데이터 전처리
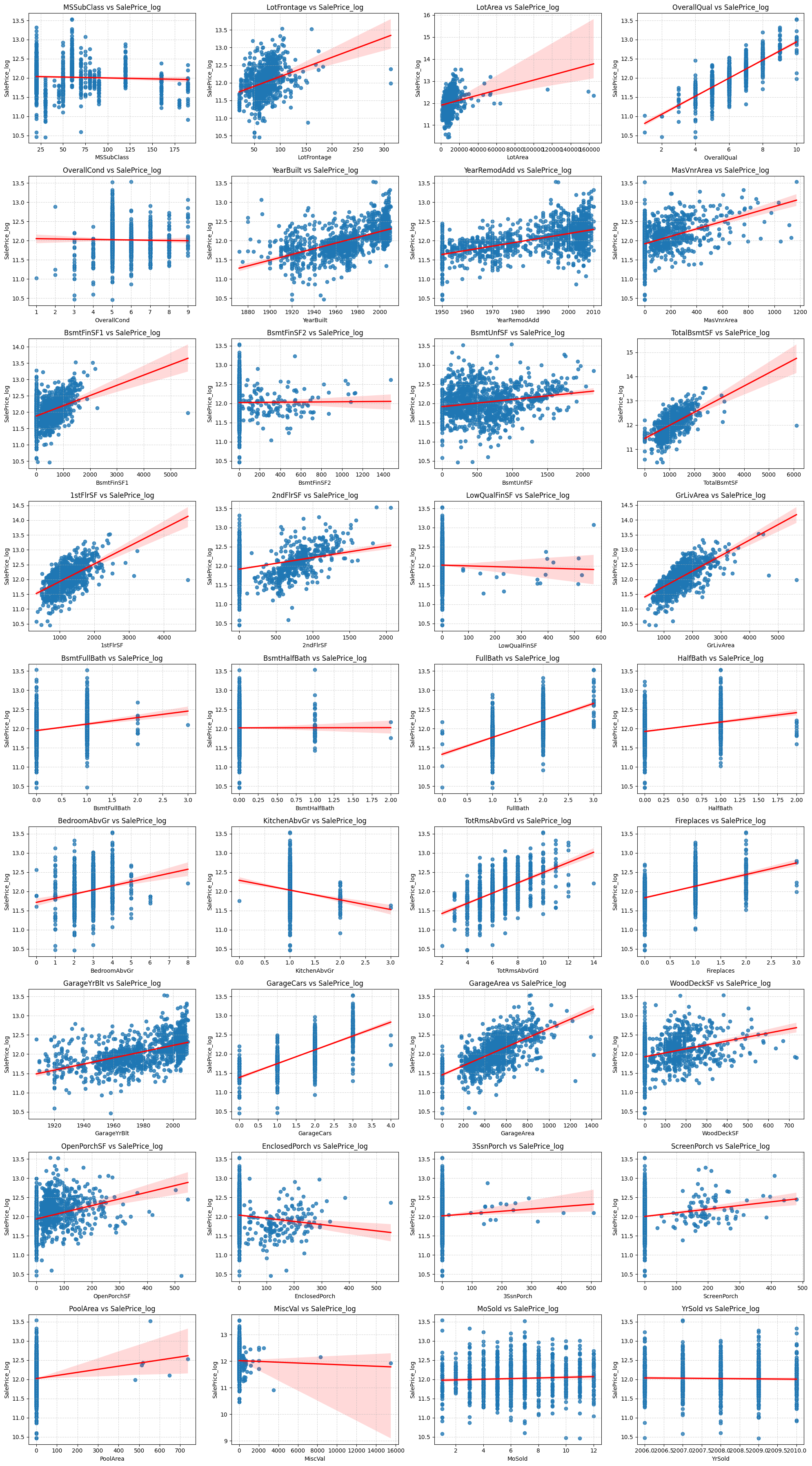
모든 피처 시각화 다 띄움
산점도+회귀선 분석이 아주 직관적이라 마음에 들었다
베이스라인 모델
베이스모델 LGB 빠르고 데이터 안 가리고 좋음
이상치 제거, 피처 엔지니어링 하나씩 넣어보면서 결정
다른 모델은 다를 수도있지 않나? 맞지만 하나만 고른다면 최선
선형 모델은 워낙 빨라서 베이스라인 여러개를 동시에 돌려도 됨
피처 엔지니어링
단순히 피처늘려서 좋다? ㄴㄴ
트리에는 뭘 해야 좋고 (의미 있는 기준으로 빠르게 분기하도록)
선형은 어떻게 먹여야 좋고 (직선으로 관계를 보기 좋게. 비선형/상호작용 인식할 수 있게)
각각의 기계(모델)가 알아들을 수 있도록
뭔가 파생 변수 더 없을까 고민
분류 때의 아이솔레이션 Anomaly Score, 오토인코더 Latent Vector 만들었던 것처럼
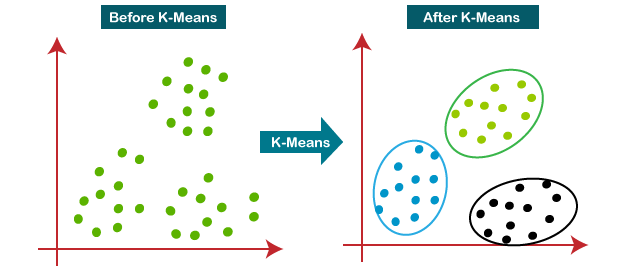
군집화 피처를 만들자!!
지도, 비지도 2가지 방식으로 함
지도는 내가 직접 구간별 답을 주는 방식
비지도는 K-Means 클러스터링 해봤음
