간단한 근황
매주 필기테스트, 코딩테스트, 서류 등으로 정신이 없는 나날을 보내고 있다. 그래도 꾸준하게 알고리즘 문제를 풀고 있어서인지 코딩테스트에선 나름 선방 중이다. 모든 코딩테스트가 끝나면 중간점검을 한번 하려 했으나 자꾸 새로운 코딩테스트가 생겼다. 내일모레 하나 응시하고 나면 일단은 더 이상은 없기에, 주말에 한번 정리해보려고 한다.
알고리즘
오늘 풀어본 문제 중 흥미로웠던 문제는 예산이라는 문제이다.
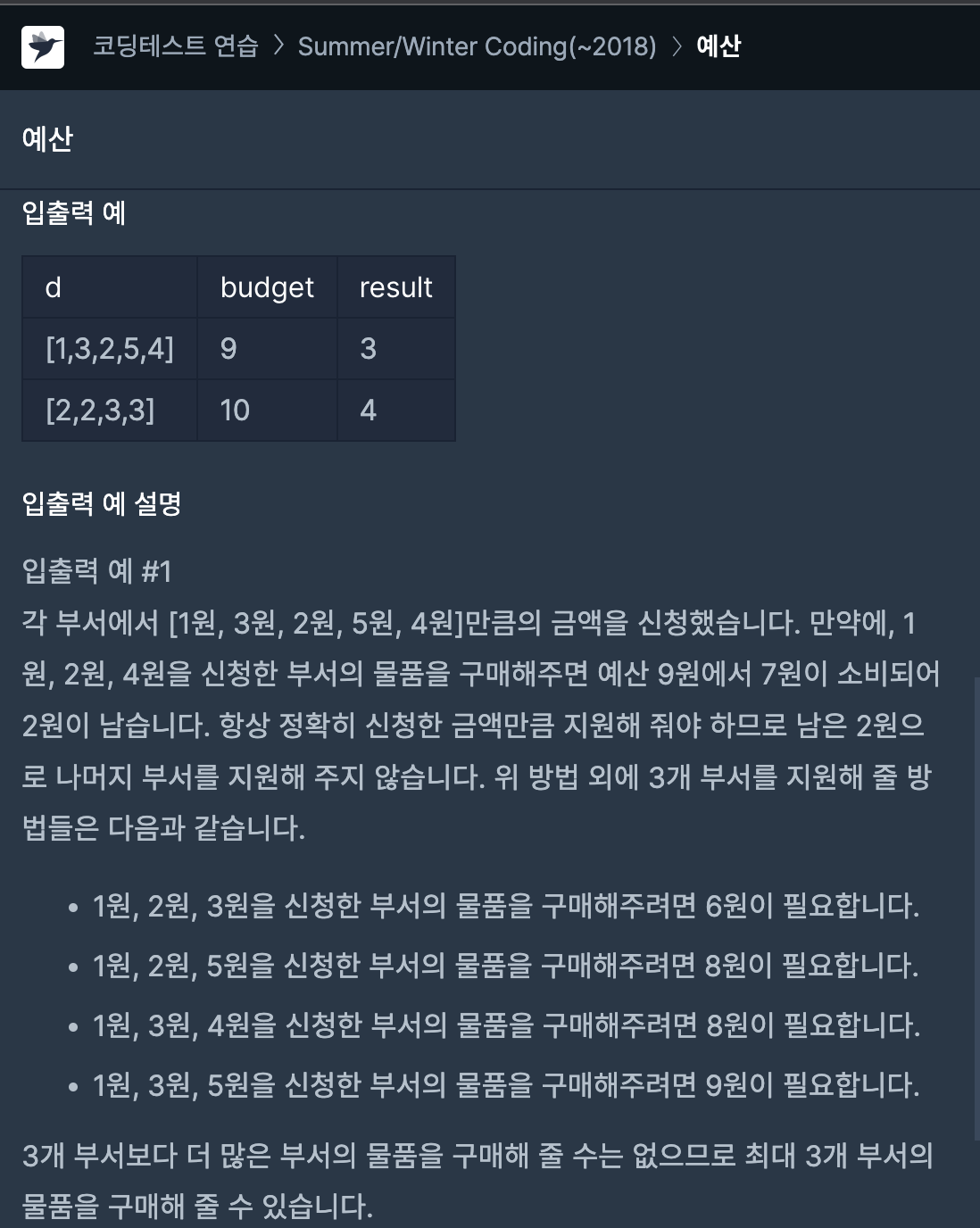 처음에는 간단히 combinations를 쓰기만 하면 풀릴거라 생각했는데, 시간초과가 났다. 곰곰이 생각해보니 정렬을 한 후에 처리를 하면 불필요한 작업을 줄일 수 있겠다는 아이디어를 얻었다.
