
✳️ 데이터 종류
- 스키마 : 데이터의 구조와 제약 조건에 대한 것들을 정의한 것
◽ 정형 데이터
- Structured Data
- 고정된 필드(스키마를 철저히 따른)에 저장된 데이터
- 예) 관계형 데이터베이스, 스프레드시트 등
◽ 반정형 데이터
- Semi-Structured Data
- 고정된 필드에 저장되어 있지는 않지만, 메타데이터나 스키마 등을 포함하는 데이터
- 예) XML, HTML, JSON 등
◽ 비정형 데이터
- Unstructured Data
- 고정된 필드에 저장되어 있지 않은 데이터
- 예) 텍스트, 이미지, 동영상, 음성
✳️ 데이터 유형
◽ 수치형 데이터 (Quantitive Data)
연속형 데이터
- Continuous Data
- 더 작은 단위로 쪼갤 수 있음
- 예) 강수량, 거리, 체중 등
이산형 데이터
- Discrete Data
- 수를 세는 것만 가능하고 더 쪼갤 수는 없음
- 예) 출산 횟수, 강아지 수 등
◽ 범주형 데이터 (Categorical Data)
순서형 데이터
- Ordinal Data
- 순서 관계가 있는 데이터
- 예) 별점, 과목 성정 등
명목형 데이터
- Nominal Data
- 순서 관계가 없는 데이터
- 예) 품종, 성별, 혈액형 등
🔎 EDA (Exploratory Data Analysis)
- 탐색적 데이터 분석
- 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미
- 크게 3가지 기술 필요
- 데이터의 각 행과 열의 의미를 이해하는 기술
- 결측치 처리 및 데이터필터링 기술
- 시각화 기술
🧐 데이터 분석 시 확인해야 하는 요인
◽ 상관계수 (correlation coefficient)
- 두 변수 사이의 상관관계의 정도를 나타내는 수치
- 상관계수 의 특징
- 음의 상관관계는 반비례, 양의 상관관계는 비례
- 0에 가까울수록 상관관계가 없음
- 큰 상관계수 값이 항상 두 변수의 인과관계를 나타내지는 않음
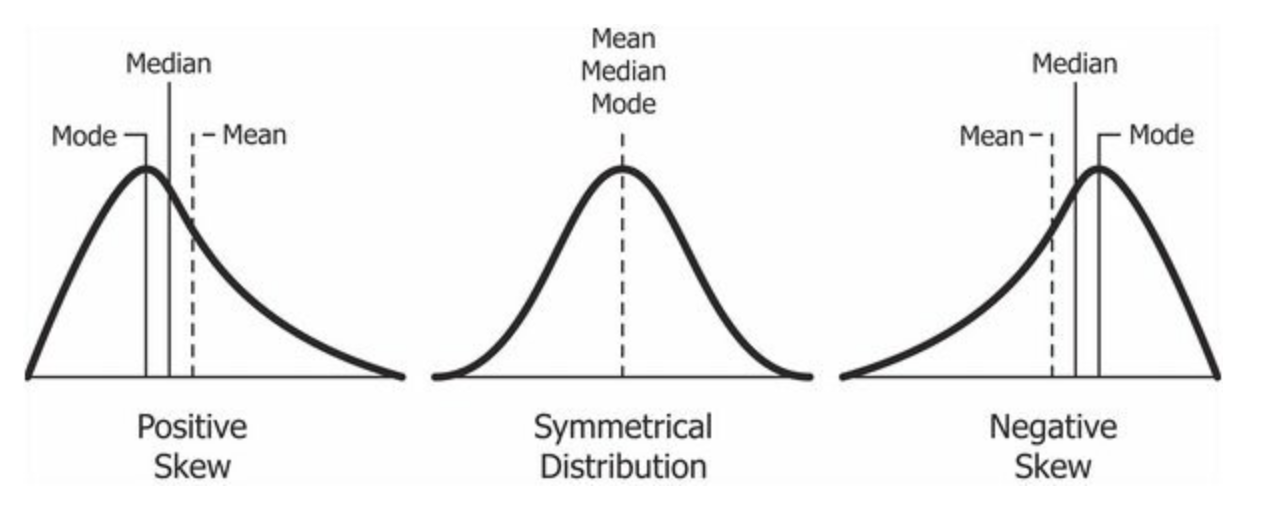
◽ 왜도 (skewness)
-
데이터 분포의 비대칭도를 나타내는 지표
-
왜도 s의 특징
│s│≤ 0.5 0.5 ≤ │s│ ≤ 1 │s│ ≤ 1 상당히 대칭적 적당히 치우침 상당히 치우침
- s : 분포가 왼쪽으로 치우침
- s : 분포가 오른쪽으로 치우침
◽ 첨도 (kurtosis)
-
확률 분포의 뾰족한 정도를 나타내는 지표
-
관측치들이 얼마나 집중적으로 중심에 몰려있는지 측정 시 사용
-
첨도 k의 특징
k < 3 k = 3 k > 3 platykurtic mesokurtic leptokurtic 데이터가 가벼움
이상치 부족정규분포와 유사한 첨도 데이터의 꼬리가 무거움
이상치가 많음
◽ 이상치 (outlier)
- 평균이나 표준편차에서 많이 벗어난 데이터
- 주로 박스플롯을 이용하여 확인
👩🏻💻 코드 예제
import numpy as np
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')- 데이터가 대략 어떻게 생겼는지 확인하는 작업 필요
df.head()df.info()df.describe()
◽ 수치형 데이터 분석
df_number = df.select_dtypes(include=np.number)
df_number.describe()| age | sibsp | survived | pclass | parch | fare | |
|---|---|---|---|---|---|---|
| count | 714.000000 | 891.000000 | 891.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 29.699118 | 0.523008 | 0.383838 | 2.308642 | 0.381594 | 32.204208 |
