.png)
CS231n 3강

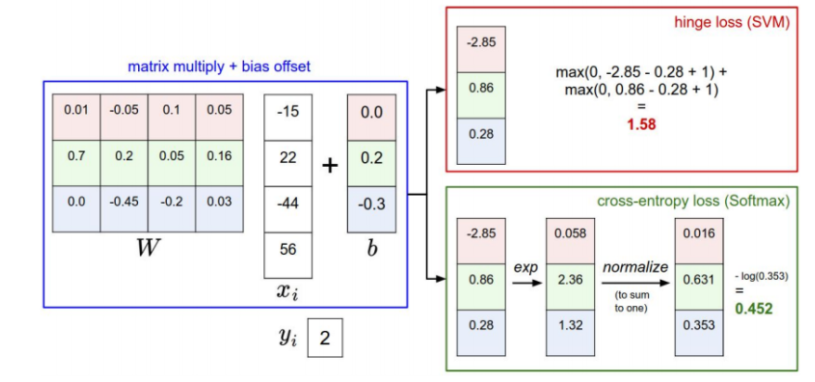
앞서 우리는 W를 임의로 정하고 score를 구했다.
고양이의 이미지를 줬을때 각 클래스별 score를 보자.
뭔가 이상하지 않는가? 개의 점수가 더 높다!!우리는 W를 수정해야할 것 같다.
이때, W가 잘 설정됐는지 안됐는지는 Loss Fuction으로 알 수 있다.
Loss Function
손실함수는 여러 종류가 있다.
1. Multiclass SVM loss
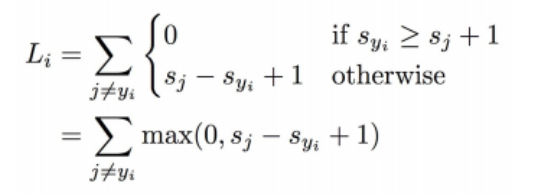
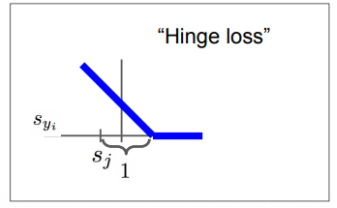
- sj : 오답 카테고리의 스코어
(hinge loss를 그릴때, sj는 오답 카테고리 중 가장 높은 스코어로 고른다.) - syi : 정답 카테고리의 스코어
sj에서 marjin을 1만큼 두고 그 이상의 스코어를 얻으면 손실은 0이다.
하지만 그 이하의 스코어를 얻으면 loss가 발생한다고 보면 된다.
<예시>