처음에는 간단히 combinations를 쓰기만 하면 풀릴거라 생각했는데, 시간초과가 났다. 곰곰이 생각해보니 정렬을 한 후에 처리를 하면 불필요한 작업을 줄일 수 있겠다는 아이디어를 얻었다.
풀이 1 : combinations 활용
정렬을 한 다음에 가장 작은 n개의 신청금액을 뽑았을 때 그 합계가 이미 예산보다 크다면, 더 이상 n개의 조합은 살펴볼 필요가 없을 것이다.
if sum(d[:n]) > budget:
continue 만약 여기서 걸러지지 않았다면, n개의 조합을 살펴보자는 것이다. 근데 이 글을 작성하다보니, 굳이 combination은 필요하지 않겠다는 생각이 든다. 가장 작은 n개를 뽑아서 budget 이하라면, 그게 바로 정답이 아닌가?
# 풀이 1 초안 : combinations 활용
from itertools import combinations
def solution(d, budget):
d = sorted(d)
for department_cnt in range(len(d), 0, -1):
if sum(d[:department_cnt]) > budget:
continue
for case in combinations(d, department_cnt):
if sum(case) <= budget:
return department_cnt
return 0# 풀이 1 변경 : combinations 제외
def solution(d, budget):
d = sorted(d)
for department_cnt in range(len(d), 0, -1):
if sum(d[:department_cnt]) > budget:
continue
return department_cnt
return 0따라서 위와 같이 combinations 없이도 가능하다. 초안에서 combination을 생성해봤자, 첫번째 case에서 바로 조건에 걸릴 것이기 때문이다. 아무래도 문제의 조건에 따라 N개 부서의 신청금액 합이 정확히 budget과 일치할 필요가 없고 그냥 budget을 초과하지 않는 한에선 마음대로 배정이 가능하기 때문 에, 굳이 일일히 들여다보며 정확히 budget에 맞아 떨어지는 경우를 찾지 않아도 된다.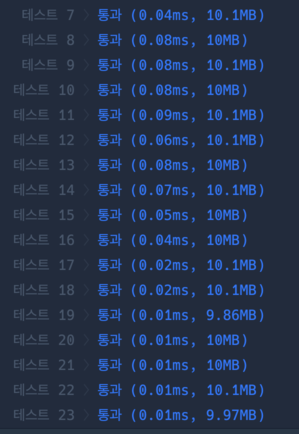 전체적인 풀이 속도도 나쁘지 않다. 모든 테스트 캡쳐가 불가해 처음에도 시간초과가 나지 않은 테스트 1~6번을 제외하고 테스트 7 부터 캡쳐하였다.
전체적인 풀이 속도도 나쁘지 않다. 모든 테스트 캡쳐가 불가해 처음에도 시간초과가 나지 않은 테스트 1~6번을 제외하고 테스트 7 부터 캡쳐하였다.
풀이 2 : 이분 탐색
여기서 착안한 2번째 풀이는 이분탐색을 활용하는 것이다. 최초에 정렬을 해놓고 시작하면 그 n이 정답이 될 수 있는지는 가장 작은 n개를 뽑아 1번의 동작으로도 판별이 가능하기 때문이다. 따라서 d의 길이가 N이라고 할 때, N부터 1까지 선형탐색을 하는 풀이 1의 시간복잡도는 O(N)인 반면 풀이 2의 시간복잡도는 O(log(N))이 된다.
