
🧹 Data Cleaning
- 좋은 데이터의 특징
- 유일성 : 중복 데이터 제거
- 통일성 : 이상치 제거, 정규화, 동일한 데이터 형식
- 완결성 : 결측치 제거
- 모델/데이터 분포/분석 목적에 따라 data cleaning을 하는 것이 좋음
import numpy as np
import pandas as pd
DATA_PATH = '../data/titanic/'
df = pd.read_csv(DATA_PATH + 'train.csv')
df.columns = [i.lower() for i in df.columns]
df.head()
x = df.drop('survived', axis=1)
y = df['survived']
SEED = 30
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=SEED)
x_train = x_train.reset_index(drop=True)
x_test = x_test.reset_index(drop=True)👯 중복 데이터
df.drop_duplicates(
subset=[중복값을 찾을 열],
keep=[first, last, False],
inplace, ignore_index
)🚮 필요없는 데이터
print('passengerid :', df['passengerid'].nunique())
print('df count :', len(df))passengerid : 891
df count : 891한 열의 값이 모두 고유할 경우 패턴을 찾기 어렵고 오히려 노이즈가 될 수도 있음
# 해당 열 삭제
df.drop('passengerid', axis=1, inplace=True)🈚 결측치
- 값이 없는 것 (NaN, null, undefined)
◽ 결측치 유형
- 완전 무작위 결측 (MCAR: Missing Completely At Random)
- 한 열의 결측치가 다른 열의 값들과 아무런 상관관계가 없는 경우
- 예) 이유없이 체중을 응답하지 않음
- 무작위 결측 (MAR: Missing At Random)
- 다른 특성의 값에 따라 결측치의 발생 확률이 계산되지만 상관관계는 알 수 없는 경우
- 예) 체중 응답이 누락된 것은 성별의 영향을 받음 (정확하게는 알 수 없음)
- 비무작위 결측 (NMAR: Not Missing At Random)
- 결측치에 상관관계가 있을 경우
- 예) 체중이 무거운 사람들은 체중에 잘 응답하지 않음
◽ 결측치 탐색
방법 1. df.info() 사용
df.info()
# 전체 : 668 entries
# age, cabin, embarked 열의 값의 합계는 668개가 되지 않음<class 'pandas.core.frame.DataFrame'>
RangeIndex: 668 entries, 0 to 667
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 passengerid 668 non-null int64
1 pclass 668 non-null int64
2 name 668 non-null object
3 sex 668 non-null object
4 age 537 non-null float64
5 sibsp 668 non-null int64
6 parch 668 non-null int64
7 ticket 668 non-null object
8 fare 668 non-null float64
9 cabin 146 non-null object
10 embarked 667 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 57.5+ KB방법 2. df.isnull(), df.sum() 사용
# 각 열의 결측치 수
df.isnull().sum().sort_values(ascending=False)passengerid 0
pclass 0
name 0
sex 0
age 131
sibsp 0
parch 0
ticket 0
fare 0
cabin 522
embarked 1
dtype: int64# 전체 결측치 수
df.isnull().sum().sum()654◽ 결측치 처리
- 제거
- 행/열을 아예 삭제하는 방법
- 가장 쉽고 단순함
- 데이터의 손실
- 치환
- 결측치를 적당한 방법으로 대체하는 방법
- 평균, 중앙값, 최빈값 등으로 치환 가능
하지만 이런 단순 대체 방법은 자료의 편향성을 높이고 상관관계를 왜곡시킬 가능성이 있음
- 모델 기반 처리
