회귀분석이란?
- 관찰된 여러 데이터를 기반으로 각 연속형 변수간의 관계를 모델링하고 적합도를 측정하는 분석방법
- 독립변수와 종속변수 사이의 상호 관련성 (함수관계)
1.선형 회귀분석
종속변수 y와 한 개 이상의 독립변수 x와의 선형 상관관계를 모델링하는 회귀분석 기법이다.간단하면서도 실생활에 적용되는 경우가 많다.
선형 회귀 분석의 조건
- 선형성
- 독립성
- 등분산성
- 정규성
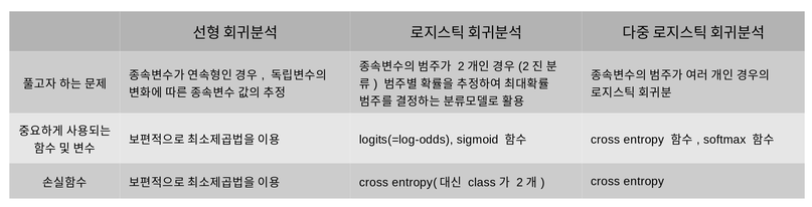
1) 선형 회귀식
H : 가정(Hypothesis)
W : 가중치(Weight)
b : 편향(bias)
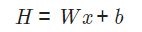
우리는 (데이터 x,y)로부터 (파라미터 W,b)를 추정해야한다.
선형 회귀 모델을 찾는다 = 주어진 데이터에 우리의 선형식이 잘 맞도록 W와 b를 찾는것
2) 선형 회귀 모델을 찾는법 : 최소제곱법
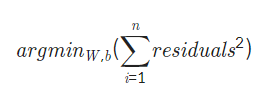
n개의 데이터에 대하여 잔차의 제곱의 합을 최소로 하는 W,b를 구하는 방법
※ 잔차(Residuals)
회귀모델을 이용해 추정한 값과 실제 데이터의 차이
※ 손실함수
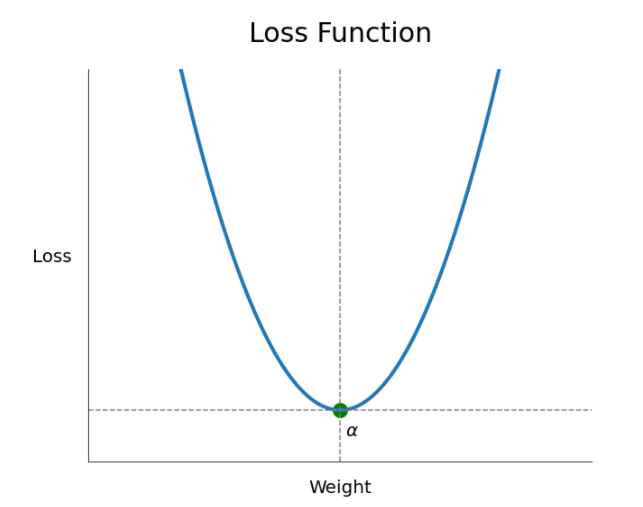
W,b와 같은 회귀계수를 구하는 과정에 쓰는 함수를 손실함수라고 한다.손실함수가 최저가 되는 지점α에서 최고의 모델 파라미터를 찾을 수 있다.
1. 최소 제곱법은 찾고자하는 α를 한번에 찾는다.
2. 경사하강법은 α를 점진적으로 찾아감 (learning rate로 수렴정도 조절가능)
2. 로지스틱 회귀분석
데이터가 어떤 범주에 속할 확률을 예측하고, 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도학습 알고리즘이다. 확률을 예측해주기때문에 회귀라고하지만 어떻게보면 분류문제이기도하다. 즉, 분류문제를 확률적으로 접근하는 아이디어이다.
1) 로지스틱 회귀식
종속변수가 0인 클래스인 확률 P(y=0∣x) 을 구하는 식
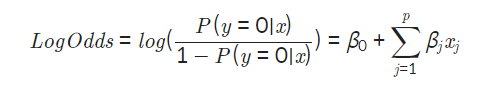
odds는 사건이 발생할 확률을 발생하지 않을 확률로 나눈값이다.
여기서 log를 붙이면 Log-odds라고 부른다. ( ※ P(Y=1∣x)=1−P(y=0∣x) )
이를 통해서,주어진 데이터를 잘 설명하는 회귀계수(β=W,b)를 구할 수 있다.
우리가 원하는 값은 lod-odds가 아니기 때문에 exp를 붙여줘서 정리할 수 있다.
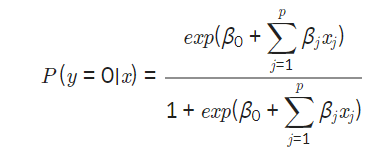
exp안의 식을 z로 치환하면 더 간단한 식을 만들 수 있다.
