CS231N, EECS 498-007 / 598-005에서 나타나는 개념을 정리하기 위하여 복기용도로 작성하였습니다.
간단히 정리한 내용을 살펴보며 모르는 부분이 있을 때 찾아보는 용도로 보시면 좋을 것 같습니다.
What’s going on inside Convolutional Networks?
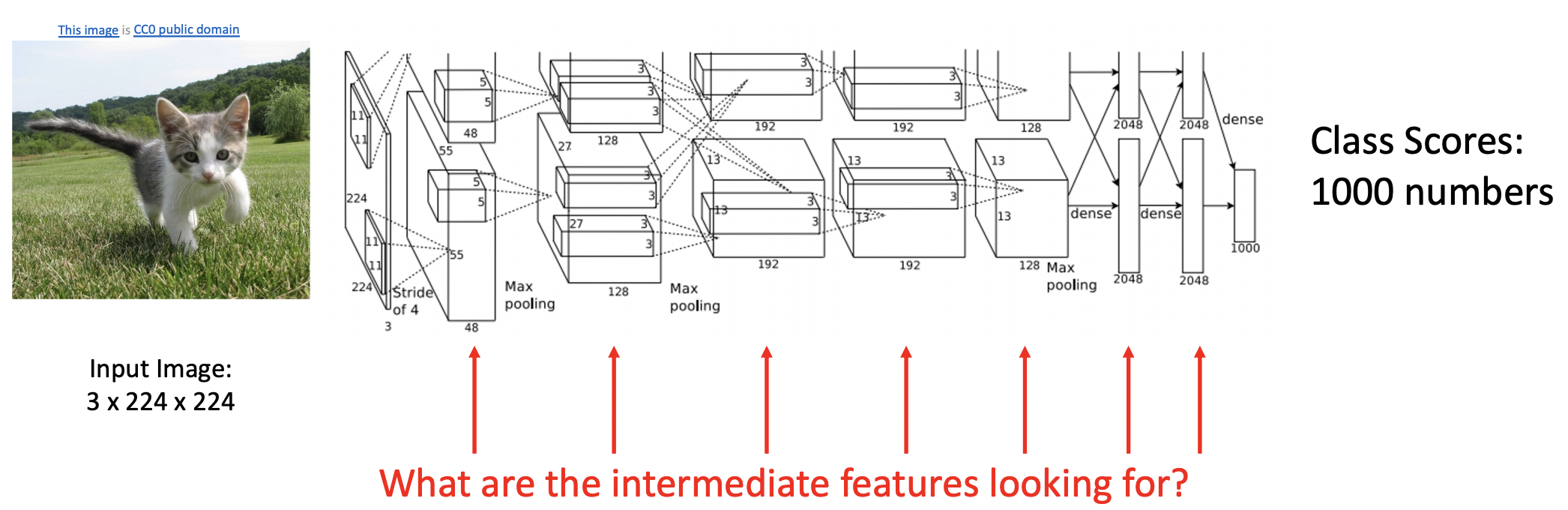
- 모델을 쌓아 학습하는 과정을 거쳤지만 과연 중간 레이어들은 어떤 특징들을 담고 있는지 궁금해진다. 중간과정의 특이점을 안다면 모델 학습의 직관을 키울수 있다.
First Layer: Visualize Filters

- 이전과정에서 template maching 예제를 보면 클래스별 filter(클래스의 보편적 이미지와 비슷)와 inner product한 결과를 점수화하여 계산했었다.
- 각기 다른 모델의 첫번째 레이어를 나타낸 결과 보통 edge의 orientation과 opposing color를 나타냈다.
- 그렇다면 이후 레이어에서 featrue 정보를 시각화하면 어떤 결과가 나올까?
Higher Layers: Visualize Filters

- 그러가 크게 직관적으로 도움되는 정보는 찾을 수 없었다.
Last Layer
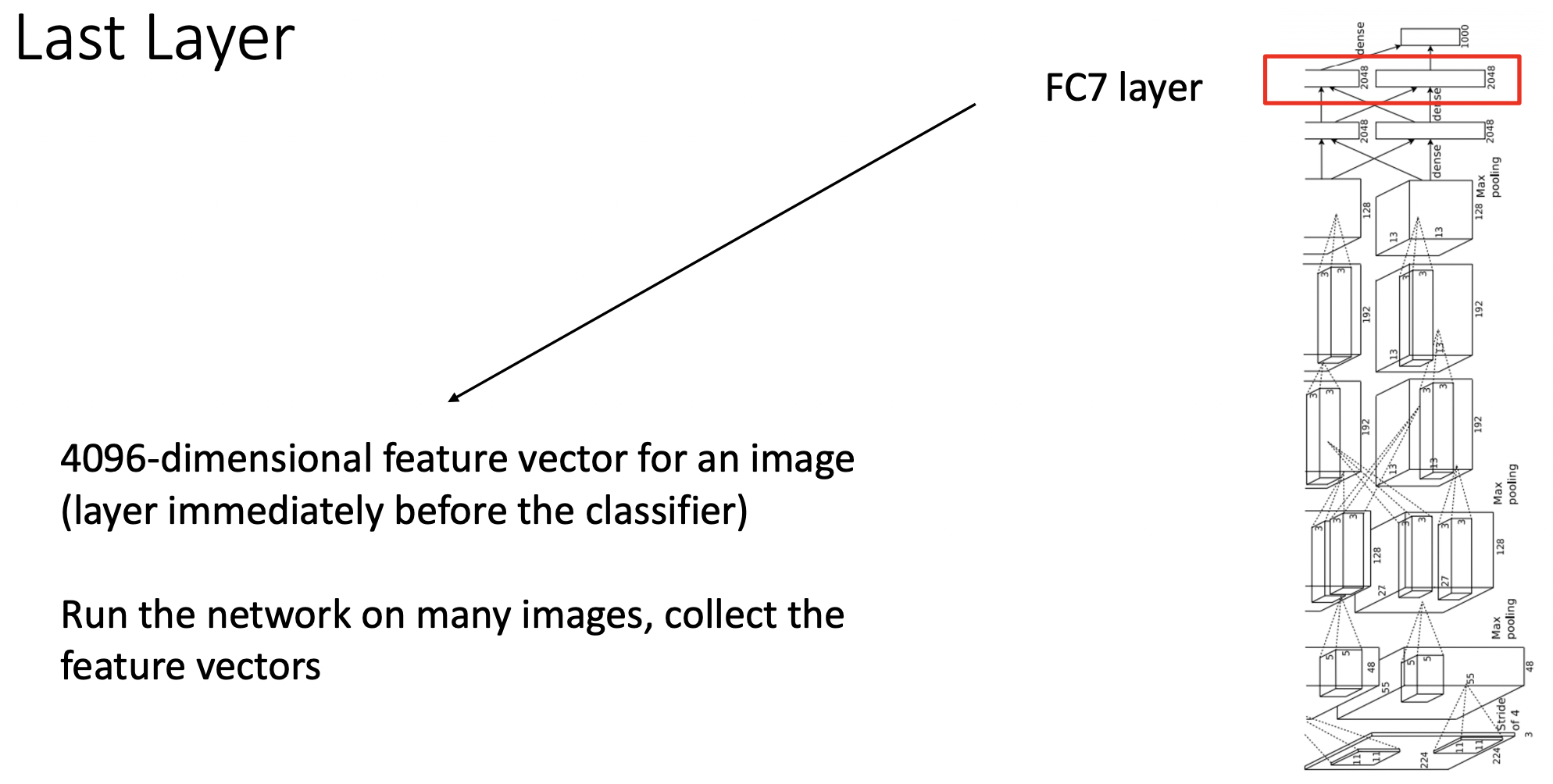
- 테스트 이미지들을 학습된 alexnet 모델의 말단의 FC 레이어를 통과한 결과(4096 feature vector)를 종합했다.

