Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network
Ya Su · Youjian Zhao · Chenhao Niu · Rong Liu · Wei Sun · Dan Pei
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2019
Abstract
- 서버,우주선 등 산업장비는 일반적으로 다변량 시계열 데이터로 모니터링됨
- 다변량 시계열 데이터의 복잡한 시간적 의존성과 확률성 때문에 이상탐지는 여전히 어려운 과제임
- OmniAnomaly: 확률적 RNN 제안
- 다변량 시계열의 정상 패턴을 학습하여 robust representation을 포착, 입력 데이터 재구성, 재구성 확률을 통해 이상 여부 결정
- stochastic variable connection: 잠재공간에서 확률 변수들 간의 시간적 의존성을 명시적으로 모델링
- planar normalizing flow: 입력 데이터의 복잡한 분포를 포착하기 위해 non-gaussian 사후 분포를 학습
- 탐지된 이상에 대한 해석 제공 > 특정 시계열의 재구성 확률이 낮으면 해당 시계열이 이상 발생에 크게 기여
1. Introduction
- 같은 entity에서 단변량 시계열 여러개가 다변량 시계열을 이룸
- 다변량 시계열을 활용하여 entity 수준에서 anomaly detection하는 것이 단변량 시계열을 사용하여 개별 metric 수준에서 anomaly detection하는 것보다 선호됨
- 운영 엔지니어들은 entity 전반적인 상태에 관심가짐
- 개별 감지는 labor-intensive
- metric끼리도 영향 줄 수 있기 때문에 이 규칙을 정의하기 어려움
- 여러 매트릭을 볼 때 더 정보를 활용할 수 있음
도전 과제
1. Robust Latent Representation
- 기존 확률 모델로는 시계열의 장기적인 의존성, 복잡한 확률 분포 포착 어려움
- VAE + LSTM 단순 결합한 방식도 확률변수 간의 시간적 의존성 고려 못함
- OmniAnomaly: GRU(RNN 변형)+VAE = stochastic recurrent neural network
- stochastic variable connection 기법
- planar Normalizing Flow
2. Providing anomaly interpretation
- 모델이 가장 잘 재구성하지 못하는(재구성 확률이 낮은) 개별 메트릭들이 해당 이상 현상에 가장 크게 기여했다고 판단
2. Related Work
지도학습 > 레이블 데이터 필요. 알려진 이상 유형만 식별 가능.
현실적인 시나리오에서는 비지도학습이 효율적
기존 비지도 학습 방법
- 결정론적 방법
- 시계열의 시간적 의존성 다룸. 확률적 변수 활용 x. 시계열의 내재된 확률적 특성 모델링 x. LSTM-NDT, EncDec-AD 등
- 확률적 기반 모델
- 확률적 변수 사용하여 데이터 분포 포착. 시계열의 시간적 의존성 충분히 고려 x. DAGMM, LSTM-VAE 등
3. Preliminaries
3.1 Problem Statement
3.2 Overall Structure
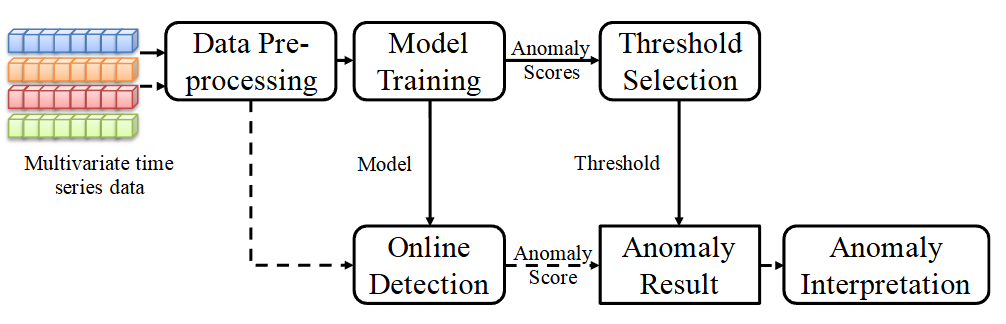
점선: 오프라인 학습 / 실선: 온라인 탐지
1) Data Preprocessing
- data standardization을 통해 원본 데이터를 변환
- 길이가 T+1인 sliding window로 데이터셋을 sequence로 분할
2) Offline Training
- 전처리된 훈련용 다변량 시계열 데이터를 train
- model training에서 정상 패턴을 학습, 이상 점수 부여
- anomaly score들이 threshold selection으로 전달되어 POT(Peaks-Over-Threshold) 방법을 사용하여 threshold 설정
- 오프라인 학습 과정은 주간/월간 단위로 정기적 수행
3) Online Detection
- offline 학습을 통해 훈련된 모델과 anomaly threshold를 저장하고 사용
- 전처리된 새로운 관측치가 online detection에 입력되면 해당 관측치에 대한 새로운 anomaly score 계산
- score가 threshold보다 낮으면 이상으로 판단
4) Anomaly Interpretation
- 이상으로 탐지되면 해당 이상 현상에 기여하는 각 단변량 시계열의 재구성 확률을 추정하고 순위를 매겨 이상에 대한 해석을 제공
3.3 Basics of GRU, VAE and Planar NF
GRU: Gated Recurrent Unit
- RNN의 한 종류. 일반적인 RNN의 long-term dependence 을 학습하기 어려운 문제를 해결하기 위해 고안
- LSTM과 유사하게 gating mechanism을 사용하여 정보 제어, 전달.