큰 기대와 달리 둘 다 그냥 그렇길래 제외함 (큰 차이 X)
생각해보니 이거 LGBM만 해봤음. 선형에도 해봐야했는데..
box-cox (skew 0.75 이상, 고정 람다가 아니라 컬럼마다 최적 람다를 찾아주는 식으로)
스케일링 (필요한 모델일 때)
베이스 러너
트리 모델
선형 모델
뉴럴 모델
커널 모델
거리 모델
(확률 모델)
머신러닝 모델을 기반 기준으로 나눠봄
앙상블 때 서로 다른 성격이면 더 좋으니까
다른 기반의 모델들을 골고루 테스트하기로함
*참고: 태뷸러 데이터는 트리, 선형이 거의 다 해먹음
추가해봤자 뉴럴 커널 약간.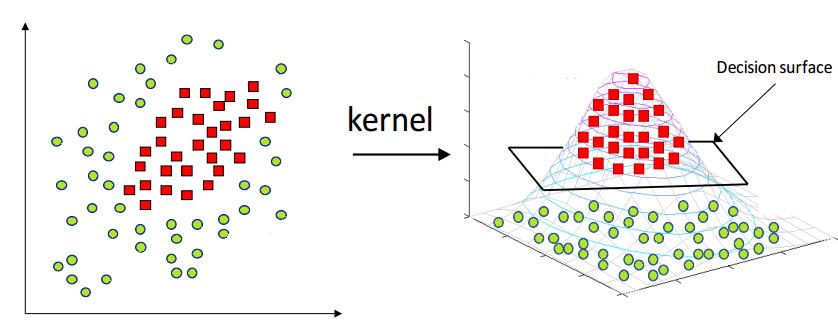
커널 트릭??
커널 함수를 이용해서
차원 확장(비선형 능력)은 얻고
고차원 특징을 직접 만들 필요는 없다.
커널릿지, SVR → 데이터가 적어서(1,100행) 커널릿지가 더 어울림
근데 XGB LGB 등 트리 모델이 성능이 기대만큼 안 나옴.
의외로 뉴럴의 성능이 더 나왔음. 그래서 채택
각종 선형 모델도 많이 해봄.
거리 모델은 KNN도 해봤으나 역시 안 좋음.
