
(6/5)
오늘은 Extra 과제에 도전해보았다. Extra 과제에 관련한 글을 찾아보니 설명은 거의 없고 단순히 코드만 나와있어서, 그 코드가 도대체 무슨 의도로 쓰인 것인가를 고민하고 분석해가며 공부했다.
덕분에 Extra 과제에 대해 잘 이해하게 되었으니 전화위복이 된 셈이긴 하지만 🙄 이해하기가 쉽진 않았다. 따라서 이번 TIL을 Extra 과제에 대해 자세하게 설명하는 글로 작성해보고자 한다.
- Project 2 Extra 과제에 대한 전반적인 flow를 잡고 싶은 분
- 직접 구현해보진 못했지만 짚고 넘어가고 싶은 분
이런 분들께는 이 글이 상당히 도움이 될 것이다 :)

위의 깃북에 따르면, 기존의 PintOS에서는 stdin과 stdout에 대한 file descriptor(fd)를 닫는 것은 금지되어 있는 상태이다. 따라서 linux 가 수행하는 방식과 마찬가지로 stdin과 stdout을 사용자로 하여금 닫을 수 있도록 구현 해주고, 그에 더불어 fd를 복사해주는 dup2라는 system call까지 구현 하는 것이 이 extra 과제의 목표이다.
- stdin에 대한 fd를 닫아주면, 그 어떤 input도 읽어들이지 않는다.
- stdout에 대한 fd를 닫아주면, 그 어떤 output도 프로세스에 의해 출력되지 않는다.
- dup2 를 구현해 주어진 stdin/stdout/file 에 대한 fd를 fd_table 내에 복사해준다.
위의 3가지를 잘 처리해주어야 만점을 받을 수 있다. 그럼 Let's go!
extra 과제 시작을 위한 초기 설정
추가 과제의 요구사항을 충족하기 위해, 몇 가지 설정해주어야 할 부분이 있다. 구현에 필요한 필드를 구조체에 추가하거나, 변수를 초기화해주는 것이다.
1. struct thread 수정
쓰레드의 fd_table 에 존재하는 STDIN fd, STDOUT fd의 갯수를 담아주는 필드를 추가해준다. dup2를 구현하고 나면, 하나가 아니라 여러 개가 될 수도 있기 때문이다.
struct thread{
...
int stdin_count;
int stdout_count;
...
}2. struct file 수정
해당 file에 대한 fd가 복사된 횟수를 담아주는 필드를 추가해준다. dup2를 구현하고 나면, 원본 외에 여러 개의 복사본이 존재할 수 있기 때문이다.
struct file{
...
int dup_count;
...
}3. STDIN, STDOUT 설정 (이전 글 Remind)
위에서 언급했듯이 dup2를 구현하고 나면, STDIN이나 STDOUT에 대한 fd가 여러 개가 될 수도 있기 때문에 단순히 fd 번호만으론 판별이 어렵다. 따라서 이전에 fd 관련 시스템 콜을 구현할 때 STDIN을 1로, STDOUT을 2로 define 해준 후에 쓰레드를 생성할 때 세팅해주었던 것을 활용해야 한다.
const int STDIN = 1;
const int STDOUT = 2;fd 관련 시스템 콜에 대한 글을 읽지 않았다면, STDIN에 대한 최초의 fd는 0이고 STDOUT에 대한 최초의 fd는 1인데 여기선 왜 1,2로 세팅했을까? 라는 의문이 들 것이다.
'f==NULL' 이란 조건을 확인해 에러 처리를 내주도록 하는 여러 시스템 콜을 고려해보자. fd가 0인 경우, 즉 fd_table[0]에 넣어주는 STDIN이 0이라면, if (f==NULL) 에 매번 걸려 에러처리가 되어버릴 것이다. 따라서 0이 아닌 값으로 넣어주다보니 1씩 밀어서 0,1 -> 1,2 로 설정해주는 방법으로 선회한 것이다.
