같은 학습 불안정성 문제
USAD
: UnSupervised Anomaly Detection for Multivariate Time Series
- autoencoder 아키텍쳐 기반 + GAN 영감받은 적대적 학습
- encoder-decoder 아키텍처가 이상 징후가 포함된 입력의 재구성 오류를 증폭 & GAN 보다 안정성 확보
2. Related Work
- DAGMM: Deep Autoencoding Gaussian Mixture Model
- 딥 오토인코더와 가우시안 혼합 모델을 결합하여 다차원 데이터의 밀도 분포를 모델링
- MSCRED: Multi-Scale Convolutional Recursive Encoder-Decoder
- 시간 의존성, 노이즈 강건성, 이상 심각도 해석을 동시에 고려
- LSTM-VAE: LSTM-Variational Autoencoder
- VAE의 feed-foward를 LSTM으로 대체하여 시계열의 시간 의존성을 모델링하고, 기존 방법보다 더 나은 일반화 능력을 제공
- ALAD: Adversarially Learned Anomaly Detection
- 양방향 GAN(bi-directional GANs)을 기반으로 이상 감지를 위한 적대적으로 학습된 특징(adversarially learned features)을 도출
- OmniAnomaly: Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network
- 확률적 변수 연결과 평면 정규화 흐름(planar normalizing flow)을 통해 강력한 다변량 시계열 표현을 학습하고, 재구성 확률을 사용하여 이상을 결정
- 위의 딥러닝 기반 방법들은 학습 속도가 느리다는 단점
- 본 논문은 빠르고 에너지 효율적인 학습을 가능하게 하는 아키텍쳐 개발의 필요성을 강조