- 왼편에서는 원본이미지를 pixel 공간에서 nearest neibors를 구한 것이며(클래스가 다르지만 비슷한 이미지가 포함됨), 오른쪽은 feature vector공간에서 nearest neibors를 구한 것이다.(클래스가 같으며 상대적으로 비슷하지 않은 이미지)
Last Layer: Dimensionality Reduction
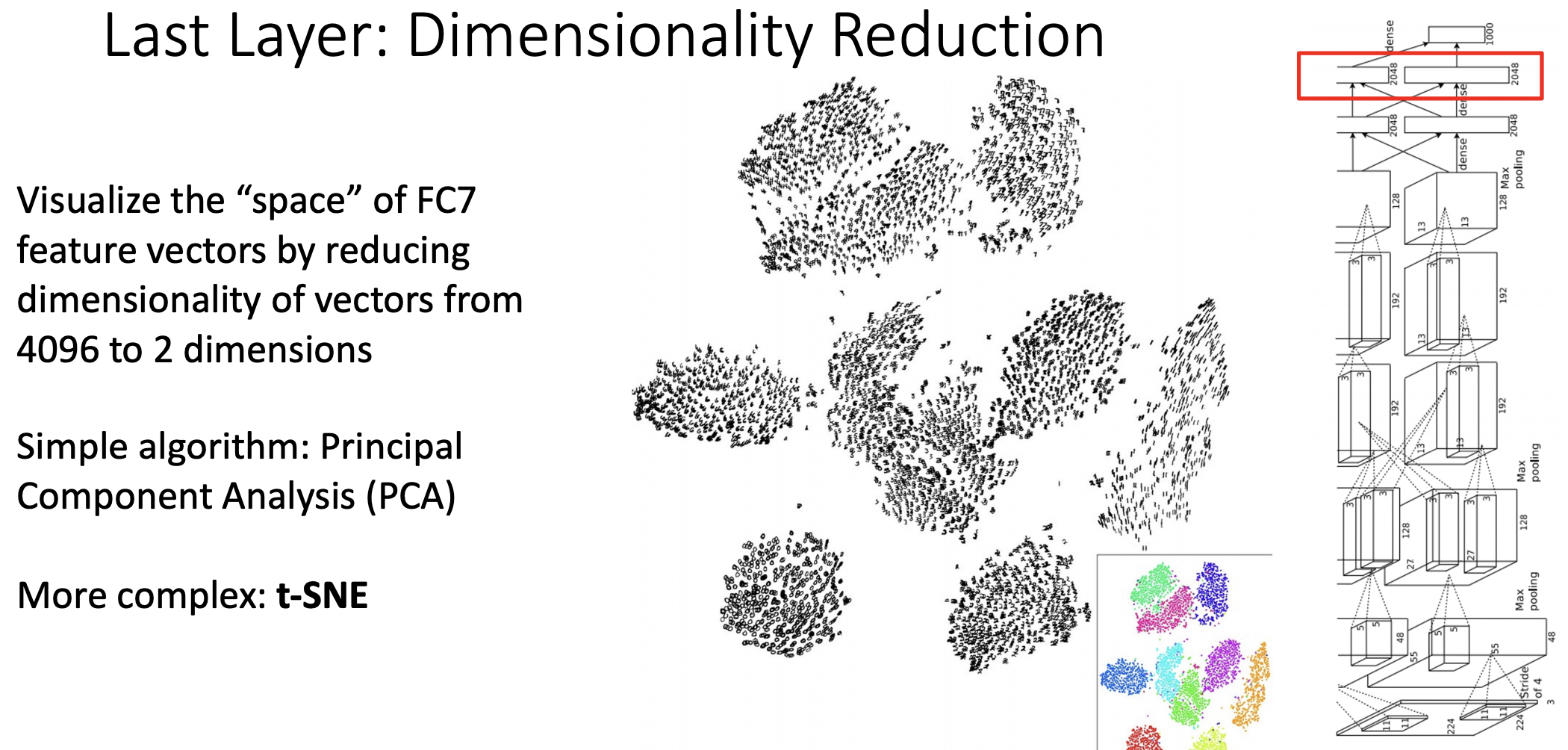
- 4096차원이 굉장히 고차원이므로 2차원으로 축소를 진행한다.(PCA, t-SNE)
- 차원축소를 진행한 결과 테스트 이미지들의 feature가 클래스별로 군집된것을 확인할 수 있었다.
Visualizing Activations
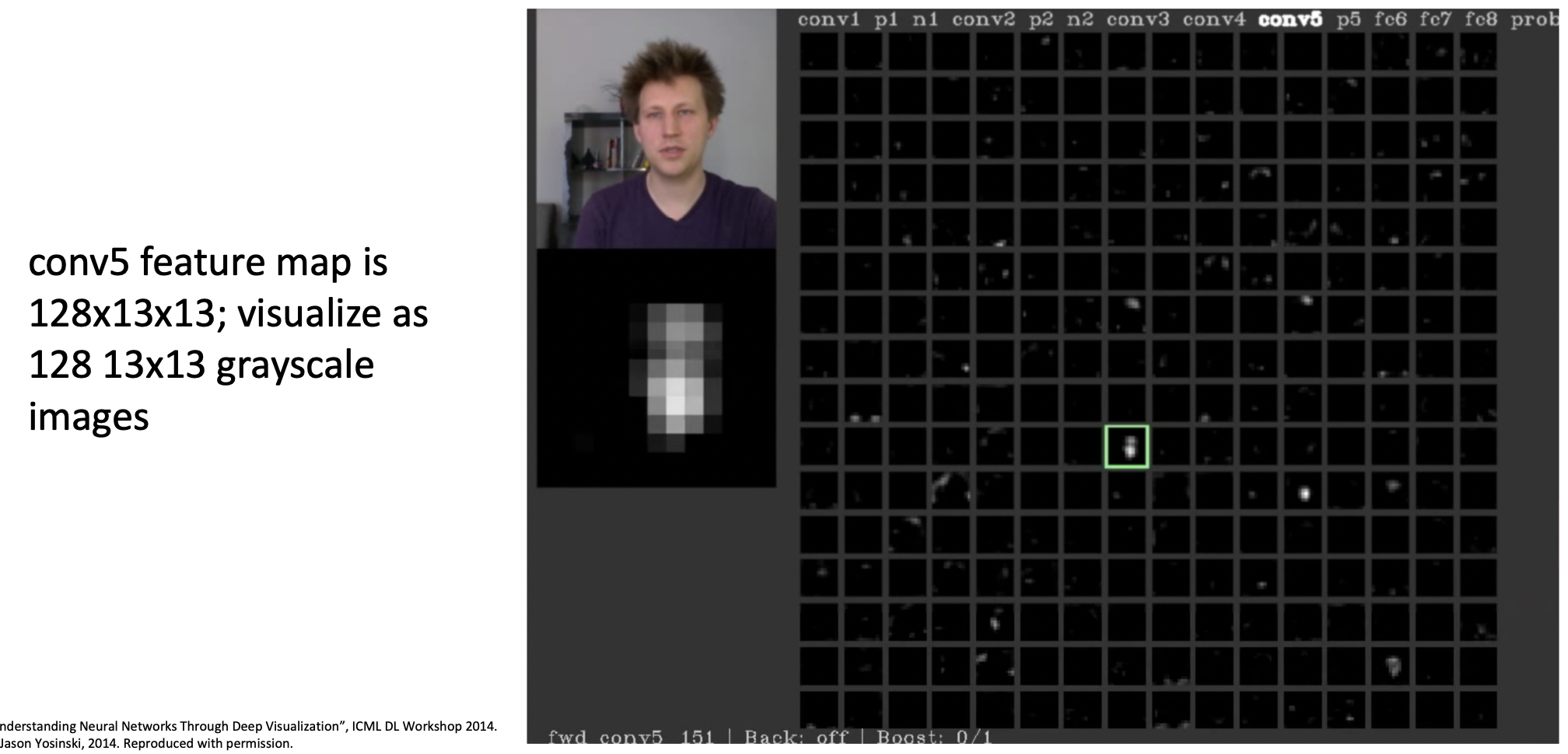
- 모델 내부 특정 레이어의 feature map이 activation되는 것을 관찰한 경우이다.
- 초록색 칸이 activation되는 경우를 분석한 결과, 사람 얼굴이 있을 때activation 하는 것으로 발견되었다.
- 직관적으로 모든 레이어들의 filter는 특정한 속성의 값이 있을때 activation되는 것으로 판단할 수 있다.
Maximally Activating Patches
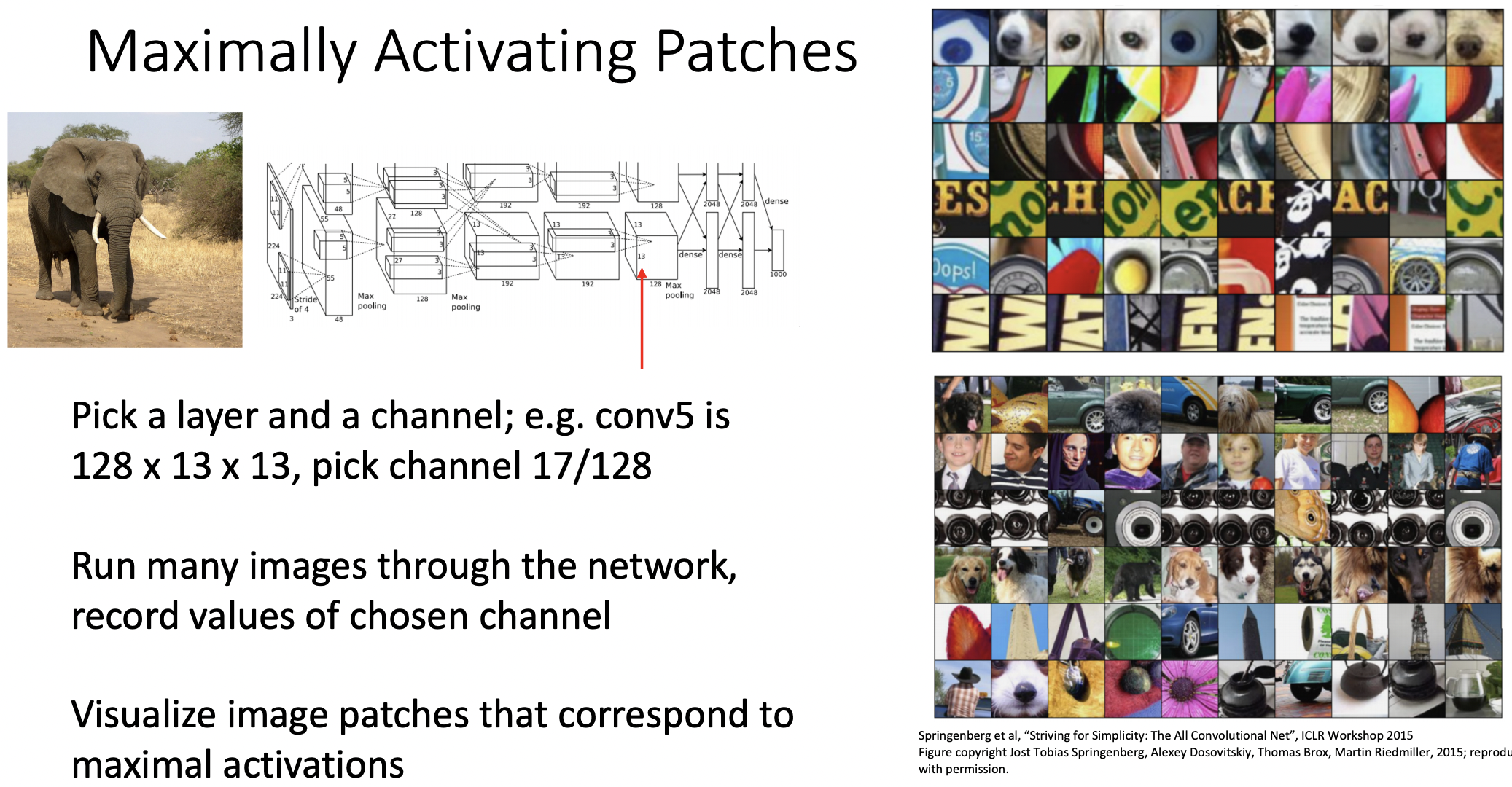
- 하나의 레이어와 filter를 선택하여 해당 필터를 통과했을때 최대의 activaiton값을 가지는 경우를 나타내보았다.
- 오른쪽, 위 그림은 여러가지 filter(행)에 대한 activation 값이 높은 patch 이미지를 (열)단위 나타내었는데, 살펴보면 결과는 비슷한 형태의 이미지가 같은 행에 위치한 것을 볼 수 있다.(특정 뉴런은 이미지의 일관된 특징을 잡아냄)
- 오른쪽, 아래 그림은 깊은 레이어의 뉴런으로, 뉴런에 해당하는 이미지의 patch가(receptive field) 커지기 때문에 위치와 색등에 (상대적으로) robust한 특징을 지니고 있다.
Which Pixels Matter?: Saliency via Occlusion