각각의 모델에 적합한 처리로 넣어주기
선형 모델에 타깃 인코딩 해봄 (기대만큼 결과가 좋지 못해서 아쉬움)
원핫 인코딩의 경우
원핫 인코딩 하고나서 피처 평가 (순열 중요도)
거기서 지우는 것도 해봄
원본 피처 자체를 지우면 손실이 크니까
원핫으로 나눠진 상태에서 → 골라 지우기
(이렇게도 해봤다는 것이지 권장하는 건 아님)
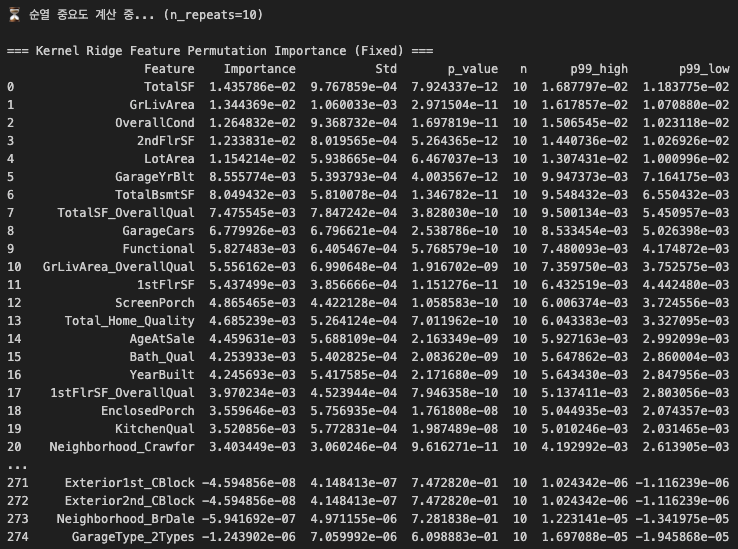
순열 중요도 이용.
피처 셀렉션 목적!!
중요도 ≤ 0 , P밸류 > 0.05 , p99_low < 0
이것도 하나하나 삭제하면서 RMSE 개선되는지 확인함 (특히 선형 모델!!)
데이터가 약 1,100개밖에 없어서 (문제인 데이터가 똑같이 10개일 때 비율을 생각)
이상치 몇개가 회귀선을 강력하게 끌어당기듯이
노이즈가 타깃 예측을 방해함. 그래서 데이터가 적어도 과감히 삭제
중요도. 0 이하는 삭제 고려
p값은 우리가 아는 통계적 유의성
p99_low는 99% 신뢰구간에서의 최솟값. 반복시 중요도가 어디까지 떨어지는가 = 최악의 경우에도 쓸모가 있는가?
0 양수이면? 최악이어도 도움 된다
< 0 음수이면? 어떤 경우엔 나빴다가 좋았다가 한다. 노이즈 가능성 높으므로 삭제 고려
기타 참고한 것
잔차 분석 (모델이 어디서 틀리나 진단)
널 중요도 (타깃을 무작위로 섞어서 확인)
SHAP (각 피처 기여도 값)
피처 중요도 << 이놈은 일부러 안 봄. 안 좋다고 함.
블렌딩 스태킹