- 기존 오토인코더 기반 방법의
- "약한 이상 감지(mild anomalies)" 문제를 극복
- GAN 기반 방법의 "학습 불안정성(mode collapse and non-convergence)" 문제를 해결
- RNN 기반 방법의 "높은 계산 비용" 문제를 개선
3. Method
3.1 Problem formulation
- train 입력 T는 정상 데이터만을 포함
- 관측치 와 정상 데이터 세트 가 얼마나 다른지는 anomaly score로 측정
- 현재 시점과 이전 시점들 간의 종속성을 모델링하기 위해, 길이 의 시간 윈도우 가 특정 시점 에 정의
- anomaly detection의 목표는 보이지 않는 윈도우 ()에 대해, 해당 윈도우의 비정상 점수를 기반으로 비정상 여부(비정상일 경우 , 아닐 경우 )를 나타내는 레이블 를 할당하는 것
- 훈련 입력 윈도우를 , 보이지 않는 입력 윈도우를 로 표기
3.2 Unsupervised Anomaly Detection
AutoEncoder 기반
- Encoder와 Decoder로 이루어진 비지도 인공신경망
- 학습목표: 최소화
- 한계: 이상이 정상 데이터와 너무 유사하여(toosmall) 재구성 오류가 작게 나타나면 이상을 탐지하지 못할 수 있음
GAN(Generative Adversarial Networks) 기반
- 생성자(G)와 판별자(D)라는 두 네트워크가 동시에 학습되는 비지도 인공신경망
- 생성자는 실제 데이터와 유사한 가짜 데이터를 생성하는 것을 목표로 하고, 판별자는 실제 데이터와 생성자가 만든 가짜 데이터를 구별하는 것을 목표로 함
- 두 네트워크는 서로 대립하는 minimax 게임을 통해 학습
USAD(UnSupervised Anomaly Detection) 방법론
- 하나의 인코더(E)와 두 개의 디코더()로 구성
- 동일한 인코더 네트워크를 공유하는 두 개의 오토인코더 과 로 연결됨
