4장
01. 로지스틱 회귀
정의
로지스틱 회귀(Logistic Regression)란 사건의 발생 가능성을 예측하는 데 사용되는 확률모델로써, 일반적인 회귀분석과 마찬가지로 입력된 데이터(독립변수) 간의 관계를 이용해서 값(종속변수)을 예측하는 방법이다. 선형회귀와 유사하지만 예측 값이 특정 분류로 나뉘기 때문에 분류기법이라고 할수 있다. 이진분류(ex: yes/no, true/false, positve/negative) 또는 다중분류(ex: 맑음,흐림,비) 이 될수 있다. 이진분류 일경우 2개의 카테고리는 확률값 0.5를 기준으로 각각 양성과 음성(0,1)으로 나타내어지고 다중분류일 경우 각 카테고리로 분류 될 확률의 합이 1로 나타내어 진다.
선형회귀대신 사용하는 이유?
 |  |
|---|
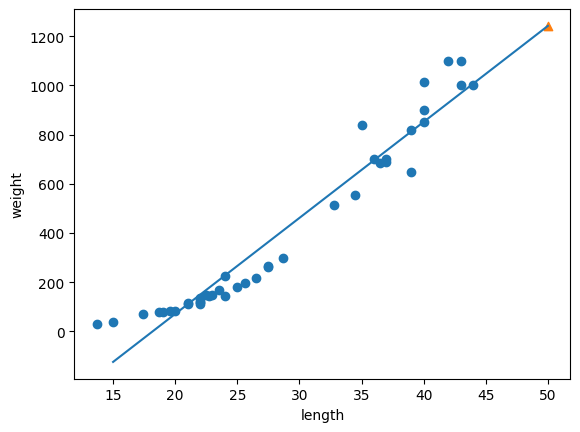
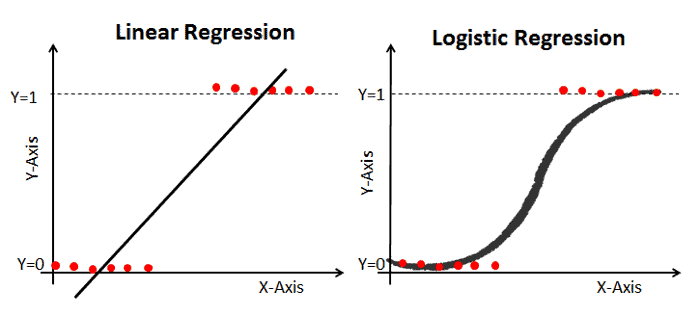
일반적으로 선형회귀의 경우 왼쪽의 그림처럼 길이에 따른 무게 값, 즉 독립변수들로 부터 연속된 종속변수들을 예측하는데 사용될 수 있다. 하지만 예측해야하는 종속변수가 6면 주사위를 굴렸을 때 각 주사위의 면이 나올 확률이라면? 무게와 길이값을 기준으로 어떤 종류의 물고기일지 분류해야 한다면? KNN알고리즘을 이용한다면 각각 독립변수가 종속변수에 미치는 영향을 정확히 분석하지 못할것이고, 선형회귀를 대입한다면 우측에 첫번째 그림과 같이 확률이나 범주에 대하여 제대로 설명하지 못할것이다. 결국 우측 마지막 그림처럼 결과에 영향을 미치는 각각의 독립변수의 상관관계로 인해 하나의 값이 발생할 0~1까지의 확율(종속변수)을 구하기 위해서는 로지스틱스 회귀를 이용해야한다.
동작방식
로지스틱 회귀는 선형회귀와 동일하게 선형방정식을 학습한 후 시그모이드(sigmoid)함수 또는 소프트맥스(softmax)함수를 통과시켜 0과 1사이의 확률값()를 얻는다. 이항분류에서는 값이 0.5이상일 경우 양성 클래스(1)로, 그렇지 않을경우 음성 클래스(0)으로 분류한다.