4. stdin_count, stdout_count 필드 초기화
stdin_count와 stdout_count를 1로 초기화해준다. thread 내 fd_table에는 최초에 하나씩의 STDIN, STDOUT을 설정해주었으니, count 역시 1씩 설정해주면 되겠다.
tid_t thread_create(const char, int, thread_func, void){
...
t->fd_table[0] = 1; // STDIN
t->fd_table[1] = 2; // STDOUT
t->stdin_count = 1;
t->stdout_count = 1;
...
}DUP2 구현
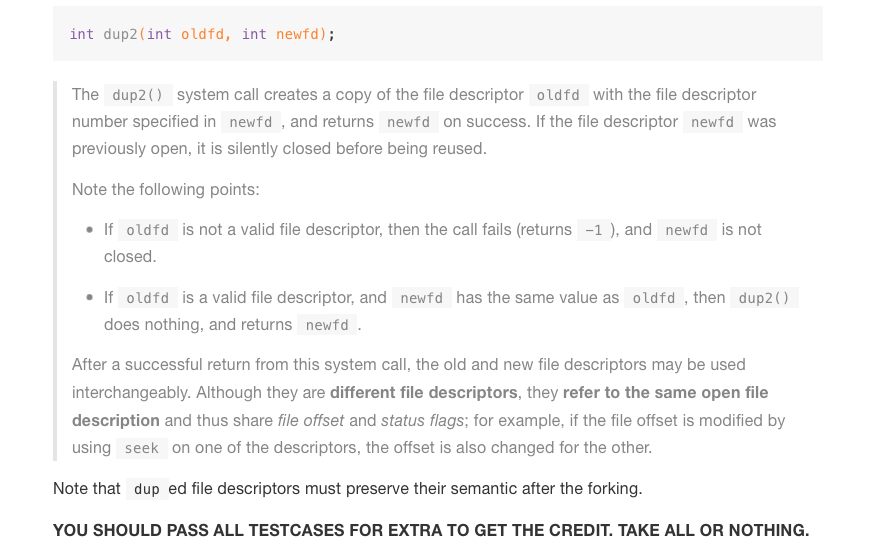
dup2는 oldfd 의 복사본을 newfd 에 생성해주는 함수이다.
 다만, 다음의 2가지 경우에는 굳이 복사본을 생성할 필요가 없다.
다만, 다음의 2가지 경우에는 굳이 복사본을 생성할 필요가 없다.
- oldfd가 유효하지 않은 경우 (case 1)
- oldfd가 유효하지만, newfd에 이미 동일한 값이 담겨있는 경우 (case 2)
따라서 dup2 함수를 구현할 때, 아래와 같이 두 케이스를 순서대로 처리해주자.
int dup2(int oldfd, int newfd)
{
struct file *f = process_get_file(oldfd);
if(f==NULL) return -1; /* case 1 */
if(oldfd == newfd) return newfd; /* case 2 */
...
초기에 설정한 2가지 if문에 걸리지 않은 경우엔, 현재 실행중인 쓰레드의 파일 디스크립터 테이블에 newfd에 복사본을 넣어줘야 한다. 따라서 current thread 와 그의 fd_table을 가져와주자!
...
struct thread *curr = thread_current();
struct file **curr_fd_table = curr->fd_table;
...이 때 생각해보아야 할 점은, 복사하게 되는 f의 종류가 도대체 무엇 이냐는 것이다.
2<=fd<FDCOUNT_LIMIT 인 경우엔, process_get_file을 통해 가져온 f는 file 구조체 타입의 어떤 파일에 해당한다. 하지만 fd가 0이거나 1인 경우엔, 각각 STDIN 혹은 STDOUT에 해당하는 파일 디스크립터이다. 따라서, 조건을 나눠주자.
...
if(f==STDIN){
curr->stdin_count ++;
}
else if(f==STDOUT){
curr->stdout_count ++;
}
else{
f->dup_count++;
}
...보다시피 f가 STDIN이거나 STDOUT이면, 현재 쓰레드(curr)의 stdin_count 혹은 stdout_count를 늘려주었다. 그 외에 일반 파일인 경우엔, 그 파일(f)자체의 dup_count를 늘려주면 되겠다.
