Multivariate Time-series Anomaly Detection via Graph Attention Network
Hang Zhao · Yujing Wang · Juanyong Duan · Congrui Huang · Defu Cao · Yunhai Tong · Bixiong Xu · Jing Bai · Jie Tong · Qi Zhang
Proceedings of the 20th IEEE International Conference on Data Mining (ICDM), 2020.
Abstract
- 다변량 시계열 이상 탐지는 산업/응용 분야에서 중요 > 서로 다른 시계열들 간의 관계를 명시적으로 포착하지 못해, 필연적으로 false alarm 발생
- self-supervised 방식 MTAD-GAT 제안
- 두개의 병렬 Graph Attention Layer(GAT) > 시간 차원, 특징 차원 모두 다변량 시계열 복잡 의존성 학습
- 예측 기반 모델 및 재구성 기반 모델의 공동 최적화
1. Introduction
- 단변량 시계열 이상 탐지는 개별 지표의 이상을 찾지만, 전체 시스템의 정상 작동 여부를 판단하기에는 부족
- 실제 상황에서는 여러 시계열 지표가 상호연관 > 다변량 시계열 이상탐지는 서로 다른 시계열 간의 상관관계를 고려해야함
- 기존 다변량 시계열 이상탐지 연구의 한계
- 서로 다른 시계열 간의 관계를 명시적으로 포착하지 못함
- 제안 솔루션
- 새로운 self-supervised 프레임워크 제안
- 각 단일 시계열을 개별 특징으로 간주
- 두 병렬 Graph Attention Layer로 시간/특징 차원 모두 학습
- 예측 기반 & 재구성 기반 공동 최적화
