미션
선택 미션
모델 파라미터란?
머신러닝, 특히 딥러닝에서 주어진 데이터를 학습할때 작동하는 모델 내부의 변수를 의미한다.
예를 들어 물고기의 길이에 따라 무게는 어떻게 변화하는가? 라는 문제에 대해 데이터의 분포를 보고 키가 증가할수록 체중변화의 비율은 얼마나 될까? 기본적으로 키가 체중에 미치는 영향은 얼마나 될까? 키가 0일때 체중이 얼마일까? 따위등으로 데이터의 종류, 패턴에 따라 추가하거나 조정되며 최적화를 진행하게 된다. 파라미터의 수, 그리고 값에 설정은 모델의 학습 능력을 결정하는 중요한 요소이며 복잡도를 결정한다. 너무나 많은 파라미터의 사용은 과대적합을 유발하고, 너무 적은 파라미터는 과소적합을 유발한다. 많은 머신러닝 알고리즘에서 훈련과정이란, 최적의 모델 파라미터를 찾아 내는 것과 같다. 이를 "모델기반 학습" 이라고 한다.
기본 미션
chapter03-01 문제 파라미터 조정 그래프
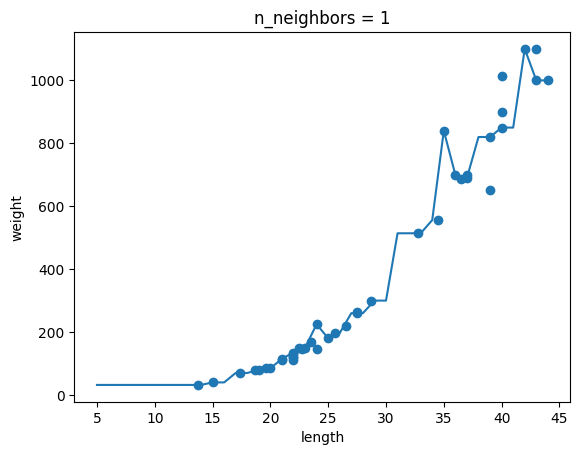
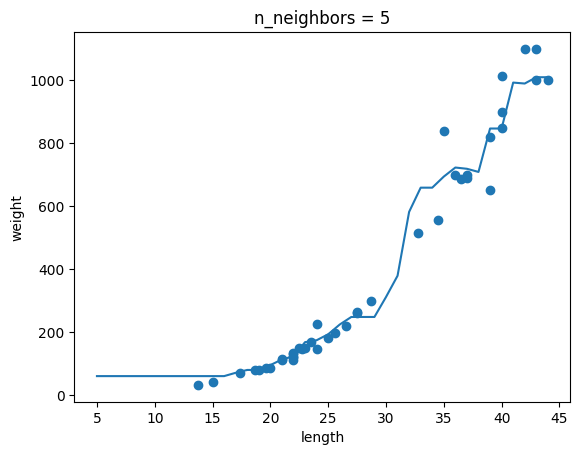
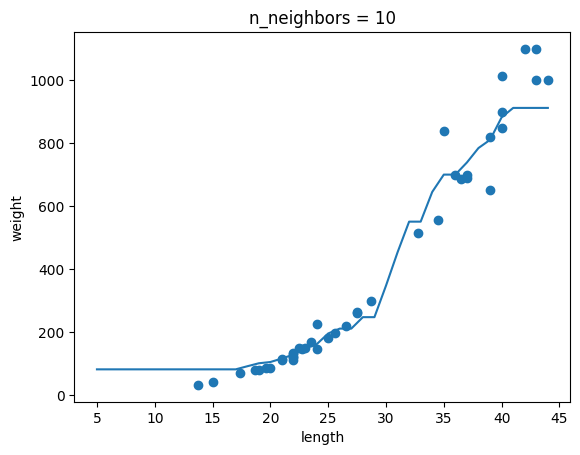

이제 진짜 개발하려구요!