- Step 1) Autoencoder training
- 각 AE가 입력 윈도우 를 재구성하는 방법을 학습
- 과 는 모두 입력 와 각자의 재구성 출력 간의 재구성 오류를 최소화하도록 학습
- Step 2) Adversarial training
- 은 를 속이려고 시도하고, 는 데이터가 실제(에서 직접 온 것)인지 또는 재구성된 것(에서 온 것)인지를 구별하는 방법을 학습
- 의 목표: 와 간의 차이 최소화 > 가 의 재구성을 실제처럼 인식하게
- 의 목표: 와 간의 차이 최대화 > 의 재구성이 실제와 다르다는 것을 구별
- 두 단계 결합 학습:
- 실제 학습에서는 두 단계의 목적이 epoch 에 따라 진화하는 가중치()를 사용하여 결합
- 입력이 원본 데이터일 때는 재구성 오류를 최소화하고, 의 재구성 출력일 때는 차이를 최대화하는 이중 목적을 가짐
- Anomaly Score
- : 오탐이 줄어들고 실제 탐지도 다소 줄어드는 낮은 탐지 민감도 시나리오
- : 실제 탐지가 늘어나지만 오탐도 증가하는 높은 탐지 민감도 시나리오
3.3 Implementation
USAD 방법론 구현 3단계
Step 1: 데이터 전처리(Data Pre-processing) 단계
- training과 detection 과정 모두에 공통으로 적용
- Normalization: 데이터가 특정 범위 내에 있도록 스케일을 조정
- Splitting into time windows of length K: 시계열 데이터를 길이 K의 겹치거나 겹치지 않는 작은 시간 window로 나눔
Step 2: Training 단계
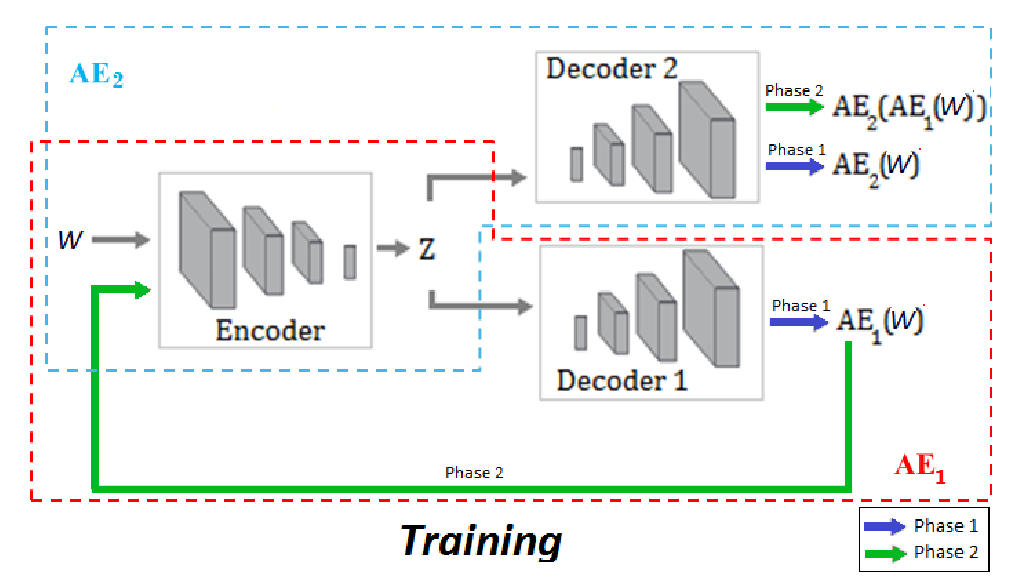
- offline으로 수행. 다변량 시계열 데이터의 '정상 행동' 패턴을 학습
