Universal approximation Theorem (=시벤코 정리)
우리가 원하는 어떤
f든 적절한 weight와 bias를 찾아 유한한 선형 결합으로 비슷하게 나타낼 수 있다.
여기서f는 우리가 원하는 역할을 하는 함수이다.
Input layer -> Hidden layer -> Output layer에서Hidden layer에서 활성화 함수를 이용하고Output layer까지 끝나면 gradient를 이용하기 때문에 어떤 문제라도 해결 할 수 있다는 뜻이다.
딥러닝의 3대 공략법
1. 최적화(방법)
2. 초기화
3. 데이터
1. 최적화(Optimizer)
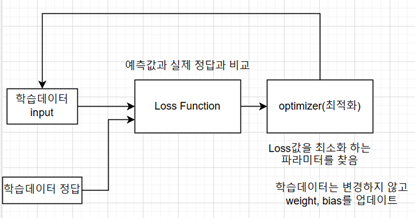
최적화란 Loss function을 최소화 하는 파라미터를 찾는 과정이다.
Loss function은 예측한 값과 실제 정답 간의 차이를 비교하는 손실 함수 이다.
이때 학습 데이터는 변경하지 않고 weight, bias를 업데이트 한다.
최적화 기법에는 Gradient Descent(경사 하강법)이 있다.
* Gradient Descent
최적의 weight를 찾는 과정이다.
 딥러닝에서는 주로 편미분을 이용하는데 접선이 여러 개인 다변 함수일 때 하나의 변수를 제외한 다른 변수는 상수로 취급해서 순간 변화율(기울기)를 구한다.
딥러닝에서는 주로 편미분을 이용하는데 접선이 여러 개인 다변 함수일 때 하나의 변수를 제외한 다른 변수는 상수로 취급해서 순간 변화율(기울기)를 구한다.
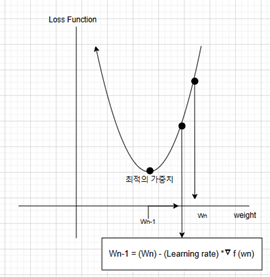
임의로 Wn이라는 가중치를 정해준다. 최적의 weight를 찾기 위해 Loss function을 W에 대해 편미분하고 learning rate를 곱한다. 그리고 정했던 Wn에서 빼주면 Wn-1을 구하게 된다.
차원이 많아 질 때는 각각의 W에 대해 편미분을 구하고 좌표를 얻는다.
Wn-2 .. Wn-3.. Wn-4 점점 값을 구하게 되면 손실 함수 값이 점차 0으로 수렴하고 W값들에 대한 차이가 점점 미미해질 때가 최적의 가중치라고 판단한다.
편미분

하지만 Gradient Descent 방법은 한계가 있다.
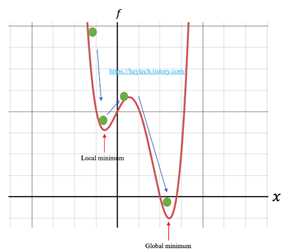
1. Local Minimum에 빠지기 쉽다.
단순한 볼록(convex) 함수는 경사하강법을 활용하면 최적의 값에 도달할 수 있지만
현실에서는 주로 비 볼록(non-convex)함수이다.
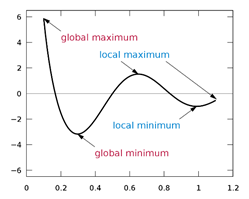 파라미터 값의 시작 위치에 따라 최적의 값이 달라지게 된다.
파라미터 값의 시작 위치에 따라 최적의 값이 달라지게 된다.
그리고 그 값이 Global하게 minmum인줄 알았지만 사실 Local minimum일 수도 있다.
즉 global인지 local인지 구분할 수 없다는 문제가 있다.