- 결측치를 예측하는 새로운 모델을 구성하는 방법
- 변수의 특성에 따라 KNN, PolyRegression 등이 있음
방법 1. df.dropna() 사용
df.dropna( axis=0/1 ): 행/열 삭제df.dropna( subset=[원하는 행] ): 원하는 행의 결측값이 있는 부분을 기준으로 행 삭제
방법 2. df.fillna() 사용
df[[컬럼명]].fillna(원하는 값): 원하는 값으로 채우기
방법 3. 모델 사용
-
SimpleImputer: 치환 방식from sklearn.impute import SimpleImputer # strategy = mean, median, most_frequent imputer = SimpleImputer(strategy="mean") x_train['age_mean'] = imputer.fit_transform(x_train[["age"]]) x_test['age_mean'] = imputer.transform(x_test[["age"]]) -
KNNImputer: 모델 기반 방식from sklearn.impute import KNNImputer imputer = KNNImputer(n_neighbors=5) x_train['age_knn'] = imputer.fit_transform(x_train[["age"]]) x_test['age_knn'] = imputer.transform(x_test[["age"]]) -
IterativeImputer: 모델 기반 방식from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer imputer = IterativeImputer(random_state=SEED) x_train['age_iter'] = imputer.fit_transform(x_train[["age"]]) x_test['age_iter'] = imputer.transform(x_test[["age"]])
🎭 비대칭 데이터
print('왜도 :', x_train['fare'].skew())
print('첨도 :', x_train['fare'].kurt())
sns.displot(x_train['fare'])왜도 : 4.601354309490882
첨도 : 30.359724282183777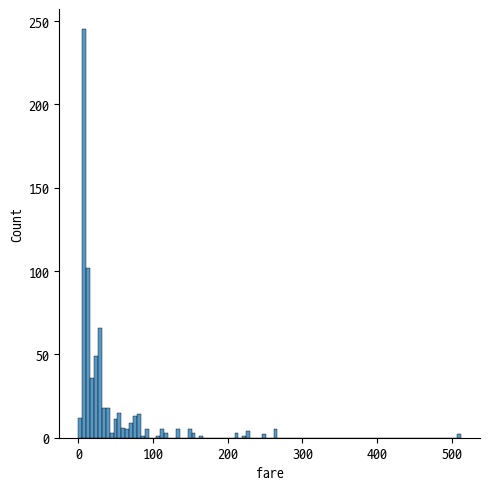
◽ 비대칭 데이터 처리
- 사용 : 큰 숫자를 같은 비율의 작은 숫자로 만듦
x_train['fare'] = x_train['fare'].map(lambda x: np.log(x) if x > 0 else 0)
print('왜도 :', x_train['fare'].skew())
print('첨도 :', x_train['fare'].kurt())
sns.displot(x_train['fare'])왜도 : 0.023966309664471202
첨도 : 0.10914875668767454
🙄 이상치
quantile_upper = x_train['age'].quantile([0.25, 0.75]).values[1]
quantile_lower = x_train['age'].quantile([0.25, 0.75]).values[0]
print(quantile_lower, quantile_upper)
IQR = quantile_upper - quantile_lower
upper_boundary = x_train['age'].median() + 1.5 * IQR
lower_boundary = x_train['age'].median() - 1.5 * IQR
print('lower boundary :', lower_boundary)
print('upper boundary :', upper_boundary)
sns.boxplot(y=x_train['age'])20.0 39.0
lower boundary : -0.5
upper boundary : 56.5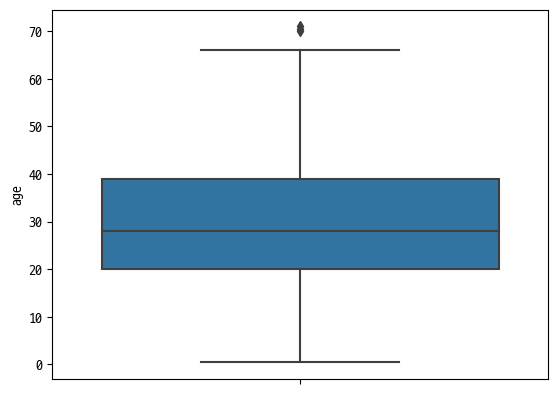
◽ 이상치 처리
x_train['age'] = x_train['age'].map(lambda x: upper_boundary if x > upper_boundary else x)
x_train['age'] = x_train['age'].map(lambda x: lower_boundary if x < lower_boundary else x)
sns.boxplot(y=x_train['age'])

울레일라