비지도 학습을 활용한 페어 트레이딩 탐색
페어 트레이딩이란?
일종의 차익거래이다.
여기선 이해하기 쉽게 주식으로 예를 들겠다.
주가가 비슷하게 움직이는 2개의 주식이 있다고 가정하자.
평소와 움직임이 달라지며 A주식과 B주식의 가격 차이가 벌어지는 상황을 상상해보자.
예를 들어, A주식은 가격이 오르고 B주식은 가격이 내려갔다.
이때, 평균회귀를 기대하며 A주식에 대해 (공)매도 B주식에 대해 매수를 하는 것이
통계적 차익거래라고 할 수 있다.
페어 트레이딩 대상을 찾기 위하여
S&P 500에서 500개 주식의 정보를 갖고왔다
그리고 아래는 500개 주식끼리의 상관관계를 나타낸 히트맵이다
이게 추상화도 아니고 도무지 알아볼 수 없다.
주식 2개씩 계속 뽑아서 확인해야할까?
그럼 500_C_2(조합) = 124,750 개의 쌍이 나온다.
그걸 다 점검하는 것은 말이 안되는 짓이다.
그렇다면 상관관계 상위권만 점검하면 될까?
여전히 문제가 있다.
상관관계는 '왜'를 설명하지 못한다.
이게 시장 전체가 올라서 생긴 상관계수인지
섹터 전체가 올라서 생긴 상관계수인지
아니면 해당 시기에 우연히 같이 올라서 생긴 상관계수인지
설명할 수 없다.
(아래는 수익률 행렬이다. 컬럼은 주식 티커, 값은 수익률, 행은 날짜로 구분한다)
위에서 발생한 문제를 해결하기 위해 PCA를 도입한다.
PCA의 특성
1. 전체 데이터를 가장 잘 설명하는 새로운 축 도입
2. 차원을 축소한다 (방금까지 무려 500차원이었다)
3. 노이즈를 버린다 (주성분 개수 선택에 의해)
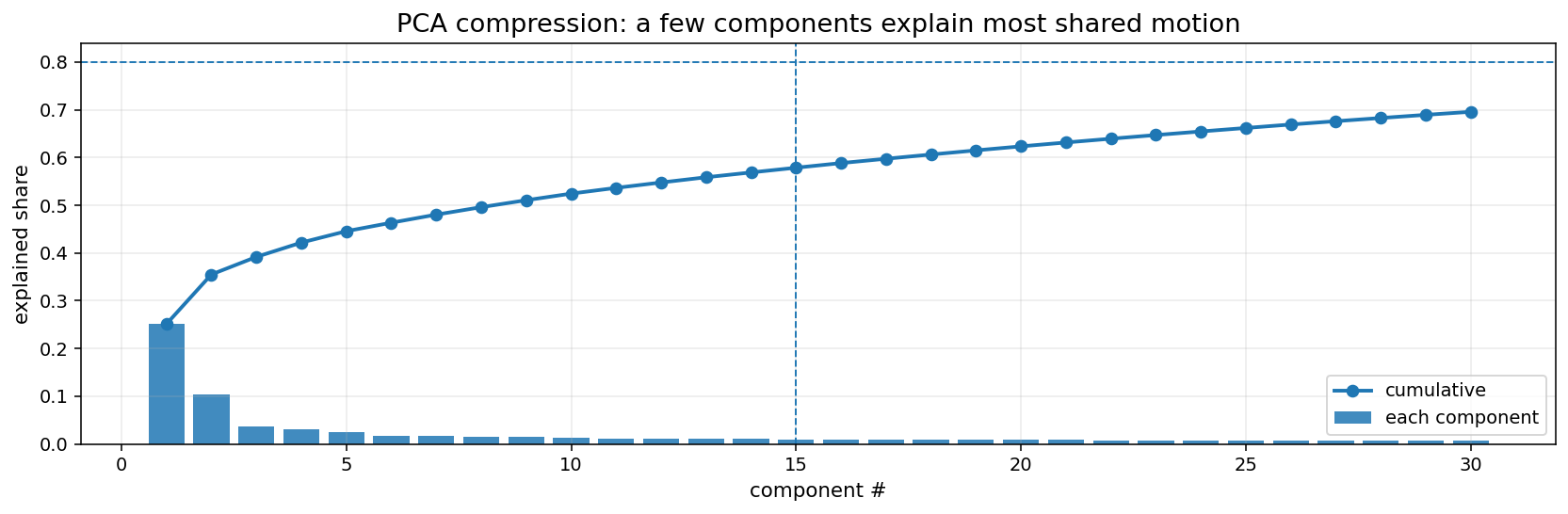
익숙한 이미지.