2. Related Work
시계열 이상 탐지 분류
1) 분석 대상 시계열 개수
- Univariate Model: 각 시계열을 개별적으로 분석 > 하나의 지표에만 집중하여 비정상패턴 찾음
- Multivariate Model: 여러 시계열을 하나의 통합된 개체로 모델링 > 시스템 전체의 이상 상태 파악
2) 이상 탐지 모델의 패러다임
- Forecasting-based Models: 예측값과 실제 관측값과의 차이로 이상 여부 판단
- Reconstruction-based Models: 정상 패턴을 저차원으로 인코딩 후 재구성하여 재구성 오류로 이상 여부 판단
2.1 Univariate Anomaly Detection
Classic Methods
- hypothesis testing, wavelet analysis, SVD, ARIMA, Robust PCA 등
Neural Networks
- DONUT, SR-CNN
2.2 Multivariate Anomaly Detection
1) Forecasting-based
- LSTM-NDT, DAGMM
2) Reconstruction-based
- LSTM-based Encoder-Decoder, OmniAnomaly,MAD-GAN, LSTM-VAE, Kitsune
3. Methodology
- Problem Definition
- inter-feature correlation/temporal dependency를 각각 평행한 graph attention network로 모델링 한다
- Gated Recurrent Unit(GRU)를 이용해서 sequential data의 long-term dependency를 capture