- 클래스 구분할 때, 픽셀의 어떤 부분이 다른 픽셀보다 더 중요한지 확인해보자.
- 이미지의 특정 부분을 움직이면서 회색으로 마스킹하여, 어떤 부분이 점수를 가장 잘 떨어뜨리는지 확인한 결과, 물체의 위치정보에 민감한 것을 확인 할 수 있었다.
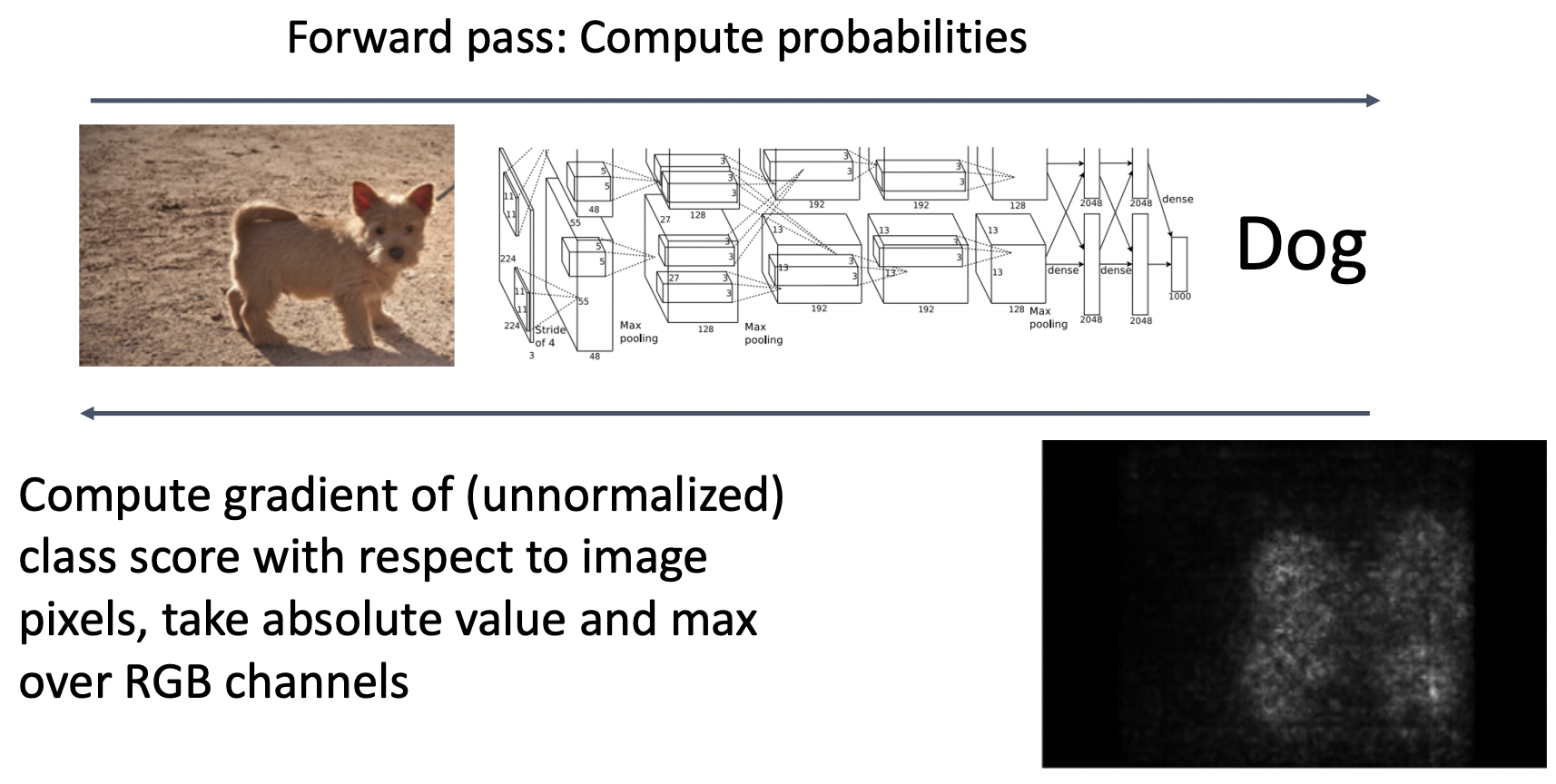
- 그림처럼 강아지 이미지를 학습할 때, 강아지 점수(final class score)에 해당하는 gradient를 픽셀 단위로 계산한다.
- 원본이미지의 픽셀을 일부 변화하여 gradient의 크기 정도를 비교하여 픽셀 위치의 중요도를 파악할 수 있다.
- 오른쪽 아래 그림처럼 강아지 형체에 해당하는 픽셀일 때, gradient가 커진것을 확인 할 수 있다.
Intermediate Features via (guided) backprop
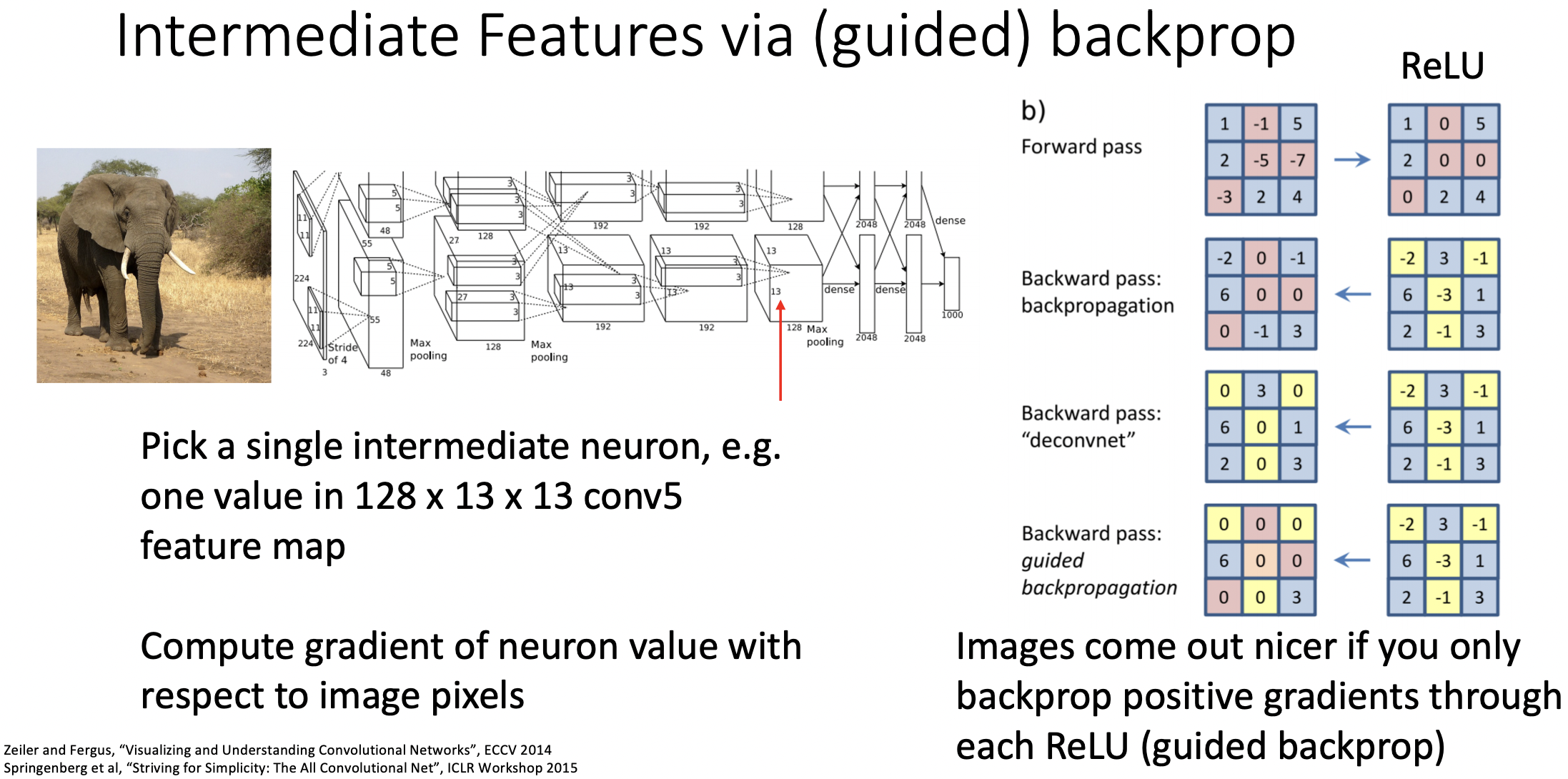
- 마지막 단계의 class score대신 중간단계 filter의 gradient를 확인하는데 이미지의 어떤부분이 크게 영향을 주는지 확인해본다.