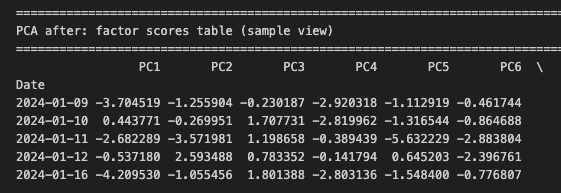
PCA 결과를 요약한 이미지이다.
여기서 궁금증이 생길 것이다
아니 이러면 개별 주식이 주성분으로 압축되어 다 사라진 것 아니냐?
이러면 어떻게 분석하느냐?
나도 같은 의문을 가졌다.
이때 PCA의 '로딩'이라는 개념을 알아야한다
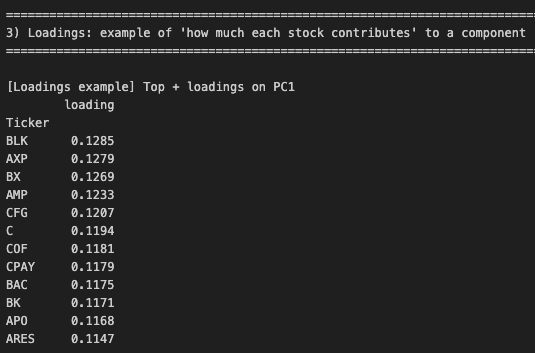
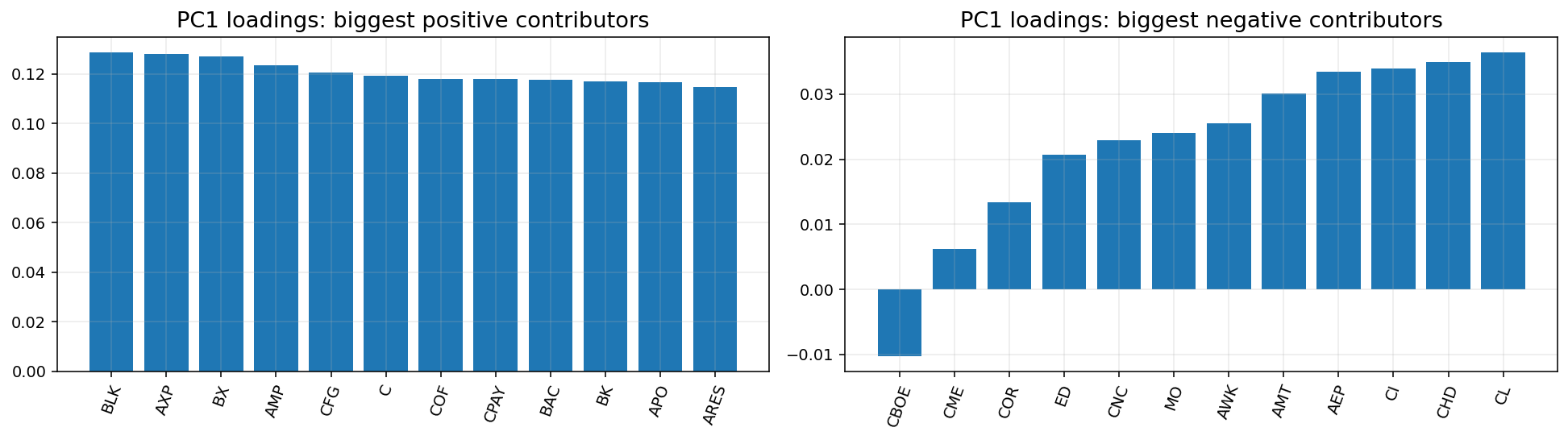
로딩이란, 쉽게 말하면 해당 주성분(PC)를 생성하는데
기존 컬럼들이 얼마나 기여했는지를 나타내는 수치이다.
