Learning to Prompt for Vision-Language Models
Kaiyang Zhou · Jingkang Yang · Chen Change Loy · Ziwei Liu
International Journal of Computer Vision (IJCV), 2022
Abstract
-
CLIP 같은 대형 vision-language 모델은 이미지 & 텍스트 함께 학습
→ 다양한 작업에 전이학습(transfer learning)으로 활용됨.
→제로샷 학습(zero-shot learning) 가능. -
이런 모델을 실제로 사용하려면 "프롬프트 엔지니어링(prompt engineering)" 필요.
→ 즉, 어떤 단어를 써서 분류할지를 사람이 직접 고민해서 문장(prompt)을 만들어야 함.
→ 시간 오래 걸림. 전문가 필요. -
본 논문: CoOp (Context Optimization) 방법 제안
→ 프롬프트 문장의 "context words"를 학습 가능한 벡터로 바꾸자
→ 모델(CLIP)은 그대로 두고, 문장 속 단어 중 일부만 학습 -
두 가지 방법:
1) 통합 context (모든 클래스에 같은 context 사용)
2) 클래스별 context (클래스마다 다른 context 사용)
1. Introduction
CLIP 이전 visual recognition system
- 지금까지 visual recognition system은 vision 모델을 정해진 범주의 라벨(discrete labels)을 예측하도록 학습
- 클래스 이름은 텍스트("goldfish", "toilet paper") 형태로 존재
- 실제 학습에선 단순 숫자(label)로 바꿈 → 단어 의미(semantics) 활용 못함
- 새로운 데이터셋은 학습 다시해야함
CLIP, ALIGN
- vision-language pre-training. visual representation learning의 대안으로 떠오름
- 이미지와 텍스트를 같은 feature space에 정렬 시키는게 목적
→ 이미지, 텍스트 각각을 별도 인코더를 사용하여 인코딩 한 뒤, contrastive loss을 최소화
→ 이미지-텍스트 짝이 맞으면 가깝게 - "고양이", "강아지"라는 라벨을 숫자로 바꾸지 않고, 직접 문장으로 써주면 그게 분류 기준이 됨.
→ 프롬프트만 바꿔도 다양한 작업에 적용 가능 - 프롬프트가 성능에 큰 영향 미침.
→ but 프롬프트 튜닝은
1) 시간이 많이 듦 (단어, 문장 수동으로 조정해야함)
2) 작은 단어 차이(앞에 a 붙이는거)로도 정확도 크게 다름
 3) 특정 작업에 따라 맞춤 프롬프트 필요 (ex. flower dataset은 flower라는 단어 포함되어야 성능 향상)
3) 특정 작업에 따라 맞춤 프롬프트 필요 (ex. flower dataset은 flower라는 단어 포함되어야 성능 향상)
→ 이렇게 열심히 튜닝해도 최적이라는 보장이 없음
CoOp: Context Optimization
: (pretrained vision-language model의) 프롬프트 엔지니어링 자동화를 위한 방법 제안
프롬프트(prompt): 이미지 분류할 때 클래스 이름을 포함한 문장 ex) A photo of a cat
- CLIP의 텍스트 인코더는 "a photo of a {class}"와 같은 프롬프트를 이용하여, class에 다양한 class를 대입하고, 만들어진 텍스트 벡터들과 이미지 벡터를 비교해서 가장 유사한 텍스트가 어떤 것인지 판단
- CoOp은 "a photo of a" 같은 문장을 짜지 않고, 해당 부분을 학습 가능한 벡터로 대체하여 자동으로 최적화
학습 방식:
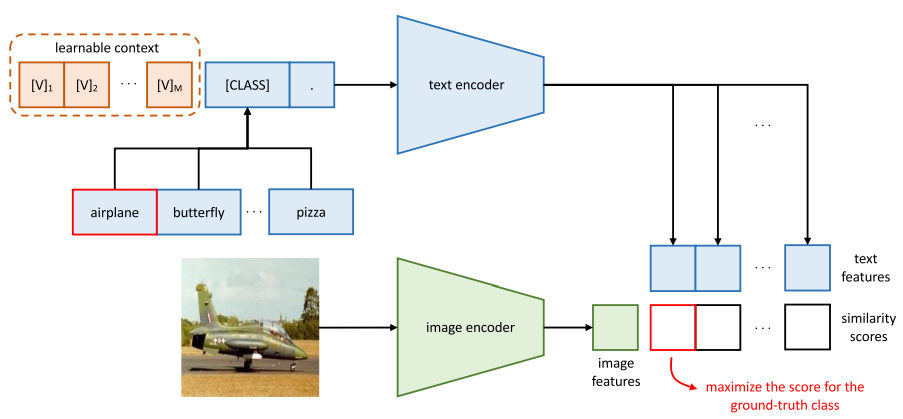
1) 이미지 인코딩
입력 이미지 → CLIP의 image encoder → image feature 벡터 생성
2) 클래스별 텍스트 프롬프트 인코딩
- 다운스트림 데이터셋 클래스 개수 총 k개라 가정.
