
1. Primary Key(기본키)
- 테이블의 각 레코드를 식별
- 중복되지 않은 고유값을 포함
- Null 값을 가질 수 없음
- 테이블 당 하나의 기본키를 가짐
1-1 테이블 생성시 Primary Key 생성방법
create table person ( pid int NOT NULL, name varchar(16), age int, sex char, primary key (pid) );
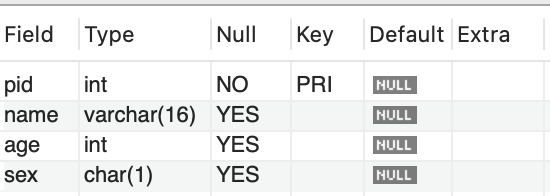
1-2 Primary Key 제거방법
alter table person drop primary key;
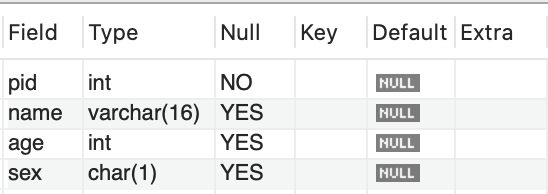
1-3 기존 테이블에 Primary Key 적용방법
alter table person add primary key(pid);
2. Foreign Key(외래키)
- 한 테이블을 다른 테이블과 연결해주는 역할이며,
참조되는 테이블의 항목은 그 테이블의 기본키 (혹은 단일값)
2-1. 테이블 생성시 외래키 생성방법
create table orders ( order_id int not null, order_no varchar(16), pid int, primary key (order_id), constraint FK_person foreign key(pid) references person(pid) );
위에서 만들었던 person 테이블의 pid 컬럼을 기본키로 참조하는 외래키(pid)를 만들었다.
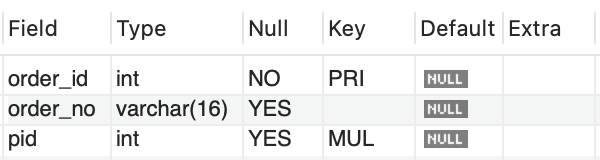
2-2. 테이블 생성시 외래키 생성방법(2)
- constraint 키를 생략하고 외래키를 생성할 수도 있다.
create table job ( job_id int not null, name varchar(16), pid int, primary key (job_id), foreign key (pid) references person(pid) );
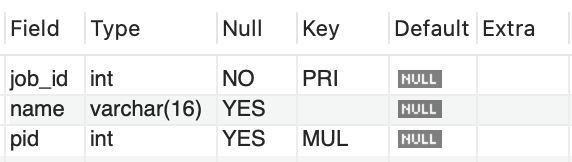
2-3. 외래키 제거 방법
alter table orders drop foreign key FK_person;
2-4. 외래키를 다시 지정 하는 방법
alter table orders add foreign key(pid) references person(pid);
기존테이블에서 기본키나 외래키를 다시 지정하는 방법에는 add가 쓰인다는것에 유념하자
외래키가 제대로 지정되었는지를 확인하려면 아래 코드를 실행하여 내용을 확인해보자
show create table orders;
문장의 중간을 보면 'PRIMARY KEY'부분에 외래키로 person 테이블에서 pid기본키를 참조하고 있다는 내용을 확인 할 수 있다.
'orders', 'CREATE TABLE `orders` (\n `order_id` int NOT NULL,\n `order_no` varchar(16) DEFAULT NULL,\n `pid` int DEFAULT NULL,\n PRIMARY KEY (`order_id`),\n KEY `pid` (`pid`),\n CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `person` (`pid`),\n CONSTRAINT `orders_ibfk_2` FOREIGN KEY (`pid`) REFERENCES `person` (`pid`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci'
2-5. 외래키 실습 예제
- police_station 테이블과 crime_status 테이블을 외래키를 이용하여 연결해보자
1) 터미널에서 서버 접속
%mysql -h 엔드포인트입력 -P 포트입력 -u 사용자입력 -p
2) 테이블 상태 확인
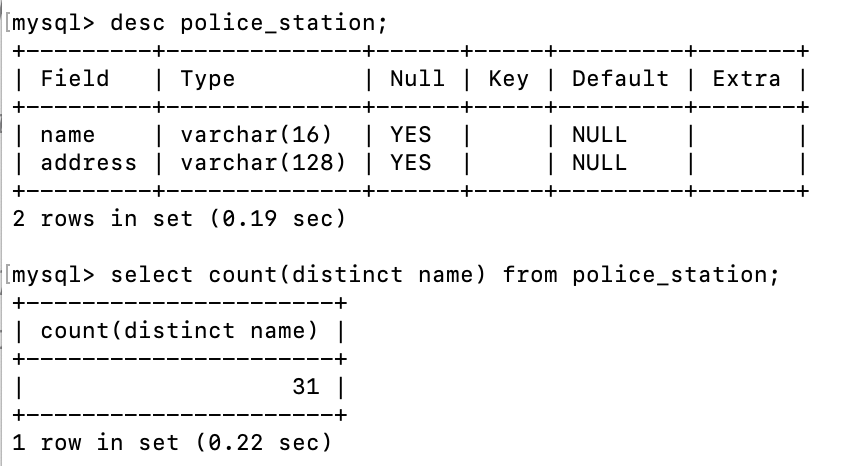
police_station 테이블에서 name컬럼을 중복을 제거했을때 총 31개가 있다는것을 알수 있다.
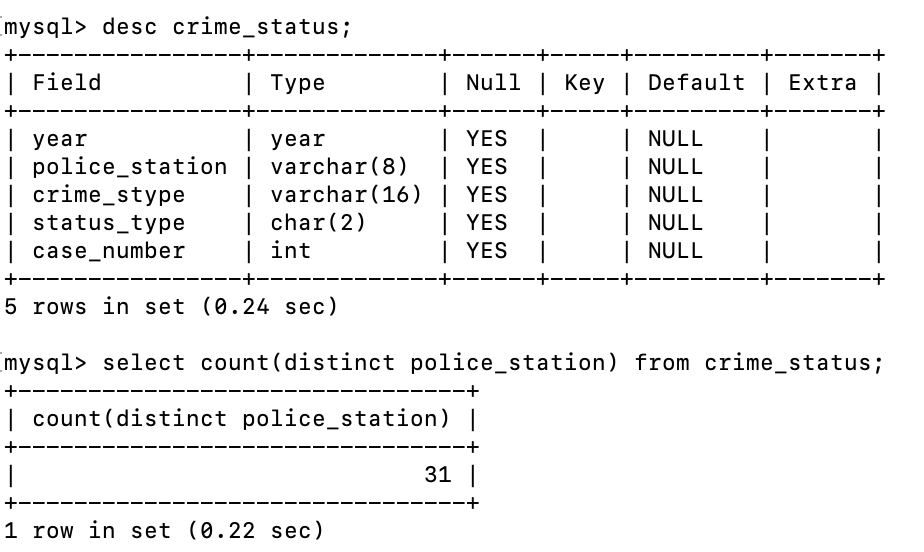
crime_status 테이블의 police_station 컬럼의 중복제거 후 갯수도 31개로 동일한 것을 알 수 있다.