- joint objective function을 통해 예측/재구성 기반 모두를 최적화
3.1 Overview
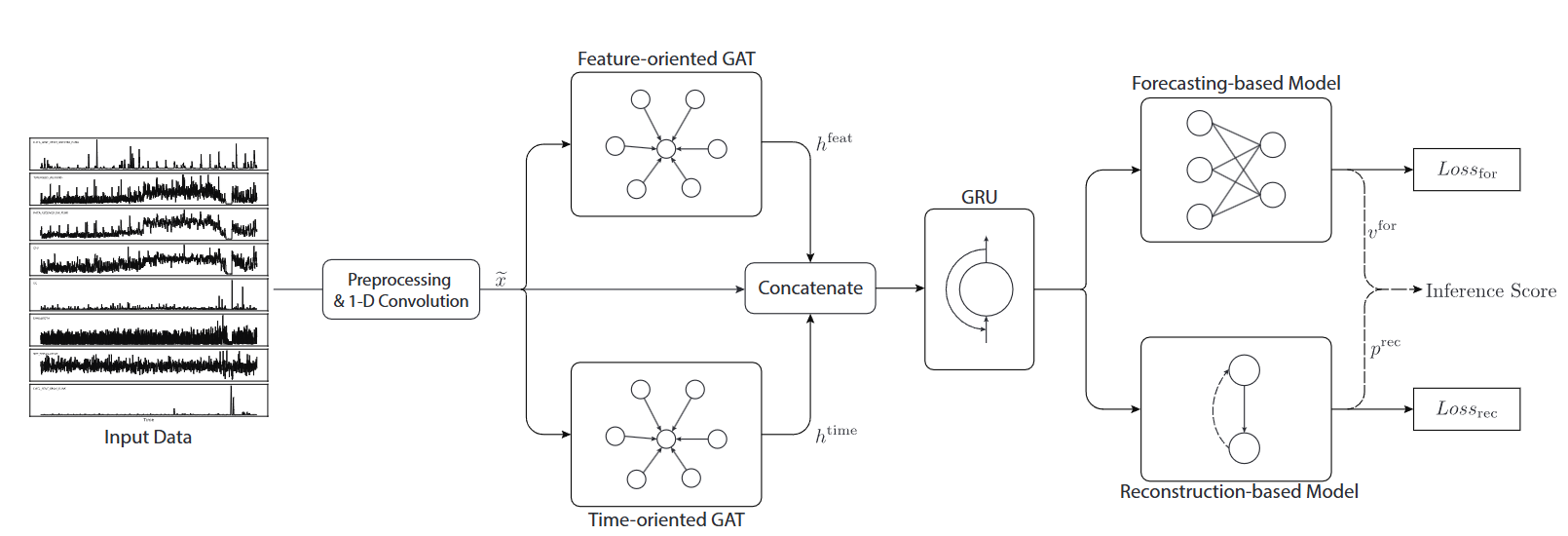
- kernel size 7의 1D convolution을 첫 레이어에 적용하여 high-level feature를 추출
- convolution operation이 sliding window내의 local feature를 잘 파악함
- 1D convolution layer의 output을 두 평행한 Graph Attention (GAT) 레이어로 전달 > 다변량 변수와 시간과의 관계 파악
- GRU에 1D convolution output과 두개의 GAT layer의 output을 넣음
- GRU의 output을 예측/재구성 모델 각각에 입력
- 예측 기반 모델은 fully-connected network
- 재구성 기반 모델은 VAE
3.2 Data Preprocessing
1) Data Normalization
2) Data Cleaning
- 예측 기반/재구성 기반 모델은 비정상 데이터에 예민
- SOTA 단변량 이상치 탐지 기법: Spectral Residual(SR) 이용
- 탐지된 이상치들은 주변의 정상치로 대체됨
3.3 Graph Attention
- : graph의 노드 개수
- : 노드 의 feature vector
- : 노드 의 output representation
- : sigmoid activation function
- : node 가 node 에 기여하는 attention score
- : node 의 인접 노드 개수
- ⊕: 두 노드 표현의 concat
- : GAT 레이어 내에서 학습을 통해 최적화 되는 가중치 벡터 > learnable parameter
