
1. CONCAT
- 여러 문자열을 하나로 합치거나 연결
select concat('concat',' ','test') #실행결과 concat test
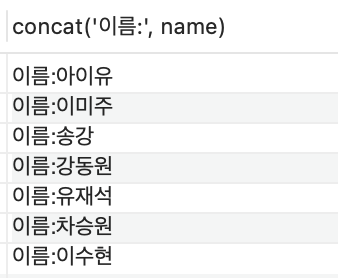
select concat('이름:', name) from celeb;
2. ALIAS
- 칼럼이나 테이블 이름에 별칭 생성
- AS 는 생략이 가능하다.
- 칼럼에 Alias 를 준 경우
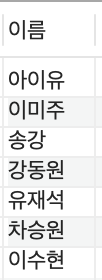
select name as '이름' from celeb;
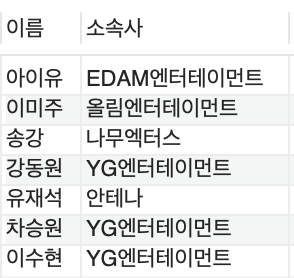
select name as '이름', agency as '소속사' from celeb;
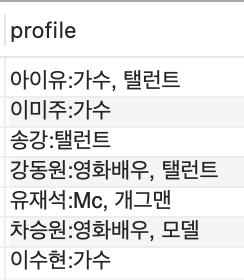
select concat (name,':',job_title) as profile from celeb;
- 테이블에 Alias 를 준 경우
select s.season, s.episode, c.name, c.job_title from celeb c, snl_show as s where c.name = s.host;
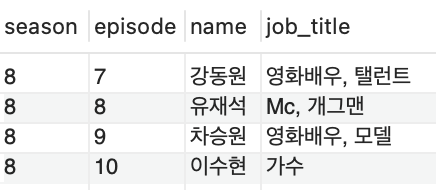
3. DISTINCT
-
검색한 결과의 중복 제거
-
연예인의 소속사 종류를 조회해라(소속사의 종류만 추출해야하므로 중복결과는 제외하고 조회해야하니 distinct가 사용되었다)
select distinct agency from celeb;
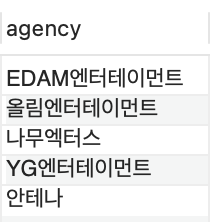
4. LIMIT
-
검색결과를 정렬된 순으로 주어진 숫자만큼만 조회
-
select문의 가장 마지막에 위치하여 조회
-
나이가 가장 적은 연예인 4명을 검색
select * from celeb order by age limit 4;
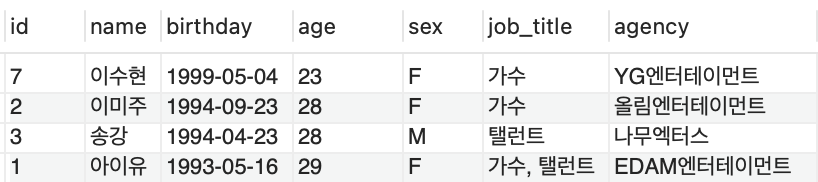
5. ASW RDS(Amazon Relational Database Service)
- AWS에서 제공하는 관계형 데이터베이스 서비스
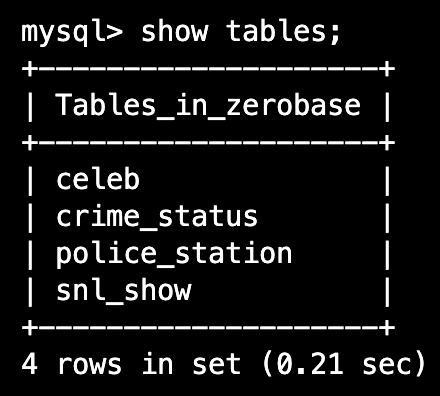
6. SQL file
6-1. Workspace 생성
Document % mkdir sql_ws Document % cd sql_ws sql_ws
6-2. SQL file 생성 방법(두가지)
sql_ws % code . #VSCode 실행
1) 첫번째 SQL file 실행방법
비주얼코드에서 test01.sql 파일을 하나 만듭니다.
% mysql -u root -p zerobase #만들어놓은 zerobase 데이터베이스에 접속 mysql> source test01.sql # SQL file 실행
2) 두번째 SQL file 실행방법
비주얼코드에서 test02.sql 파일을 하나 만듭니다.