선형결합(Linear Combination)
- = 종속변수(예측값)
- = 계수(coefficient) 혹은 가중치(weight)
- = 독립변수, 종속변수에 영향을 주는 변수(특성값)
- = 절편(intercept)
시그모이드 함수(Sigmoid Function,Logistic Function)
- = 0과 1사이의 확률값.
- = 값이 매우 큰 양수일 경우 값은 0에 가까워져 에 한없이 가까워 지게되고, 매우 큰 음수일 경우 값은 매우 큰 수가되어 가되어 0에 한 없이 가까워 진다.
소프트맥스 함수(SoftMax Function)
=
- : 출력값의 j번째 요소
- : 클래스의 총 개수
- : 의 번째 요소에 대한 지수함수
- : 모든 클래스 점수에 대한 지수 함수의 합
- 예를들어 만약 3개의 선형방정식의 출력 ~까지 값이 있다면 지수함수 ~ 을 모두 더한 값으로 ~ 을 나누어 주고, 에서 까지 모두 더하면 분자와 분모가 모두 같아져 1이된다.
확률 분석
- 이항분류일 경우 시그모이드 함수 값이 0.5이상이면 양성(1), 그렇지 않을경우 음성(0)으로 분류
- 다중분류일 경우 소프트 맥스 함수 값의 총 확률의 합이 1로 표현된다.
02. 확률적 경사 하강법
정의
경사하강법(Gradient Descent)란 손실함수(Loss function)의 기울기를 계산하여 이 기울기가 감소하는 반향으로 반복적으로 파라미터를 업데이터 하여 최적의 파라미터를 찾는 방법이다. 쉽게 이야기해서 머신러닝의 모델이 스스로 틀릴 확률이 가장 적은 가중치값을 찾는 과정이다. 확률적(Stochastic)이란 전체 데이터 세트에 대해 계산하지 않고 무작위로 선정된 데이터 세트의 대해 기울기를 계산하는 방식이다. 예를 들어 아래 이미지와 같이 라는 함수가 존재할 때, 값을 증가시켰을 때 함수의 값이 증가한다면 x를 음의 반향으로 옮기고, 반대의 경우에 x를 양의 방향으로 움직인다면 어느 지점에서 함수의 값이 최소가 될수 있는 x값을 찾을 수 있을 것이다.
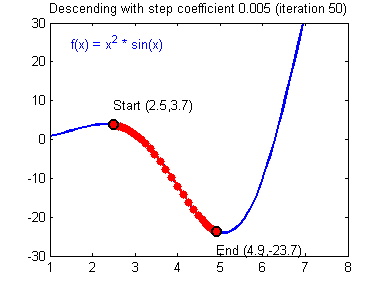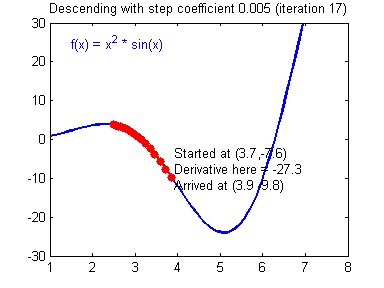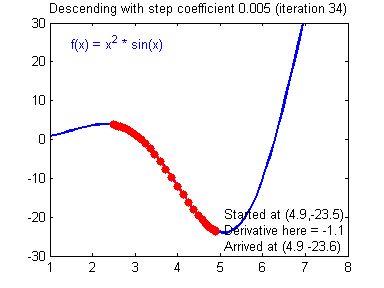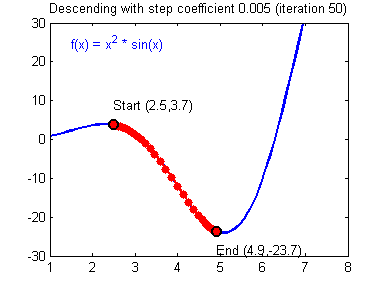
출처 : https://hackernoon.com/life-is-gradient-descent-880c60ac1be8
왜 사용해야 하나?