2. Saddle point(안장점)을 벗어나지 못한다
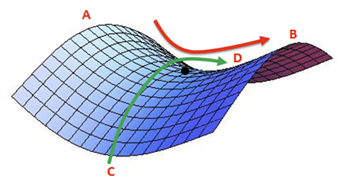 모든 방향으로 기울기가 0이고 극점이 아닌 점을 saddle point라고 하는데,
모든 방향으로 기울기가 0이고 극점이 아닌 점을 saddle point라고 하는데,
임의의 검은색 점을 정해보면 A-B는 최솟값이 되지만 C-D는 최대값이 된다.
Gradient Descent의 단점을 극복한 기법에 대해 알아보자
* Momentum
경사 하강법이랑 동작은 비슷하지만 추가로 관성을 부여하는 최적화 기법이다
 이전에 이동했던 방향과 기울기의 크기를 고려하여 어느 정도 추가로 이동시킨다.
이전에 이동했던 방향과 기울기의 크기를 고려하여 어느 정도 추가로 이동시킨다.
즉 Local minimum에 빠질 수 있는 상황에서 쉽게 벗어 날 수 있게 된다.
r : 관성계수 , n : 학습률
2. 초기화
최적화 기법을 사용할 때 초기 위치를 정하는 것이 특히 중요하다.
* Zero initialization
모든 가중치를 0으로 초기화 하면 derivative wrt loss function은 모든 가중치 W에 대해 subsequent iterations이 동일한 값을 가지게 된다.
이것은 n번의 반복으로 학습을 하여도 hidden layer가 대칭적이게 만들어 진다. 따라서 linear model보다 더 안좋게 만들 뿐이다.
* Random initialization
weight에 random한 값을 주는 것은 대칭 문제를 해결하고 더 높은 정확도를 가진다.
하지만 weight을 초기화 할 때 매우 높거나 매우 낮은 값을 가지게 될 수도 있다.
weight값이 0과 1에 치우쳐서 분포하고 여기에sigmoid함수를 쓰게 된다면 0과 1에 가까워질수록 미분 값이 0에 가까워지기 때문에 gradient가 점점 작아지는gradient vanishing문제가 생길 수가 있다.즉 학습을 하면서 효율적이게
weight값이 변해야 되는데 미미한 변화만을 가지게 된다. 그래서 학습효과를 보기 어려워 진다.
Exploding gradient한 문제를 야기할 수도 있다.weight가 0이 아닌 아주 작은 값이면 그만큼 학습을 할 때 매우 크게 기울기가 변경이 된다. 그래서 어떠한 값이 제대로 학습이 안될 수 있는 문제가 생기고 gradient 값이 크기 때문에overflow문제 발생 가능즉 weight를 초기화 할 때는 평균은 0 정도로 zero-centered한 값이어야 할 것이고, 모든 layer에서 일정한 값을 가져야 될 것이다.
* Xavier Initialization
각 layer에서 weight값을 더욱 광범위하게 분포시킨다.
tanh또는 sigmoid로 활성화 되는 경우에 만들어진 초기화 방법이다.
앞 layer의 neuron이 n개일 때 표준편차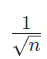
인 정규분포를 사용한다.
너무 크지도 않고 작지도 않은 weight을 사용하여 gradient가 vanishing하거나 exploding하는 문제를 막는다.
하지만 ReLU를 이용할 때는 0으로 수렴하는 문제가 발생
* He-et-al Initialization
He Initialization는 앞 layer의 neuron이 n개일 때, 표준편차가 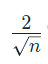
인 정규분포를 사용한다.
ReLU는 음의 영역이 0이라서 활성화 되는 영역을 더욱 넓게 분포 시키기 위해 2배를 한 것이다.
3. 데이터
딥러닝에 사용되는 데이터들은
train데이터,validation데이터,test데이터로 이루어 진다.
train데이터는 학습에 사용하는 데이터이고
validation데이터는 훈련데이터로 학습된 모델을 평가할 때 사용한다.
보통 딥러닝을 할 때 데이터가 주어지면 7 : 3 비율로 나눠서 train과 validation데이터를 구성한다. 이때 샘플링 편향이 일어나지 않도록 주의해야 한다.
test데이터는 학습 과정에서 전혀 사용되지 않는 데이터를 이용해 최종 평가에 사용한다.