- backprop시 guided backprop을 사용하는데 relu에서 local gradient값 뿐만아니라 upstream gradinet도 음의값을 가진다면 0으로 맞춰준다.
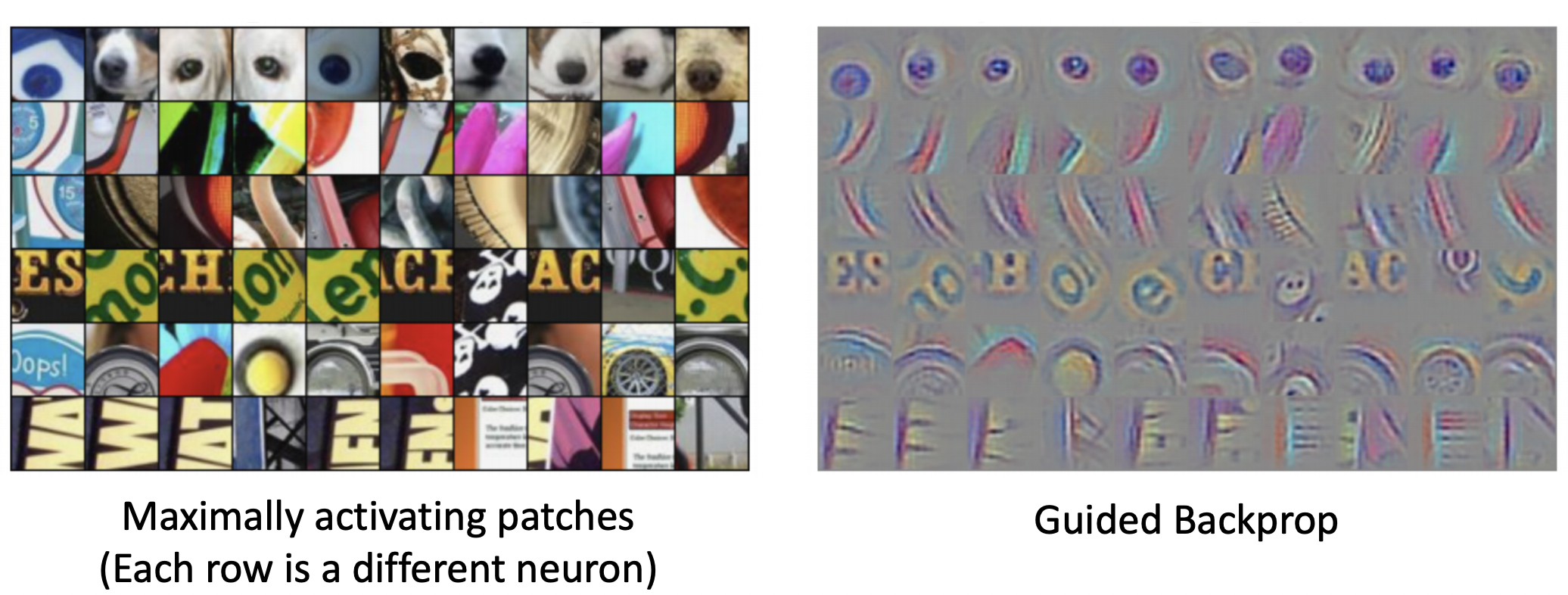
- 최대로 activation 값을 지닌 이미지 patches 나열한 것과 같이 guided backprop을 사용 했을때, 실제 이 뉴런이 어떤 특징을 잡아내려 하는지 확인할 수 있다.
Class Activation Mapping (CAM)
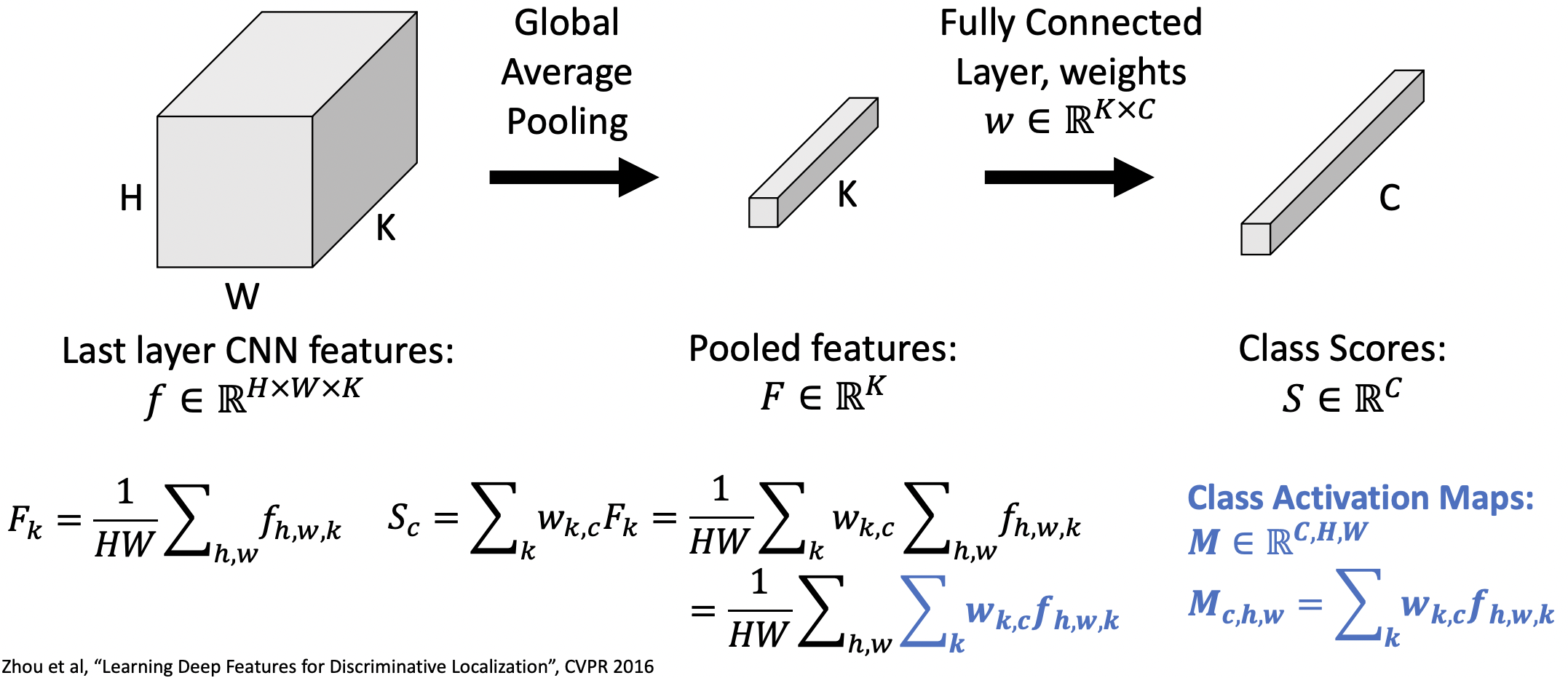
- CONV 레이어가 이미지의 어떤 부분을 보고 해당 클래스로 판단하는지 알기위해서 CAM을 사용했다.
- 마지막 CNN layer의 feature:
Pooling 이후 feature:
FC layer이후 class score, weight 정보:
, - GAP(global average pooling) 적용
--(1) - class score 계산 과정:
--(1)
- class activation map(CAM) 확인
- CAM은 마지막 레이어의 크기(H,W)에 해당하는 클래스(C)의 점수를 알 수 있다.