...
close(newfd);
curr_fd_table[newfd] = f;
return newfd;
...이후엔 깃북에 언급된대로, newfd가 이전에 사용되고 있던 경우엔 재사용 전에 살포시 닫히도록 (silently closed before being reused) 처리해준다. 그리고 나서 newfd에 oldfd에 있던 f를 복사해주고, 성공했으니 newfd를 리턴해주는 것이다.
이렇게 완성한 dup2의 최종 코드는 다음과 같다.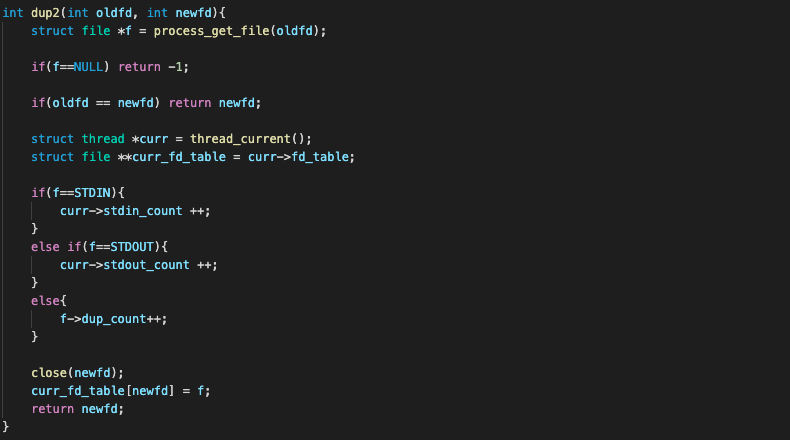
dup2 구현을 마쳤으니 닫고(close), 읽고(read), 쓰는(write) 경우에도 stdin_count, stdout_count, dup_count를 활용해 적절한 처리를 할 수 있도록 조정해주자.
CLOSE 수정
파일을 복사해주는 함수가 파일의 타입에 따라 3가지 count 중 하나를 증가시킨다면, close에서는 그 반대 동작을 수행 해줄 수 있어야 할 것이다. 따라서, close를 수정해보자.
extra 과제 구현 전의 close 는 다음과 같다.
void close (int fd){
struct file *f = process_get_file(fd);
if(f == NULL)
return;
if(fd < 2) return;
process_close_file(fd);
file_close(f);
}보다시피 STDIN이나 STDOUT에 해당하는 경우(fd<2)에는 닫지 않고 return 하도록 했기에, 현재로썬 글의 초반부에 언급했듯이 'stdin과 stdout에 대한 file descriptor(fd)를 닫는 것은 금지되어 있는 상태' 이다.
따라서 이 close 함수를 수정해서 인자 'fd'에 STDIN과 STDOUT이 들어오는 경우에는 현재 쓰레드의 stdin_count나 stdout_count를 하나 줄이도록 만들어주자.
참고로 단순히 하나의 STDIN fd를 닫고 stdin_count를 하나 줄인다고 해서 바로 STDIN 자체를 닫는 것은 아니다. 앞서 dup2를 구현해줌으로써 한 쓰레드 내의 fd_table이 하나의 STDIN fd가 아니라 복수의 STDIN fd들을 가질 수 있고, 그런 경우엔 stdin_count > 1 이기 때문이다 😙 (우리는 stdin_count == 0 이 될 때에야 비로소 STDIN을 닫게 될 것이다!)
...
struct thread *curr = thread_current();
if(fd==0 || f==STDIN)
curr->stdin_count--;
else if(fd==1 || f==STDOUT)
curr->stdout_count--;
...
if(fd < 2 || f <= 2){
return;
}
...if문에 fd==0 외에 f==STDIN 인지 확인해주는 것도, STDIN이 복사되었을 경우를 함께 고려하기 위함이다. 만약 이전에 dup2(0,7) 이 수행되었다고 가정하고, 이후에 close(7) 을 수행하는 상황이라면 fd==0이 아니라 f==STDIN 에서 걸릴 것이기 때문이다.
STDOUT 역시 동일한 이유로 f==STDOUT 까지 함께 확인해주어야 한다. 또한, fd < 2 일 때만 리턴해주던 것 역시 f<=2 일때의 경우도 포함하도록 변경해주어야 한다.
