5장 비지도 학습
01. 비지도 학습과 군집 알고리즘
정의
군집 알고리즘(Clustering Algorithm)은 비지도학습의 대표적인 예로써 서로 비슷한 특성 값을 갖는 데이터 샘플들을 특정한 그룹으로 분류하는 과정을 이야기한다. 300장의 과일 사진이 있을 때, 각 사진이 가지고 있는 픽셀 데이터 값을 기준으로 비슷한 그룹으로 묶고 새로운 사진이 어떤 그룹에 속하는지를 판별한다던가, 혹은 쇼핑몰의 고객의 데이터를 대상으로 연령, 지역, 성별등의 기준으로 어떤 구매 패턴을 보이는지에 대해 분석하기 위해 사용된다. 이처럼 정답 타깃이 지정되지 않은 채로 주어진 데이터로부터 패턴을 발견하거나 의미 있는 정보를 추출하기 위한 학습방식을 비지도학습(Unsupervised Learning) 이라고 하는데, 명시적인 정답이나 구체적인 결과를 얻을 수는 없지만 인간의 직관으로 파악하기 어려운 방대한 데이터 내의 구조나 관계를 파악할 수 있다.
02. K-평균
K-평균(K-means)알고리즘은 군집 알고리즘 중 하나로, 데이터를 K개의 클러스터로 나누고 각 클러스터를 데이터들의 중심점(Centroid)로 대표하는 간단한 알고리즘 이다.
작동 방식
- 초기화: K개의 클러스터를 대표할 중심점을 무작위로 선택한다.
- 할당 : 각 데이터 샘플들을 가장 가까운 중심점에 할당한다. 보통 유클리드 거리같은 거리 측정 방법을 이용하여 가까움을 측정한다.
- 중심점 업데이트 : 클러스터에 속한 데이터 샘플들의 평균위치 값으로 새로운 데이터 중심점을 이동한다.
- 반복 : 클러스터의 중심점이 더이상 변하지 않거나, 설정한 반복횟수에 도달할 때까지 반복한다.
최적의 K값 찾기
K-평균의 단점은 클러스터의 개수를 사전에 지정해야 한다는 것이다. 완벽한 값을 찾는 방법은 없지만, 각 클러스터링에 대한 효과를 평가하고 자연스러운 그룹 수를 측정하기 위한 몇가지 방법이 존재한다.
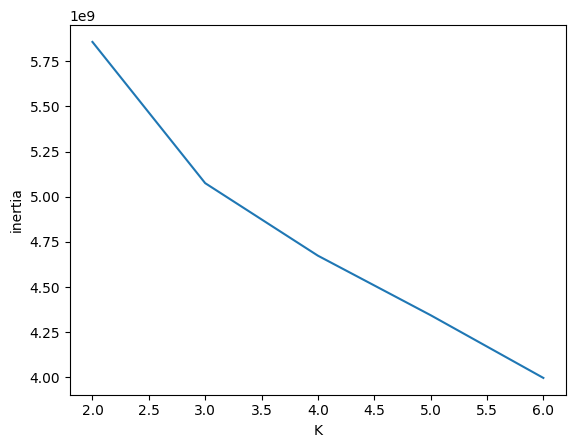
엘보우 방법
엘보우 방법은 클러스터 수 의 변화에 따른 클러스터 중심과 샘플사이의 거리의 제곱의 합(이너셔:Inertia)의 변화를 시각화하여 최적의 값을 찾는 방법이다. 클러스터의 수를 늘려갈수록 이너셔값이 감소하지만, 어느 지점에서는 팔꿈치 처럼 감소율이 급격히 줄어든다. 감소율의 변화가 더이상 의미있지 않을 때 이 지점의 값을 지정한다.
실루엣 방법
실루엣 방법은 클러스터링의 효과를 각 데이터 샘플이 자신이 속한 클러스터와 얼마나 잘 맞는지(응집도:cohension), 다른 클러스터와 얼마나 떨어져 있는지(분리도:separation)를 측정여 -1~1사이의 값으로 나타낸다. 객관적인 수치를 제공하지만, 데이터 셋이 큰 경우 시간이 많이 소요될 수 있다.
- a:응집도 , b:분리도
- 점수가 1에 가까울 때 : 데이터 샘플이 자신의 클러스터에 잘 맞고, 다른 클러스터와 잘 분리되어 있음
- 점수가 0에 가까울 때 : 데이터 샘플이 클러스터의 경계에 위치해 있고, 인접한 클러스터와 구분이 모호함.
- 점수가 -1에 가까울때 : 데이터 샘플이 잘못된 클러스터에 할당되어있음
03. 주성분 분석
정의
주성분 분석(Principal Component Analysis, PCA)은 차원 축소 알고리즘의 대표적인 방법이다. "차원 축소"에서의 차원이란 이전에 정의했던 데이터의 특성을 이야기한다. 만약 하나의 이미지의 10,000개의 픽셀이 있고 각 다른 색상 값을 가진다면 이 이미지는 10,000개 차원을 가지고 있고, 비슷한 수만장의 데이터로 학습을 진행한다면 비용과 시간이 매우 많이 들 수밖에 없다. 이런 많은 차원(특성)의 데이터를 분석하여 데이터의 주성분을 찾아 저차원으로 변환하여 데이터를 간략화하고, 노이즈를 제거하거나 주요 특성을 파악하여 요약하기 위해 쓰인다.