- GRU는 LSTM만큼 좋은 성능 보이면서, 파라미터 수가 적고 구조가 간단 > OmniAnomaly에서 GRU를 사용
VAE: Variational Autoencoder
- deep Baysian Model의 일종. 고차원 입력 를 저차원 표현 로 압축후 다시 를 재구성
- AE와 다르게 잠재공간을 확률분포로 모델링
- 가 주어졌을때 잠재 변수 의 사후 분포 를 학습, 이 로부터 생성하는 분포를 학습
- 실제 사후 분포 는 계산하기 어렵기 때문에, 추론 네트워크(inference network) 를 사용하여 이를 근사
- θ는 생성 네트워크(generative network, pnet)의 파라미터, 는 추론 네트워크(inference network, qnet)의 파라미터
- ELBO(데이터의 marginal log-likelihood의 하한) 최대화
Planar NF
- 기존 VAE는 추론 네트워크의 사후분포를 단순 대각 가우시안 분포로 가정 > 데이터 분포 가우시안이 아니면 표현력 떨어짐, 언더피팅 유발
- Invertible mapping(가역 매핑)을 통해 잠재변수를 매핑함수를 통과시켜 최종잠재변수 얻음
- Planar NF 통해 잠재변수가 입력의 비가우시안적 분포를 더 잘 포착 > '정상 패턴'을 더 정교하게 학습
4. Design of OmniAnomaly
4.1 Network Architecture
- x-space에서 시간적 의존성 포착 : GRU를 사용하여 시계열 관측값간의 시간적 의존성 학습
- VAE를 통한 잠재표현 학습: 고차원 입력 를 저차원 확률적 잠재공간표현 로 매핑, 재구성
- 잠재 공간(z-space)에서의 시간적 의존성 모델링 (확률 변수 연결):
- 기존 VAE 모델들이 z-space 변수들 간의 시간적 의존성을 간과하는 한계를 극복하기 위해 Linear Gaussian State Space Model (SSM)을 사용하여 와 를 연결
- Planar NF 적용: qnet(인코더)에서 확률변수 가 비가우시안 분포를 포착할 수 있도록
네트워크 두가지 주요 부분
-
qnet (추론 네트워크, Inference Network):
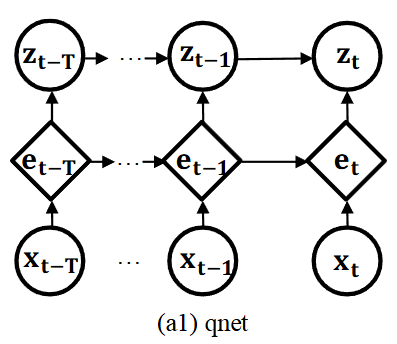