가중치라고 생각해도 된다.
우리가 PC성분 개수를 k개로 골랐다고 가정하자.
그럼 AAPL 의 로딩 벡터를 이렇게 생각할 수 있다
AAPL: [loading_PC_1, loading_PC_2, ... , loading_PC_k]
즉, 각 주식의 각 PC에 대한 로딩 기여도를 나타낸 k차원 벡터이다
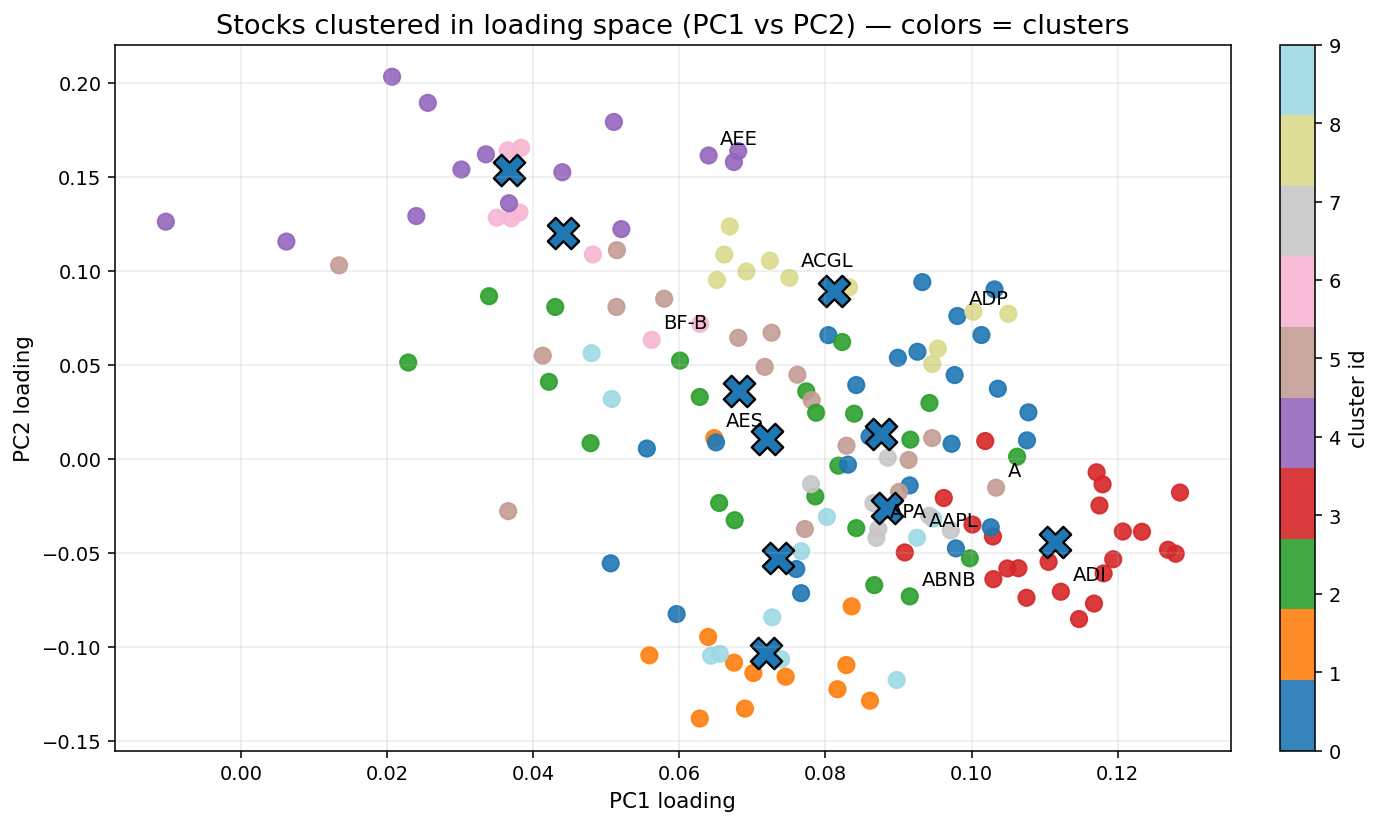
이때, 로딩 유사도를 이용해 군집화를 진행한다.
