[Python] pdf2text : PyPDF2
Introduction
프로젝트를 진행하다보니 백엔드 단에서 PDF 처리 기능이 필요할듯 하여 미리 연습해보았다. 서비스를 위해 ChatGPT 외에도 다양한 언어 모델을 테스트해보고 있는데 이번엔 Bard를 한번 사용해보기로 했다. PyPDF2 라이브러리의 존재는 조사를 통해 알고 있었고 코드도 어느정도 작성해놓은 상태였다. 문득 Bard가 과연 올바른 코드를 작성해줄 수 있을지 궁금해서, 한번 시켜보았다.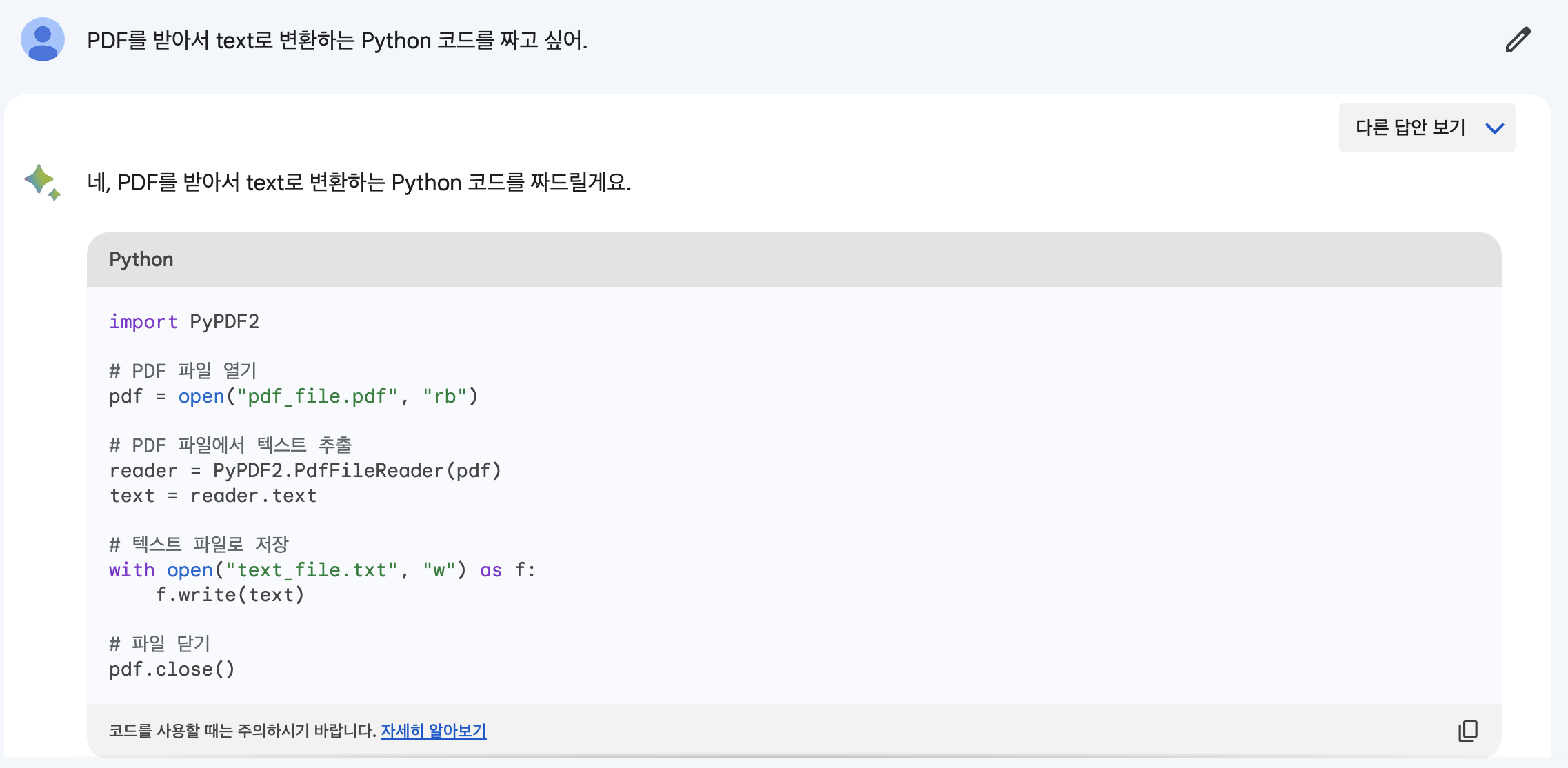 이렇게 Bard가 내놓은 코드를 기반으로 간단한 함수를 작성하고,
이렇게 Bard가 내놓은 코드를 기반으로 간단한 함수를 작성하고,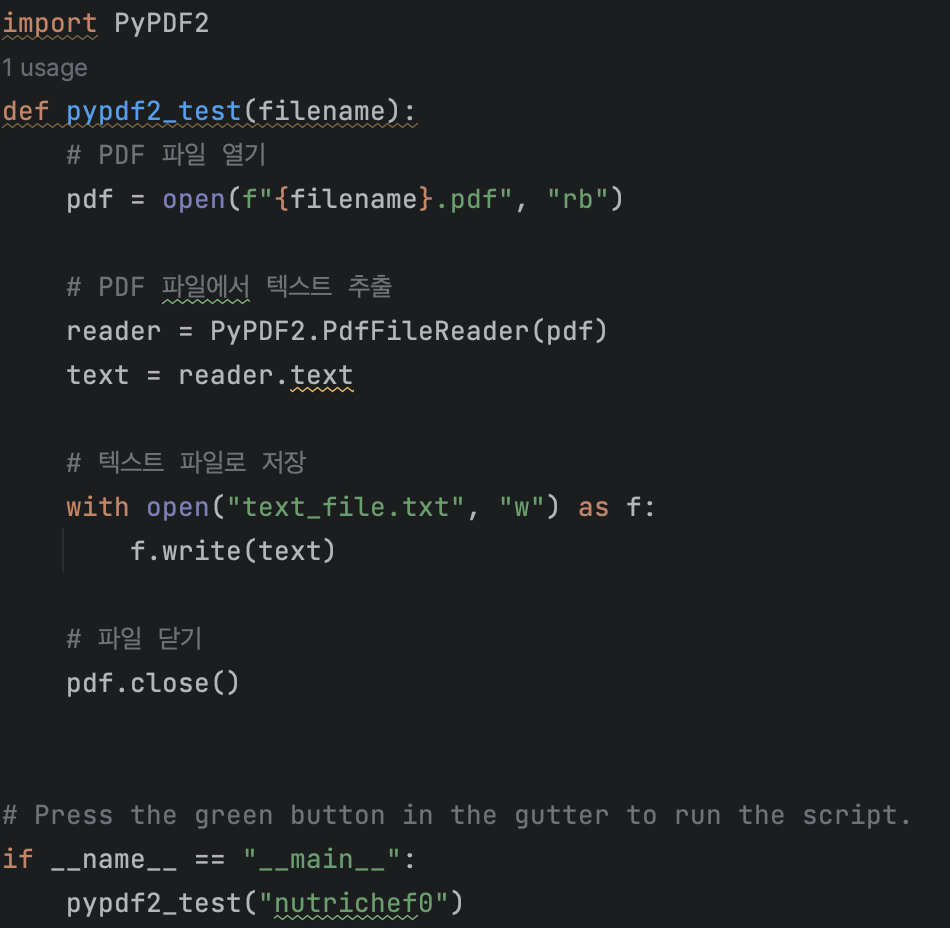 테스트를 돌려보았다.
테스트를 돌려보았다.