- 미리 정의된 기간동안의 정상 데이터를 사용하여 모델을 학습, 각 window에 대한 anomaly score를 생성
- train 기간에 비정상적인 기간이 너무 많이 포함되지 않도록 선택
Step 3: Anomaly Detection 단계
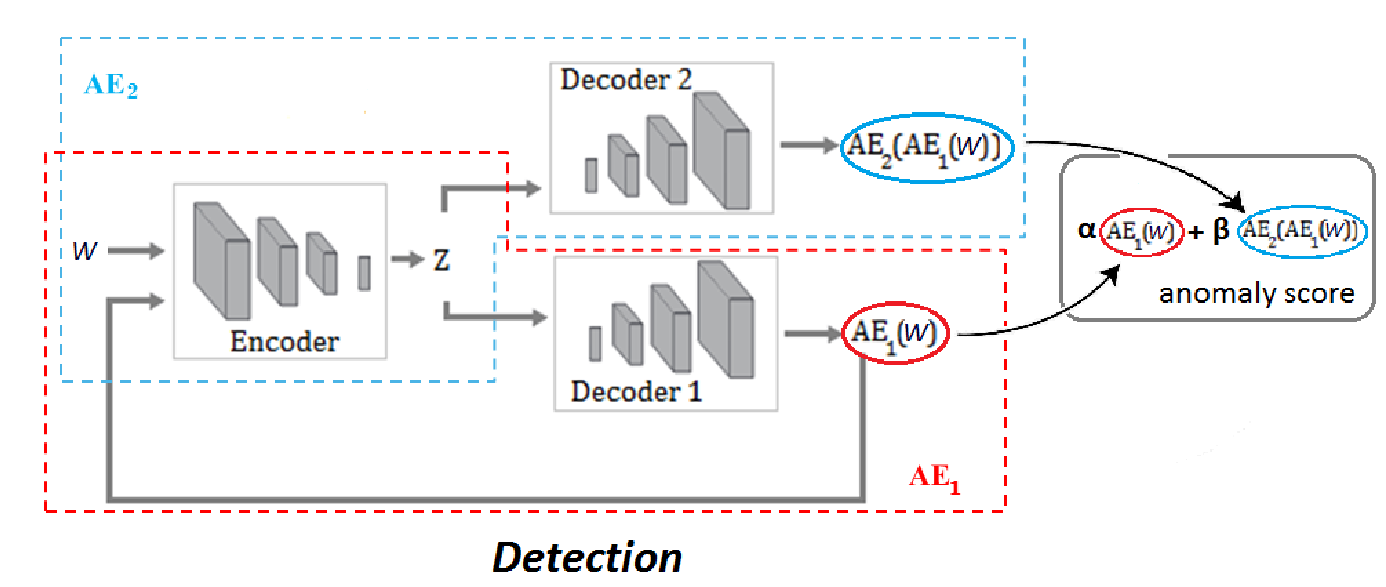
- 훈련된 모델을 사용하여 online으로 수행
- 새로운 시간 윈도우가 도착하면 훈련된 모델을 사용하여 해당 윈도우에 대한 이상 점수를 얻음 > threshold보다 높으면 비정상
4. Experimental Setup
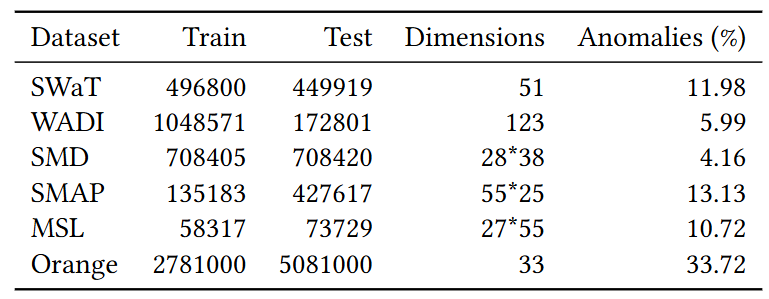
- SWaT: Secure Water Treatment
- WADI: Water Distribution
- SMD: Server Machine Dataset
- SMAP: Soil Moisture Active Passive
- MSL: Mars Science Laboratory
5. Experiments and Results
5.1 Overall performance
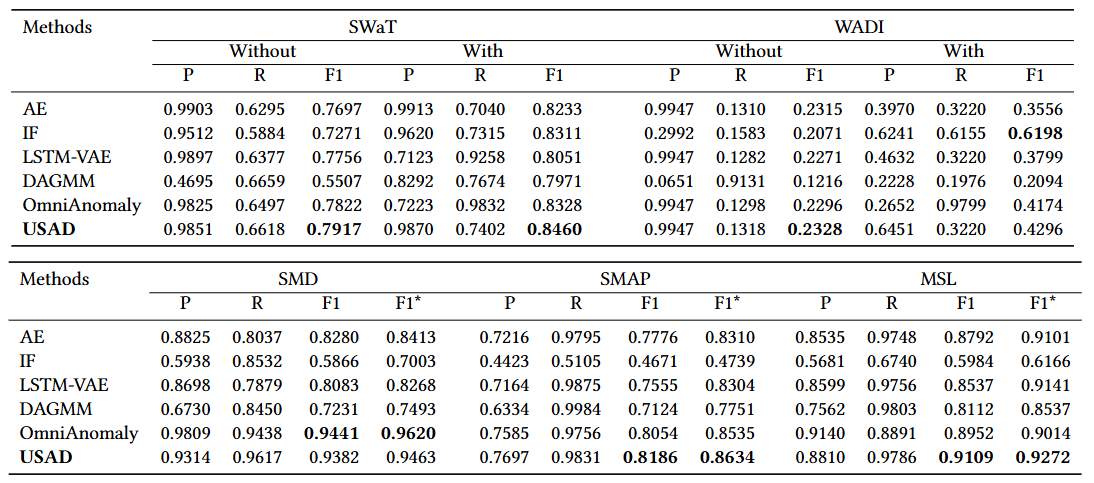
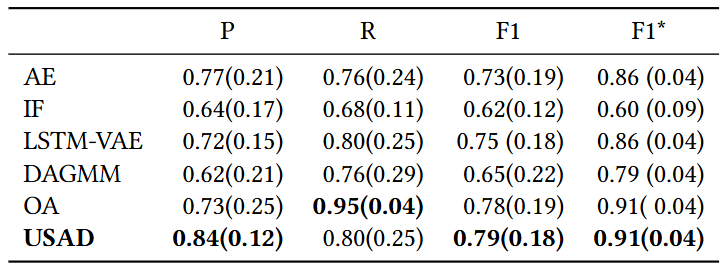
- USAD는 기존 SOTA 방법보다 평균 0.096 높은 성능을 달성
- Isolation Forests와 DAGMM은 시계열 데이터의 시간적 의존성을 활용하지 않기 때문에 대부분의 데이터셋에서 낮은 성능
- IF는 WADI에서 point-adjust를 적용했을 때 가장 높은 F1 점수를 기록 > IF가 각 시점을 독립적으로 분석하는 특성과 WADI의 이상 현상이 장시간 지속되는 특성이 결합되었기 때문 >> point-adjust 덕분에 단일 시점의 부정확한 예측이 전체 이상 세그먼트의 감지로 보정되는 효과
- AE, LSTM-VAE는 못잡는 경미한 이상도 USAD는 적대적 학습으로 이상을 증폭시켜 잡아냄