왜 로딩 유사도를 이용하는가?
로딩이 유사하다는 것은 주가가 움직일 때
같은 시장 요인(Factor)에 대해 거의 동일한 민감도로 반응한다는 것을 의미하기 때문!!!
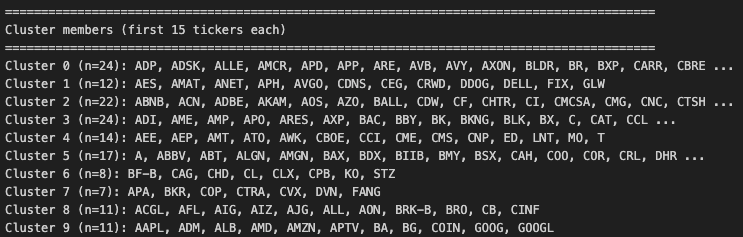
이제 같은 군집 내에서 가장 유사한 Pair 를 골라주면 된다.
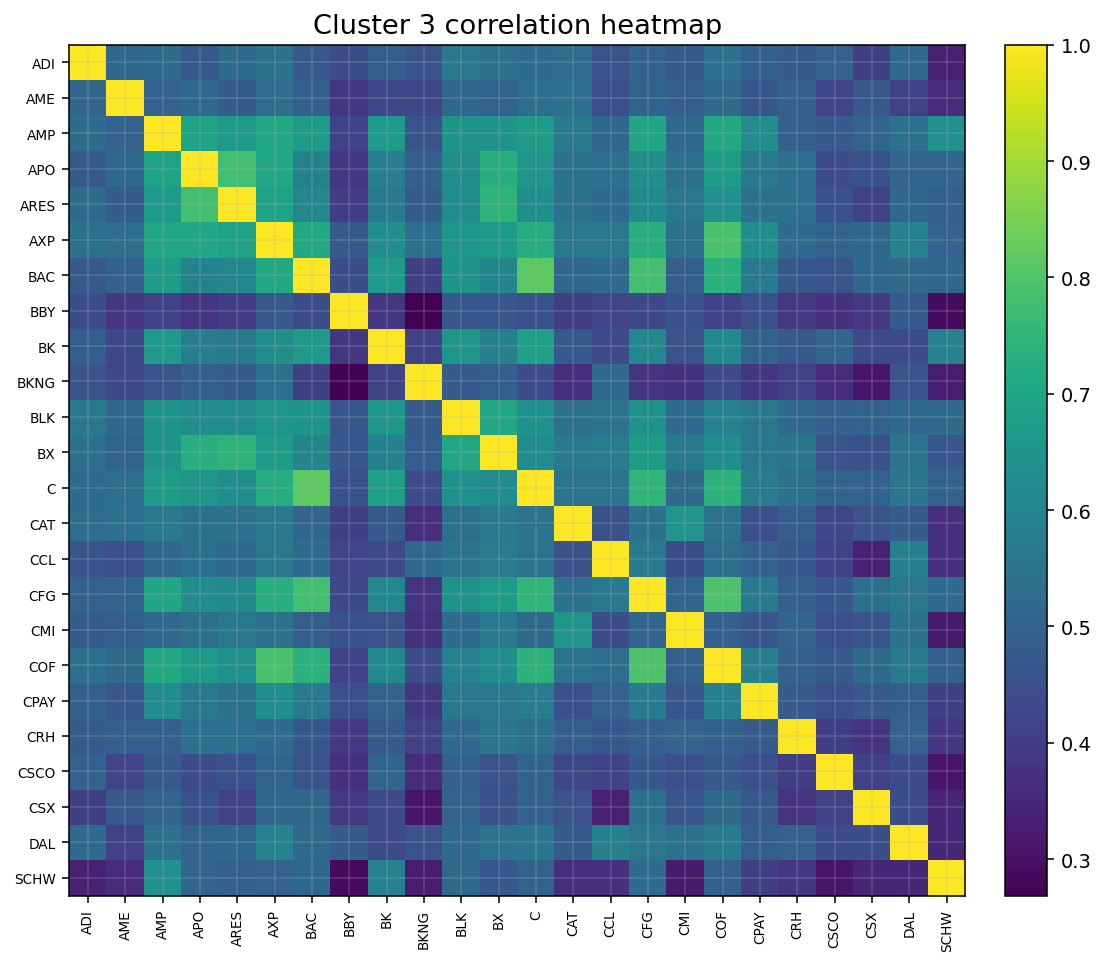
거의 다 왔다.