- k개 클래스 각각에 대해 프롬프트 생성:
[V1][V2][V3][CLASS_NAME] - 각 프롬프트 → CLIP의 text encoder → text feature k개 생성
3) 이미지 벡터 vs 텍스트 벡터 간 similarity 계산: cosine similarity 사용 → k개의 점수(score) 생성
4) softmax + cross-entropy loss 계산:
이미지에 해당하는 정답 클래스 라벨과 모든 클래스에 대한 점수로 계산된 softmax 분포를 비교하여 cross-entropy loss 계산
Contributions
1) 프롬프트 엔지니어링의 한계 지적
최신 비전-언어 모델을 downstream에 적용할 때
수작업 프롬프트 작성이 큰 장애물이라는 점을 처음으로 체계적으로 분석
2) CoOp 제안
프롬프트를 학습 가능한 벡터(context)로 자동 최적화하는 간단한 방법을 제안
3) 우수성 입증
기존 수작업 프롬프트와 linear probe 모델보다 성능과 도메인 일반화 측면 모두에서 더 뛰어나다는 걸 실험으로 입증
2. Related Work
2.1 Vision-Language Models
-
CLIP, ALIGN 등은 다양한 분류 작업에 zero-shot 전이(transfer)가 가능
→ 프롬프트 기반 접근 방식(prompting) 덕분 -
이미지와 텍스트를 같은 공간에 매핑하려는 시도는 10년 전부터 존재
- 단어 벡터(word2vec, GloVe)로 텍스트 표현
- TF-IDF 같은 수작업 피처 사용
- 이미지-텍스트 매칭을 metric learning이나 captioning으로 접근
-
기존 연구들은 비전-언어 모델을 만드는 데 집중
-
CoOp은 이미 잘 훈련된 모델(CLIP 등)을 실제 분류 작업에 더 쉽게, 효율적으로 적용(deployment)하는 방법을 다룸
→ “적응(adaptation)” 문제에 집중
2.2 Prompt Learning in NLP
Knowledge Probing
: 빈칸 채우기(cloze test) 형태의 문장을 통해 사전 학습된 언어 모델이 어떤 지식을 가지고 있는지를 확인하는 방법
ex) "Paris is the capital of ___." → 모델이 "France"라고 예측하는지 확인.
Discrete Prompt vs. Continuous Prompt:
Discrete: 단어 수준 프롬프트, 해석 용이.
Continuous: 임베딩 공간의 벡터 최적화 → 더 유연하지만 해석 어려움.
NLP에서 널리 연구된 프롬프트 학습을 vision-language 모델에 처음 도입.
Transfer learning 향상, domain shift에 대한 강건성 확보.
3. Methodology
3.1 Vision-Language Pre-Training
Model
CLIP 모델 구성:
- 이미지 인코더: ResNet-50 또는 ViT. 고차원 이미지를 저차원 임베딩 공간으로 매핑
- 텍스트 인코더: Transformer 기반. 자연어로부터 텍스트 표현 벡터를 생성.
