
CS231n 3강
우리는 함수 f(W,x)를 통해서 스코어를 구하고 , W가 얼마나 잘 만들어졌는지 손실함수를 이용해서 평가도 하였다. 이제 손실함수가 최소가 되는 W를 만드는 optimization에 대해 알아볼 것 이다.

optimization은 loss가 0인 지점을 찾아나가는 것이다.
1. Random Search
결론부터 말하면 절대 사용하면 안된다.
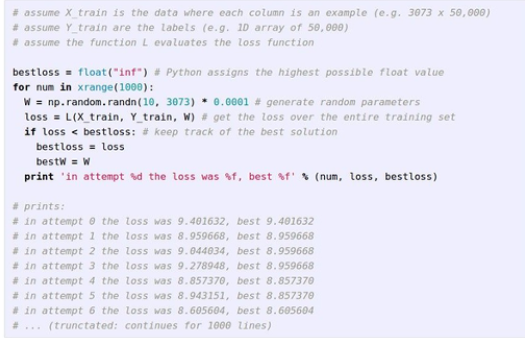
W를 완전 랜덤으로 만들어서 1000번정도 돌려가며 best loss를 찾는것이다.

정확도가 좋은건좋고 안좋은건 무지하게 안좋다. 갭차이 ㄷㄷ
2. Gradient Descent
1) Gradient Descent 접근법
(1) numerical gradient
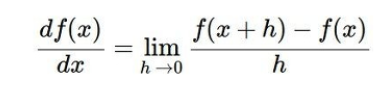
수식을 하나하나 계산해서 사용하는 방법으로 1차원이면 위와 같은 미분식으로 계산하고 다차원이면 편미분된 벡터의 값으로 나온다.

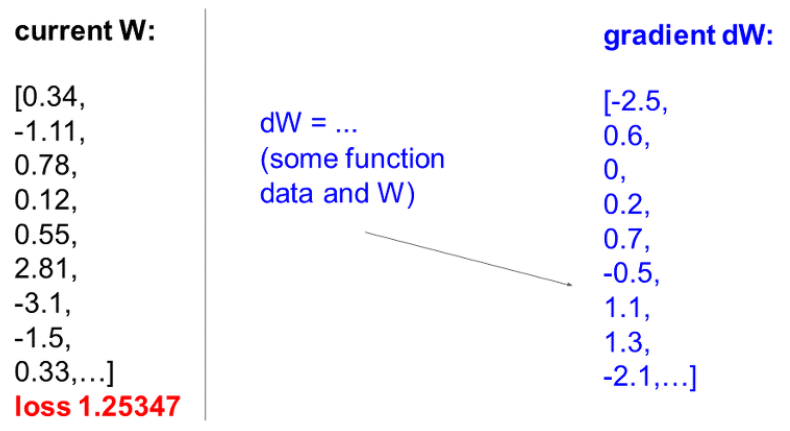
W를 임의로 가정했다고 치자.

h를 0에 가깝게 설정하고 w를 미세하게 옮긴후 미분식으로 계산해서 gradient를 구한다. 손실은 줄었고 기울기는 -2.5이다.

또, 이 친구는 손실은 증가했고 기울기는 0.6이다.

이 친구는 기울기가 변하지않았다.
loss의 변화가 없으므로 볼 필요가 없는 친구였다..
numerical gradient 는 하나 하나 계산을 방법이기 때문에 너무 느리다!!
마법처럼 gradient를 계산해주는 도구가 없을까??
(2) analytic gradient

뉴턴 선생님과 라이프니츠 선생님이 만들어 놓은 미분식을 사용하면 정확하고 빠르게 gradient를 구할 수 있다. 이 방법은 Backpropagation으로 다음장에서 배운다.
2) Gradient Descent 방식