# 풀이 2: 이분탐색
from itertools import combinations
def solution(d, budget):
d = sorted(d)
start, end = 0, len(d)
while start <= end:
mid = (start + end) // 2
if sum(d[:mid]) <= budget:
start = mid + 1
else:
end = mid - 1
return end
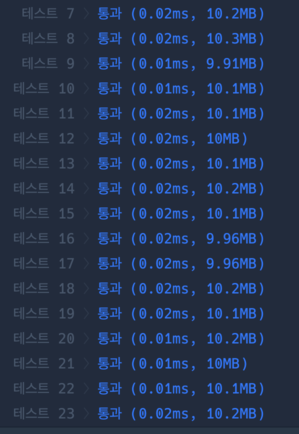
풀이시간 역시 0.02ms가 넘는 것이 없을 정도로 전반적으로 확 개선된 것을 확인할 수 있다.
풀이 3: 한 줄 풀이(accumulate & bisect_right )
마지막으로 생각해낸 풀이는 파이썬의 기능을 100% 활용해 1줄짜리 코드를 작성해보았다. itertools의 accumulate, 그리고 bisect의 bisect_right을 활용한 것이다.
# 풀이 3: 이분탐색 + accumulate 활용
from itertools import accumulate
from bisect import bisect_right
def solution(d, budget):
return bisect_right(list(accumulate(sorted(d))), budget)itertools.accumulate
accumulate는 어떤 배열의 누적값을 새로운 배열로 구성한 결과를 내어준다. 따라서 정렬 후에 accumulate를 사용해 만든 배열을 a라고 한다면, a의 i번째 인덱스는 정렬된 d의 0번째 인덱스부터 i번째 인덱스까지의 총계를 나타낸다.
즉, a[i] == sum(sorted(d)[0 : i+1]) 이다.
보다 쉬운 이해를 위해 풀이 화면에서 출력한 결과인데, 2줄의 print문을 통해 출력된 배열을 비교해보면 바로 이해가 될 것이다 :) 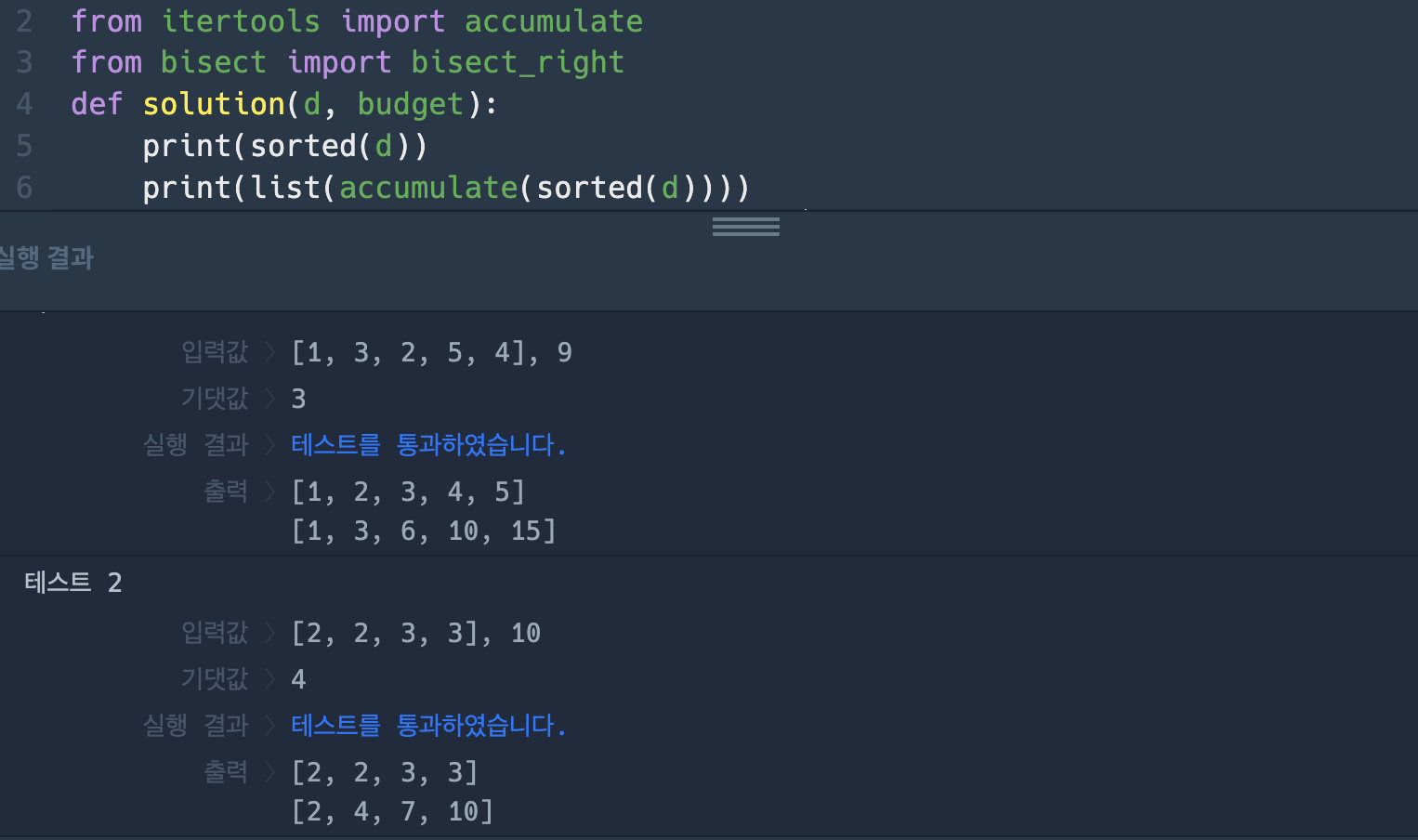
bisect.bisect_right
bisect는 어떤 배열의 정렬을 유지하면서 특정 원소를 넣을 수 있는 위치를 반환해주는 라이브러리로, 파이썬에서는 이 bisect를 활용해 이진탐색을 매우 쉽게 구현할 수 있다. bisect에 대한 자세한 설명은 링크의 공식 문서를 참고하도록 하자.