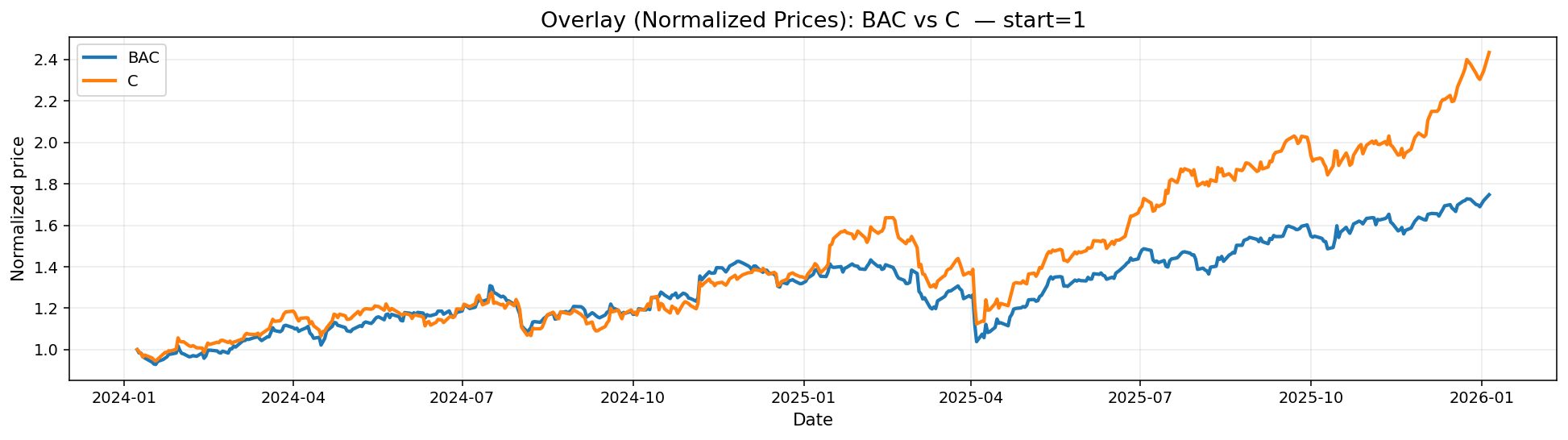
Pair -> BAC, C 당첨
눈으로 봐도 비슷하게 움직인다는 것이 보인다.
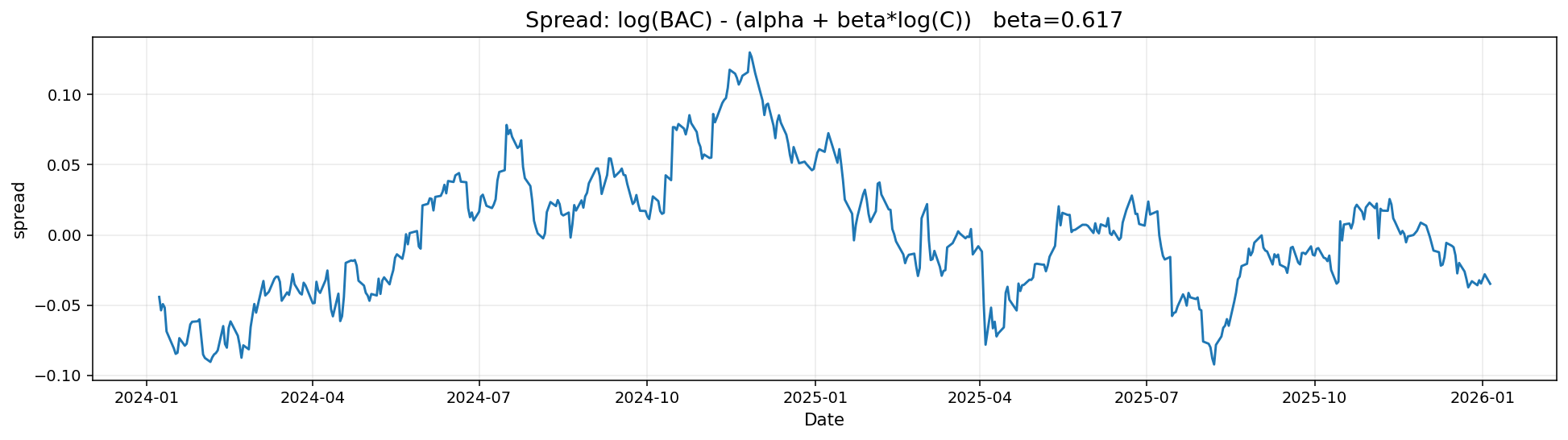
한눈에 확인하기 쉽게 스프레드 그래프를 새로 그렸다.