세개의 클래스별 스코어를 가지고 SVM loss를 계산해보자
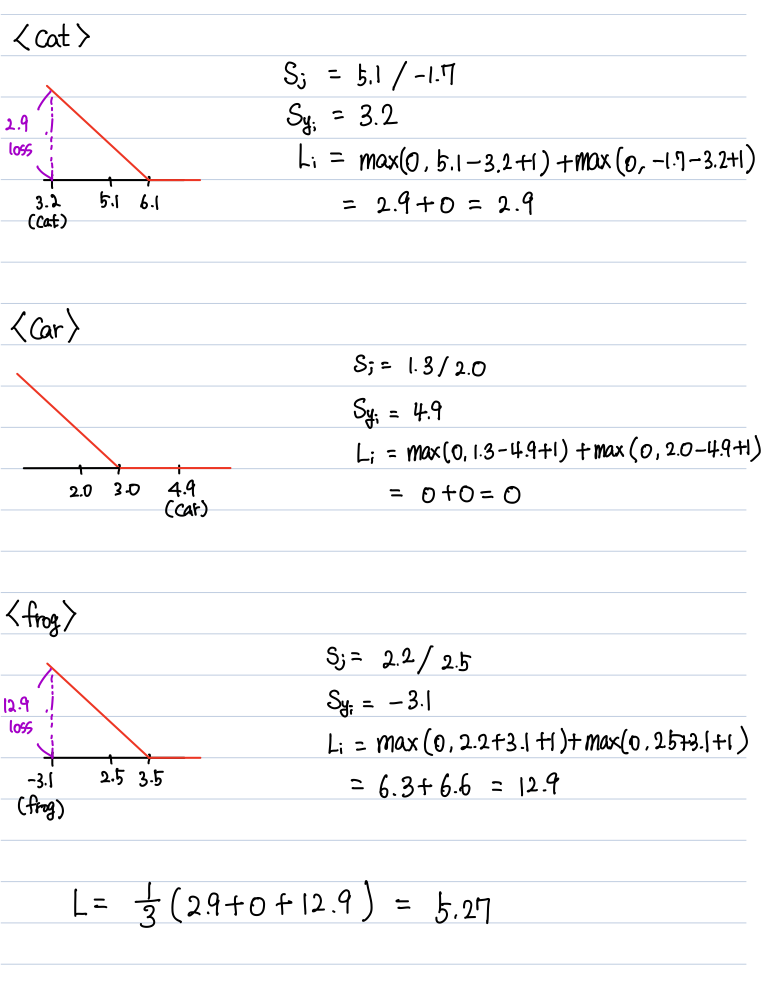
각각의 손실을 더해서 평균을 내면 Multiclass SVM loss 를 구할 수 있다.
Q1. car의 스코어가 조금 변하면?
그림을 보면 알수있듯이 스코어가 조금 변해도 손실은 0이다.
Q2. 손실의 최대값,최소값은?
0에서부터 무한대까지의 값을 가질 수 있다.
Q3. 모든 스코어가 0에 가깝다면 손실은 어떻게 될까?
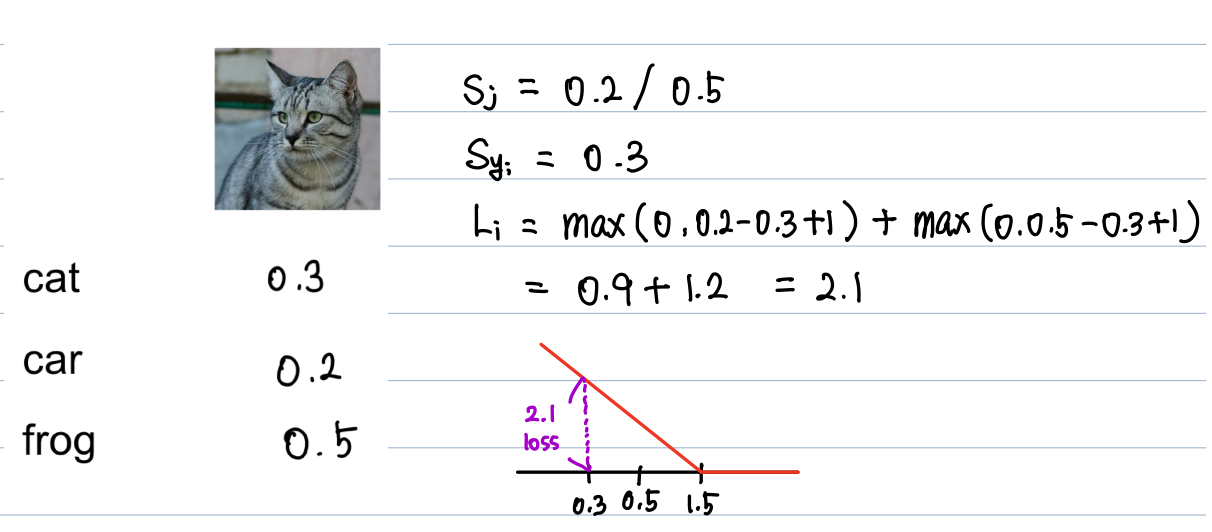
일반화를 시키면 C-1 (클래스 개수-1) 에 가까운 손실을 얻게 된다.
처음 트레이닝을 시킬때, loss가 c-1 이 아니라면 초기화에 문제가 생긴 것으로 볼 수 있다.
Q4. j=yi 인 경우도 sum에 포함한다면?
아무리 완벽하게 분류를 하더라도 손실이 1이 된다. 그래서 j=yi인 경우를 제외하고 더한다.
Q5. loss에서 전체 합이 아닌 평균을 쓴다면?
스케일만 변할 뿐 영향없다.
Q6. 손실함수를 제곱항으로 쓴다면?
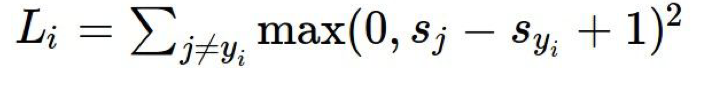
squared hinge loss라고 하며 비선형적으로 바뀐다.
Milticlass SVM loss의 파이썬 코드