5.2 Effect of Parameters
Downsampling 비율
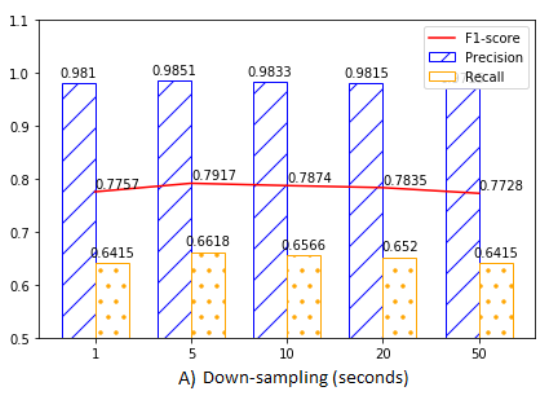
- USAD의 성능은 다운샘플링 비율에 비교적 둔감
- 5의 비율이 학습 데이터의 노이즈 감소와 정보 손실 최소화 사이의 최적의 균형
Window Size
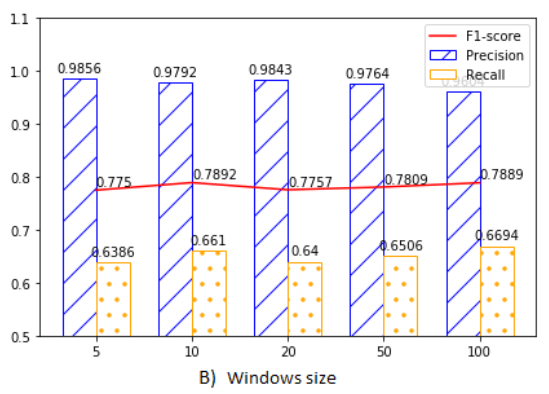
- K=10일 때 가장 좋은 성능
- 윈도우 크기가 작으면 각 관측값이 비정상 점수에 미치는 영향이 커져 행동 변화를 더 빨리 감지 가능
- 윈도우 크기가 너무 크면 이상 징후를 감지하기 위해 더 많은 관측값을 기다려야 하지만, 더 긴 이상 징후를 감지하는 데 유리
Latent space의 차원
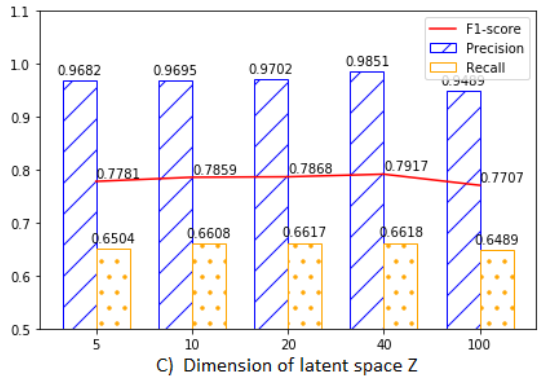
- m이 너무 작으면 인코딩 단계에서 정보 손실이 커져 성능이 저하
- m이 너무 크면 학습 데이터의 과적합이 발생하여 성능이 떨어짐
- 중간 범위의 m 값은 비교적 높고 안정적인 F1 점수
train 데이터 내의 노이즈(anomaly) 비율
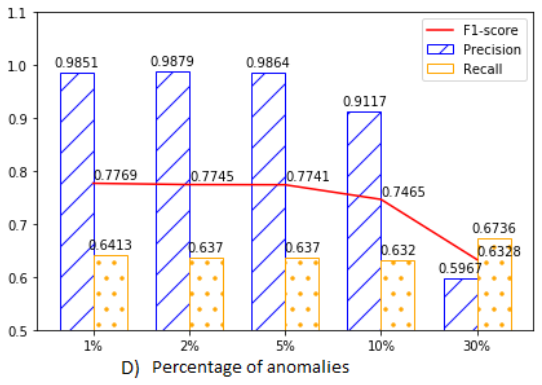
- 최대 5%의 노이즈 수준까지는 비교적 일관되고 높은 성능을 유지하며 강건
- 노이즈가 10%가 되면 성능 저하가 나타나기 시작하며, 특히precision이 낮아져 false positive가 증가하는 경향 > USAD가 복잡한 정상 행동을 비정상으로 오인
- 30%와 같은 높은 노이즈 수준에서는 성능이 크게 저하되지만, 실제 운영 환경에서는 이렇게 많은 비정상 데이터를 놓치는 상황은 비현실적이라고 판단
Sensitivity Threshold
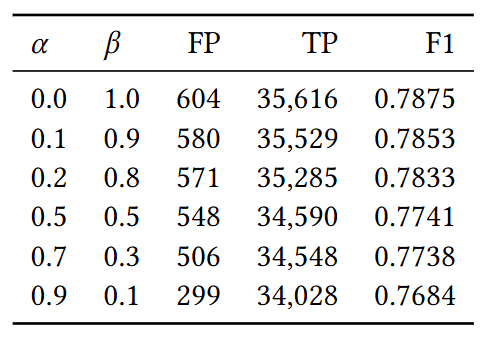