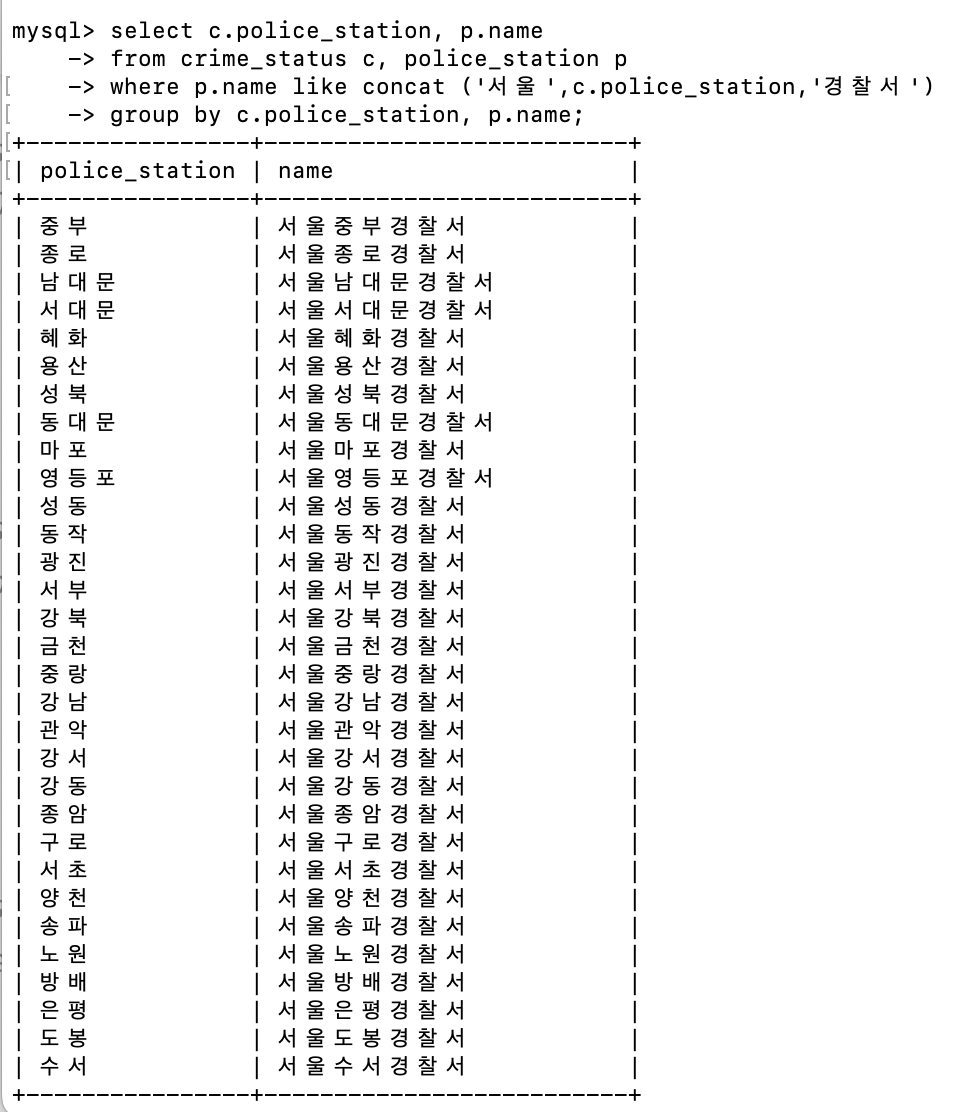
where절에서 concat 을 이용하여 각 테이블의 매칭되는 부분을 확인한 모습이다.
3) police_station 테이블에 기본키 설정
alter table police_station add primary key(name);