...
if(f->dup_count == 0){
file_close(f);
}
else{
f->dup_count--;
}
...한편 dup2를 구현함으로써 한 쓰레드의 fd_table 내에 동일한 파일이 여러 번 복사되었을 수 있기에, 일반 파일에 대해서도 close 처리를 변경해주어야 한다. 따라서, 위와 같이 dup_count(복사횟수)==0 인 경우, 즉 f 외에는 복사본이 없는 경우에만 최종적으로 file_close(f)로 닫아주고, 그 외에 경우에는 dup_count만 1씩 줄이도록 변경해주면 된다.
최종적으로 수정된 close 함수는 아래와 같다.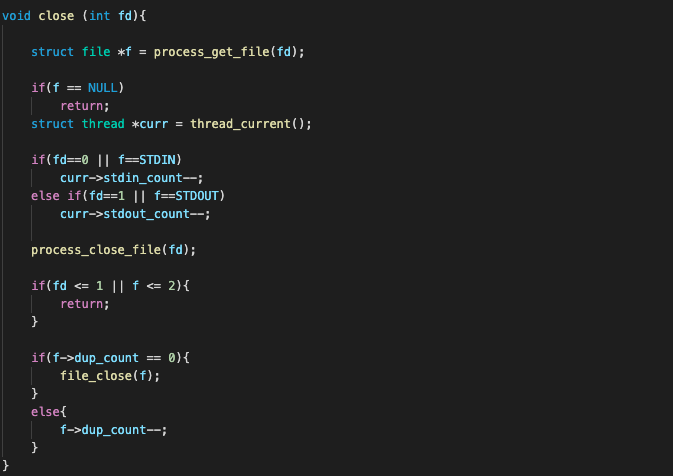
READ 수정
read 함수에서는, 위에서 구현한 dup2와 close에서 관리해온 stdin_count 필드를 확인하는 식으로 변경해주면 된다. 만약 stdin_count == 0 이면 더 이상 열려있는 STDIN fd가 없다는 뜻이므로, extra 과제 목표에 걸맞게 그 어떤 input도 읽어들이지 않도록 해주는 것이다.
...
if (f == STDIN){
if(curr->stdin_count == 0){
NOT_REACHED();
process_close_file(fd);
readsize = -1;
}
else{
for (readsize = 0; readsize < size; readsize++){
char c = input_getc();
*buf++ = c;
if (c == '\0')
break;
}
}
}
...따라서, 원래 read 함수에서 fd==0 인 경우라면 무조건 실행했던 input_getc()가 포함된 for문을, stdin_count가 0이 아닌 경우에만 조건부로 실행되도록 수정해주었다. stdin_count가 0인데 STDIN을 read하도록 요청한 경우엔, 읽어들인 사이즈인 readsize를 -1로 설정해 리턴함으로써 해당 READ 시스템 콜이 잘못되었음을 알렸다.
최종적으로 수정된 read 함수는 아래와 같다.
WRITE 수정
write 함수도 read 함수와 비슷하다. 만약 stdout_count == 0 이면 더 이상 열려있는 STDOUT fd가 없다는 뜻이므로, extra 과제 목표에 걸맞게 그 어떤 output도 내주지 않도록 조정해주는 것이다.
if (f == STDOUT){
if(curr->stdout_count == 0){
NOT_REACHED();
process_close_file(fd);
writesize = -1;
}
else{
putbuf(buffer, size);
writesize = size;
}
}원래 write 함수에서 fd==1 인 경우라면 무조건 실행했던 putbuf()를, stdout_count가 0이 아닌 경우에만 조건부로 실행되도록 수정해주면 된다. stdout_count가 0인데 STDOUT을 write하도록 요청한 경우엔, 작성해준 크기인 writesize를 -1로 설정해 리턴함으로써 해당 WRITE 시스템 콜이 잘못되었음을 알렸다.
