미션
기본미션
K-FOLD 교차 검증과정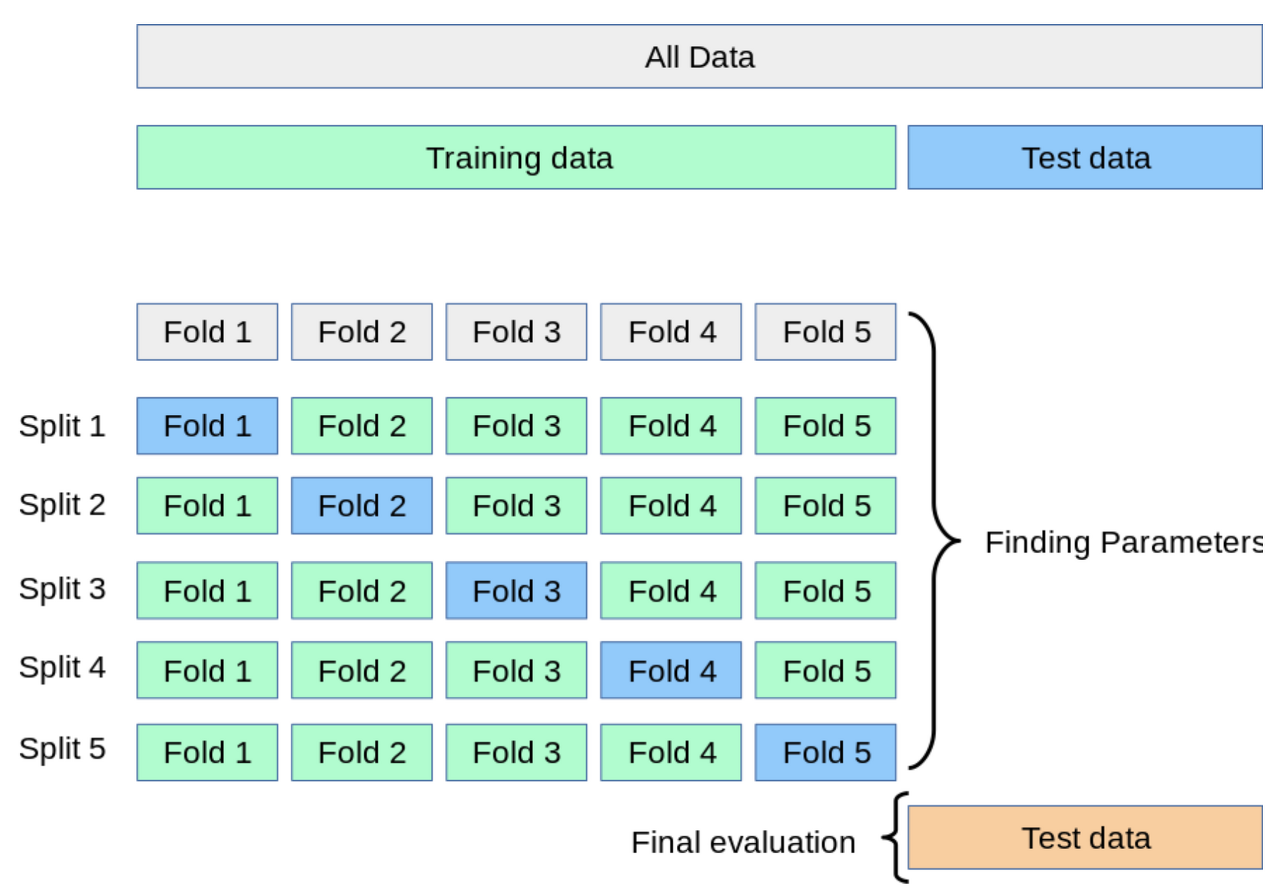
- 전체 데이터 셋을 Training Data Set와 Test Data Set로 나눈다.
- Training Data Set을 K개의 Fold로 나눈다.
- 첫번째 Fold를 Validation Set으로 사용하고, 나머지 Fold를 Training Set으로 사용해 훈련하고 평가한다.
- 차례대로 다음 Fold를 Validation Set으로 사용하고, 나머지 Fold를 Training Set으로 사용해 훈련하고 평가하는 과정을 총 K번 반복한다.
- 총 K개의 평가결과가 나오고, 이 결과를 평균하여 종합적으로 성능을 평가한다.
선택미션
RandomForest
## RandomForest
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier( n_jobs=-1, random_state=42 )
scores = cross_validate( rf, train_input, train_target, return_train_score=True, n_jobs=-1 )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )
rf.fit( train_input, train_target )
print( rf.feature_importances_ )
rf = RandomForestClassifier( oob_score=True, n_jobs=-1, random_state=42 )
rf.fit( train_input, train_target )
print( rf.oob_score_)

순서대로 과대적합된 결과값, 각 특성의 중요도, OOB(Out of bag:부트스트랩에 포함되지 않은 샘플)로 평가한 평균 점수값.
Extra Trees
## Extra Tree
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier( n_jobs=-1, random_state=42 )
scores = cross_validate( et, train_input, train_target, return_train_score=True, n_jobs=-1 )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )
et.fit(train_input,train_target)
print( et.feature_importances_ )
랜덤포레스트와 비슷한 결과값, 각 특성 중요도
Gradients Boosting
## Gradients Boosting
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier( random_state=42 )
scores = cross_validate( gb, train_input, train_target, return_train_score=True, n_jobs=-1 )
print(np.mean(scores['train_score']), np.mean(scores['test_score']))

과대적합이 거의 되지 않은 교차 검증 점수값
gb = GradientBoostingClassifier( n_estimators=500, learning_rate=0.2, random_state=42 )
scores = cross_validate( gb, train_input, train_target, return_train_score=True, n_jobs=-1 )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )
gb.fit( train_input, train_target )
print( gb.feature_importantces_ )
결정트리 갯수를 500까지 늘렸지만, 과대적합이 억제됨.
각 특성의 중요도
Histogram-based Gradient Boosting
## Histogram-based Gradient Boosting
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier( random_state = 42 )
scores = cross_validate( hgb, train_input, train_target, return_train_score=True )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )
from sklearn.inspection import permutation_importance
hgb.fit( train_input,train_target )
result = permutation_importance(hgb, train_input, train_target, n_repeats=10, random_state=42, n_jobs= -1 )
print( result.importances_mean )
result = permutation_importance(hgb, test_input, test_target, n_repeats=10, random_state=42, n_jobs= -1 )
print( result.importances_mean )
hgb.score( test_input, test_target )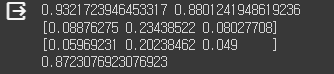
그레디언트 부스팅에 비해 높은 성능, 훈련 데이터 세트와 테스트 세트의 특성 중요도, 테스트 세터에서의 최종 성능.
XGBoost
## XGBClassifier
from xgboost import XGBClassifier
xgb = XGBClassifier( tree_method='hist', random_state=42 )
scores = cross_validate( xgb, train_input, train_target, return_train_score=True )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )

LightGBM
## XGBClassifier
from lightgbm import LGBMClassifier
lgb = LGBMClassifier( random_state=42 )
scores = cross_validate( lgb, train_input, train_target, return_train_score=True, n_jobs=-1 )
print( np.mean(scores['train_score']), np.mean(scores['test_score']) )


이제 진짜 개발하려구요!