% mysql -u root -p zerobase < test02.sql #zerobase 데이터베이스에 접속하면서 test02라는 SQL file을 실행합니다.
7. 데이터베이스 백업(backup)
- 터미널에 접속하여 아래와 같이 코드를 친다
mysqldump -u root -p zerobase > zerobase.sql
만들어놓았던 제로베이스 데이터베이스의 내용을 zerobase.sql로 저장한다는 의미이다. 실행 후 . code 를 입력하여 비주얼코드에서 위 zerobase.sql 파일이 만들어져있으면 정상적으로 백업이 된것이다.
8. 파이썬으로 MySQL에 접속하는 방법
8-0. 환경설정
pip install mysql-connector-python
위 코드를 실행하여 커넥터를 설치해줍니다.
import mysql.connector
설치 후 커넥터를 실행 시켜줍니다. 아무문제없이 작동이된다면 정상적으로 설치가 된 것입니다.
8-1. local 환경에 연결
local = mysql.connector.connect( host ="localhost", user ="root", password ="패스워드입력", database = "zerobase" )
위에서 zerobase라는 데이터베이스로 연결하려면 database 작성을 하면된다.
8-2. AWS RDS(database-1)연결
remote = mysql.connector.connect( host="엔드포인트입력", user ="사용자입력", password="패스워드입력" )
8-3. 연결을 닫아주는 방법
local.close() remote.close()
9. 파이썬으로 MySQL 쿼리 실행
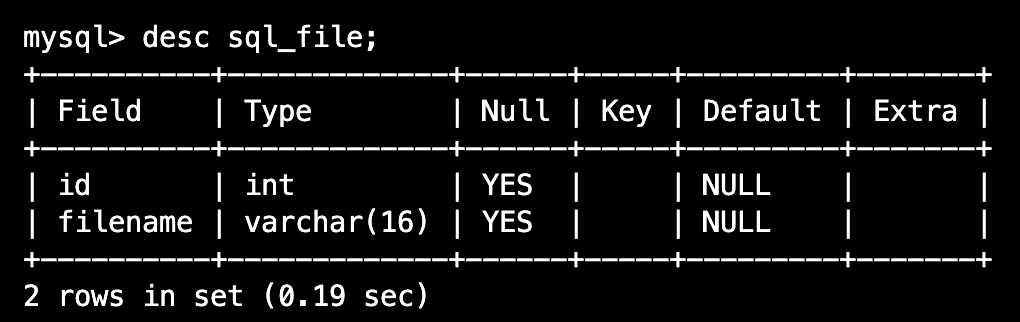
9-1.RDS 서버에 sql_file 이라는 테이블을 생성해보자
remote = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" ) cur = remote.cursor() cur.execute("create table sql_file (id int, filename varchar(16))") remote.close()
다음 코드를 쳐서 서버에 들어가 해당 테이블(sql_file)이 만들어졌는지 확인해보자.
%mysql -h "database-1.cpjnll2kjl1j.us-east2.rds.amazonaws.com" -P 3306 -u admin -p use zerobase; show tables;
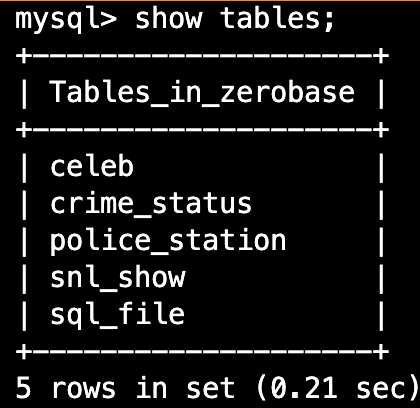
- 만들었던 sql_file 다시 지워보자
remote = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" ) cur = remote.cursor() cur.execute("drop table sql_file") remote.close()
cursor 실행문에 drop table 코드를 쳐서 sql_file을 지웠다.