최종적으로 수정된 write 함수는 아래와 같다.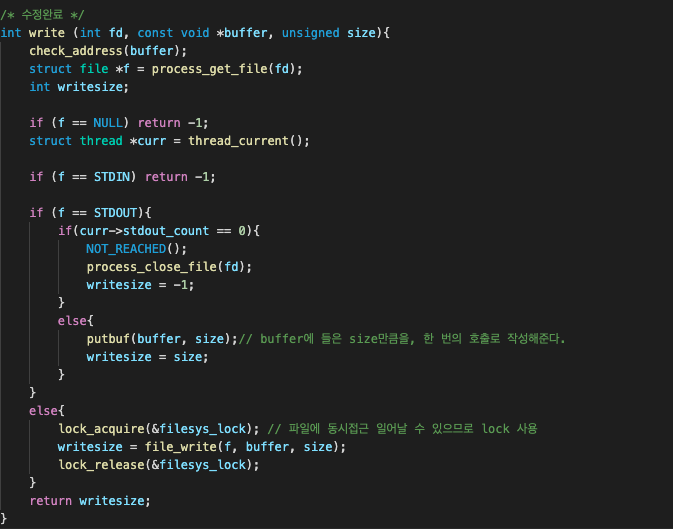
FORK 수정

깃북을 살펴보면, dup2 이후 oldfd와 newfd는 혼용되어 사용될 수 있게 된다고 한다. 서로 다른 파일 디스크립터이지만, 같은 open file description을 참조하고 offset과 status flag까지 공유하게 되는 것 이다. 만약, seek 시스템 콜을 통해 한 fd의 offset을 변경했으면 동일한 open file을 참조하는 다른 fd의 offset도 바뀌게 된다고 한다.
이런 내용을 반영하기 위해선, 어떤 부모 쓰레드가 fork를 호출해 자식 쓰레드를 만들고 fd_table을 복사해줄 때도, 이러한 조건이 유지되도록 해주어야 한다. 이를 위해서 fork 에서 중요 역할을 담당하는 __do_fork 함수를 수정해보자.
static void __do_fork (void){
...
const int DICTLEN = 100;
struct dict_elem dup_file_dict[100];
int dup_idx = 0;
...
먼저 위의 3가지를 함수 내에 선언해준다. 이 dup_file_dict 구조체(사전)의 역할은, 부모의 fd_table을 복사해오는 과정에서 동일한 파일에 대해 복사본을 중복해서 만들지 않도록 사전에 방지 해주는 것이다.
만약 어떤 원본 파일을 file_duplicate()함수를 통해 복사했다면, 원본(부모)을 key로, 복사본(자식)을 value로 구성해 사전에 넣어두자. 이렇게 해주면, fork를 통해 부모 쓰레드의 fd_table을 그대로 복사해오는 자식 쓰레드의 경우에도, 여러 개의 fd가 동일한 오픈 파일에 대해 생성되도록 할 수 있다.
int MAPLEN = 10; // why?다만, 정글뿐만 아니라 PintOS를 거쳐간 사람들이 'MAPLEN=10' 이런 식으로 이 사전의 길이를 10으로 설정해주었던데, 그 이유가 무엇인지 잘 모르겠다. 나의 경우엔, FDCOUNT_LIMIT-1 을 설정해주니까 몇 가지 테스트 케이스에서 FAIL이 났지만, 100 을 넣어도 잘 수행되어서 최종적으론 100을 선택했다. (당연히 10개 저장해두는 것보단, 100개 저장해두는 것이 성능 면에서 훨씬 나을 것이다)
왜 FDCOUNT_LIMIT-1 이 에러가 나는지는 Extra 과제에 있어 유일하게 풀지 못한 궁금증이다. 추측하기로는, fd_table에 공간을 할당해주는 palloc_get_page() 함수에서 내어주는 크기가 생각보자 작은데서 기인하는 것 같다. Project 3을 진행하다보면 더 자세한 내용을 파악할 수 있지 않을까 기대해본다 :)
for(int i = 0; i < FDCOUNT_LIMIT; i++){
struct file *f = parent->fd_table[i];
if (f==NULL) continue;
bool is_exist = false;
for (int j = 0; j <= dup_idx; j++){
if (dup_file_dict[j].key == f){
current->fd_table[i] = dup_file_dict[j].value;
is_exist = true;
break;
}
}
if (is_exist)
continue;
...
