
학습
- 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
- 손실함수가 최소화되는 쪽으로 학습
- 선형 분리 가능 문제는 유한 번의 학습을 통해 풀 수있다는 사실이 퍼셉트론 수렴 정리로 증명됨
손실함수
- 오차제곱합 (sum of squares for error, SSE)
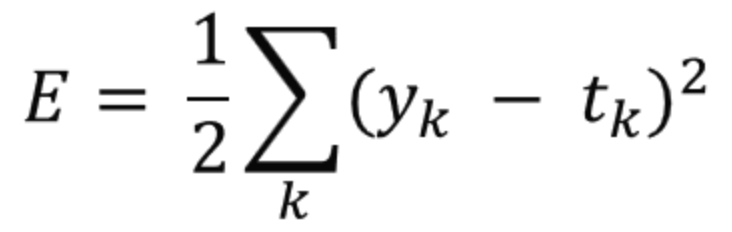
- yk는 신경망이 추정한 값
- tk는 정답 레이블
- k는 데이터의 차원 수
- 교차 엔트로피 오차 (cross entropy error, CEE)
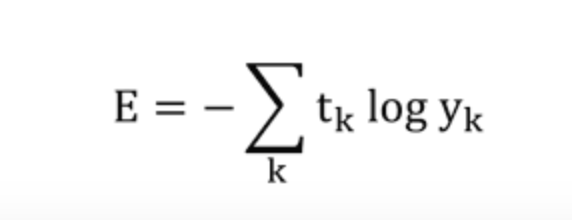
- 로그의 밑은 e
- 구현시, 마이너스 무한대가 되지 않도록 yk에 아주 작은 값인 delta를 추가로 더해줌
미니 배치 학습
- 훈련 데이터가 너무 많을 때, 일부만 무작위로 골라 학습에 사용하는 방법
경사 하강법 (gradient descent method)
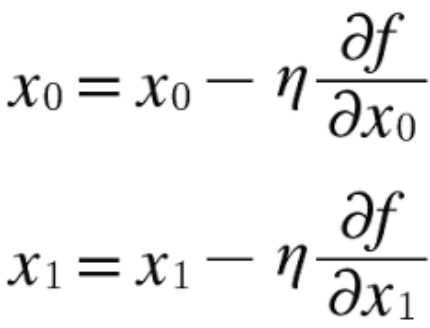
-
에타는 학습률 (갱신되는 양)
-
학습률이 너무 크면 큰 값으로 발산해버리고, 너무 작으면 거의 갱신되지 않은 채 끝나버림
-
학습률은 하이퍼파라미터 ( 시험을 통해 최적의 값을 사람이 직접 설정해야 함)
-
매개변수의 값을 갱신하는 방법. 신경망 학습에서 사용
-
현위치에서 기울어진 방향으로 일정 거리만큼 이동
-
함수의 극소값을 찾기 위해 정해진 만큼 수행. (잘하면 최소값도 가능)
-
f는 최적화하려는 함수 (손실함수)
- 손실함수가 최소값이 되는 매개변수를 찾아야함
확률적 경사 하강법 (stochastic gradient descent, SGD)
- 데이터를 미니 배치로 가져와서 경사하강법을 시행하는 것
SSAFY 9기, 네이버 부스트캠프 AI Tech 7기
늘 멋져요~!