'운세 강화게임과 결합된 새로운 경험의 데일리 운세 플랫폼' '아그작' 프로젝트의 시간 단위 랭킹 기능에서, 단일 MySQL 테이블 +
ORDER BY정렬만으로는 실시간성·운영 안정성·과거 조회 세 가지 요구를 동시에 만족시키지 못한다는 한계를 확인하였습니다. 이를 Redis ZSET 기반 실시간 랭킹 + MySQL 스냅샷 보관소 라는 이중 저장 구조로 분리한 의사결정 과정을 정리한 내용입니다.
1. 들어가며
아그작은 사용자가 받은 오늘의 운세 점수 를 기반으로 다음 세 가지 랭킹을 제공합니다.
| 랭킹 종류 | 정렬 기준 |
|---|---|
| Total | 강화 후 최종 총점 |
| Original | 강화 전 원래 총점 |
| Gain (증가율) | (final − original) / original |
처음에는 단순하게 Fortune 테이블을 그날 날짜로 조회한 뒤 메모리 정렬로 응답하였으나, 실제 운영 환경에 올린 후 다음과 같은 문제를 마주하였습니다.
- 매 요청마다 풀스캔 + ORDER BY 발생
- "내 등수 가져오기" 가 별도 카운트 쿼리로 분기되어 비용이 또 발생
- 어제·과거 일자 랭킹을 보고 싶은 요구가 생김 — 이때는 운세 데이터가 변경되어도 그 시점의 순위가 보존 되어야 함
본문은 다음 흐름으로 정리합니다.
- 문제 상황 — 단일 MySQL 정렬 기반 구현의 한계
- 본질 재정의 — "실시간 랭킹" 과 "스냅샷" 은 다른 자료구조가 필요하다
- Redis ZSET(실시간) + MySQL Ranking(스냅샷) 이중 저장
- 동기화 전략 — 시간당 reseed + 매시간 스냅샷
- 측정 결과
- 회고 및 정리
2. 문제 상황 — 단일 MySQL 정렬 기반 구현의 한계
초기 구현은 Fortune 테이블을 날짜 기준으로 조회한 뒤, 애플리케이션에서 정렬 + 페이징으로 잘라 응답하는 단순 구조였습니다.
// 의사 코드 — 초기 구현
List<Fortune> fortunes = fortuneRepository.findAllByDateWithMember(today);
return fortunes.stream()
.sorted(Comparator.comparingInt(Fortune::getTotalScore).reversed())
.limit(limit)
.map(this::toRankingItem)
.toList();확인된 문제점은 다음과 같습니다.
| 항목 | 문제 |
|---|---|
| 매 요청 풀스캔 | 같은 날 데이터가 변경되지 않아도 매번 전체 행을 읽음 |
| 세 가지 정렬 모두 메모리 처리 | Total / Original / Gain 각 기준으로 매번 정렬 |
| 내 등수 조회 추가 비용 | 사용자별 등수는 결국 같은 결과를 한 번 더 정렬·인덱싱 |
| 과거 일자 보존 X | Fortune 데이터가 갱신되면, 어제 랭킹의 "그 시점" 결과가 사라짐 |
| 초마다 갱신되는 점수 반영 어려움 | 게임으로 점수가 자주 바뀌는데 매번 DB 정렬을 다시 도는 구조 |
특히 마지막 항목 — "어제 랭킹은 어제 그대로 보존" + "오늘 랭킹은 점수가 바뀔 때마다 즉시 반영" — 두 요구를 단일 테이블 + 정렬만으로는 깨끗하게 표현하기 어려웠습니다.
3. 본질 재정의 — 실시간 랭킹과 스냅샷은 다른 자료구조가 필요하다
요구사항을 다시 정리하면 다음과 같습니다.
| 요구 | 특성 | 적합한 자료구조 |
|---|---|---|
| 오늘 랭킹 | 점수 변동이 잦고, 즉시 정렬된 상태가 필요 | 정렬 자료구조 in-memory (Redis ZSET) |
| 과거 일자 랭킹 | 이미 확정된 결과, 영속 보관 + 가끔 조회 | RDB 스냅샷 테이블 (MySQL) |
| 내 등수 | "이 사용자의 현재 등수" 단건 조회 | ZSET ZREVRANK 또는 스냅샷 rank_no 컬럼 |
MySQL 은 정형 + 영속 보관에 강하고, ZSET 은 정렬 상태 자체를 자료구조로 들고 있는 구조입니다.