}
}위의 코드를 보면, dup_file_dict 에 해당 원본 파일(key)을 복사한 적이 있는지를 검증한다. 만약 해당 key값이 존재하여 복사본(value)이 들어있다면, file_duplicate() 를 한번 더 하는 대신, 단순히 그 동일한 복사본(value)을 자식 쓰레드의 fd_table 에 그대로 넣어주도록 하는 것이다. 그리고 is_exist 를 true로 설정하고, 탐색을 빠져나온다. 이때는 이미 current->fd_table[i] 에 값을 잘 넣어주었으니, parent의 다음 fd를 복사할 수 있도록 바로 continue 로 넘겨주게 된다.
for(int i = 0; i < FDCOUNT_LIMIT; i++){
...
if (is_exist)
continue;
struct file *new_f;
if (f>2)
new_f = file_duplicate(f);
else
new_f = f;
current->fd_table[i] = new_f;
if(dup_idx<DICTLEN){
dup_file_dict[dup_idx].key = f;
dup_file_dict[dup_idx].value = new_f;
dup_idx ++;
}
}만약 dup_file_dict 에 대한 is_exist 가 false라면, 해당 원본에 대한 복사본을 생성한 적이 없다는 것이니까, 복사본을 생성해준다. 이 때, STDIN이나 STDOUT이 아니라 일반 파일인 경우엔 file_duplicate() 를 호출해 복사해주자.
이후에 current->fd_table[i] 에 복사본을 넣어주고, 아직 dup_file_dict 에 여유공간이 있는 경우엔 key(원본)-value(복사본) 세트를 추가해주자. 이렇게 사전에 추가해주면 이후엔 중복된 복사본을 생성하는 것을 방지할 수 있다.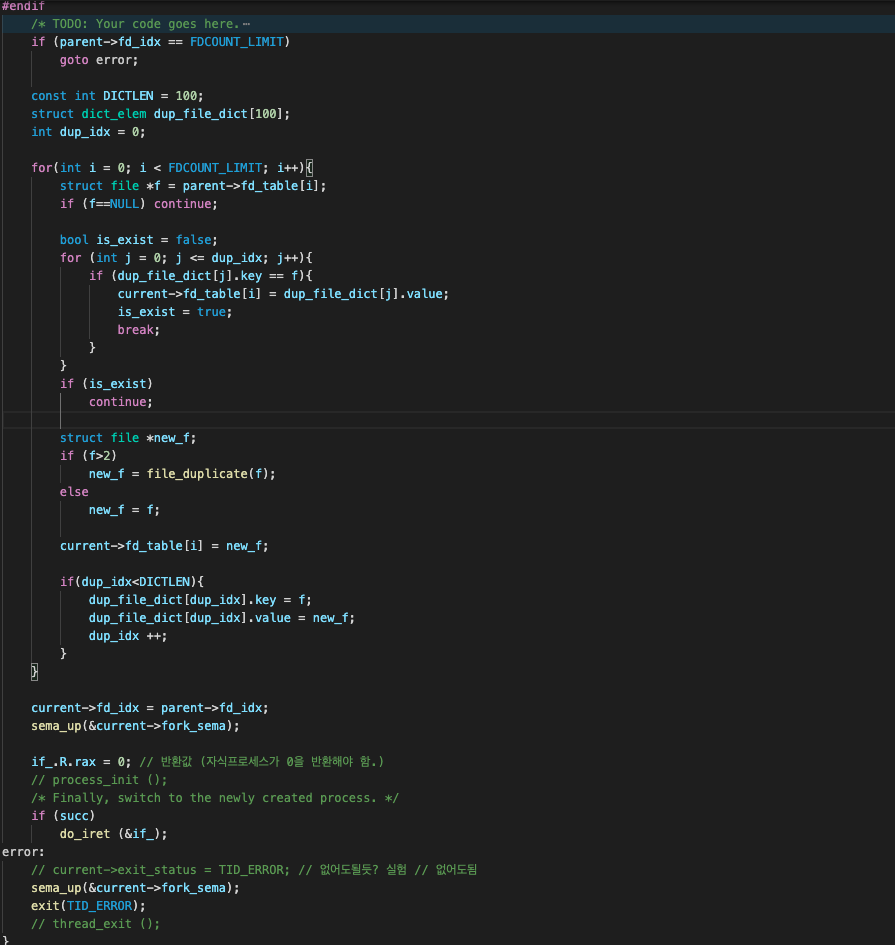 이렇게 해서 수정한 __do_fork 함수는 위와 같다. 참고로 #endif는 #ifdef VM과 한쌍인 #endif 이다.