Feature-oriented Graph Attention Layer
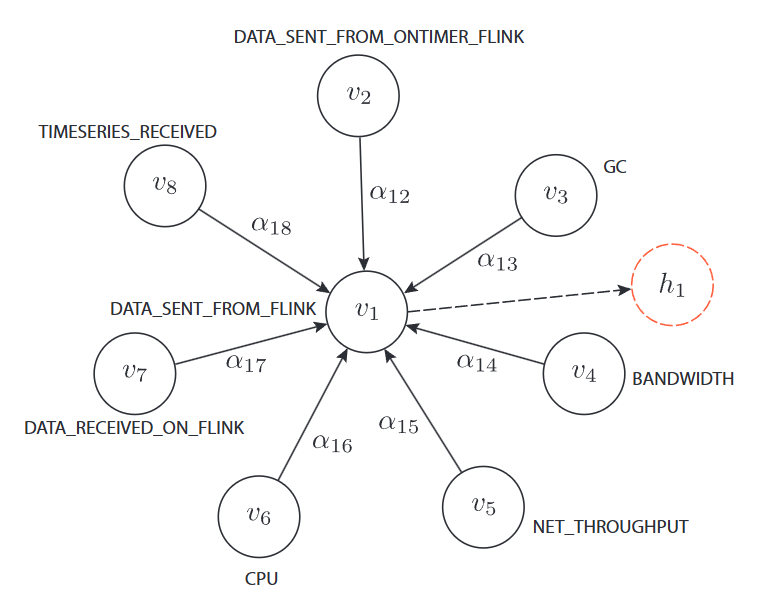
- MTAD-GAT 모델의 핵심 구성 요소> 다변량 시계열 데이터에서 서로 다른 feature간의 관계를 명시적으로 학습
- Node: 각 개별 시계열을 하나의 독립적인 feature로 간주 > feature를 그래프의 하나의 노드로 표현
- Edge: 다변량 시계열을 완전 그래프로 취급 > 모든 feature 노드 쌍 사이에 edge가 존재하여, 모든 feature가 서로에게 잠재적으로 영향을 미칠 수 있음
- Graph Attention Network을 통해 node(feature)간의 관계 학습
Time-oriented Graph Attention Layer
- 동일한 feature의 다른 timestamp들 간의 관계 파악
- 주어진 sliding window내의 모든 timestamp를 각 독립적인 노드로 간주
- 각 노드 는 해당 timestamp에서의 전체 피처 벡터
- 노드들로 완전 그래프 구성 > 모든 timestamp 노드가 서로에게 인접노드가 됨
- Transformer의 fully-connected self-attention과 매우 유사
Concatenation: 정보 융합
- 1) 전처리된 입력 :
- 원본 입력 데이터에 전처리(1-D Convolution 포함)를 거친 결과
- 형태는
- 2) Feature-oriented GAT:
- 각 피처 노드에 대한 차원 시퀀스 벡터
- 형태는
- 3) Time-oriented GAT:
- 각 타임스탬프 노드에 대한 차원 피처 벡터