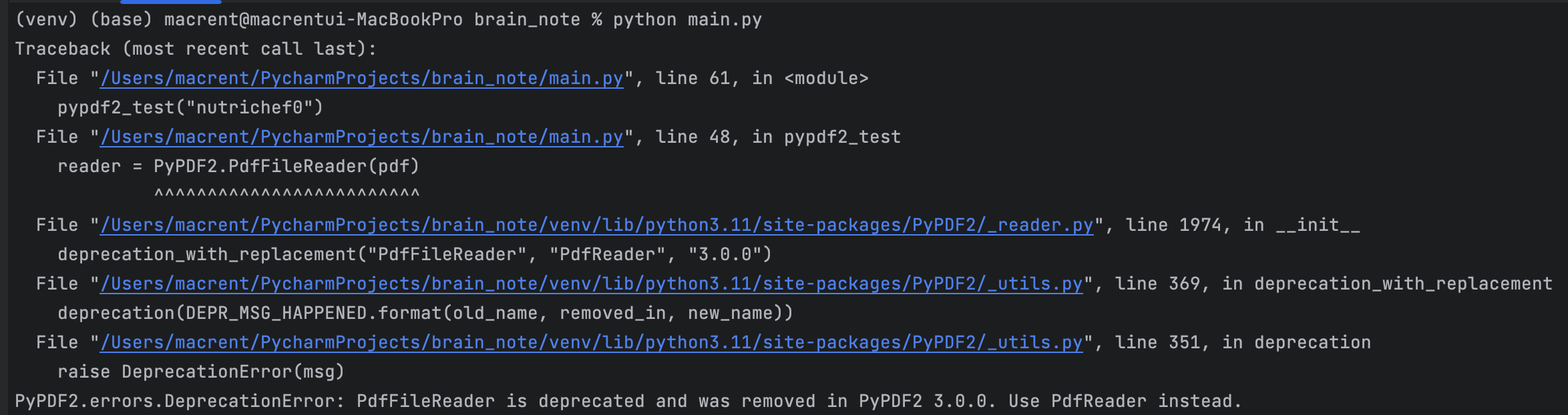 펑! PdfFileReader 라는 함수는 3.0.0에 deprecated 및 removed 되었다고 한다. 찾아보니 3.0.0 버전은 2022년 12월에 릴리즈되었음을 알 수 있었다. 블로그 레퍼런스들을 봐도 2022년 혹은 그 이전에 작성된 글이 많아서 만족스러운 코드를 찾을 수 없었다.
펑! PdfFileReader 라는 함수는 3.0.0에 deprecated 및 removed 되었다고 한다. 찾아보니 3.0.0 버전은 2022년 12월에 릴리즈되었음을 알 수 있었다. 블로그 레퍼런스들을 봐도 2022년 혹은 그 이전에 작성된 글이 많아서 만족스러운 코드를 찾을 수 없었다.
그래서 변경사항을 확인하며 그냥 하나하나 직접 바꾸어 작성해보았다.
How to use PyPDF2 (Version : 3.0.1)
이번 기회에 PyPDF2를 사용하고 싶은 사람이나, 이전 버전의 PyPDF2를 사용 중이었지만 3.0.0 이상의 버전으로 업그레이드를 원하는 사람들에게 도움이 되길 바라며...
- Bard에서 내어준 옛날 코드에서는 한번에 텍스트를 추출해야 하지만, 3.0.0 버전에서는 한 번에 추출하는 기능이 보이지 않는다. (추가 확인 중)
- 텍스트를 추출하기 전에, 우선 페이지 번호를 기준으로 특정 페이지에 대한 객체를 가져와야 한다. Bard가 준 코드 상의 버전에서는 reader.getPage(페이지번호)로 가능했으나, 이제는 reader.pages[페이지번호] 로 가능하다. 눈치챘겠지만 reader.pages 는 List로 주어지고, 각 페이지에 대한 객체가 담겨있다.
- 3.0.0 버전에서 각 페이지의 텍스트는 extract_text() 라는 함수를 통해 뽑아낼 수 있다.
이러한 사항을 반영하여 새로 작성한 코드는 다음과 같다. 테스트용 코드로 작성한 것이라, txt 파일로 추출하는 대신 stdout으로 출력해서 확인 가능하도록 하였다. txt 파일로 추출하기 원하면 위의 Bard가 준 코드에서 with open("파일명.txt", "w") as f: 구문 하위에 for문이 들어가도록 하면 될 것이다.