| std | 14.526497 | 1.102743 | 0.486592 | 0.836071 | 0.806057 | 49.693429 |
| min | 0.420000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 |
| 25% | 20.125000 | 0.000000 | 0.000000 | 2.000000 | 0.000000 | 7.910400 |
| 50% | 28.000000 | 0.000000 | 0.000000 | 3.000000 | 0.000000 | 14.454200 |
| 75% | 38.000000 | 1.000000 | 1.000000 | 3.000000 | 0.000000 | 31.000000 |
| max | 80.000000 | 8.000000 | 1.000000 | 3.000000 | 6.000000 | 512.329200 |
※ 소수점 뒷 부분이 다 0인 것들은 범주형인 것으로 의심할 필요가 있음
▶ 왜도, 첨도 확인
print('첨도 :', df_number['fare'].kurt())
print('왜도 :', df_number['fare'].skew())
df_number['fare'].plot.hist(bins=50) # pandas 자체 기능
# fare 데이터는 뾰족하고 치우쳐있음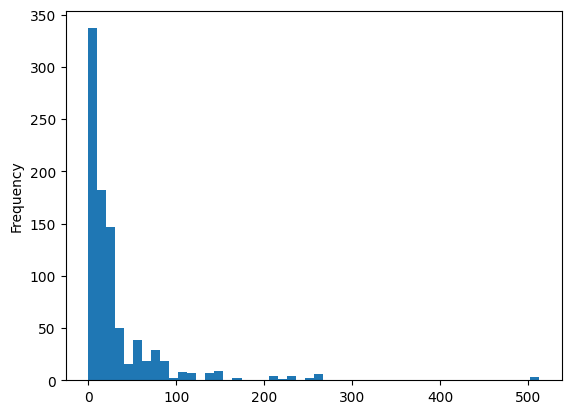
▶ 이상치 확인
sns.boxplot(x=df_number['survived'], y=df_number['age'])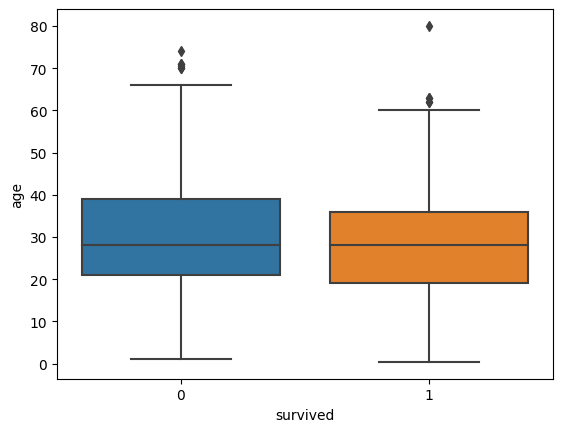
▶ 상관관계 확인
sns.heatmap(df_number.corr(), annot=True, linewidths=0.2, cmap='Reds')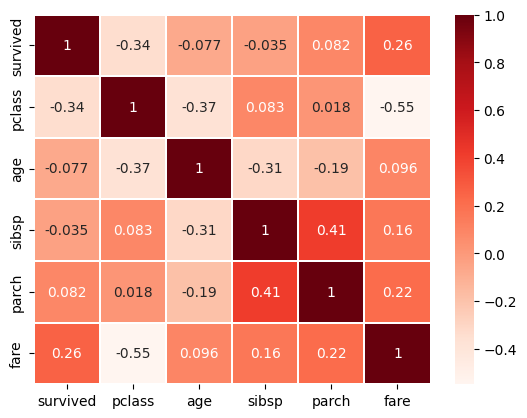
◽ 범주형 데이터 분석
df_object = df.select_dtypes(exclude=np.number)
# survived 추가
df_object = df_object.join(df['survived'])
# 데이터 타입 변형 (수치 → 범주)
df_object['survived'] = df_object['survived'].astype('category')
df_object.describe()| sex | embarked | class | who | adult_male | deck | embark_town | alive | alone | survived | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 891 | 889 | 891 | 891 | 891 | 203 | 889 | 891 | 891 | 891 |
| unique | 2 | 3 | 3 | 3 | 2 | 7 | 3 | 2 | 2 | 2 |
| top | male | S | Third | man | True | C | Southampton | no | True | 0 |
| freq | 577 | 644 | 491 | 537 | 537 | 59 | 644 | 549 | 537 | 549 |
교차분석
pd.crosstab(): 데이터 재구조화
pd.crosstab(df_object['sex'], df_object['survived'], margins=True)
# margins : 전체 통계 포함 여부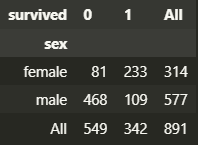
pd.crosstab(df_object['sex'], df_object['survived'], margins=True, normalize='all')
# normalize : 개수가 아닌 비율로 표시
pivot_table 분석

울레일라