우리가 설정할 수 있는 파라미터는 W, number of steps, learning rate이다.현재 임의로 설정한 W에서 기울기를 구하고 negative gradient 방향으로 step-by-step 나아가는 것이다.
왜 negetive gradient 방향으로 가야할까?
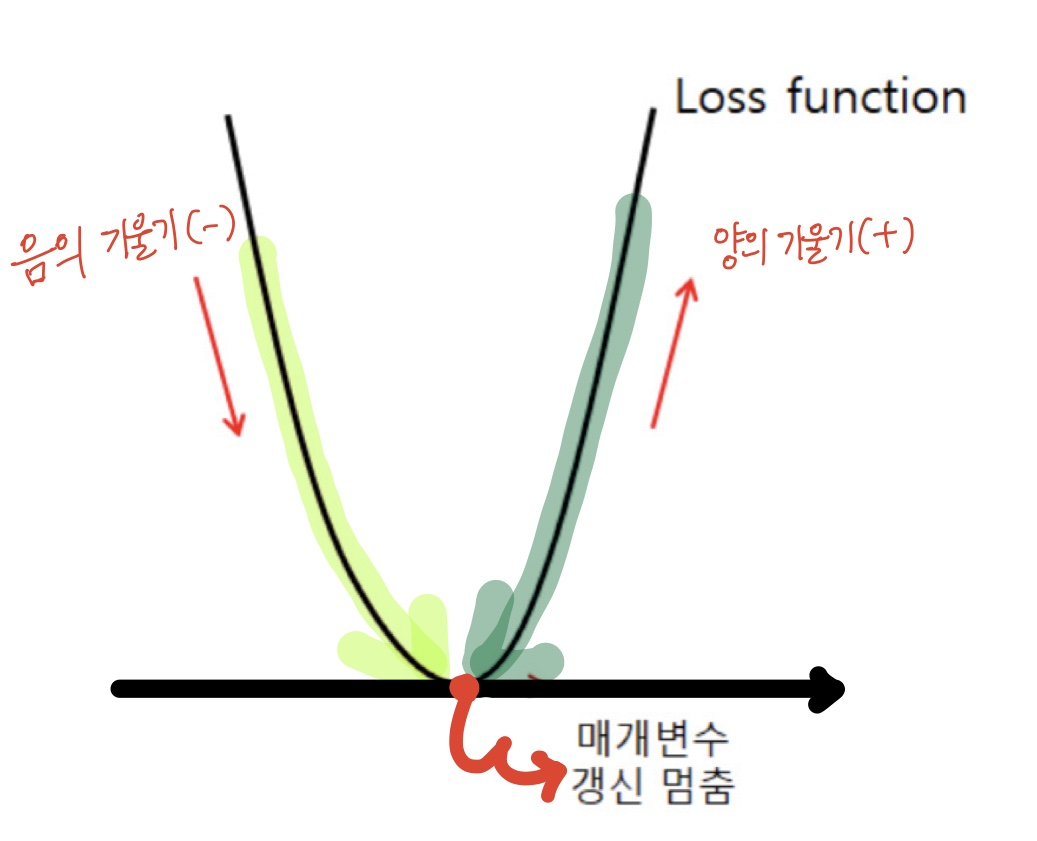
음의 기울기를 가졌으면 loss가 0인 지점으로 가기위해서는 + 방향으로 가야한다. 양의 기울기를 가졌으면 loss가 0인 지점으로 가기위해서는 - 방향으로 가야한다.
그래서 negetive gradient 방향으로 설정하는 것이다.
적절한 number of steps와 learning rate를 찾는것이 중요하고 어렵다.
3) 경사하강법의 SGD
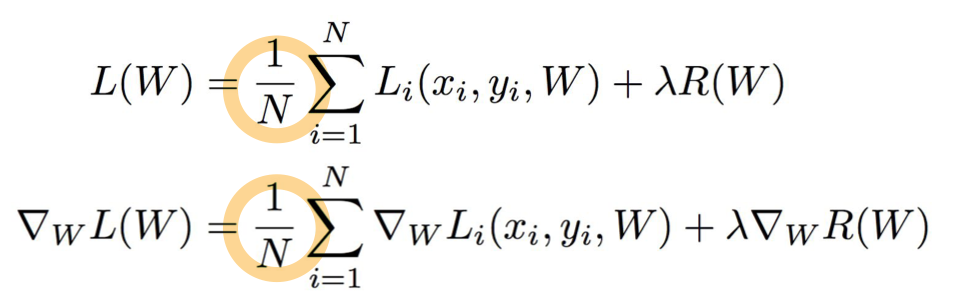
우리는 이때동안 N을 한꺼번에 올려서 계산을 하였다.(경사하강법의 BGD)
이렇게하면 문제가 되는게 파라미터를 업데이트할 때마다 모든 학습 데이터를 사용해서 계산이 오래걸린다는점이다.
그래서 우리는 SGD를 사용한다.
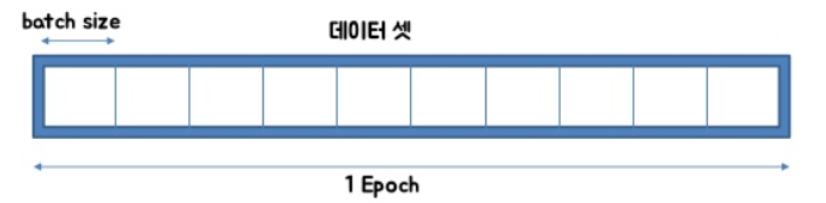
데이터셋을 batch size로 나누어 파라미터를 업데이트할때마다 일부를 사용해 나가는 것이다. 만약 batch size 가 256이면 256개의 데이터 뭉탱이를 가지고 W를 업데이트하고 또 다음 256개의 뭉탱이를 가지고 W를 업데이트 하는 방식이다.