- 왼쪽 그림은 5가지 클래스에 해당하는 activation값을 이미지로 표현한 것이고, 오른쪽 그림은 바벨이미지의 어떤 부분이 activation값이 크게 나타나는지 확인한 그림이다.
- 하지만 이 방법은 마지막 CONV에만 적용가능하여 한계점을 지녔다.
Gradient-Weighted Class Activation Mapping (Grad-CAM)

- (activation값을 가진)특정 레이어 A를 지정한다.
- A에서의 gradient class score 를 계산한다.
- 2의 결과를 GAP한다.
- 1과 3의 결과를 종합하여, activation map 를 계산한다.
2의 클래스에 대한 클래스점수가 feature크기(H,W)만큼 표시된다.

- 개와 고양이가 있는 그림에서 개가 활성화된 부분과 고양이가 활성화되는 부분이 다름을 확인 할 수 있다.
Visualizing CNN Features: Gradient Ascent
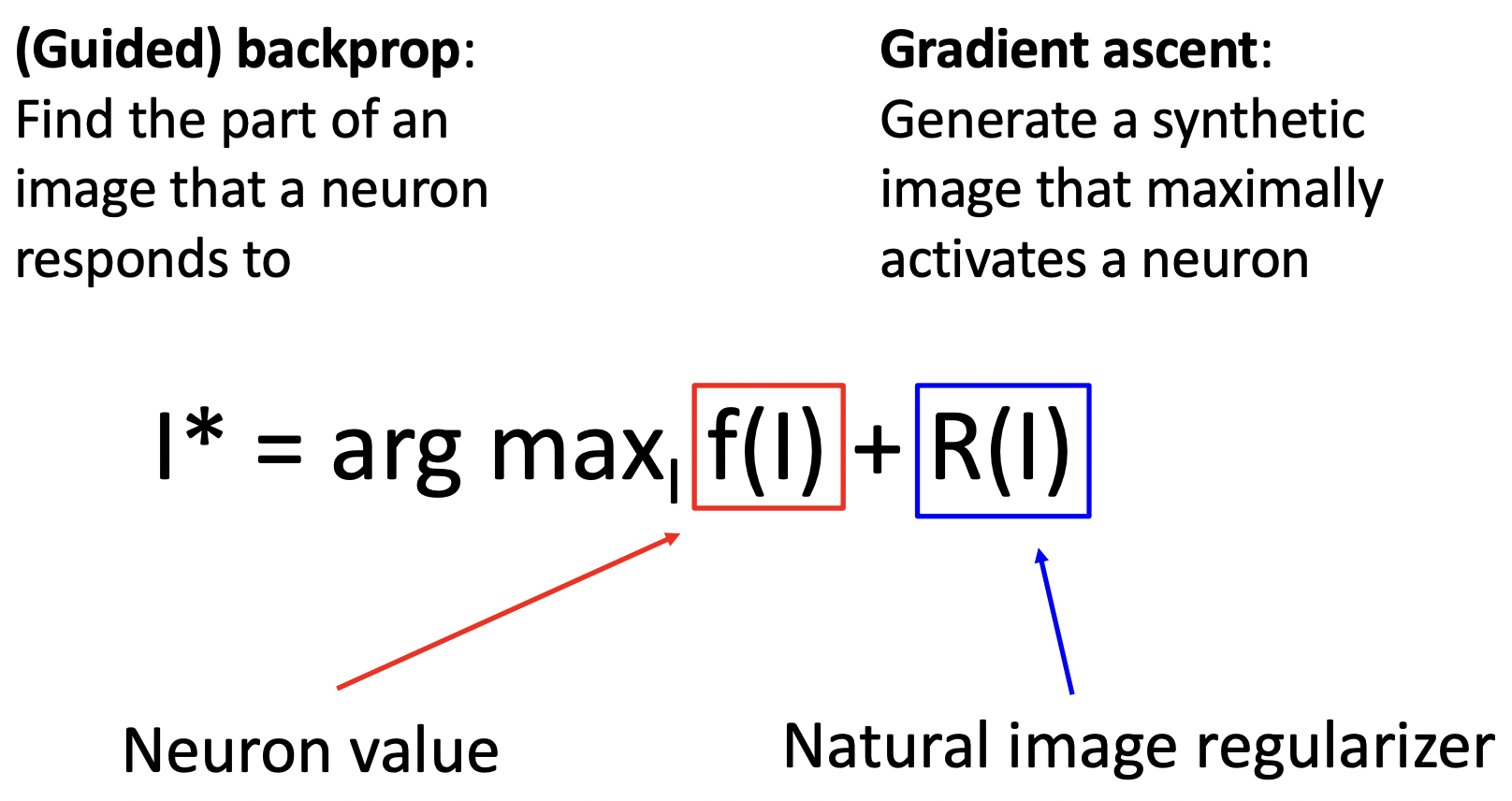
- 학습된 네트워크 모델의 weight를 고정하고, 학습할 이미지를 (특정 뉴런의 값을 최대화하는 방향으로) update하여, 합성된 이미지를 생성해본다.
- I*은 특정 뉴런이 최대로 활성화된 이미지이고, f(I)는 특정 뉴런에서의 값, R(I)는 정규화 값으로 일반적인 이미지처럼 보이게 만든다.
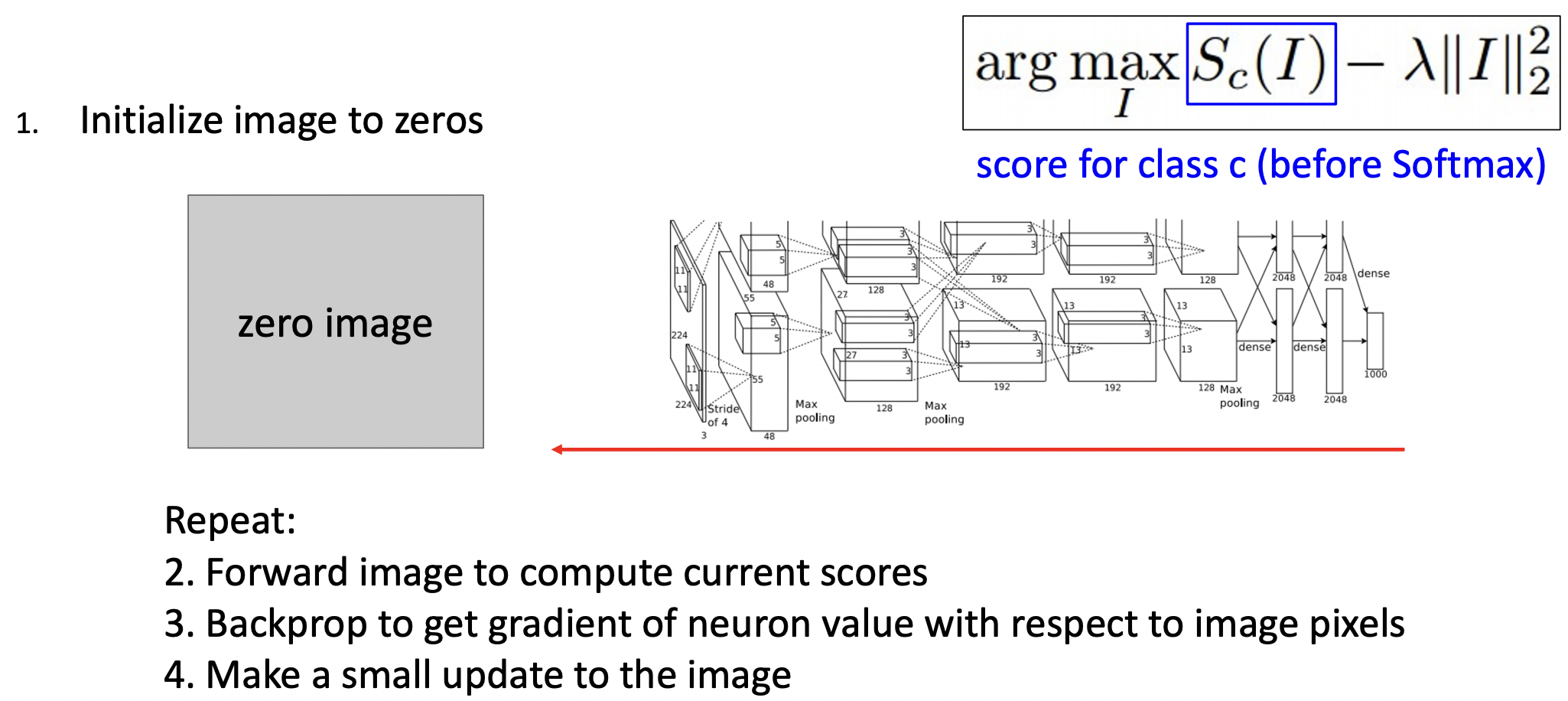
- 처음 노이즈 혹은 0값을 가진 이미지로 초기화한다. forward pass과정으로 현 점수 값을 계산하며, backprop과정에서 이미지 픽셀에 해당하는 뉴런의 gradient를 계산한다. update과정을 반복하여 진행한다.

- 정규화 값으로 L2 norm을 적용했을때, 생성된 이미지를 살펴보면 해당하는 클래스의 특징들이 이미지에 투영된것을 확인할 수 있다.

- 단순한 L2 norm대신 주기적으로 blur와 clipping과정을 거쳐 좀 더 일반적인 이미지를 생성해본다.

- 클래스 점수를 최대화하는 것이 아닌 레이어의 뉴런의 weight를 최대화하면 위와 같이 생성된 이미지가 나타난다.
Feature Inversion

- 테스트할 이미지의 특정 CNN의 feature와 비슷하지만 새로운 이미지를 생성해보자.
- 새로운 로스값은 새로운 이미지와 테스트할 이미지의 feature의 차이를 제곱하고, 로스에 정규화 값(Total Variation regularizer)을 추가하여 x*인 새로운 이미지를 생성한다.

- 깊은 레이어(오른쪽)일수록 이미지의 원본값에 변형이 많이 되는것을 확인 할 수 있다.
DeepDream: Amplify Existing Features
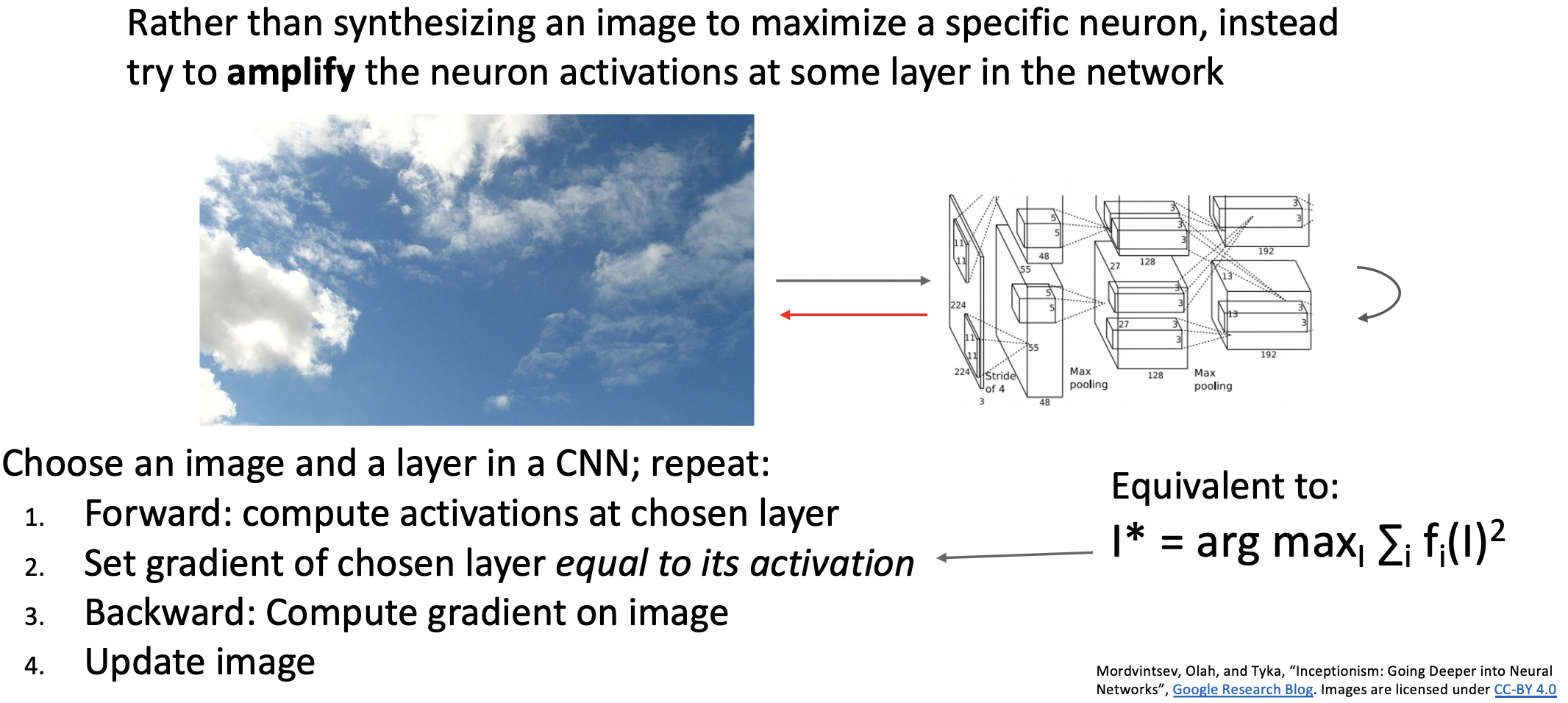
- 특정 뉴련의 값을 maximize 대신 amplify한다.
- forward에서의 activation값을 backward에서의 gradient으로 사용합니다.