4) crime_status 에 외래키 설정
crime_status 테이블에 reference 컬럼을 추가하여 외래키를 설정
alter table crime_status add column reference varchar(16); alter table crime_status add foreign key (reference) references police_station(name);
5) 외래키 설정을 마무리하고 police_station의 name의 내용을 crime_status에 업데이트
update crime_status c, police_station p set c.reference = p.name where p.name like concat('서울',c.police_station,'경찰서');

3. Aggregate Functions(집계함수)

3-1. Count
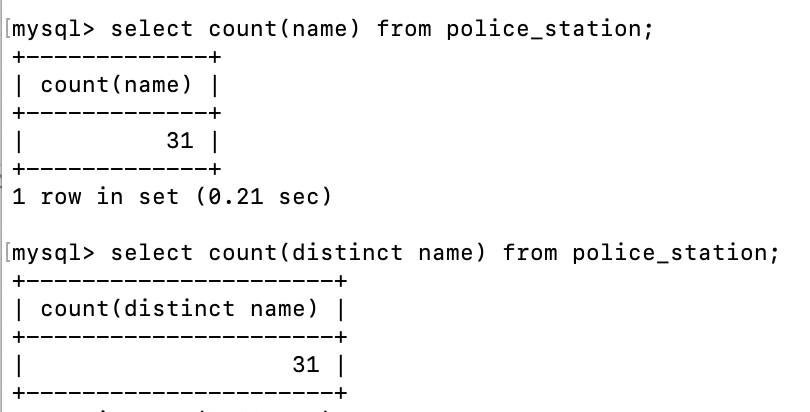
- count는 컬럼의 갯수를 세어주는 함수이다. count(컬럼명)이라고 쓰면 되는데 만약 컬럼안의 데이터에 null 값이 없으면 count(컬럼명), count(distinct 컬럼명) 해줘도 동일한 결과가 나온다.
예를 들어 아래 쿼리의 결과는 동일하게 31개를 반환해준다.
select count(name) from police_station; select count(distinct name) from police_station;
3-2. Group by
- 컬럼을 기준으로 그룹핑해준다.
- crime_status 테이블에서 경찰서별로 그룹화하여 경찰서 이름을 오름차순으로 조회한 결과
select police_station from crime_status group by police_station order by police_station limit 5;

- 경찰서 종류를 distinct 를 사용하여 검색. 위 코드처럼 오름차순으로 검색하고 싶지만 distinct를 사용했을 때 order by 구문은 사용할 수가 없음

3-3. having
- 조건에 집계함수가 포함되는 경우 where대신 having 사용
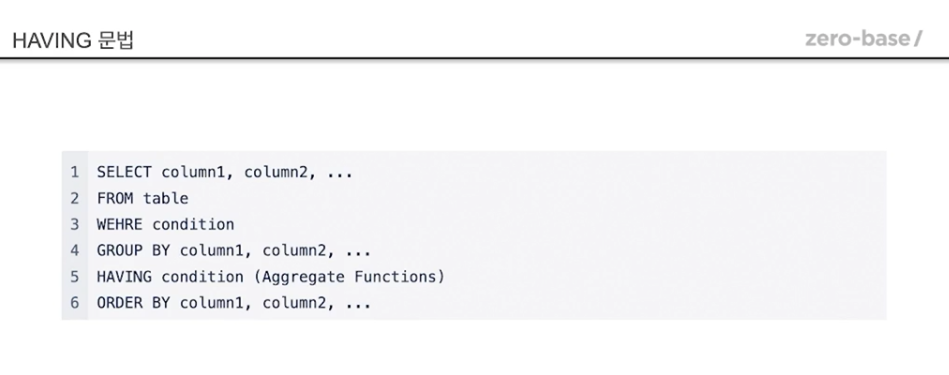
- 경찰서 별로 발생한 범죄 건수의 합이 4000 건보다 큰 경우를 검색
select police_station, sum(case_number) as count from crime_status where status_type like '발생' group by police_station having count > 4000;


우직한 거북이