머신러닝의 데이터는 계속해서 추가 되고 관리가 되어야하는데, 시간이 지날 수록 필연적으로 훈련 데이터 세트의 크기는 커질 수 밖에 없다. 매번 새로운 데이터가 추가 될때마다 모든 데이터 세트에서 최적의 가중치 값을 찾기 위해 학습을 한다면 비용과 시간은 계속해서 증가하게 된다. 이를 해결하기 위해 대표적으로 확률적 경사하강법을 사용하는데, 이러한 방식을 점진적 학습또는 온라인 학습이라고 부른다. 앞서 훈련된 데이터에서의 가중치 값을 유지한 채로, 새로운 데이터에 대해서 조금씩 가중치 값을 업데이트 하는 방식으로 모델은 훈련에 사용한 모든 데이터를 유지할 필요가 없다.
손실함수
손실함수(Loss Function)는 모델의 성능을 측정하는 함수로, 모델의 예측값과 실제 타깃값 사이의 차이를 수치화 한다. 손실함수는 반드시 미분 가능해야한다. 즉 함수 에서 의 변화가 함수에 어떻게 영향을 미치는지 그 변화의 양을 측정할수 있어야 한다. 그래프로 나타낼 수 있는 규칙이 존재 해야한다는 이야기다.
로지스틱 손실함수
이진분류에서의 정확도는 샘플이 얼마나 타깃값을 잘 맞추었느냐에 따라 달려있기 때문에 연속적이라고 말할 수없고, 그에 따라 손실값을 최대한 줄이기 위한 용도로 사용할 수가 없다. 예를 들어 100개의 샘플중 90개를 맞추고 있는 모델이 하나의 샘플을 더 맞추기위해 가중치값을 계속 조정해 나갈때, 정확도는 아무런 변화가 없다가 샘플을 하나 더 맞추는 순간 갑자기 91%로 변할 것이다. 즉 모델이 가중치의 움직임에 따른 정확도의 변화량을 파악하여 어느 방향으로 가중치값을 조정해야할지를 결정할 수가 없다. 이러한 문제를 해결하기 위해 사용하는 것이 로지스틱 손실 함수(Logistic Loss Function) 혹은 이진 크로스엔트로피 손실함수(Binary Cross-entrophy Loss Function) 이라고 부른다.
Formula
- : 실제 타깃 값(0 or 1)
- : 모델의 예측 확률 (sigmoid를 통과한 0-1사이의 확률값)
- 타깃값이 1인경우 : 일 때 , 손실값은 이되고 의 값이 1에 가까울수록 손실값이 0에 가깝게, 0에 가까울수록 무한대로 증가한다.
- 타깃값이 0인경우 : 일 때 , 손실값은 이되고 값이 0에 가까울수록 손실값이 0에 가깝게, 1에 가까울수록 손실은 무한대로 증가한다. (즉, 음성클래스의 예측값을 양성클래스에 대한 예측으로 바꾼다. 예측값이 0.2라면 음성클래스로 분류되는데, 이를 1 - 0.2로 0.8을 만들어 양성클래스에 대한 손실값으로 만든다.)
에포크와 과대/과소적합
에포크(Epoch)란 모델이 학습과정에서 전체 훈련 데이터세트를 한번 완전히 사용하는 것을 의미한다. 확률적 경사하강법 모델에서는 에포크 횟수가 적으면 모델이 경사를 따라 내려오다가 멈추어 과소적합한 모델이 되어 버릴것이고, 반대로 너무 많은 반복은 훈련세트에 과대적합한 모델이 될수 있다. 적절한 학습 반복횟수를 찾아내기위해 과대적합이 시작되기 전 훈련을 멈추는 기법을 조기종료라고 한다.