두 영역은 요구되는 갱신 빈도와 정렬 비용이 근본적으로 다릅니다.
→ "오늘 랭킹은 Redis ZSET 으로, 과거 일자는 MySQL 스냅샷 테이블로" 저장소 자체를 분리 하기로 의사결정하였습니다.
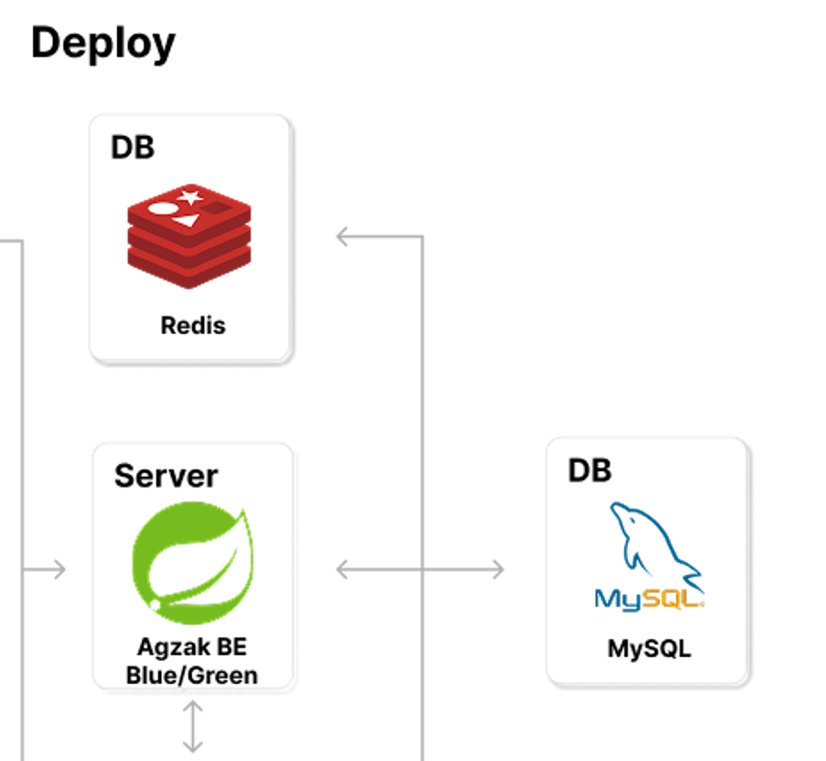
4. Redis ZSET (실시간) + MySQL Ranking (스냅샷)
시스템 구성
점수 변경 이벤트
사용자 → Fortune 갱신 → refreshTodayForMember(memberId)
│
▼
┌────────────────┐
│ Redis ZSET │ ← 오늘 랭킹 실시간
│ HASH (user) │
└───────┬────────┘
│ 매시간 59분 55초
▼ rebuildTodaySnapshot()
┌────────────────┐
│ MySQL ranking │ ← 과거 일자 보관
└────────────────┘
▲
│ 매시간 55분 reseed (정합성 보정)
┌───────┴────────┐
│ MySQL fortune │
└────────────────┘Redis 키 설계
// rank:20251119:total ZSET (memberId → totalScore)
// rank:20251119:original ZSET (memberId → originalScore)
// rank:20251119:gain ZSET (memberId → 증가율 %)
// rank:20251119:user:42 HASH (nickname/total/original)
private String key(LocalDate d, String suffix) {
return "rank:" + d.format(DAY) + ":" + suffix;
}
public String zTotal(LocalDate d) { return key(d, "total"); }
public String zOriginal(LocalDate d) { return key(d, "original"); }
public String zGain(LocalDate d) { return key(d, "gain"); }
public String hUser(LocalDate d, Long memberId){ return key(d, "user:"+memberId); }ZSET 에는 점수만, HASH 에는 닉네임/원본 점수 등 부가 정보 를 분리 저장하여 ZSET 조회 시 메모리·네트워크 비용을 줄였습니다.
RedisInsight 로 실제 키 구조를 보면, rank:20251125 네임스페이스 아래에 total / original / gain 세 ZSET 과 사용자별 HASH 가 함께 적재된 것이 보입니다.