텍스트 처리 과정:
- 입력: 자연어 문장 (예: "a photo of a dog")
- BPE → 토큰화: 고유 숫자 ID로 변환 (vocab size: 49,152)
- SOS, EOS로 감싸고 길이 77로 고정
- 각 토큰 → 512차원 임베딩
- Transformer 통과
- [EOS] 위치의 출력 벡터 → 정규화(layer normalization) → 선형 투사(linear projection) → 최종 임베딩 생성
Training
- 학습 목적: 이미지와 텍스트 임베딩 공간을 정렬
- loss function: Contrastive loss
- 정답 쌍: 코사인 유사도 최대화
- 오답 쌍: 코사인 유사도 최소화
- 데이터셋 규모: 4억 개의 이미지-텍스트 쌍
- 전이 성능(다운스트림 task에 transfer) 향상을 위한 다양한 시각 개념 학습이 목적
Zero-Shot Inference
Zero-Shot 방식 작동 원리
- 이미지 인코더 입력: 이미지 x
- 이미지 인코더 출력: 이미지 벡터 f
- 텍스트 인코더 입력: "a photo of a cat", "a photo of a dog", ... 등 K개의 클래스 텍스트 프롬프트
- 텍스트 인코더 출력: 각 클래스에 대한 벡터 {w₁, ..., wₖ}
- 각 클래스에 대한 확률:
- τ(타우)는 CLIP이 학습한 온도 조절 파라미터(temperature parameter)
- 코사인 유사도 기반 softmax를 통해 예측 클래스 결정
장점
- 기존 분류기는 클래스 수가 고정된 closed-set 구조
- CLIP은 텍스트 프롬프트만 있으면 미학습 클래스도 분류 가능 (open-set recognition)
- 전이 학습 성능이 뛰어나고 의미 공간이 확장됨
3.2 Context Optimization
1. Unified Context
: 모든 클래스가 동일한 context(token sequence)
1) 텍스트 인코더 g(·)에 입력되는 프롬프트(t):
2) 프롬프트 t를 텍스트 인코더 g(·)에 통과시키면, [EOS] 위치에서 시각 개념을 표현하는 임베딩 벡터를 얻는다.
3) 예측 확률:
4) 각 프롬프트 tᵢ에서 [CLASS]는 i번째 클래스 이름의 임베딩 벡터로 대체됨
ex) "cat" → BPE → [‘c’, ‘at’] → 각각 512차원의 벡터로 변환 → [CLASS] 위치에 삽입됨
2. Class-specific Context
: 클래스마다 독립적인 컨텍스트 벡터 사용
