
들어가기 앞서
실리콘밸리에 계시는 유능한 개발자 분과 화상챗 이 후 여러가지 생각이 들었다. 그 분의 커리어 패스와 현재 위치와 무관하게 개발자로써 본인의 주력기에 대한 자신감과 전문성. 두가지에 대해 존경을 느꼈다. 나 또한 개발을 하루 이틀할 것이 아니라면 결국 내가 좋아하는 언어나 프레임워크에 전문성을 가져야 한다는 생각이 들었다. 이 후 취업을 위한 공부가 아닌 그냥 내가 잘하기 위해서, 내 실력을 위한 공부를 시작했다. 두루뭉실하게 이해했던 내용들을 곱씹어가며 공부했다. 오늘 다룰 내용도 그렇다. 프론트엔드 개발자라면 사이트에 접속해서 페이지가 렌더링되는 과정 정도는 알아야지 라는 생각이 들었다. 보통 '주소창에 url 을 검색하면 일어나는 일'을 공부하고 '페이지가 렌더링되는 과정'을 공부했다. 결국 사용자 입장에선 한번의 행동인데 이걸 구분해서 공부하니 오히려 와닿지 않았던 것 같다. 그래서 두 과정을 자연스럽게 연결해서 되돌아보려 한다.
브라우저에 주소를 검색하고 사이트가 뜨기 까지..
1. 사용자가 브라우저 주소창에 url 을 입력한다.
(예: velog.io)
2. 브라우저는 로컬에서 해당 도메인의 IP주소를 찾아보고 없을 시 DNS서버에 도메인의 IP주소를 요청한다.
브라우저는 로컬의 DNS테이블에 저장된 DNS 캐시를 확인하여 해당 도메인의 IP주소가 있는 지 찾아본다. 여기서 DNS란 무엇일까?
DNS란 ?
DNS 는 Domain Name System 의 약자다. DNS 가 하는 역할은 간단하게 주소창에 입력한 url을 포함한 주소를 123.456.789.101 과 같이 IP 주소로 변환해준다. 최초 방문한 사이트의 경우 DNS서버를 통해 IP주소를 응답 받게 되는데 이 후 같은 사이트에서 동일한 작업에 대한 불필요한 자원누수를 막기 위해 사용자 컴퓨터의 DNS테이블에 도메인네임과 IP주소 형태로 저장된다. 이를 DNS캐시 라고 한다. 다시 말해 브라우저는 사용자가 접속하고자하는 url 에 대한 IP주소를 DNS서버에 요청하기 전에 로컬에서 먼저 찾아보는 것이다.
3. DNS서버가 질의받은 도메인의 IP주소를 응답한다.
DNS서버가 호스팅하고 있는 서버 IP주소를 찾기 위해 DNS query를 날린다. 에러가 날때까지 DNS 서버를 오가며 IP주소를 검색한다. 원하는 DNS기록을 가진 DNS서버에 도달할 때까지 클라이언트와 서버를 여러번 왔다갔다 한다.
4. DNS서버가 응답한 IP주소를 가지고 웹서버에 페이지 파일을(index.html) 요청한다.
TCP 연결이 되면 브라우저는 http 통신(get)하여 서버에게 해당 도메인의 페이지파일을 요청한다.
TCP 란?
TCP 는 Transmission Control Protocol 의 약자다. 서버와 클라이언트 간에 데이터를 신뢰성 있게 전달하기 위해 만들어진 프로토콜이다. TCP 설명을 들었을 땐 HTTP 와 동일한 느낌인데 어떤 차이가 있을까? 간단하게 HTTP는 TCP 기반으로 만들어진 프로토콜이다. 이것을 이해하기 위해서는 OSI 7계층 에 대해 이해해야 한다.
OSI 7계층
OSI 7계층 혹은 OSI 7 Layer 라고 한다.
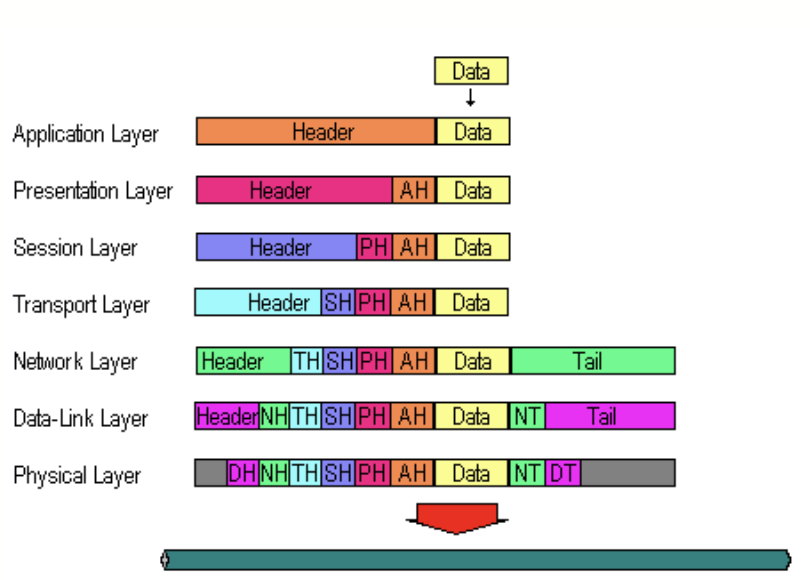
간단하게 말해 사용자가 주소창에 url 을 검색하기까지는 맨 위의 응용계층(Application Layer에 해당된다. 서버에 보낼 데이터, 어떤 프로토콜 방식을 사용할 지에 대한 헤더가 붙게 되고 이런 것들을 패킷이라고 한다. 주소를 검색 후 브라우저(Application) ~ 컴퓨터 랜카드까지 모든 계층들을 지나가고 위 사진처럼 각 계층마다 패킷이 붙는다. 각 계층마다 명확한 목적성을 가진 패킷이 부착되어 나간다.