- 낮은 단계의 레이어에 적용한 경우으로 해당 레이어는 edge를 인식하는 것으로 추론할 수 있다.

- 하위 단계의 레이어에 적용한 경우 미세한 특징값을 최대하하여 원본에 없던 특징을 가진 합성 이미지가 생성된 것을 확인 할 수 있다.

- 과정을 지속하면 꿈을 꾼듯한 이미지가 생성된다.
Texture Synthesis
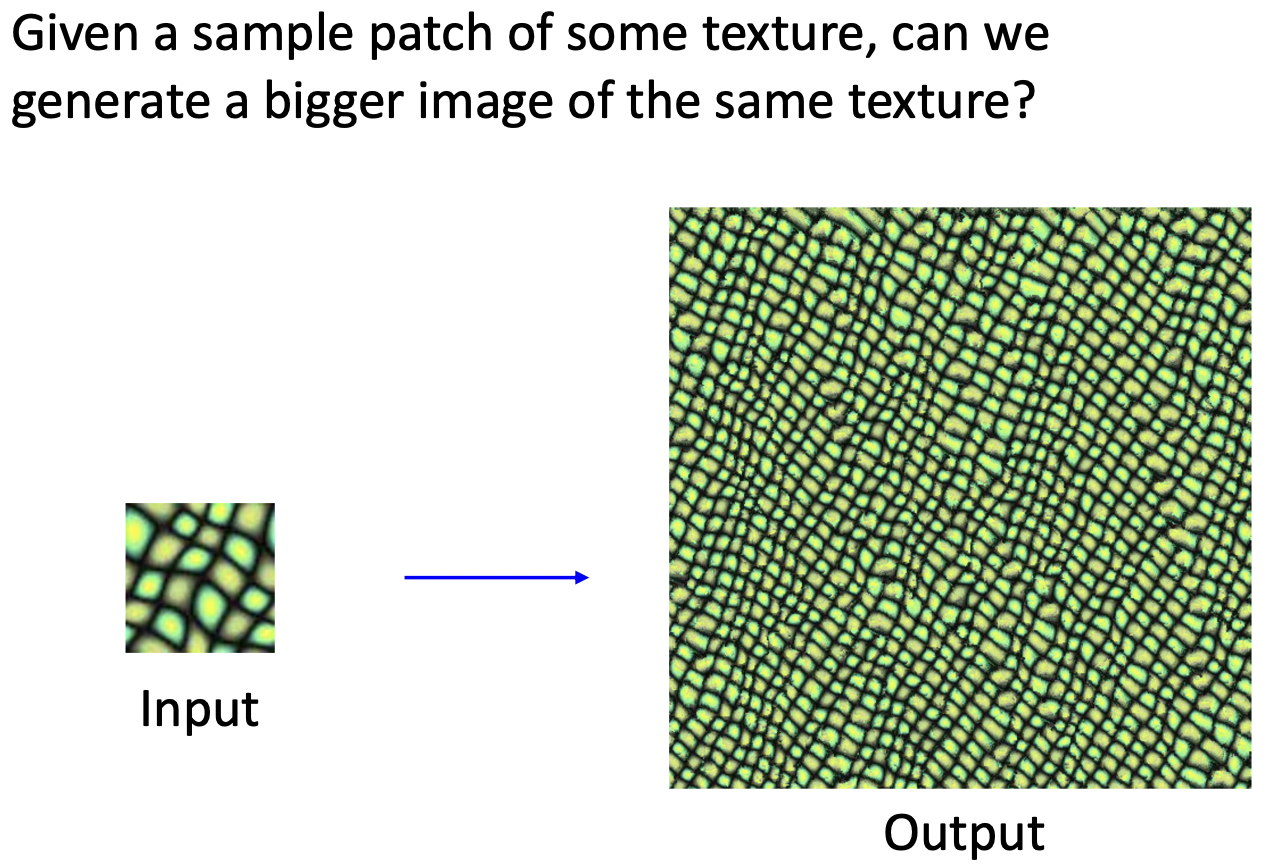
- 특정한 texture을 가진 patch 이미지를, 같은 texture을 가진 큰 이미지로 생성해보자.
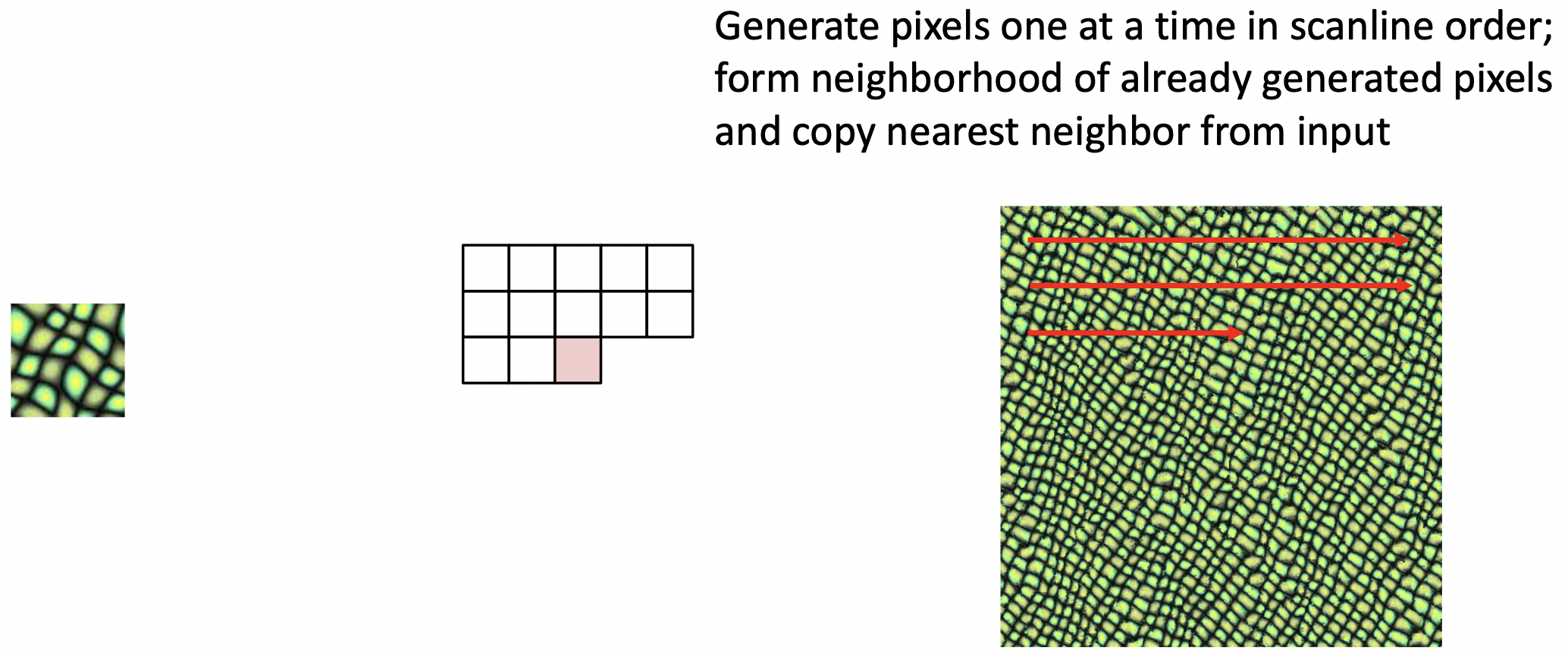
- Nearest Neighbor을 사용하여 학습 과정없이 texture synthesis를 할 수 있다.
Texture Synthesis with Neural Networks: Gram Matrix
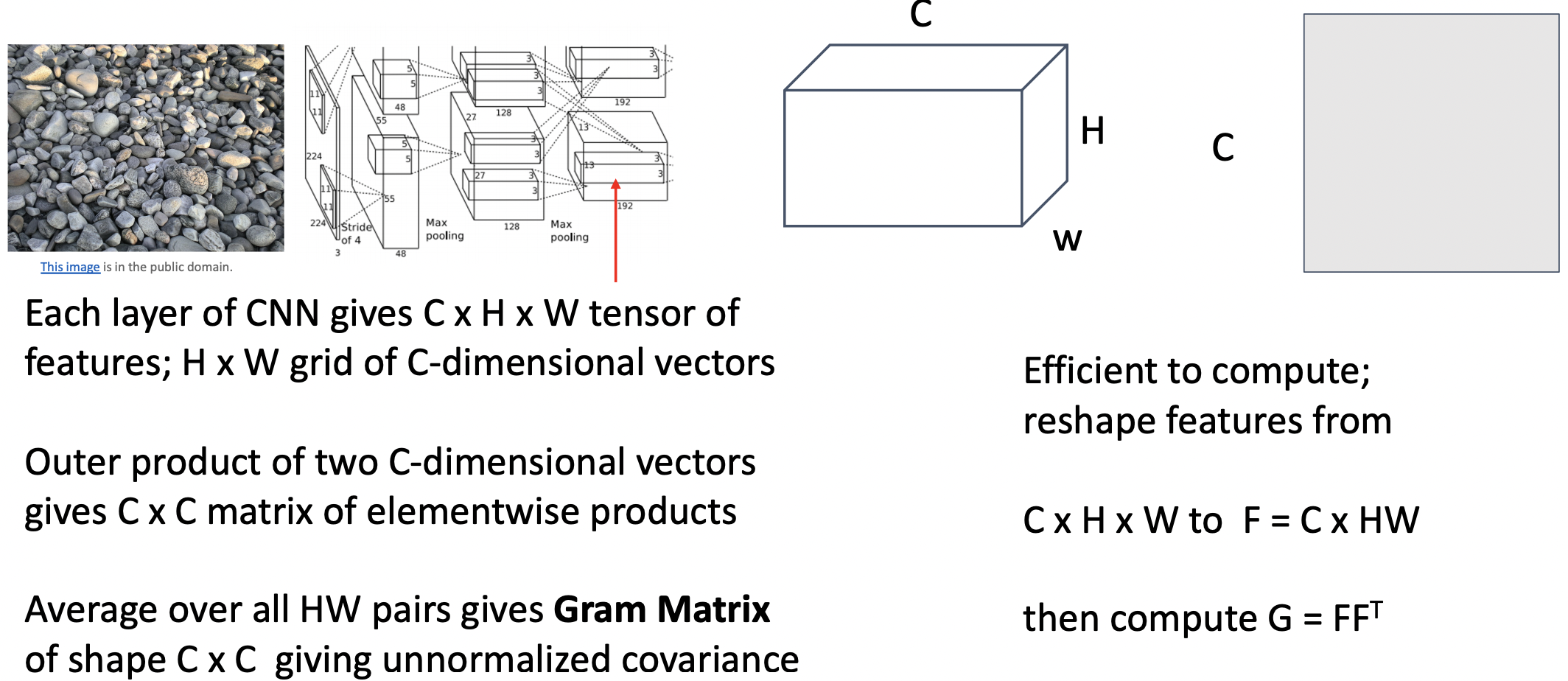
- 특정 레이어를 선택하고, 타겟 이미지를 통과 시킨 뒤, feature volume을 뽑아낸다(W,H,C)
- feature volume에서 C차원의 feature vector(H*W 갯수중) 두개를