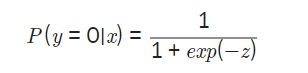
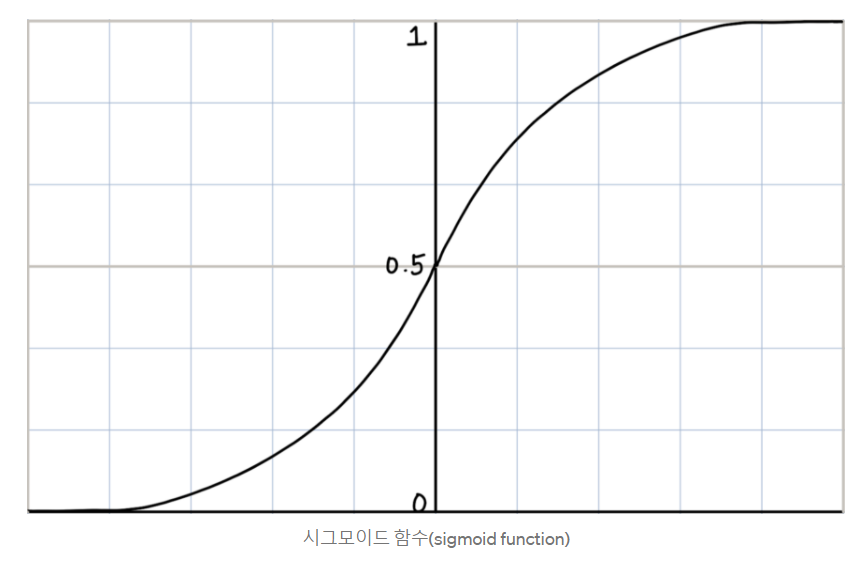
2) 시그모이드 함수
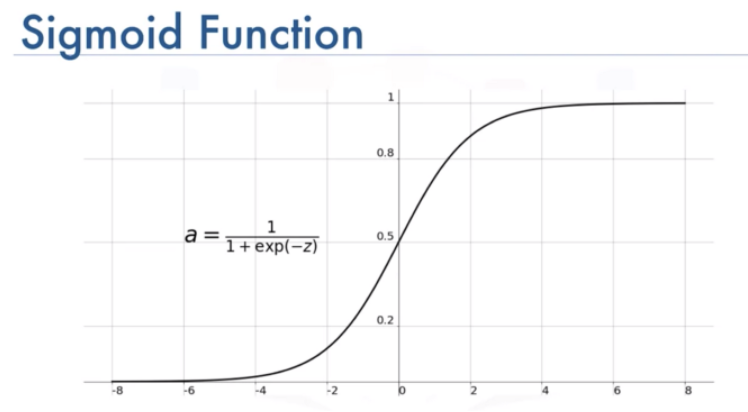
Log-odds 값을 구한 다음 시그모이드 함수에 넣으면 0-1 사이의 값(확률)으로 변환해준다.
3) 로지스틱 회귀 단계 총 정리
로지스틱 회귀는 데이터가 특정 범주에 속할 확률로 이진 분류를 한다고 앞서 말했다.
- 실제 데이터를 대입하여 log-odds , 회귀계수를 구한다.
- log-odds를 시그모이드 함수의 입력으로 넣어서 특정 범주에 속할 확률을 계산한다.
- 설정한 threshold 이상이면 1, 이하면 0으로 이진 분류를 수행한다.
3. 다중 로지스틱 회귀분석
로지스틱 회귀는 이진 분류뿐만아니라 여러 범주로 분류하는 다중 로지스틱 회귀로 확장될 수 있다.
1) 소프트맥스 함수
앞에서 썼던 시그모이드 함수는 소프트맥스 함수로 확장되야한다.
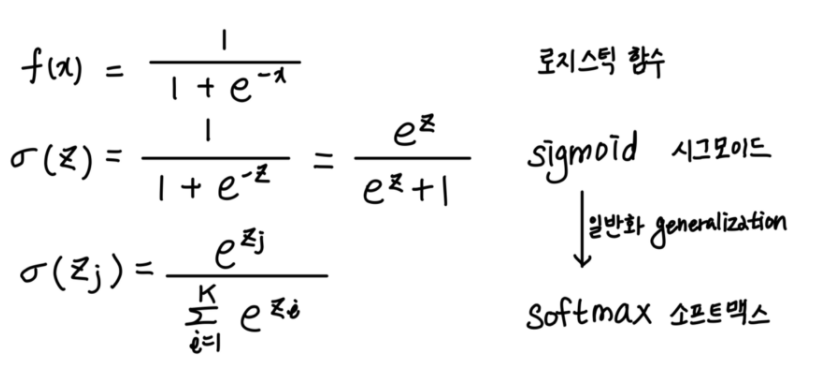
2) Cross Entropy
Cross Entropy는 소프트맥스 함수의 손실함수로 쓰인다.
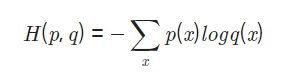
- p(x) : 실제 데이터의 범주값
- q(x) : 소프트맥스의 결과값
가중치가 최적화될수록 H(p,q)의 값이 감소하게 되는 방향으로 가중치 학습이 된다.실제로 가방에 0.8/0.1/0.1 의 비율로, 빨간/녹색/노랑 공이 들어가 있다.
0.2/0.2/0.6의 비율로 들어가있다고 예상했을때 cross-entropy 는 아래와 같이 계산된다.
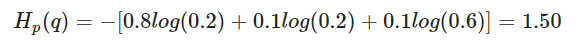
출처: https://3months.tistory.com/436 [Deep Play]총 정리