Conditional Prompt Learning for Vision-Language Models
Kehan Chen · Xiaokang Chen · Boxin Wang · Lei Zhang · Yingwei Li · Qi Zhao · Jiashi Feng
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract
- CLIP과 같은 강력한 사전학습 vision-language 모델의 등장에 따라, 이러한 모델을 다운스트림 데이터셋에 적응시키는 방법을 연구하는 것이 중요해짐
- 최근 제안된 Context Optimization (CoOp) 기법은 NLP에서 유행 중인 프롬프트 학습(prompt learning) 개념을 비전 분야에 도입하여, 사전학습된 vision-language 모델을 적응시키는 방식
- CoOp은 프롬프트 내 컨텍스트 단어들을 학습 가능한 벡터로 바꾸고, 소수의 라벨된 이미지로도 수작업 프롬프트보다 뛰어난 성능을 보임
- 그러나 CoOp은 훈련 클래스에 과적합되어, 같은 데이터셋 내의 보지 못한 클래스(unseen classes)에는 일반화되지 않는 문제가 있음
- CoOp을 확장한 Conditional Context Optimization (CoCoOp)을 제안하며, 각 이미지에 대해 조건부 입력 벡터(token)를 생성하는 경량 신경망을 도입함
- CoCoOp의 동적 프롬프트는 입력에 따라 적응되므로, 클래스 변화(class shift)에 덜 민감함
- CoCoOp은 unseen 클래스와 다른 데이터셋에서도 더 뛰어난 성능을 보이며, 도메인 일반화 성능도 우수함
1. Introduction
CLIP, ALIGN
: 대규모 Vision-Language Pretraining 모델
- zero-shot image recognition에서 뛰어난 성과
- 기존의 Supervised Learning은 고정된 클래스(Label)만 다루는 closed-set > 새로운 클래스 확장 불가
- 자연어 기반 프롬프트(prompt)를 통해 open-set 인식이 가능
기존 한계:
- 모델 규모가 커짐. 전체 파인튜닝 불가능
→ 프롬프트 튜닝(prompt tuning) : 프롬프트에 task-specific 문맥(context)을 삽입하는 방식. - 이를 자동화한 방식이 CoOp (Context Optimization): 프롬프트 문맥을 학습 가능한 벡터로 바꿔 소수 샘플로 학습 가능.
→ 훈련 클래스에 과적합(overfitting) → Unseen 클래스에 일반화 실패
CoOp 문제점
- 학습된 context 벡터를 고정(static)시킴 → 새로운 클래스에 적응 불가
- 실험 결과: base class에선 잘 작동하지만 unseen class에서는 성능 급감
CoCoOp : Conditional Prompt Learning
- 입력 이미지마다 동적으로 조건부 프롬프트(token)을 생성 → 인스턴스마다 최적화된 문맥.
- CoOp 구조에 가벼운 신경망을 추가하여 이미지별 조건부 토큰 생성.
2. Related Work
Vision-Language Models
- 현대 모델(CLIP)은 이미지와 텍스트를 위한 두 인코더를 함께 학습, 대형 신경망 기반.
- Transformer 아키텍처
- Contrastive learning 방식
- 웹 기반 초대규모 데이터셋
- CLIP: 이미지-텍스트 쌍을 contrastive loss로 학습 → zero-shot recognition 성능 탁월. 사전학습(pretraining)에 초점, downstream 적응은 별도 과제
- CoCoOp : CLIP 같은 거대 사전학습 모델을 효율적으로 downstream task에 적응시키는 솔루션을 목표로 함.
Prompt Learning
- 원래 자연어처리(NLP)에서 출발한 개념.