다만 bisect_left가 아니라 bisect_right을 사용한 이유는, accumulate를 활용해 생성해낸 배열에 budget과 정확히 일치하는 값이 존재할 수 있기 때문이다.
when-are-bisect-left-and-bisect-right-not-equal라는 글에 달린 답변이 bisect_left와 bisect_right의 차이를 잘 설명하고 있어 참고해보았다. 만약 총 5개의 부서가 있고 가장 작은 신청금액 순서대로 총 3개 부서의 누적 합(배열의 2번째 원소)이 정확히 budget과 일치한다면, bisect_left는 정확히 그 인덱스인 2를 반환하지만 bisect_right은 3을 반환한다. bisect_left는 그 특정 원소보다 크거나 같은 (<=) 최초의 인덱스를 반환하고, bisect_right은 그 특정 원소보다 큰 (<) 인덱스를 반환하기 때문이다. 따라서 bisect_right을 활용해야 정확한 값인 3을 구할 수 있다.
만약 총 5개의 부서가 있고 가장 작은 신청금액 순서대로 총 3개 부서의 누적 합(배열의 2번째 원소)이 정확히 budget과 일치한다면, bisect_left는 정확히 그 인덱스인 2를 반환하지만 bisect_right은 3을 반환한다. bisect_left는 그 특정 원소보다 크거나 같은 (<=) 최초의 인덱스를 반환하고, bisect_right은 그 특정 원소보다 큰 (<) 인덱스를 반환하기 때문이다. 따라서 bisect_right을 활용해야 정확한 값인 3을 구할 수 있다.
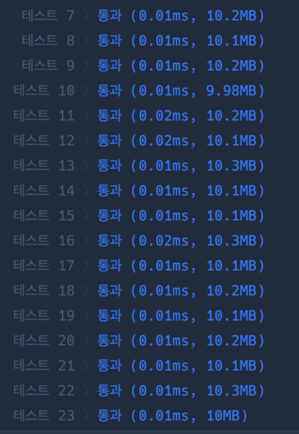 이와 같이 2가지 라이브러리의 함수를 하나씩 활용한 결과, 가장 빠른 풀이시간에 해결할 수 있었다. 풀이 2에선 절반 가량의 테스트만 0.01ms에 끝났지만, 풀이 3에서는 훨씬 많은 테스트가 0.01ms 에 끝난다. 파이썬의 강점을 활용한 풀이라고 할 수 있겠다 😋
이와 같이 2가지 라이브러리의 함수를 하나씩 활용한 결과, 가장 빠른 풀이시간에 해결할 수 있었다. 풀이 2에선 절반 가량의 테스트만 0.01ms에 끝났지만, 풀이 3에서는 훨씬 많은 테스트가 0.01ms 에 끝난다. 파이썬의 강점을 활용한 풀이라고 할 수 있겠다 😋