Regularization
-
loss를 0으로 만드는 W를 찾았다고하자. 그런데 이 W는 하나뿐일까??
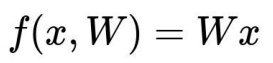
아니다!!
스코어가 선형적인 관계이기때문에 2W,3W 등등 W의 배수이면 전체 스코어도 선형적 바뀌기때문에 loss를 0으로 만든다!! -
loss를 0으로 만들면 무조건 좋을까?
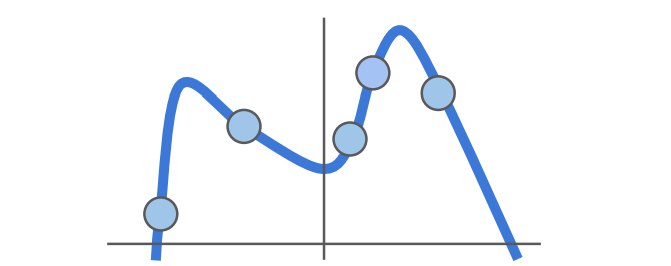
loss를 0으로 만든다는 것은 훈련데이터에 완벽하게 훈련을 했다고 보면 된다.
하지만 우리는 훈련된 데이터로 테스트를 하는것이 아니라 한번도 보지 못한 데이터로 테스트를 한다.
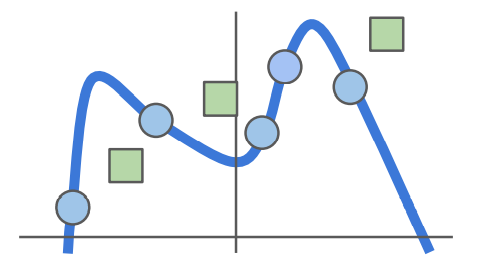
이처럼 훈련데이터에 완벽하게 훈련된 모델에 새로운 데이터가 들어오게되면 오차가 엄청나게된다. 우리는 오버피팅된 모델을 규제를 시킬 필요가 있어보인다.
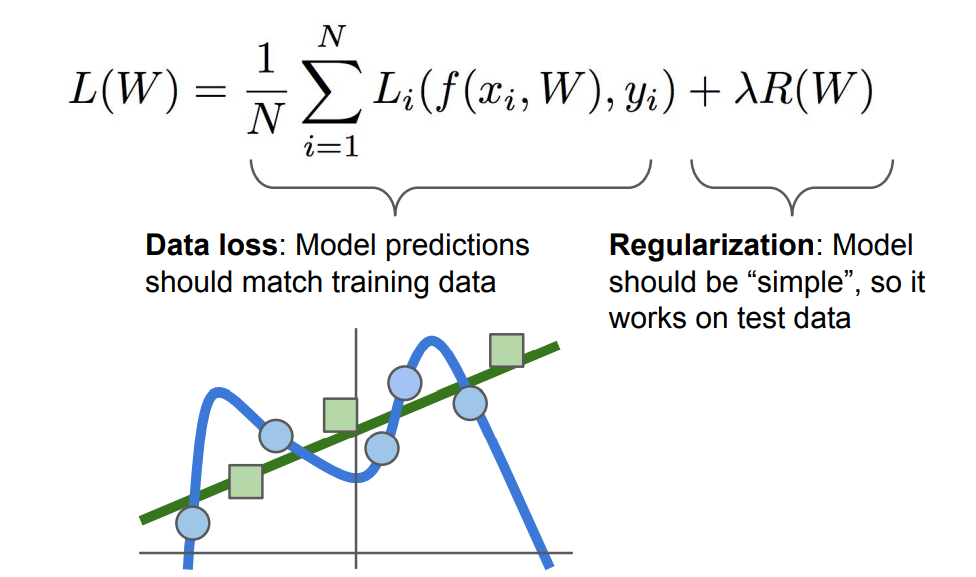
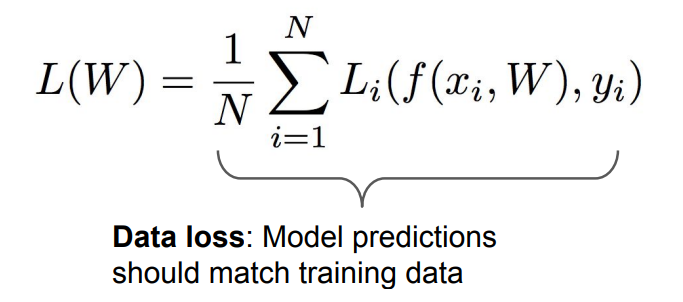
그래서 손실함수를 위와 같은 식으로 최종적으로 정의할 수 있다.
regulariztion은 모델이 훈련데이터에 완벽하게 피팅되는것을 막는 요소로 보면 될 것 같다.
regulariztion의 방법 다양하다.


1. l2 규제
wights의 값이 한쪽으로 몰려있는 경우 spread out하기에 좋다.
즉, l2규제는 w2를 선호한다고 볼 수 있다.
2. l1 규제
0이 많은 w1을 선호한다고 볼 수 있다.
나머지 regulation 방법들은 다음에 살펴보겠다.
2. Multinomial logistic regression(softmax)
앞서 svm loss에서는 스코어에 대한 해석보다는 정답클래스와 오답클래스를 비교하는 형식으로 계산했는데 softmax는 스코어 자체에 추가적인 의미를 부여하는 방법이다.

<예시>

1. 스코어를 지수화시킴
2. 정규화 시킴
3.-log를 씌움
스코어의 값을 확률적으로 나타내서 더 직관적으로 이해할 수 있다.
SVM(hinge loss) vs Softmax(cross-entropy loss)