사전학습 언어 모델을 일종의 지식베이스처럼 활용하여, 다운스트림 작업에 필요한 정보를 끌어냄. - 수동 설계는 비효율적 → 자동화 프롬프트 학습 연구 시작
- CoOp: 프롬프트를 continuous vector로 학습하여 downstream task에 적용
- CoCoOp: CoOp의 일반화 한계 문제를 해결하기 위해 제안 입력 → 이미지에 따라 동적으로 프롬프트를 조정
Zero-Shot Learning (ZSL)
- ZSL(Zero-Shot Learning)
- base class만 학습하고 novel class를 인식하는 목표를 가짐
- 학습 클래스에 편향되는 seen-class bias 문제가 있음
- 보통 속성(attribute)이나 단어 임베딩(word embedding) 기반 semantic space를 학습함
- CoCoOp은 prompting 기반으로 작동하며, Vision-Language 모델 적응이라는 새로운 문제를 다룸
→ ZSL과 유사한 목표지만, 기술적 접근은 완전히 다름
3. Methodology
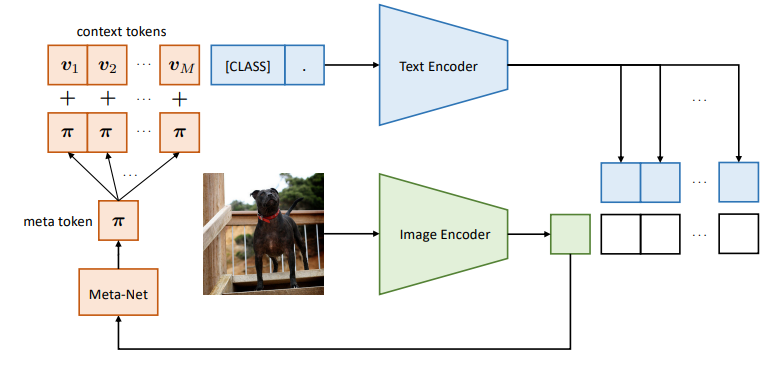
문제 인식: CoOp의 한계
- CoOp은 소수의 labeled 이미지로 context 벡터를 학습할 수 있는 효율적인 방법임
- 하지만 학습된 context는 고정(static)되어 있어, unseen 클래스에 일반화되지 못하고 과적합(overfitting)되는 문제가 있음
핵심 아이디어: 입력-조건부 프롬프트
- 입력 이미지 x에 따라 context를 조정하면, 클래스에 덜 의존하고 task-level 일반화 가능
- 즉, instance-level prompting은 base class에 고정된 벡터보다 더 유연하고 일반화에 강함
CoCoOp 구조
1. 기본 구조
-
기존 CoOp은 M개의 context vector: v1, v2, ..., vM 을 사용함
-
CoCoOp은 여기에 입력 이미지 x에 따라 조정되는 조건부 벡터 π를 더함
-
각 context token은 다음과 같이 계산됨:
-
는 이미지 특성을 입력받아 조건부 벡터 π를 생성하는 Meta-Net임
-
Meta-Net: 입력 이미지에 따라 조건부 벡터(π)를 생성하는 작은 신경망. 이미지 특성에 맞는 맞춤형 context 조정값을 만들어주는 역할
2. 최종 프롬프트 구성
- 클래스 i에 대한 최종 프롬프트는 다음과 같이 구성됨:
- 여기서 는 클래스 이름(예: "a dog")의 텍스트 임베딩 벡터임
3. 예측 방식 (softmax over similarity)
- 최종 출력 확률은 아래와 같은 softmax 방식으로 계산됨:sim: cosine similarity
g: 텍스트 인코더
τ: temperature scaling 파라미터
4. Experiments
목적
1. Base → New Class 일반화