- 형태는
3.4 Joint Optimization
Forecasting-based Model
- GRU 레이어 출력 뒤에 3개의 Fully Connected Layer를 쌓아 구성
- 손실함수: RMSE로 예측/실제 값 사이의 오차 최소화
Reconstruction-based Model
- VAE 목적 함수는 주어진 입력 에 대한 조건부 분포 로부터 재구성되는 방식으로 학습
- Loss = expected negative 로그우도 + 인코더/사전분포 사이의 KL divergence
4. Experiments
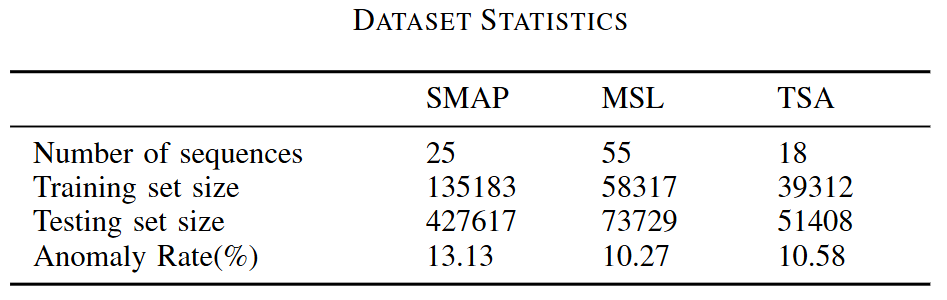
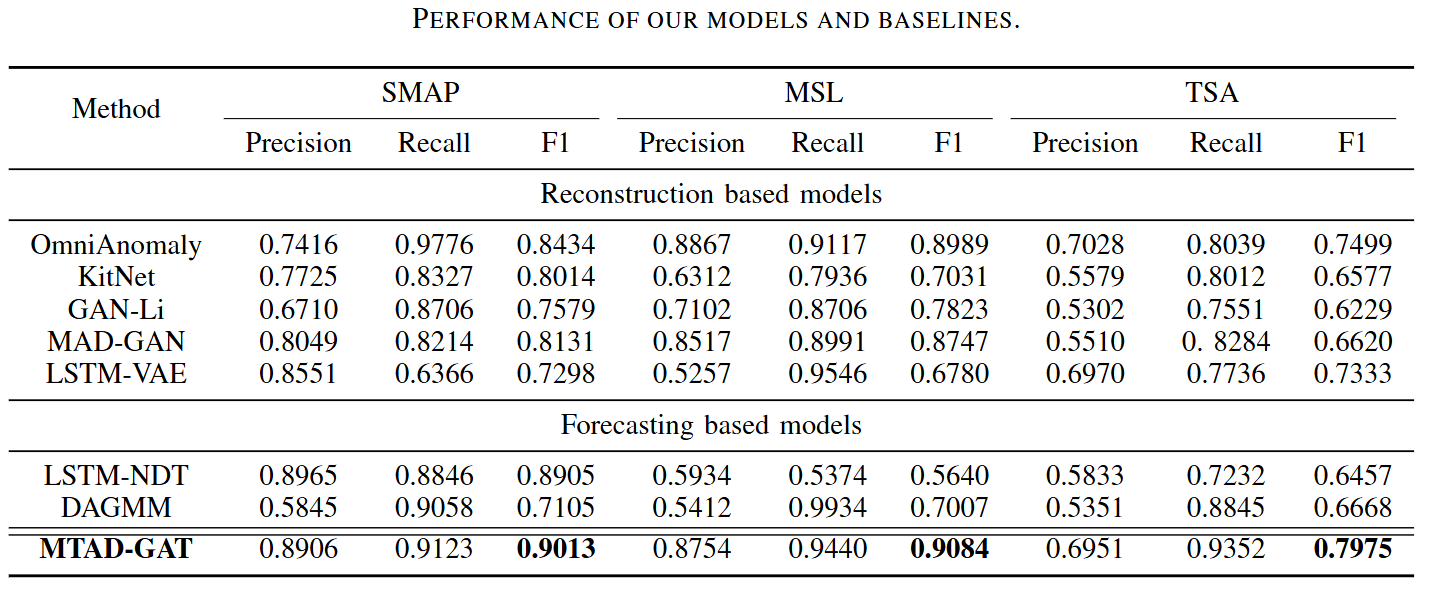
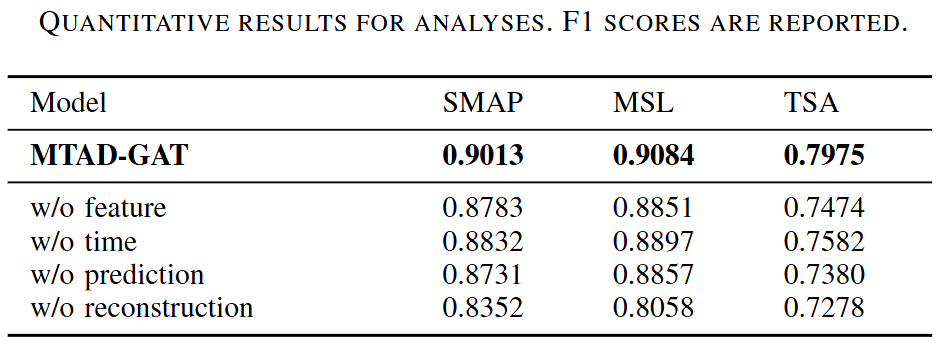
- 다변량 상관관계 명시적 모델링의 중요성:
- OmniAnomaly처럼 다변량 시계열 간의 특징의 상관관계 파악하지 못하는 모델보다 MTAD-GAT가 모든 데이터셋에서 우수
- 시간적 의존성 모델링의 중요성:
- DAGMM과 같이 시간적 정보 고려하지 않는 모델을 성능이 좋지 않음
- 예측 기반 및 재구성 기반 모델의 강점 결합:
- LSTM-NDT와 같은 예측 기반 모델 > 예측 불가능한 경우에 민감 (MSL,TSA)
- OmniAnomaly와 같은 재구성 기반 > MSL, TSA에서 더 나은 결과
- joint optimization이 최적의 결과
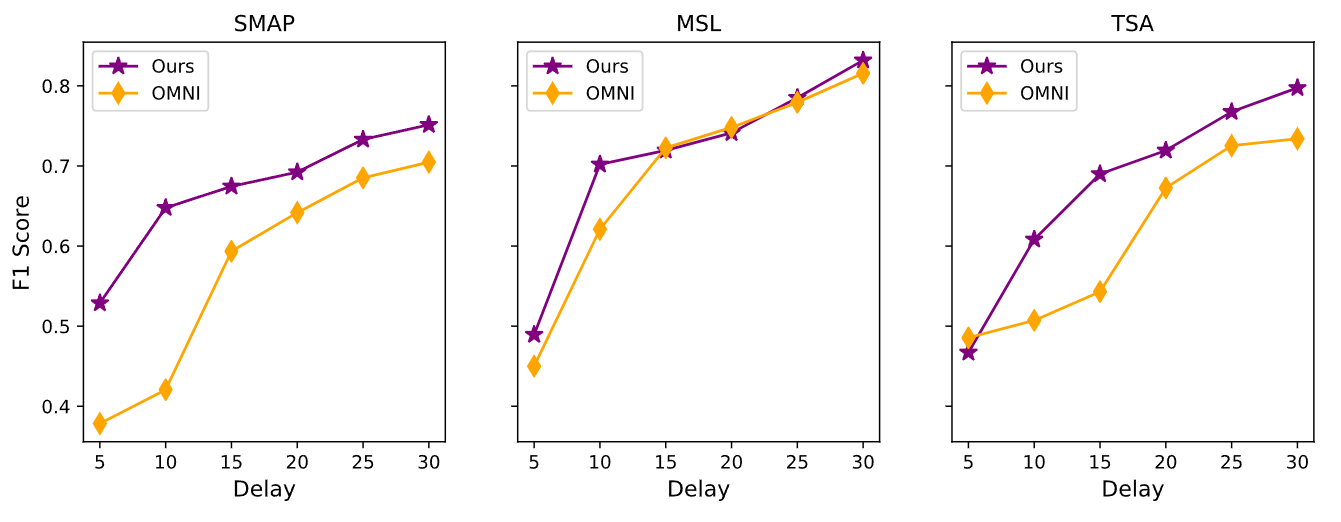
- 실제 시스템에서는 anomaly가 연속적인 구간에서 발생
- 첫 번째 이상 시점으로부터 최대 스텝 이내에 모델이 이상을 정확하게 감지하면, 해당 이상 구간 전체를 참 양성(True Positive)으로 간주