클래스 i의 프롬프트: [V]ᵢ₁ [V]ᵢ₂ ... [V]ᵢₘ [CLASSᵢ]
클래스 j의 프롬프트: [V]ⱼ₁ [V]ⱼ₂ ... [V]ⱼₘ [CLASSⱼ]
→ i ≠ j이면 컨텍스트 [V]들도 전혀 다르게 학습된 값
세밀한 분류(fine-grained classification) 작업에서 유용
4. Experiments
4.1 Few-Shot Learning
Baseline Methods
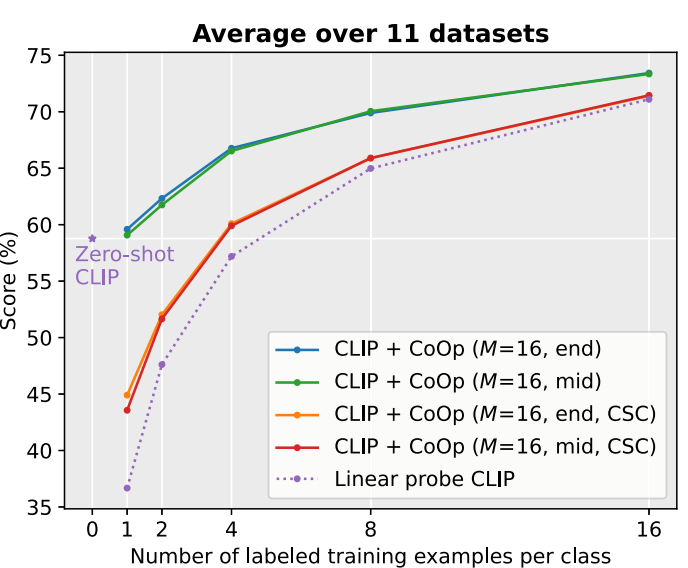
- [CLASS] 위치는 끝이나 중간이나 성능 거의 동일
- 평균적으로 CoOp은 2-shot만으로도 zero-shot CLIP보다 우수한 성능 달성
- 16-shot 사용 시, 약 15% 성능 향상
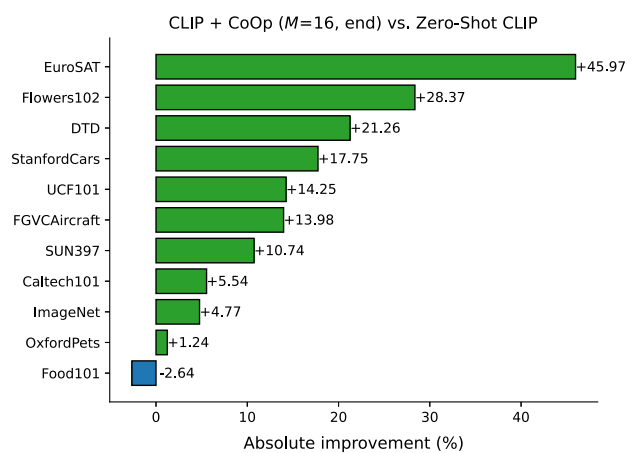
- 특수 과제(EuroSAT, DTD)에서 큰 향상
- 세밀 분류(Flowers102, StanfordCars, FGVCAircraft)에서도 안정적 향상
- 장면/행동 인식(SUN397, UCF101)에서도 향상
- OxfordPets, Food101: 작은 향상 → 과적합 가능성 의심
Comparison with Linear Probe CLIP
- CoOp는 적은 데이터에서도 강력한 성능
- Linear probe는 사전학습된 CLIP 임베딩이 강력하기 때문에 꽤 좋은 baseline이지만,
- 적은 shot 수에서 성능이 낮음
- 데이터가 많아질수록 CoOp에 밀림
- 특히 CSC(CoOp의 클래스별 컨텍스트 버전)는 미세 분류와 특수 과제에서 linear probe를 확실히 능가함.
- 도메인 일반화 실험에서도 CoOp가 훨씬 뛰어남 → 진정한 의미의 범용 few-shot 학습자
Unified vs Class-Specific Context
Unified Context
- 파라미터 수가 적고 일반화 성능이 높음
- 특히 데이터가 적을 때 효과적
CSC (Class-Specific Context)
- 클래스별로 더 정교한 표현 가능
- fine-grained, 특수 과제, 충분한 샷 수 (16+)일 때 더 유리
4.2 Domain Generalization
- CoOp은 특정한 데이터 분포에서 학습해야하기 때문에, 보지 못한 도메인에 대해 일반화하기 어려운, 허위 상관(spurious correlation)을 학습할 위험이 있음.
- Zero-shot CLIP은 특정 분포에 얽매이지 않음. 분포 변화(distribution shift)에 대해 강한 강건성(robustness)을 보여줌.