9-2.RDS 서버에 sql_file 이라는 테이블을 실행해보자
remote = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" cur = remote.cursor() sql = open("test03.sql").read() cur.execute(sql) remote.close()
9-3. 멀티쿼리가 담겨있는 테이블을 실행해보자
- 멀티쿼리가 담겨있는 test04.sql 파일을 만들어보자

- 그다음 아래와같이 코드를 작성하여 실행해본다.
remote = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" cur = remote.cursor() sql = open("test04.sql").read() for result_iterator in cur.execute(sql, multi=True): if result_iterator.with_rows: print(result_iterator.fetchall()) else: print(result_iterator.statement) remote.commit() remote.close()
9-4. Fetch All
-
위에서 쿼리를 실행한 다음에 결과값이 rows을 포함하고 있으면 fetchall을 통해서 실행을 시켰었다. 실행하는 쿼리가 아니라 조회하는 select문을 실행한 경우에는 데이터를 가지고 오는데 그데이터가 있는 경우에는 fetchall을 써서 위의 코드처럼 변수에 담을 수 있다.
-
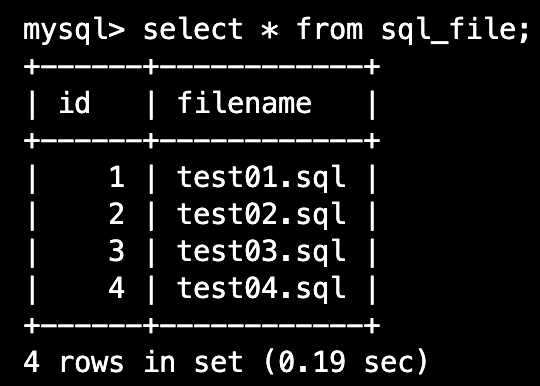
sql_file 테이블을 조회(읽어올 데이터 양이 많은 경우 buffered=True)
1) 환경설정
import mysql.connector
2) 서버설정
remote = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" );
3) 커서설정
- cur라는 변수안에 위에서 만든 서버의 cursor 메소드를 지정해주면서 buffered=True 옵션을 지정하였다. cur.execute실행문으로는 sql_file을 불러오고 result 변수에 cur.fetchall()을 실행시킨 모습이다.
cur = remote.cursor(buffered=True) cur.execute("select * from sql_file") result = cur.fetchall() result #실행결과 [(1, 'test01.sql'), (2, 'test02.sql'), (3, 'test03.sql'), (4, 'test04.sql')]
4) 서버닫기
remote.close()
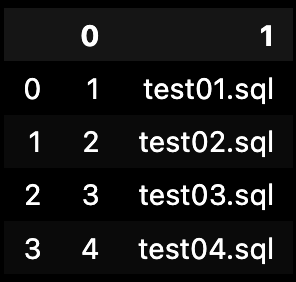
5) 위 검색결과를 pandas 로 읽기(참고)
import pandas as pd df = pd.DataFrame(result) df
10. csv 에 있는 데이터를 파이썬으로 insert
1) 환경설정
import mysql.connector
2) csv데이터 판다스로 열기
- csv 파일을 읽어올때 encoding은 'utf-8' 또는 'euc-kr'로 설정을 해주어야 열릴때 있으니 참고
df = pd.read_csv("police_station.csv") df.tail()

3) zerobase(데이터베이스)에 연결
import mysql.connector conn = mysql.connector.connect( host="엔드포인트입력", port=포트입력, user="사용자입력", password="패스워드입력", database="zerobase" );
4) cursor 만들기
- 읽어올 양이 많은 경우에는 buffered=True 설정을 해줍니다.
cursor = conn.cursor(buffered=True)
5) insert 문 만들기
- 위의 police_station.csv 에서 봤듯이 컬럼명이 두개이고 string 값으로 되어있어 values(%s,%s)라고 지정하였다.
sql = "insert into police_station values (%s,%s)"
6) 데이터 입력
- commit() 은 database에 적용하기 위한 명령어 이다.
for i, row in df.iterrows(): cursor.execute(sql, tuple(row)) conn.commit()
- cursor.execute로 실행할 문장은 위에서 만든 sql이고 이것에 대응하는 데이터를 tuple(row) 형태로 집어넣어준 것이다.
그리고 conn.commit()으로 실행을 시켜주었다.
참고로 tuple(row) 형태를 살펴보면 아래와 같다.
7) 결과확인
- police_station에 있는 내용을 실행시켜 result라는 변수에 fetchall 기능을 이용해서 가져왔다.
cursor.execute("select * from police_station") result = cursor.fetchall() result
8) 검색결과를 pandas로 읽기
df = pd.DataFrame(result) df.tail()