- 이면 이상이 시작되는 바로 그 시점에서 감지해야만 참 양성
- 이면 이상 시작 후 10스텝 이내에만 감지하면 해당 이상 구간 전체가 참 양성
- 일반적으로 값이 커질수록 F1-score도 증가
- 전반적으로 MTAD-GAT는 baseline 모델인 OmniAnomaly보다 일관되게 더 나은 성능
5. Analyses

- 정상적인 상황(왼쪽): 특정 특징(DATA SENT FROM FLINK)과 다른 관련 특징들(DATA RECEIVED ON FLINK, TIMESERIES RECEIVED) 사이에 강한 어텐션 스코어
- 이상 발생(오른쪽): DATA SENT FROM FLINK와 CPU, DATA RECEIVED ON FLINK 간의 상관관계가 약해지는 것을 어텐션 스코어 변화를 통해 감지
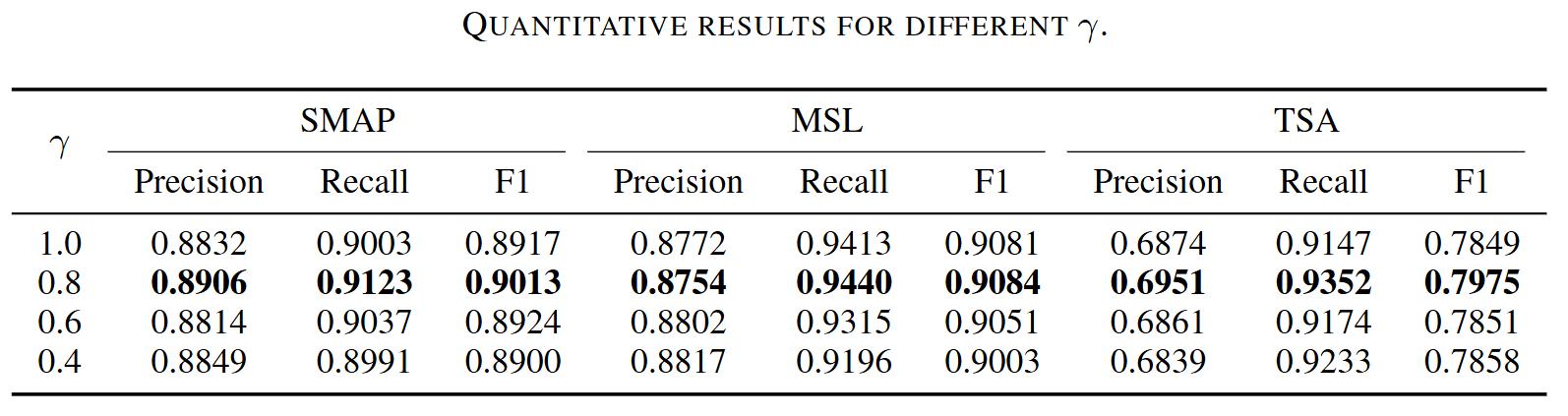
- 는 forecasting-based model의 예측 오류와 reconstruction-based model의 재구성 기반 확률을 결합하여 최종 이상 점수를 계산하는 데 사용되는 하이퍼파라미터
- 일 때 가장 좋은 성능
- 를 0.4에서 1.0 사이로 설정했을 때, 이 논문에서 비교한 다른 최신 모델들보다 일관되게 더 나은 결과
- 제안된 MTAD-GAT 모델이 값의 변화에 대해 강건함을 보여줌
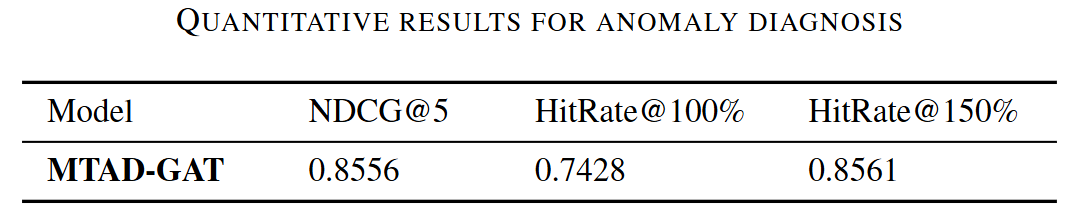
- NDCG: 랭킹의 정확도를 정량화. 관련성 높은 feature가 상위에 랭크될수록 높은 NCDG 점수.
- HitRate@P%: 상위 P%의 진단 후보 안에 실제 근본 원인이 포함되는 비율을 측정합니다.