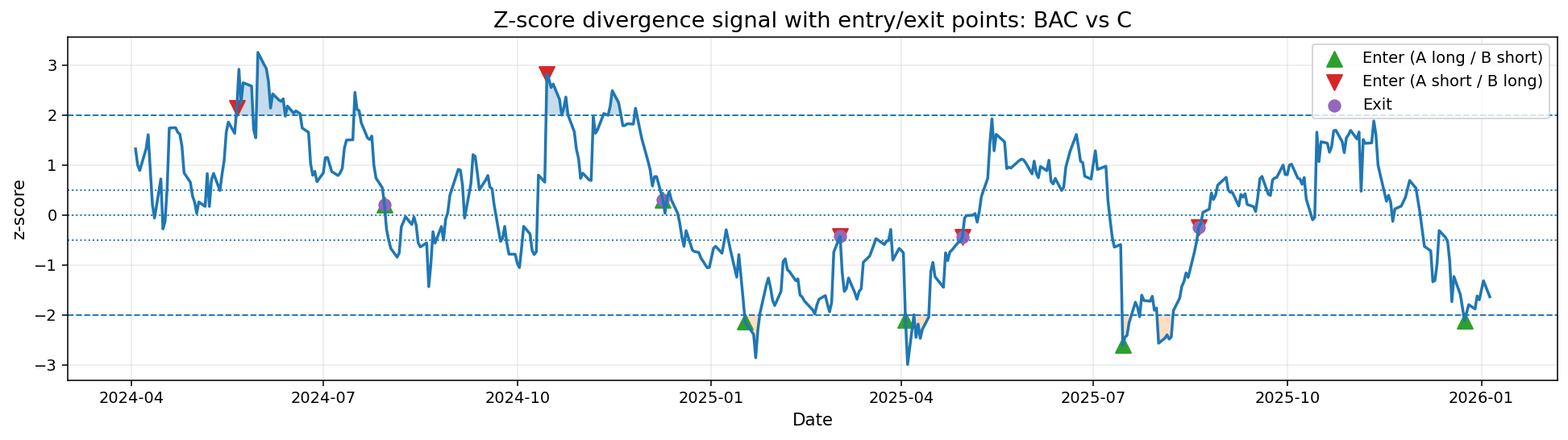
Z-스코어를 이용한 진입 신호
초록색 - A long / B short
빨간색 - A short / B long
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
비지도 학습(PCA, 군집화)을 활용해서 무엇을 했나? 포인트 정리
1) 차원의 저주 해결 및 연산 효율성 극대화
12만개의 조합을 전수조사하는 대신, 수치화된 로딩 벡터 군집화로 연산 효율을 수만배 높였음.
2) 가짜 상관관계 제거
단순히 차트가 닮은 게 아니라, 시장을 움직이는 동인(Driver)에 반응하는 메커니즘이 같은 종목들을 찾아냈다.
마지막으로
'공분산행렬 분해'를 꼭 알아보시길 바랍니다
PCA 이해도가 차원이 달라졌습니다