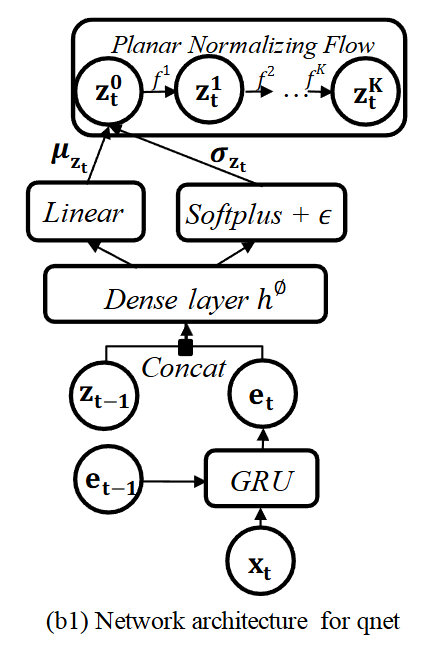
- 입력 데이터 로부터 잠재 변수 의 사후 분포를 근사
- 시간 t에서 입력 와 이전 시점의 GRU 은닉 변수 가 GRU 셀에 입력되어 현재 시점의 은닉 변수 를 생성
- 이 는 이전 시점의 확률 변수 와 연결되어 밀집층(dense layer)을 거쳐 확률 변수 의 평균 와 표준편차 를 생성
- 여기서 생성된 (초기 가우시안 샘플)는 Planar NF를 통과하여 (최종 확률 변수 )로 변환되어 비가우시안 분포를 학습
-
pnet (생성 네트워크, Generative Network)
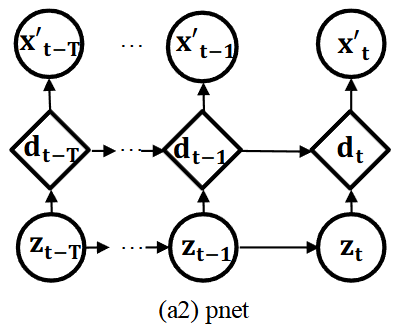
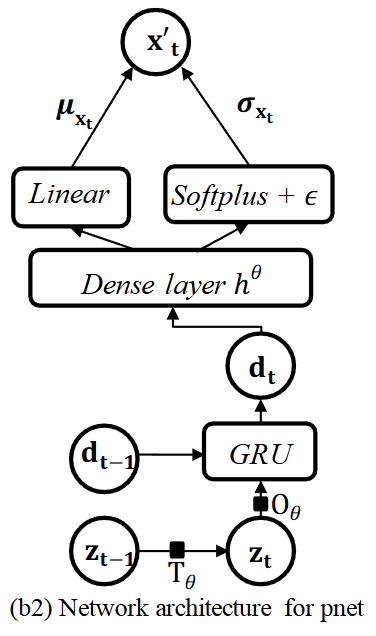
- 잠재 변수 로부터 원본 데이터 를 재구성하는 역할
- qnet에서 얻은 는 GRU 셀에 입력되고, 이전 시점의 은닉 변수 와 함께 현재 시점의 은닉 변수 를 생성
- 이 는 밀집층을 거쳐 재구성된 데이터 의 평균 와 표준편차 를 생성
- pnet에서는 Linear Gaussian SSM을 활용하여 z-space 변수들 간의 시간적 의존성을 명시적으로 연결
4.2 Offline Model Training
- OmniAnomaly 모델의 오프라인 학습은 qnet,pnet을 동시에 훈련. 시계열 데이터의 정상 패턴 학습, 잠재표현 최적화 목표
- VAE의 최적화 프레임워크인 ELBO를 최대화
- ELBO: VAE 모델 훈련에 사용되는 목적함수
- 재구성 오류 + 정규화 항
- 몬테카를로 적분을 이용하여 ELBO의 기댓값 근사
4.3 Online Detection
- 특정 시점 t의 관측값 가 이상한지 여부 결정
- 시점 t의 관측값과 그 이전 T개의 연속적인 관측값 (길이 T+1)를 입력 받음
- 이상 점수 St 계산 > 높으면 정상, 낮으면 이상
4.4 Automatic Threshold Selection
- 이상치인지 아닌지 판단하는 임계값을 자동으로 설정
- 1) 이상치 점수 시계열 생성
- 이상치 점수 단변량 시계열을 형성
- 낮은 점수 > 이상치일 확률 높음