- 실제 근본 원인의 약 70%를 진단 결과에서 포착하고 상위 5개 후보 내에서 근본 원인을 찾을 확률이 높음을 보여줌
6. Case Study
True Negative Case
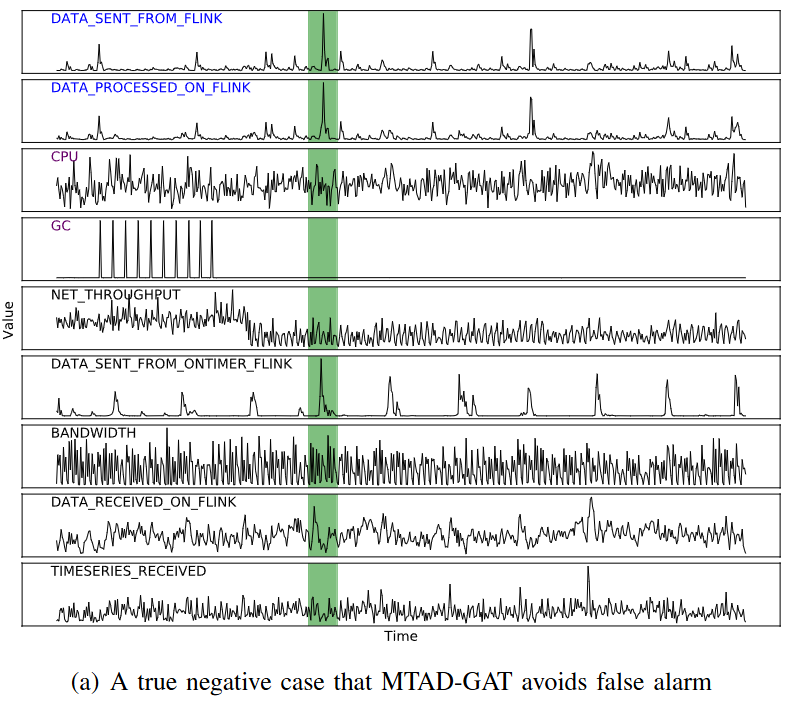
- 여러 시계열에서 스파이크 나타남
- 개별 시계열을 탐지했다면 false alarm 발생할 수 있었음
- MTAD-GAT는 시스템이 정상 상태임을 정확히 인지하여 불필요한 오탐을 크게 줄임
False Positive Case
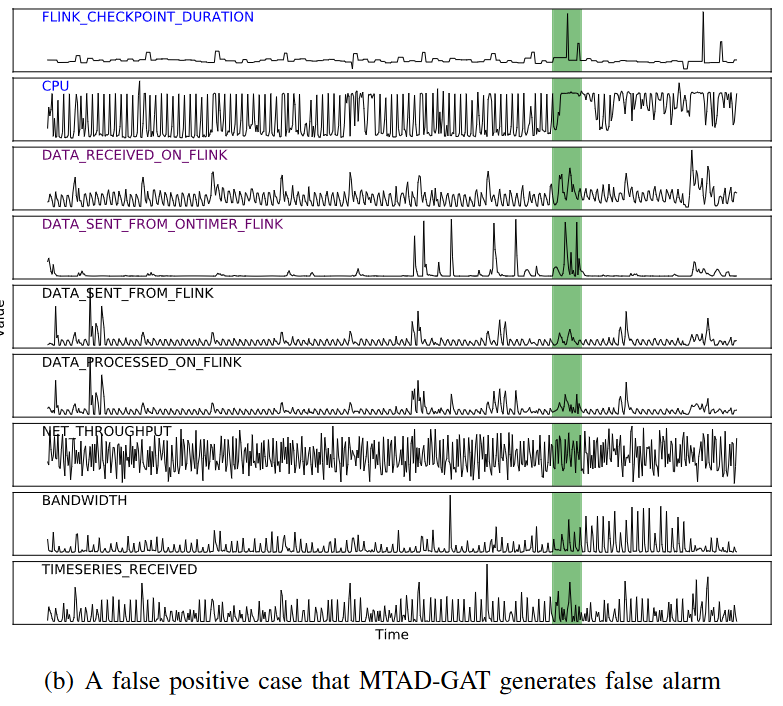
- FLINK CHECKPOINT DURATION과 CPU에서 비정상적인 스파이크가 감지
- MTAD-GAT 모델은 이를 이상 징후로 판단하고 알림을 발생
- 실제로는 입력 데이터 볼륨이 일시적으로 증가하여 발생한 현상
- 해당 유형의 스파이크가 과거 데이터에서 드물게 나타났기 때문에, 비지도 학습 기반의 이상 탐지 알고리즘인 MTAD-GAT는 이를 비정상적인 경우로 처리
7. Conclusion
- 모델 제안 :
Graph Attention Network를 기반으로 하는 Multivariate Time-series Anomaly Detection를 위한 새로운 프레임워크 제안 - 주요 방법론:
- 다변량 시계열의 특징(feature-wise) 및 시간적(temporal) 관계를 학습
- 예측 기반 모델과 재구성 기반 모델의 장점을 결합한 joint optimization 전략 사용