동일 데이터셋 내에서 훈련된 base class → unseen class로 일반화
2. Cross-Dataset Transfer
한 데이터셋에서 학습 → 다른 데이터셋에서 테스트
3. Domain Generalization
하나의 도메인에서 학습 → 도메인 분포가 다른 다른 데이터셋에서 테스트
4.1. Generalization From Base to New Classes
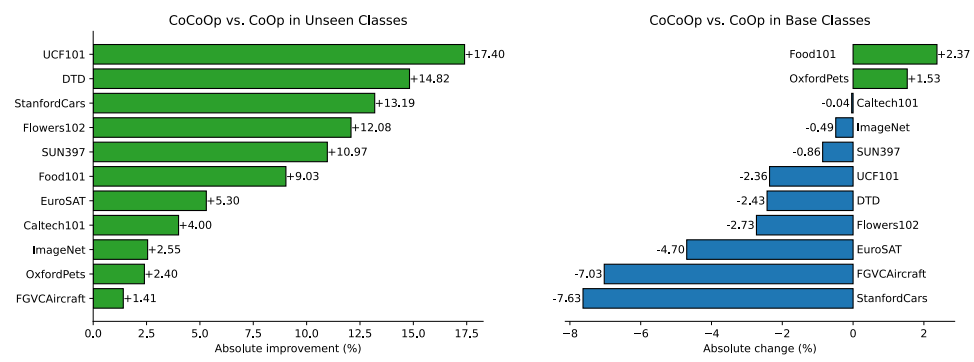
- CoOp은 base class에서는 우수한 성능을 보이나, new class에서는 성능 급감
→ base class에서 얻은 이점이 new class 실패로 상쇄됨>> 일반화 문제 명확히 드러남 - CoCoOp는 Generalization Gap 대폭 감소
- base class 성능에서 약간의 감소가 있음
- unseen class에서의 큰 이득이 이를 상쇄하거나 초과함
CLIP은 수작업 프롬프트로 테스트 클래스까지 튜닝되었음에도 불구하고, CoCoOp이 더 나은 성능을 달성
4.2. Cross-Dataset Transfer
: CoCoOp이 단일 데이터셋 내부에서의 일반화를 넘어서, 다른 데이터셋으로 전이 가능한지 평가
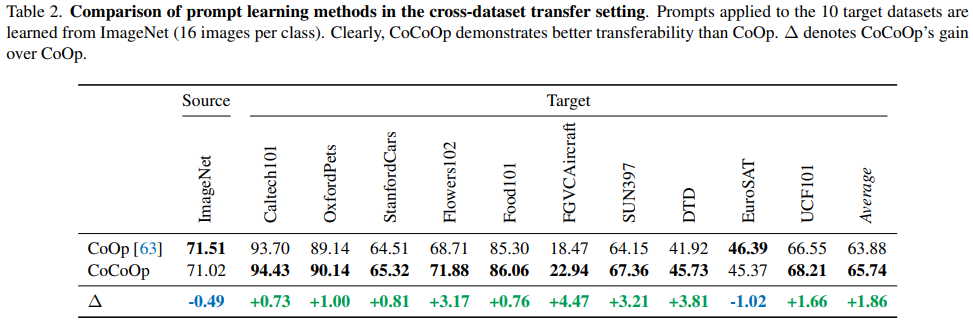
- CoCoOp이 대부분의 데이터셋에서 CoOp을 명확히 능가
- 특히 전이 난이도가 높은 특수 데이터셋에서 차이가 큼:
- FGVCAircraft (비행기 세부 분류)
- DTD (텍스처 분류)
두 모델 모두 정확도는 낮지만, CoCoOp이 더 강한 전이력(transferability) 보임
→ 이는 instance-conditional design이 더 일반적인 특징을 잘 포착하기 때문
4.3. Domain Generalization
: Distribution shift(도메인 이동) 상황에서 CoCoOp이 여전히 일반화 능력을 유지하는지 평가

- CoOp / CoCoOp 모두 CLIP보다 성능 우수
→ 학습된 프롬프트가 수작업 프롬프트보다 도메인 변화에 더 강함 - CoCoOp:
- ImageNetV2에서는 CoOp보다 약간 낮은 성능
- 다른 3개 도메인(Sketch, A, R)에서는 CoOp보다 우수한 성능
CoCoOp의 instance-conditional 프롬프트가 도메인 일반화에 더 강함을 입증
4.4. Further Analysis
1) Class-Incremental Test (클래스 확장 시나리오)
- 문제 설정:
기존 base class만 학습된 모델이, 이후 등장한 new class에 대해 zero-shot으로 인식해야 하는 시나리오
→ continual learning과 유사하지만, new class의 학습은 없음
- CoOp: CLIP과 성능 유사하지만 추가 학습 데이터가 필요하므로 비효율적
