
❗❗ 먼저 알아야 할 사항
- HTTP 메소드
- 브라우저가 서버에 데이터를 요청하는 방식
- GET 방식과 POST 방식이 있음
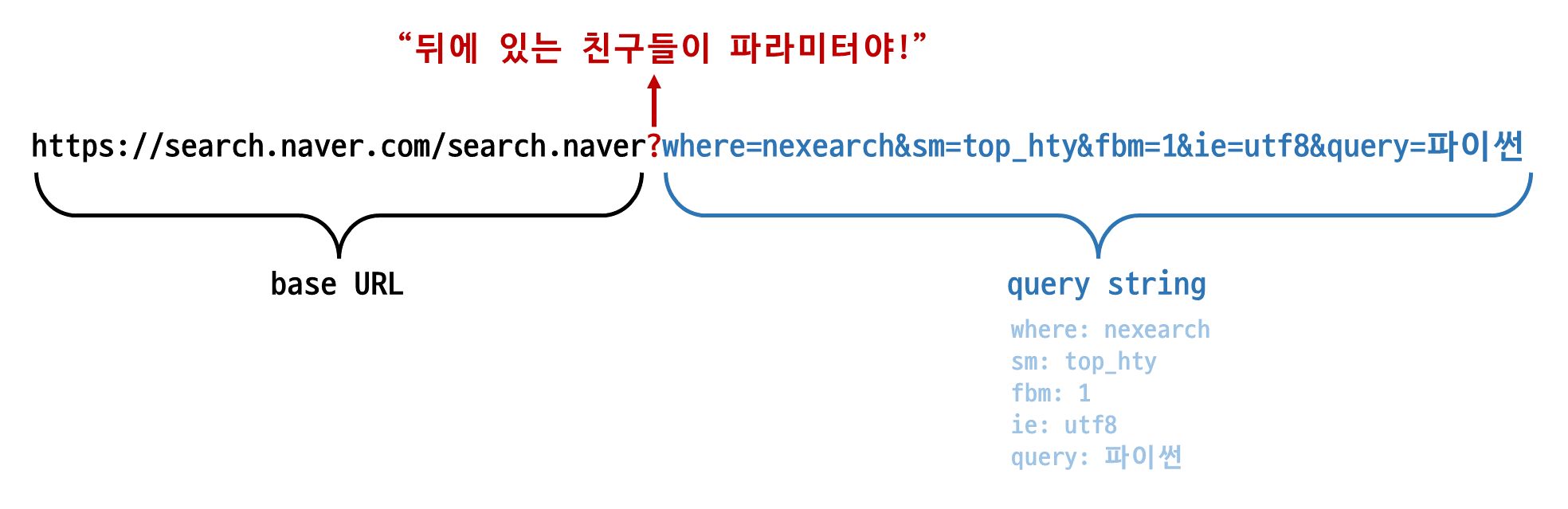
- GET 방식
- 요청 시 데이터를 body에 담지 않고 쿼리스트링을 통해 전송
- 길이 제한 있음
- 서버의 리소스에서 데이터를 요청할 때 사용
- POST 방식
- 데이터를 HTTP 메시지의 body에 담아서 전송
- 길이 제한 없음 → 대용량 데이터 전송 가능
- 서버의 리소스를 새로 생성하거나 업데이트할 때 사용
📜 GET 방식으로 크롤링
import requests
from bs4 import BeautifulSoup
url = '어디어디 링크'
response = requests.get(url)
soup = BeautifulSoup(response.text)
# findAll : 해당하는 모든 태그를 리스트 형식으로 반환
target = soup.findAll('div', {'class': 'first-button', 'custom': 'my-style'})
# find : 해당하는 첫 번째 태그를 반환
target = soup.find('div', {'class': 'first-button', 'custom': 'my-style'})
# select : 해당하는 모든 태그를 리스트 형식으로 반환
target = soup.select('div.first-button > span')
# select_one : 해당하는 첫 번째 태그를 반환
target = soup.select('div.first-button > span')find,findAll의 장점- 태그의 클래스, 아이디 외에도 특정 속성을 지정하여 태그를 찾을 수 있음
select_one,select의 장점- 특정 태그에 도달하기까지의 경로를 지정할 수 있음
- 간편한 방식으로 특정 클래스와 아이디를 갖는 태그를 지정할 수 있음
- ex ) HTML이 다음과 같을 때
<div class="one" id="first"> <img src="something.com"/> <div class="two" id="second"> <span>나 여기 있어!</span> </div> </div>span태그에 도달하기 위해서는 다음처럼 작성하면 됨soup.select('div.one#first > div.two#second > span')
📜 POST 방식으로 크롤링
- 사이트에서 개발자 도구 >
Network탭을 연 후에 동작을 취하기 - 자신이 원하는 액션에 해당하는 파일(주로 xhr 파일인 것 같음)을 우클릭하여 링크 복사
- 해당 파일의
Payload부분 확인 - 페이로드를 딕셔너리 형태로 변형하여 사용
import requests
from bs4 import BeautifulSoup
url = 'xhr 파일 링크'
payload = {
'딕셔너리 형태로 바꾼 페이로드': '얍'
}
response = requests.post(url, data=payload)
target = response.json() 또는 response.text?📜 동적 크롤링
import selenium
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
driver = Chrome()
url = '어디어디 링크'
driver.get(url)
target = driver.find_element(By.CSS_SELECTOR, '원하는 태그의 CSS selector 복사')
# 가능한 동작
target.click() # 클릭
target.send_keys() # 입력값
html = driver.page_source📜 URL 구문 분석
scheme://netloc/path;parameters?query#fragmenturllib.parse.urlparse: URL을 6개의 구성 요소로 구문 분석하여, 6개 항목 네임드 튜플을 반환
from urllib import parse
url = '어디어디 링크'
result = parse.urlparse(url)
# url의 매개변수 부분을 반환
query = result.query
# url의 매개변수 부분을 딕셔너리 형태로 변환
query_dict = parse.parse_qs(query)
'''
{'serviceKey': ['someKey'],
'schDate': ['someDate']}
'''
# query_dict의 대괄호까지 인코딩 (굳이 사용하지 않는 방식)
parse.urlencode(query_dict)
'''
'serviceKey=%5B%27someKey%27%5D&schDate=%5B%27someDate%27%5D'
'''
# 대괄호 제외하고 인코딩
parse.urlencode(query_dict, doseq=True)
'''
'serviceKey=someKey&schDate=someDate'
'''📜 XML 파싱
import requests
import xml.etree.ElementTree as ET
url = '어디어디 링크'
response = requests.get(url)
root = ET.fromstring(response.text) # 문자열 to XML
tags = root.iter(tag='태그명') # '태그명'의 태그 모음을 loop을 통해 반환
for tag in tags: # 객체 자체
for info in item: # 객체 안의 정보
print(info.text)
울레일라