- 2) 극단값 이론 (Extreme Value Theory, EVT) 기반 임계값 설정
- 확률 분포의 꼬리 부분의 법칙을 찾는 통계이론 > 데이터 분포를 가정하지 않고 극단값을 찾을 수 있다는 장점
- EVT의 두번째 정리 POT(Peaks-Over-Threshold)방법 채택하여 이상치 점수 임계값 학습
- 3) POT 방법의 이상치 탐지 적용
- 이상치 점수 분포의 '낮은 끝(low end)'에 집중
- 낮은 이상치 점수 S를 초기 임계값 th에서 뺀 값 (th-S)를 '높은 끝'에 위치하도록 변환하여 GPD(Generalized Pareto Distribution)에 적합시킴
- 4) 최종 임계값 계산
- MLE(Maximum Likelihood Estimation)을 통해 GPD의 매개변수 추정
- 추정된 매개변수를 이용하여 최종 이상치 임계값 계산
4.5 Anomaly Interpretation
- 이상 발생에 가장 크게 기여한 (재구성 확률이 가장 낮은) 개별 시계열 지표를 식별하여 제공
- 이상으로 탐지된 관측값 에 대해, 각 차원 의 이상 점수 를 계산
- 이 점수들을 오름차순(점수가 낮을수록 이상에 대한 기여도가 높음)으로 정렬하여 리스트 를 생성
- 에서 상위에 랭크된 몇몇 차원(예: 상위 10%, 20%)을 운영 엔지니어에게 제시하여 이상 현상의 원인 분석 및 문제 해결을 도움
5. Evaluation
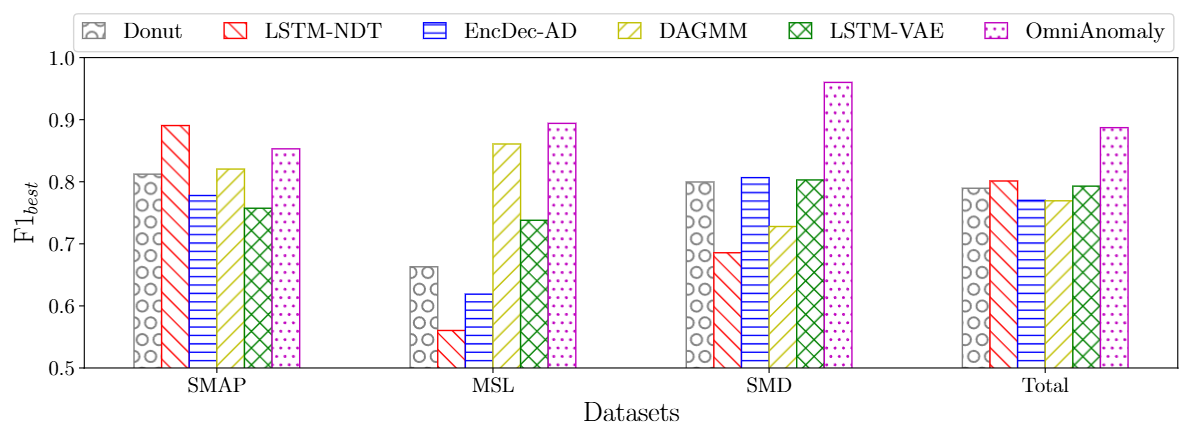

- OmniAnomaly가 가장 높은 Total F1best 점수
- SMAP 데이터셋에서는 LSTM-NDT 다음으로 두 번째로 높은 성능
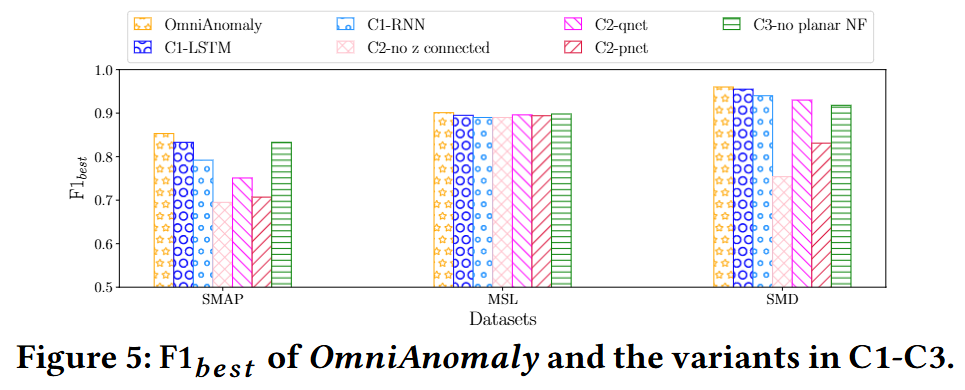
- OmniAnomaly: 본 논문에서 제안하는 완전한 모델
- C1-LSTM : OmniAnomaly의 GRU를 LSTM으로 대체한 모델
- C1-RNN : OmniAnomaly의 GRU를 Simple RNN으로 대체한 모델
- C2-no z connected : OmniAnomaly에서 z-공간 변수 간의 시간적 의존성 연결을 제거한 모델
- C2-qnet : z-공간 변수 연결을 qnet(인코더)에만 적용한 모델