이를 outer product한다. - H*W 갯수의 pair들을 평균화 하여 Gram Matrix(CxC)를 계산한다.
- Gram Matrix
- unnormalized covariance between feature vector
- give info of which feature correlated
- efficient to compute by reshaping feature
- 어떤 feature가 다른 위치에서 동시에 일어나는지 제공하고, spatial structure를 제외시킨다.
- gram mat 와 gradient ascent를 사용하여 Texture Synthesis를 한다.
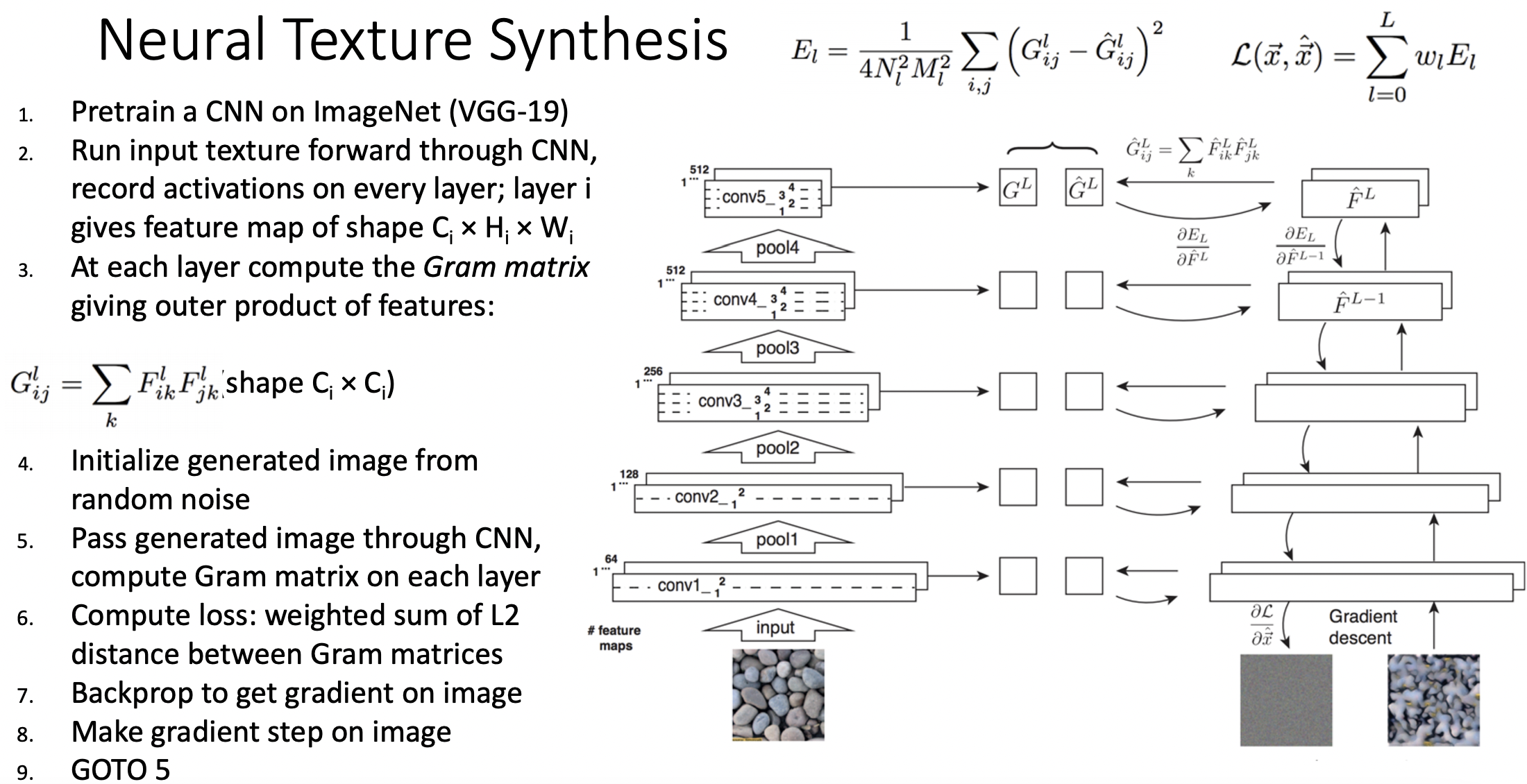
- 수행 단계
- CNN을 pretrain 한다.
- 입력 texture를 CNN에 forward하고, 모든 레이어의 activation을 저장한다.
- 모든 레이어에 gram matrix를 계산한다.
- 생성할 이미지를 랜덤 노이즈와 함께 초기화한다.
- 생성할 이미지의 gram matrix를 계산한다.
- 두 개의 gram matrix간 로스를 계산한다.
- 생성할 이미지에 gradient를 구하여 backprop과정을 수행한다.