def pypdf2_test(filename):
# open PDF File
pdf = open(f"{filename}.pdf", "rb")
# PDF to Text
reader = PyPDF2.PdfReader(pdf)
reader.pages
total_pages = len(reader.pages)
# Check text in each page
for page_no in range(total_pages):
print(f"\n\n**** PAGE {page_no + 1} ****\n\n")
now_page = reader.pages[page_no]
txt = now_page.extract_text()
print(txt)
# Close PDF File
pdf.close()nutrichef0.pdf

위의 pdf파일을 input으로 넣어줬고, 새로 작성한 함수를 실행해보았다.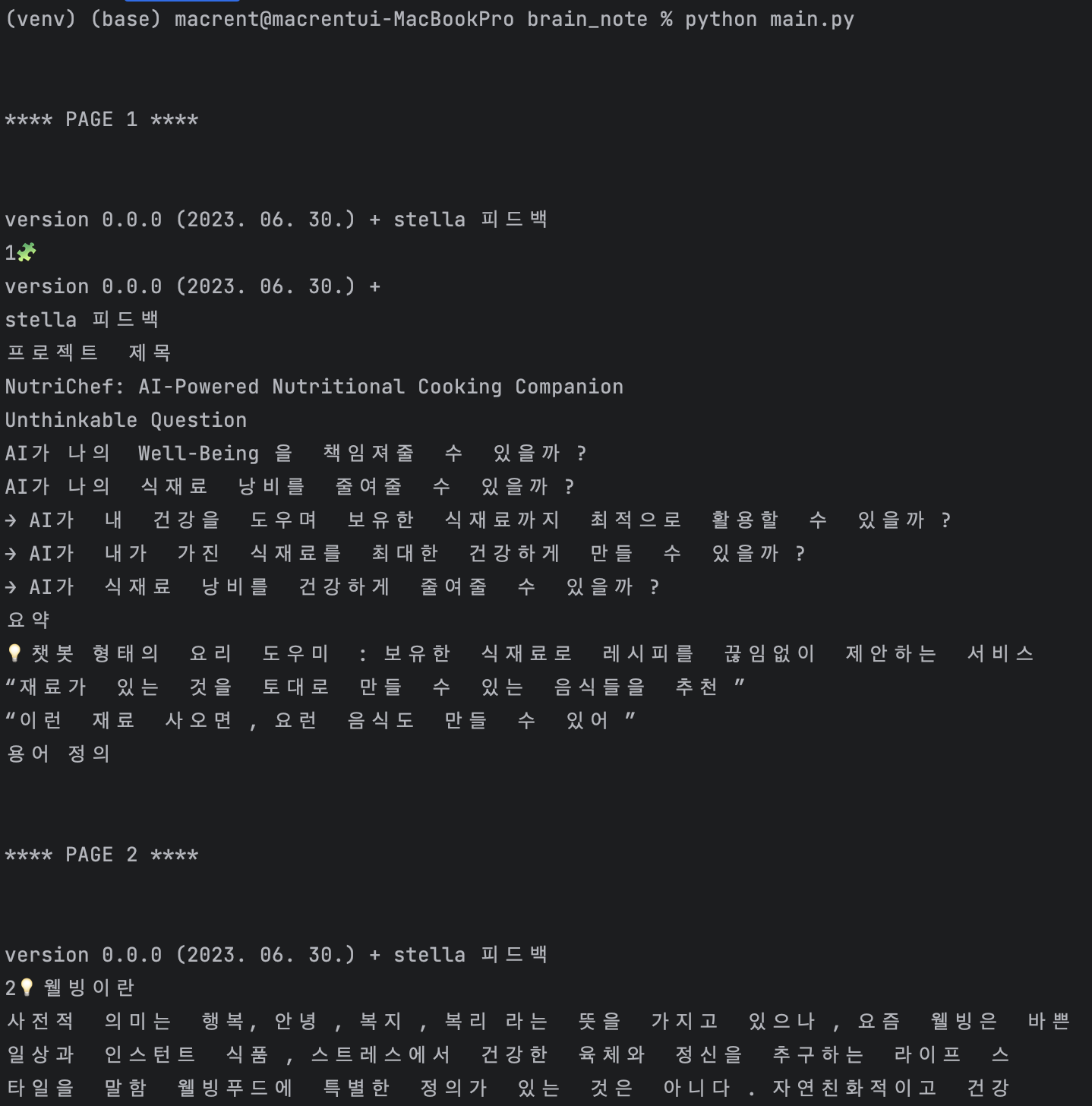 다음과 같이 텍스트가 정상적으로 출력됨을 확인할 수 있다.
다음과 같이 텍스트가 정상적으로 출력됨을 확인할 수 있다.