- C2-pnet : z-공간 변수 연결을 pnet(디코더)에만 적용한 모델
- C3-no planar NF : OmniAnomaly의 qnet에서 planar Normalizing Flows(NF)를 사용하지 않고 Gaussian 분포를 가정한 모델
효과 분석
- C1 비교: GRU 효과
- C2 비교: z-공간 변수 연결의 효과 > MSL은 데이터 특성 때문에 간단한 z-공간도 괜찮아서 차이가 크지 않음
- C3 비교: Planar NF의 효과 > MSL은 데이터 특성 때문에 간단한 z-공간도 괜찮아서 차이가 크지 않음
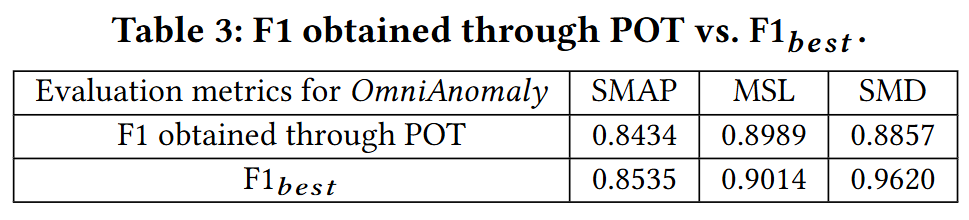
- POT로 자동 설정 임계값으로 얻은 F1과 이론적으로 가장 높은 인 를 비교
- 모든 데이터셋에서 POT를 통해 얻은 F1-Score가 에 매우 가까움
6. Discussion
6.1 Visualization on z-space representations
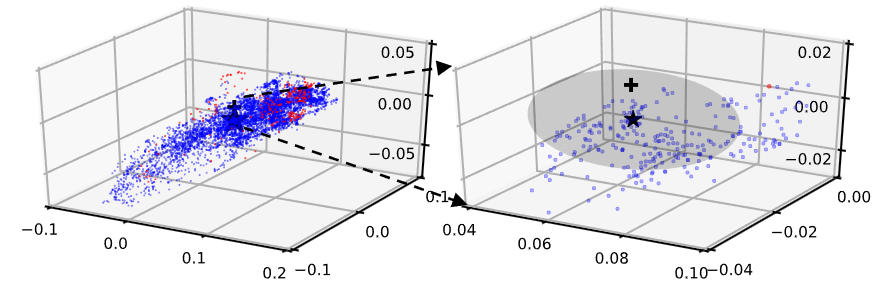
- 모델이 정상 데이터의 패턴을 포착하기 위해 z-space 표현을 학습
- 정상(파란색) 및 이상(붉은색) 샘플들이 z-space에서 서로 많이 겹쳐 나타남 > 이상 데이터가 들어와도 z-space는 이를 정상 패턴 영역에 가깝게 매핑하려는 경향을 보임
- 오른쪽처럼 원래 정상인 데이터()를 인위적으로 이상하게 만들더라도, 그 이상 데이터의 z-space 표현은 원래 정상 데이터의 z-space 표현과 매우 가까움
- 이상 데이터가 입력되면, z-space는 정상 패턴으로 압축되고, 이 정상 패턴으로 원래의 이상 데이터를 제대로 재구성하기 어렵게 됨 > 큰 재구성 오류
6.3 Lessons Learned
- 확률론적 딥 베이시안 모델과 결정론적 RNN 모델의 결합 필요성
- 확률 변수(Stochastic Variables) 연결의 중요성
- Z-공간에서 비-가우시안 분포 가정의 필요성
- 재구성(Reconstruction) 기반 모델의 강건성
- 견고한 잠재 표현(Latent Representations)의 중요성
- 이상 현상 해석(Anomaly Interpretation)의 가능성