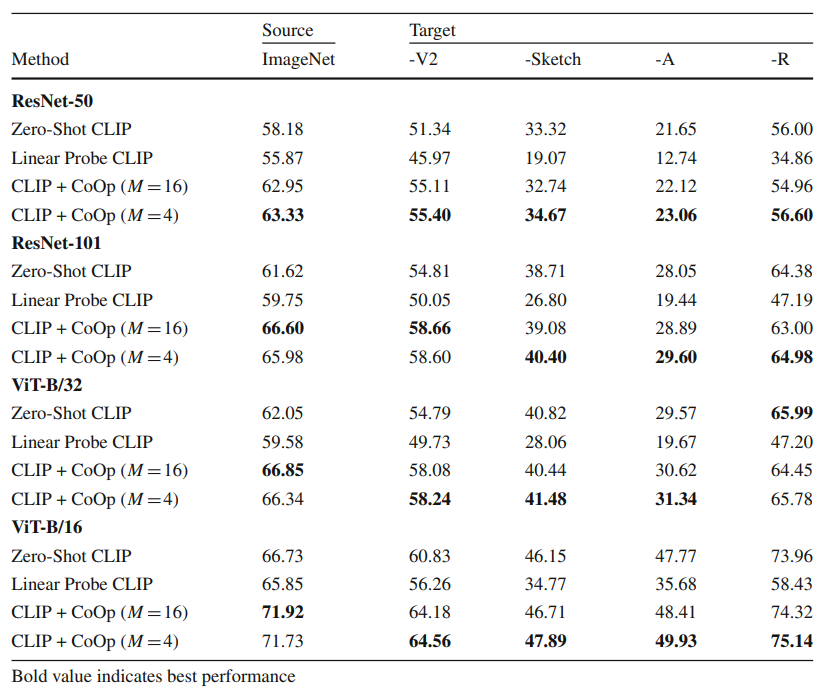
- CoOp은 CLIP보다 더 강한 도메인 일반화 성능을 보임
- 적은 컨텍스트 토큰 수가 오히려 더 강건함
- Linear Probe는 성능이 급격히 떨어지며 일반화에 약함
CoOp의 학습된 프롬프트는 단순히 소스 도메인에 특화된 것이 아니라 다양한 도메인에도 잘 전이됨!
4.3 Further Analysis
1. Context Length
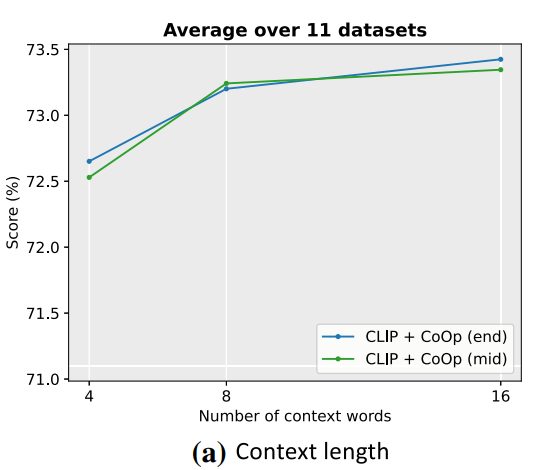
- 짧을수록 도메인 일반화에 유리
- 길수록 성능 향상
→ 성능 vs 일반화 사이에서 균형 필요
2. Vision Backbones
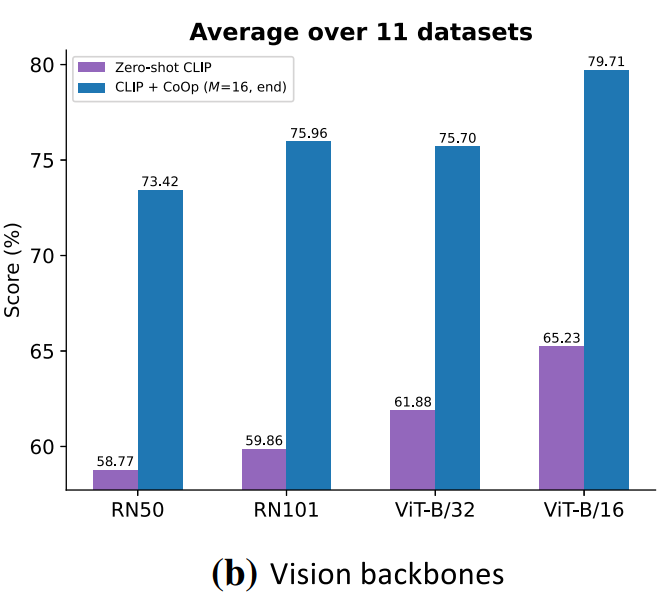
- Backbone이 더 좋을수록 성능 향상
- CoOp vs hand-crafted prompt(zero-shot CLIP) 간의 격차는 모든 백본에서 유의미하게 존재
3. Comparison with Prompt Ensembling
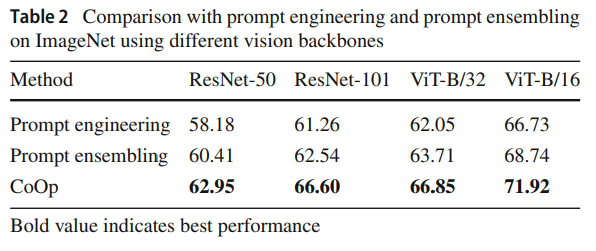
- zero-shot 앙상블보다 CoOp가 우수함
→ 미래 연구에서는 CoOp에 앙상블 아이디어 결합 가능성
4. Comparison with Other Fine-tuning Methods
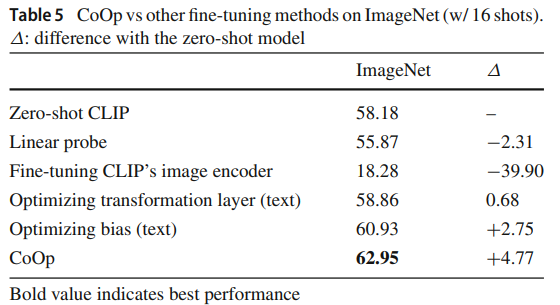
- 텍스트 인코더로의 gradient 전달이 CoOp 성능의 핵심
5. Initialization

- 초기화는 거의 영향 없음, 랜덤으로도 충분
6. Interpreting the Learned Prompts