그래서 HTTP 랑 TCP의 차이는?
http 는 tcp 기반으로 만들어진 프로토콜이기 때문에 tcp의 특징을 모두 갖고 있다고 한다. 보는 관점에 따라 다르고 4계층의 시각에서는 같은 개념이고 7계층의 시각에서는 아예 다른 개념이라고 한다. 뭔가 TCP는 HTTP 의 부모같은 느낌이 드는데 조금 두루뭉실하다. 좀 더 알아보니 이번 글에서 다루기에 조금 방대했다. 7계층 관점에서 봤을 때 HTTP 통신은 요청을 하면 반드시 응답이 돌아오는 비연결지향적인 단방향 통신 이다. 현재 상황을 예로 들 수 있다. 웹서버에 페이지 파일을 요청하고 페이지 파일을 응답 받는다. 단방향 통신이기 때문에 현재는 연결되어 있지 않는다. 반면 TCP 는 연결지향적으로 클라이언트(브라우저)와 서버가 서로 연결된다. HTTP와 다르게 요청을 했다고 해서 반드시 응답이 오지 않고 요청을 하지 않아도 응답이 오는 경우가 있다. 이는 온라인게임과 같은 실시간 처리에 많이 사용된다고 한다. 결론은 HTTP와 TCP는 다른 개념이다.
5. 웹서버는 요청에 대한 로직을 수행하여 브라우저에 html 파일을 전송한다.
이 과정에서 웹서버가 모든 로직을 처리하고 페이지를 응답하면 과부하가 올 수 있기 때문에 이를 방지하기 위해 웹어플리케이션서버(WAS)에 페이지처리를 맡기고 WAS로부터 받은 결과를 다시 브라우저로 전송한다.
6. 브라우저가 전달 받은 페이지 파일을 렌더링 엔진에게 전달한다.
CRITICAL RENDER PATH 시작
7. 렌더링 엔진은 브라우저로부터 받은 파일을 파싱하여 렌더트리를 만든다.
- html 마크업을 파싱해서 DOM(Document Object Model) tree 를 생성한다.
- css 마크업를 파싱해서 CSSOM tree 를 생성한다.
- JS는 JS 해석기로 보내 JS해석기가 파싱 후에 결과를 렌더링 엔진에 전달한다.
- 파싱된 JS를 통해 DOM 과 CSSOM에 동적인 요소를 추가한다.
- 동적 요소가 추가된 DOM CSSOM 를 결합하여 render tree 를 형성시킨다.
8. 렌더 트리에서 레이아웃을 실행하여 각 노드의 형태를 계산한다.
위 과정에서 형성된 렌더 트리의 위치와 크기를 캡처하는 BOX 모델이 출력된다. 해당 과정을 레이아웃 단계 라고 부른다.
9. 렌더 트리를 화면에 출력시킨다.
레이아웃 단계에서 모든 렌더트리의 위치와 크기가 계산이 완료되면 화면에 출력시킨다. 이 단계를 페인팅 단계 혹은 래스터화 라고 부른다.
리플로우(reflow)란?
최초 렌더링 과정 이 후 사용자의 액션으로 발생한 이벤트로 레이아웃 구조가 변경될 경우 영향을 받게된 모든 요소들이 렌더 트리 생성과 레이아웃 과정을 재수행하게 되는 데 이것을 리플로우 라고 한다.
리페인팅(repainting)이란?
리플로우 과정에서 변경된 모든 요소들을 레이아웃 과정을 재수행하고 실제로 변경점들을 토대로 다시 화면에 그리는 작업을 리페인팅 이라고 한다.
결국 리플로우가 일어나게 되면 재수행된 요소들에 대한 리페인팅이 반드시 일어난다. 그러나 border-radius 나 background-color color 와 같이 색상이나 단순한 변화에 대해서는 리플로우 될 필요가 없으므로 리페인팅 과정만 수행된다.
10. 사용자가 렌더링 화면을 본다!
짜잔 오래 기다리셨습니다.(1초)
마치며
분명 봤던 내용들인데 다시 보면 새롭다. 새로운 정보가 있을 수도 있고 그 전에 보았던 잘못된 정보를 기억하고 있기도 했다. 구글링이 실력이란 말이 괜히 있는 게 아닌 듯하다. 정보를 개개인마다 이해한대로 재해석해서 블로그로 남기다보니 오해를 통한 잘못된 뒤틀린 황천의 정보가 있을 수 있으니 조심해야겠다. 공식문서를 애용해야겠다. 파면 팔수록 알게 더 많아지는 것 같다. 사실 파고 들고자 하는 욕구 때문에 더 많이 알아야 한다는 생각을 하는 게 아닌가 싶다. 어쨌든 배운다는 건 즐겁다.