- 를 증가시키고 를 감소(의 재구성 오차에 더 큰 중요도를 부여)
- FP의 수를 최대 50%까지 줄임
- TP의 감소는 3%에 그쳐 제한적
5.3 Training time
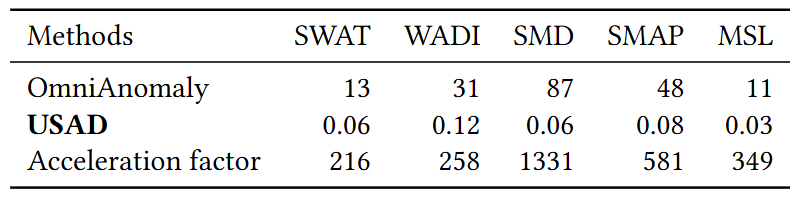
- epoch당 평균 훈련시간
- USAD는 OmniAnomaly에 비해 훈련 시간을 평균 547배 단축
5.4 Ablation Study
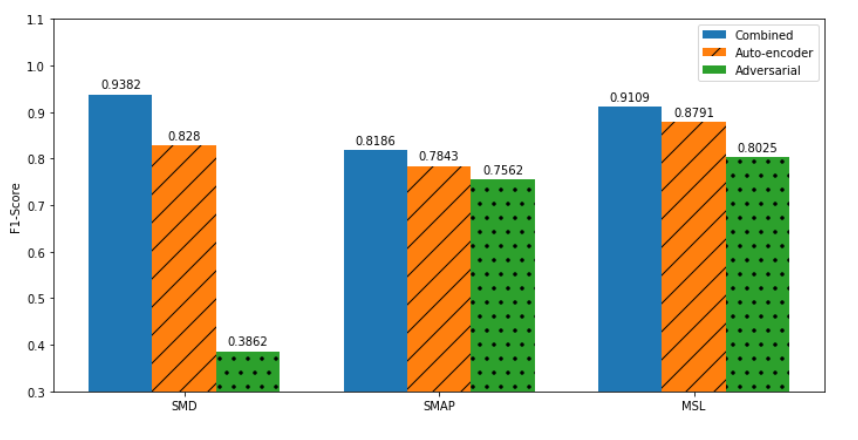
- USAD가 가장 높은 F1 score 기록
- USAD with only phase one training (Autoencoder)은 USAD보다 저조
- USAD with only phase 2 training (Adversarial)는 세 가지 모델 중 가장 낮은 성능 > Phase 1의 오토인코더 학습이 모델의 가중치를 '좋은 시작점'으로 안내하는 역할을 하는데, 이 단계가 없으면 적대적 학습이 효과적으로 이루어지기 어렵기 때문
6. Conclusions
- 빠른 훈련 속도, 파라미터 선택에 대한 robustness, 안정성을 입증하여 산업 환경에서의 높은 scalability을 보임
- 단일 모델로 다양한 감지 sensitivity를 조절할 수 있는 파라미터()를 제공 > Orange와 같은 기업의 IT 시스템 감독 팀에게 필수적인 기능
- 관리자는 주요 사고에 대해 낮은 민감도를, 기술자는 최소한의 사고도 놓치지 않기 위해 높은 민감도를 설정할 수 있게 함
- 하나의 모델만 훈련하면 되므로 훈련 시간 및 모델 관리/감독에 소요되는 시간을 줄여 인력의 효율적인 활용이 가능해짐
- 배포 및 실행 과정에서 예상치 못한 어려움(예: 이상 징후가 없는 연속적인 정상 훈련 데이터 수집의 어려움)이 발견, 이는 USAD를 성공적으로 배포하기 위한 인프라 구축의 중요성을 시사