: 의미 해석 가능성
- 컨텍스트 벡터는 연속 공간에서 최적화되기 때문에 해석이 어려움
- 대신, 벡터와 유클리디안 거리가 가장 가까운 단어를 사전에서 검색
→ 유사 단어 기반 해석은 부정확할 수 있으며, 명확한 해석은 어렵다
5. Conclusion, Limitations and Future Work
Conclusion
-
대규모 사전학습된 vision-language 모델들은 다양한 다운스트림 작업에서 강력한 성능을 보여주고 있음
-
이러한 모델들은 "중요하지만 아직 완전하지 않은" 특성을 가진 비전 파운데이션 모델로 간주
-
다운스트림 성능과 효율을 높이기 위해 자동화된 방식으로 적응(adaptation)이 필요
-
본 연구는 CLIP과 같은 모델이 프롬프트 학습을 통해 데이터 효율적인 학습자로 바뀔 수 있음을 시사
-
또한 학습 기반 접근임에도 불구하고, CoOp은 수작업 프롬프트보다 도메인 일반화 성능이 훨씬 뛰어나다는 것을 보여줌
→ 대형 비전 모델에 프롬프트 학습이 효과적일 수 있다는 강력한 근거 -
프롬프트 학습을 통해 대형 비전 모델을 적응시키는 최초의 종합적 연구라는 점에서 의의
Limitations
- 다른 NLP 프롬프트 학습 방식과 마찬가지로 결과 해석이 어려움
- 노이즈 라벨에 민감함 (Food101에서의 약한 성능)
Future Work
- CoOp의 구조가 단순하여 향후 확장이 용이
ex) 데이터셋 간 전이 학습(cross-dataset transfer), 테스트 시점 적응(test-time adaptation) - 초대형 비전 모델을 위한 보다 일반적인 적응 방법을 탐구
- CoOp은 파운데이션 모델의 효율적 적응에 대한 후속 연구의 기반