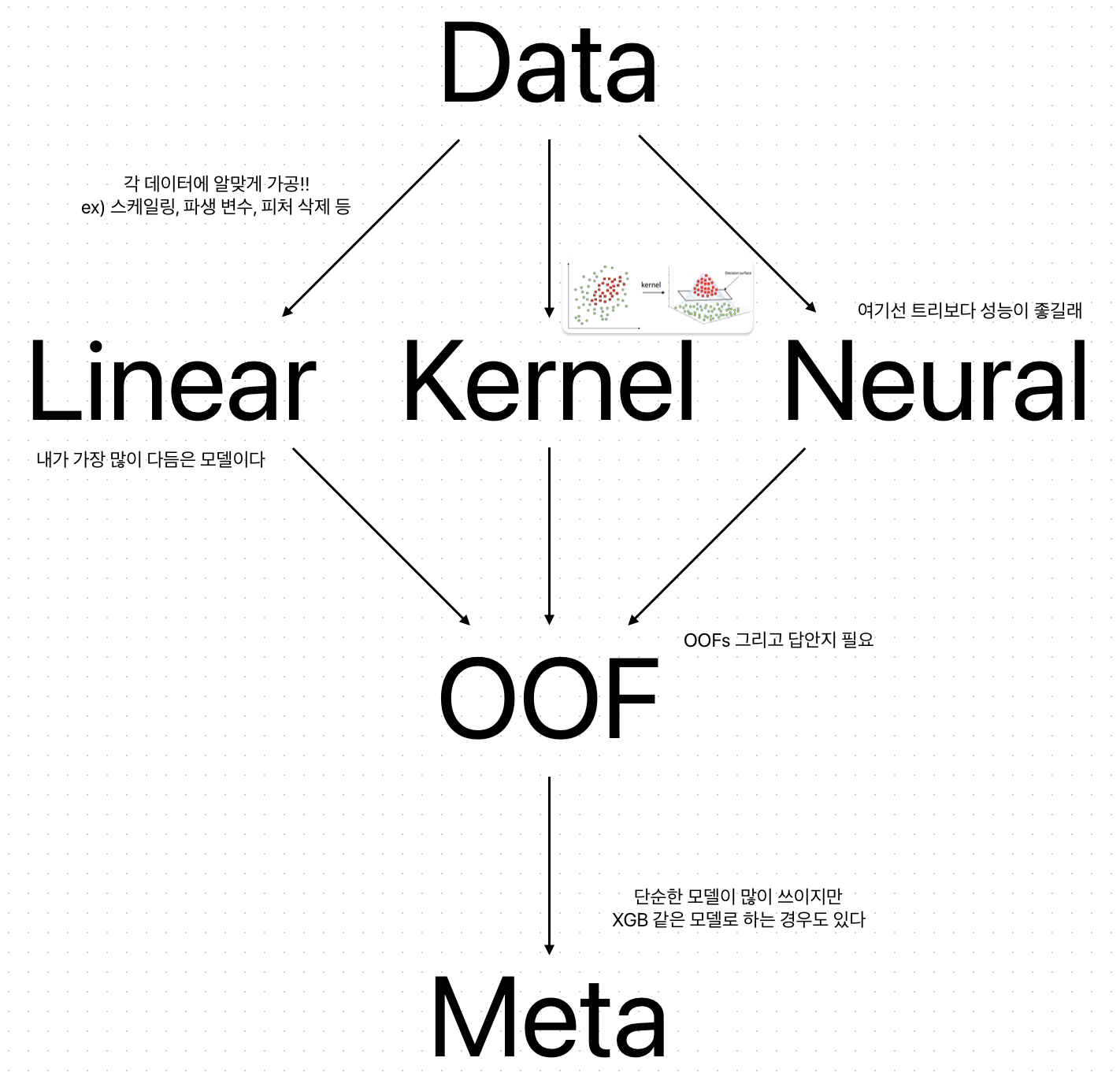
블렌딩(가중치 앙상블), 스태킹 진행함
블렌딩은 수동으로 하는 것과
scipy minimize 최적 수행이 있음
스태킹 OOF, test
코드 오타내서 스태킹 컬럼 하나 값이 전부 0이됨
모르고 제출했다가 절망함
릿지CV, 메타모델 전부 비교해서 선택
힐 클라이밍도 해봄 (가중치 합 강제로 1 만들기)

스태킹 하면서 깨달음
데이터를 보는 관점이 다른 모델들이 서로 보완
XGB LGB 단독 성능이 CAT보다 좋았지만 CAT이 좋음
포켓몬 배틀 예시
PassThrough 스태킹 (메타모델이 원본 X의 세부 신호도 다 담기 위해)
OOF를 원본 피처에 섞어서 XGB 주는 것도 해봄
기타
못해봐서 아쉬운거
스태킹 더 많은 조합을 준비해놨는데 못해본거.
모델마다 다르게, 데이터에서 이상치 혹은 노이즈를 더 제거하면 성능이 더 좋아질게 분명한데 못해서 아쉽다
VIF(다중공선성) 확인하고 삭제해볼 시간이 없어서 아쉽다 혹은 PCA
시드 앙상블?? 알아보고 싶었는데
더욱 개선할 여지나 아이디어는 많았다 하루만 더있었다면
18,000 아래도 될 것 같지만? 못해ㅘ거 아쉽네
ai와 협업하는 것의 중요성을 또 다시 체감
자바웹개발 (DB → 백엔드 → 프론트엔드)
우리도 써야한다
근데 일임은 ㄴㄴ
나는 실험 설계에 집중해야한다
의사결정 수억 수십억 수백억
설명가능?
재현성은? 재현가능?
나를 중심으로 ai를 써야한다