- 첫 번째 행은 원본 이미지이며 아래 행일수록 깊은 레이어이다.
- 레이어가 깊어질 수록 반복되는 patch의 크기가 커지고 매우 다른 spatial texture을 가지는 것을 확인 할 수 있다.
Neural Style Transfer: Feature + Gram Reconstruction

- Feature reconstruction 방식과 Texture synthesis 방식을 합해본다.

- Feature reconstruction 방식을 사용한 content image와 Texture synthesis 방식을 사용한 style image를 합산한다.
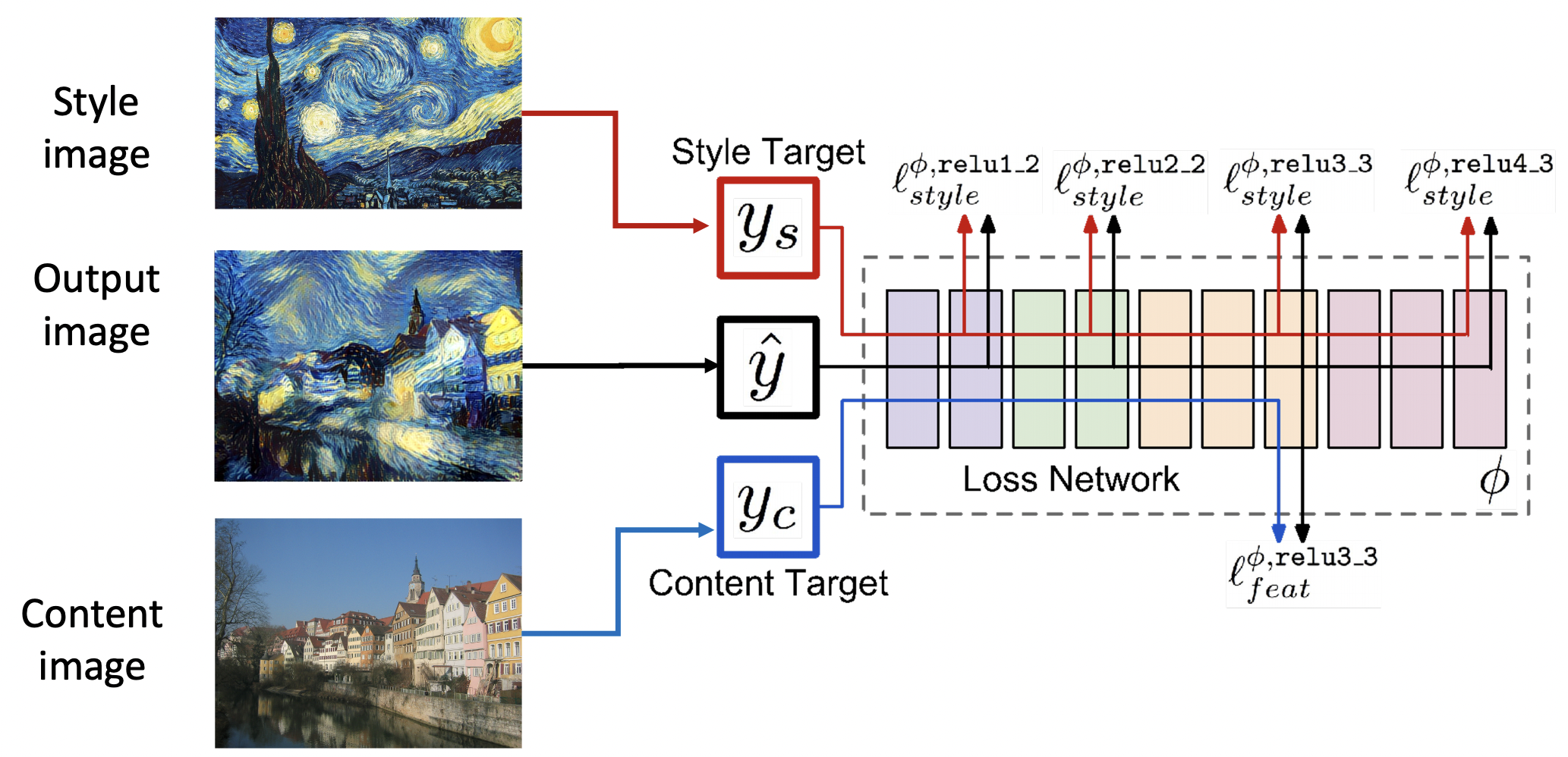
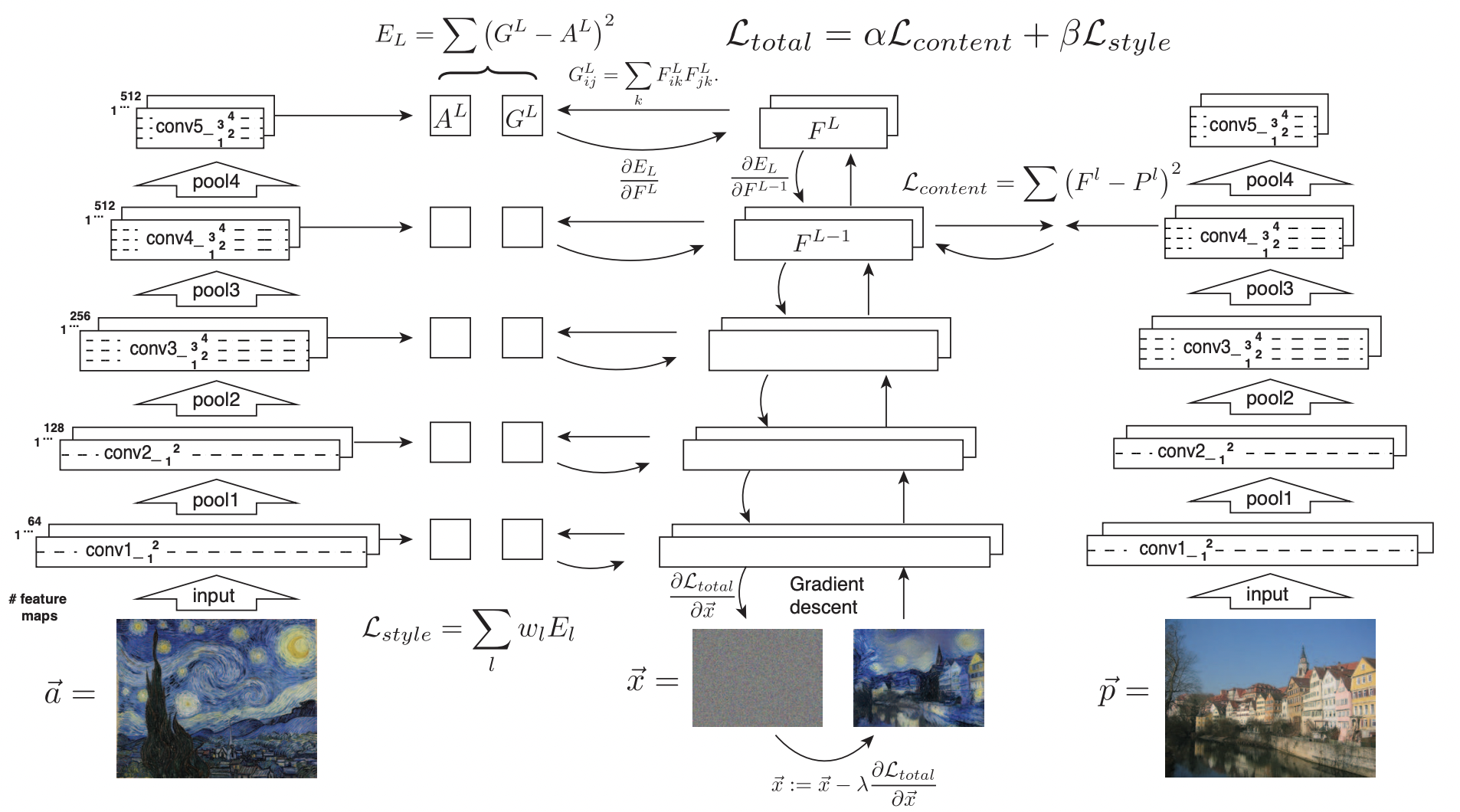
- style 로스는 모든 레이어에 적용되지만 content 로스는 하나의 레이어에서만 적용된다.

- 로스값의 가중치를 어떻게 주는지에 따라 결과 이미지가 달라진다.
- P: 많은수의 모든레이어에서의 forward / backward 과정이 필요하여 매우 느리다.
S: 새로운 neural network을 학습한다.
Fast Neural Style Transfer

- 새로운 Feed forward net을 하나의 스타일으로 학습한다. 입력값은 원본 이미지이고 출력값은 합성된 이미지이다.
- 학습이 끝난 이후에는 Feed forward net을 통과하기만 하면 합성된 이미지를 얻을 수 있다.

- Instance Normalization은 Style Transfer을 위하여 개발되었다.
One Network, Many Styles
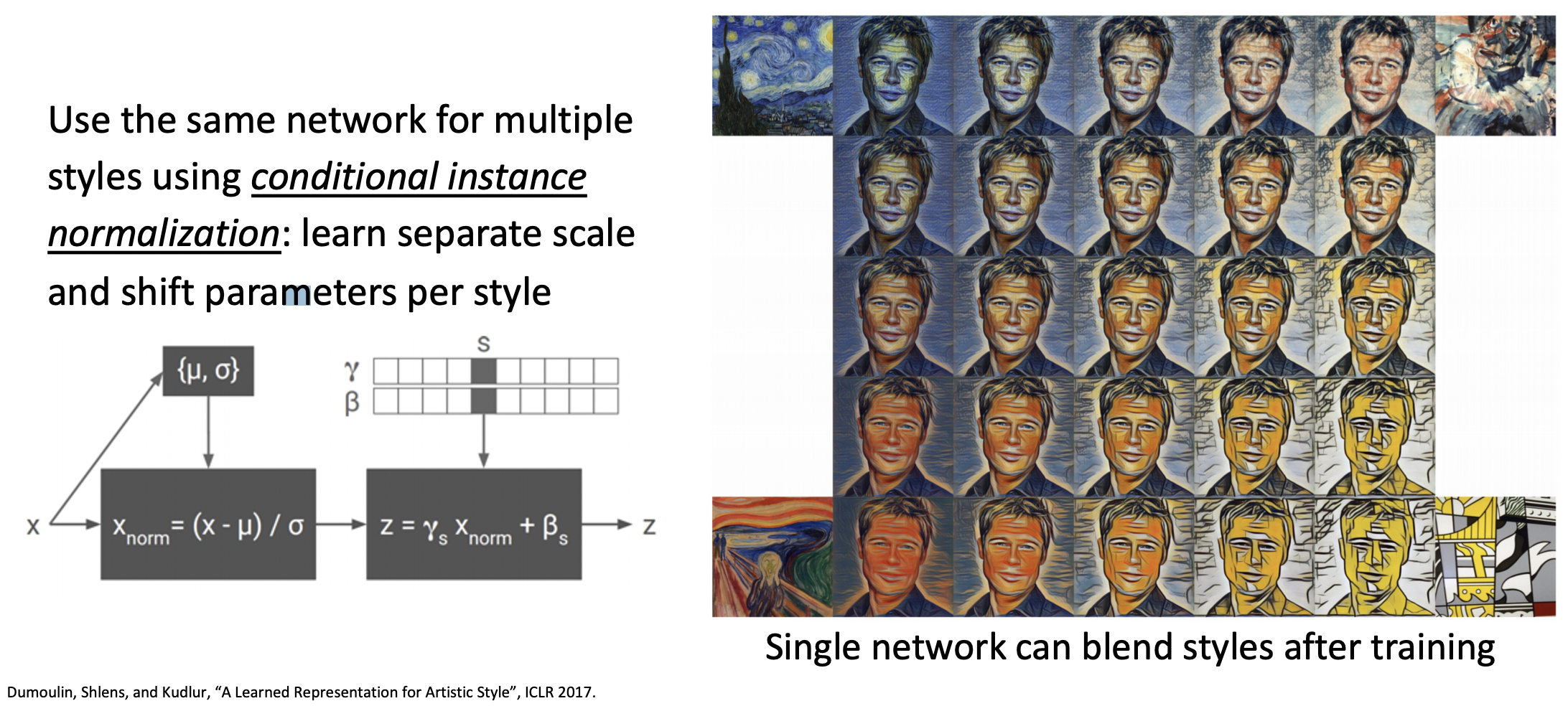
- 모델당 하나의 스타일만 담을 수 있었지만, conditional instance
normalization으로 각 스타일마다 sperate scale & shift parameter을 학습한다. - 단순히 여러 스타일중 하나의 스타일만 선택할뿐 아니라 여러 스타일을 종합하여 나타낼 수도 있다.
참고자료
cs231n 강의 자료
EECS 498-007 / 598-005 2019 강의 자료
Neural Style Transfer 참고