이렇게 해서 수정한 __do_fork 함수는 위와 같다. 참고로 #endif는 #ifdef VM과 한쌍인 #endif 이다.
Extra 과제 채점 (MAKEFILE 수정)
 드디어 다 왔다! 마지막 단계이다 :)
드디어 다 왔다! 마지막 단계이다 :)
userprog/Make.vars 를 열어보면, 맨 아래에 세 줄이 주석처리 되어있다.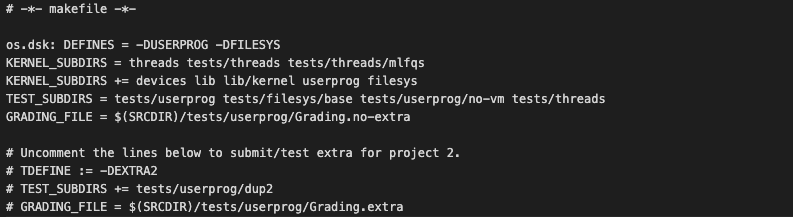
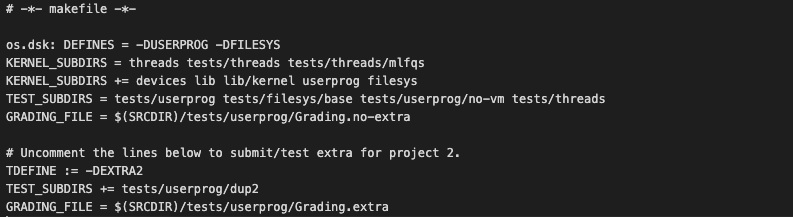 위와 같이, 마지막 3줄 앞에 있는 #을 제거해서 주석처리를 해제해주자.
위와 같이, 마지막 3줄 앞에 있는 #을 제거해서 주석처리를 해제해주자.
이후에 src/userprog 에서 $make 및 $make check 를 해주었더니,
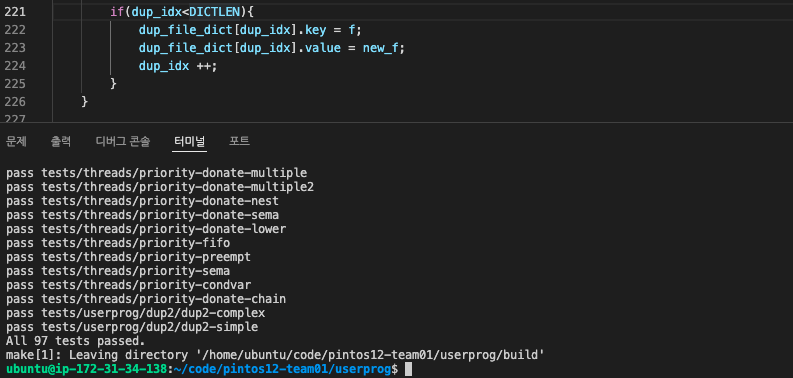 Extra 과제 구현 후에도 다시 한 번 all pass! 를 볼 수 있었다 🙆♂️
Extra 과제 구현 후에도 다시 한 번 all pass! 를 볼 수 있었다 🙆♂️
마무리
앞서 언급했듯이 Extra 과제에 대해 상세히 설명한 포스팅을 찾지 못해서, 이번 프로젝트가 일찍 끝나면 내가 작성해야겠다고 다짐했었다. 그 다짐을 이렇게 지킬 수 있어서 기쁘다 :) 누군가에겐 도움이 되는 글이길 바라며 작성한 글이지만, 정리하면서 나도 다시 한 번 애매했던 점들을 짚어볼 수 있어서 너무 좋다.
이번에는 TIL을 꾸준히 작성했기에, WIL에서는 간단히 이번 프로젝트를 돌아보며 마무리 해야겠다:)

그저 빛주형✨