- CoCoOp: 두 모델보다 우수한 성능 → 실제 응용에 더 적합
2) Initialization (초기화 영향 실험)
- 비교 방식:
- Word embedding 기반 초기화
- Random 초기화
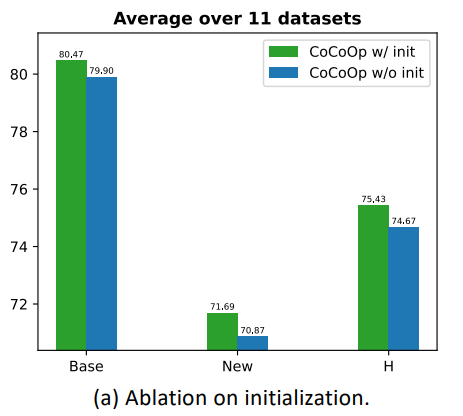
- 초기화를 잘하면 base와 new 클래스 모두에 이점 있음
- Dataset마다 편차는 있지만, 전반적 경향은 일관됨
3) Context Length (context token 수 영향)
- 설정: context token 개수를 4, 8, 16개로 변경하며 실험 (모두 random 초기화 사용)
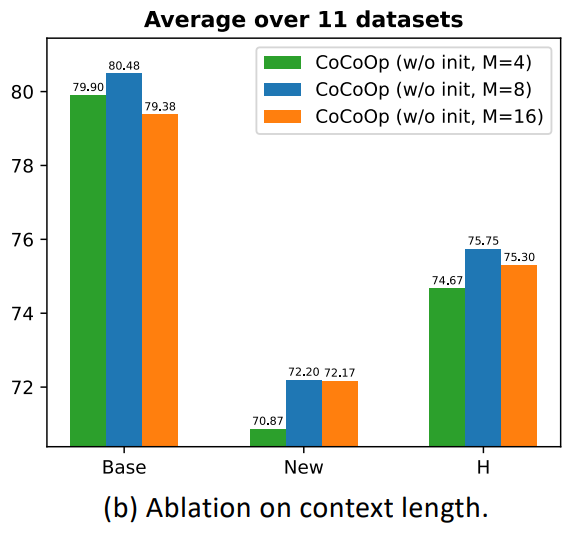
- Base class 성능 차이는 작음
- New class 성능은 길이가 길수록 확실히 좋아짐
- 8개를 word embedding으로 초기화하면 더 나은 결과 가능성 시사
4) CoCoOp vs Parameter-Increased CoOp
: CoCoOp이 잘 되는 이유가 Meta-Net 구조 때문인지, 아니면 단순히 파라미터가 많아졌기 때문인지?
- 검증 방법: Meta-Net 제거. 대신 CoOp의 context token 수를 증가시켜 CoCoOp과 파라미터 수를 맞춤
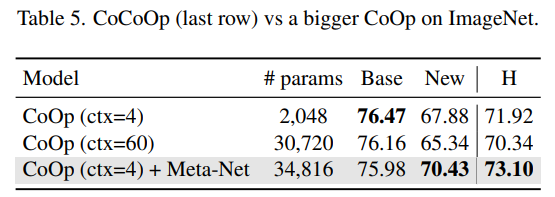
- 단순히 context token을 늘린 CoOp은 CoCoOp만큼 성능 향상 없음
→ CoCoOp의 성능 향상은 instance-conditional 구조 자체에서 기인한 것임을 확인
5. Limitations
1. 학습 비효율성
- CoCoOp은 학습이 느림. GPU 많이 차지
- 이미지별 조건부 프롬프트(instance-conditional prompts)를 생성하기 때문
→ 각 이미지마다 개별적으로 텍스트 인코더를 통과해야함
→ CoOp은 미니배치 전체가 한번만 통과해도 됨
2. 일반화 성능
- 11개 중 7개 데이터셋에서 CoCoOp의 unseen 클래스 성능이 CLIP보다 낮음
→ 수작업 프롬프트보다 항상 우월하지는 않음
6. Discussion and Conclusion
- Foundation model(CLIP 등)은 강력하지만, 학습 비용이 매우 크고 파라미터 수가 많아 적응이 어려움
- 본 연구는 parameter-efficient prompt learning(CoCoOp) 기반으로, 정적 프롬프트의 일반화 한계를 극복하고 다양한 문제 상황에서 강력한 성능을 보임
- base → new class 일반화
- cross-dataset 프롬프트 전이
- 도메인 일반화
- 향후 방향:
- 더 효율적인 조건부 프롬프트 학습 구현 → 학습 속도 개선 + 일반화 향상
- 대형 모델, 대규모 이미지, 이질적 데이터셋에도 조건부 프롬프트 확장 여부 탐색