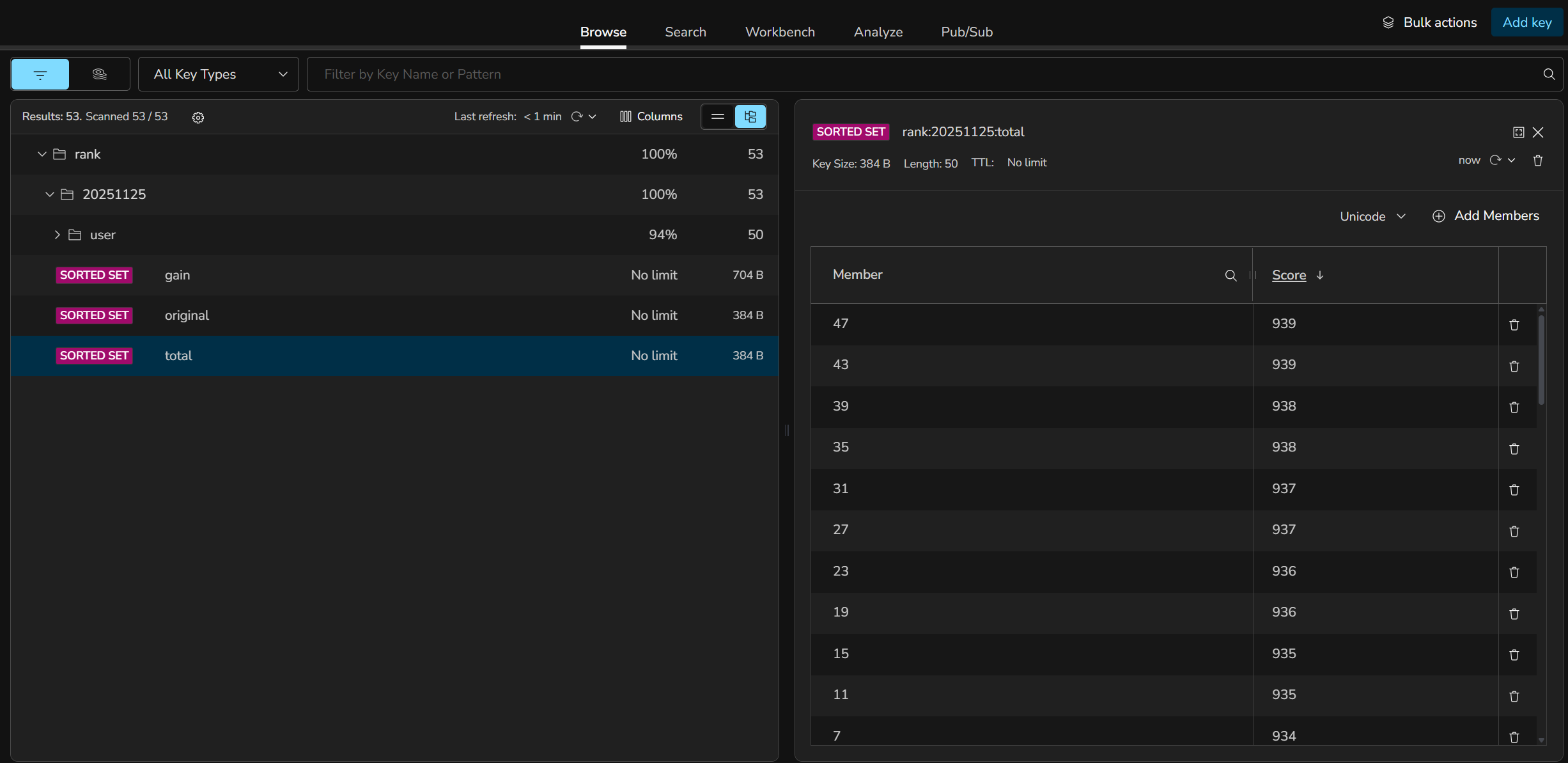
total ZSET 옆에는 동일 날짜의 original (강화 전 점수 기준) ZSET 도 함께 보관되어, 같은 사용자에 대해 정렬 기준만 다른 두 결과를 곧바로 꺼낼 수 있습니다.
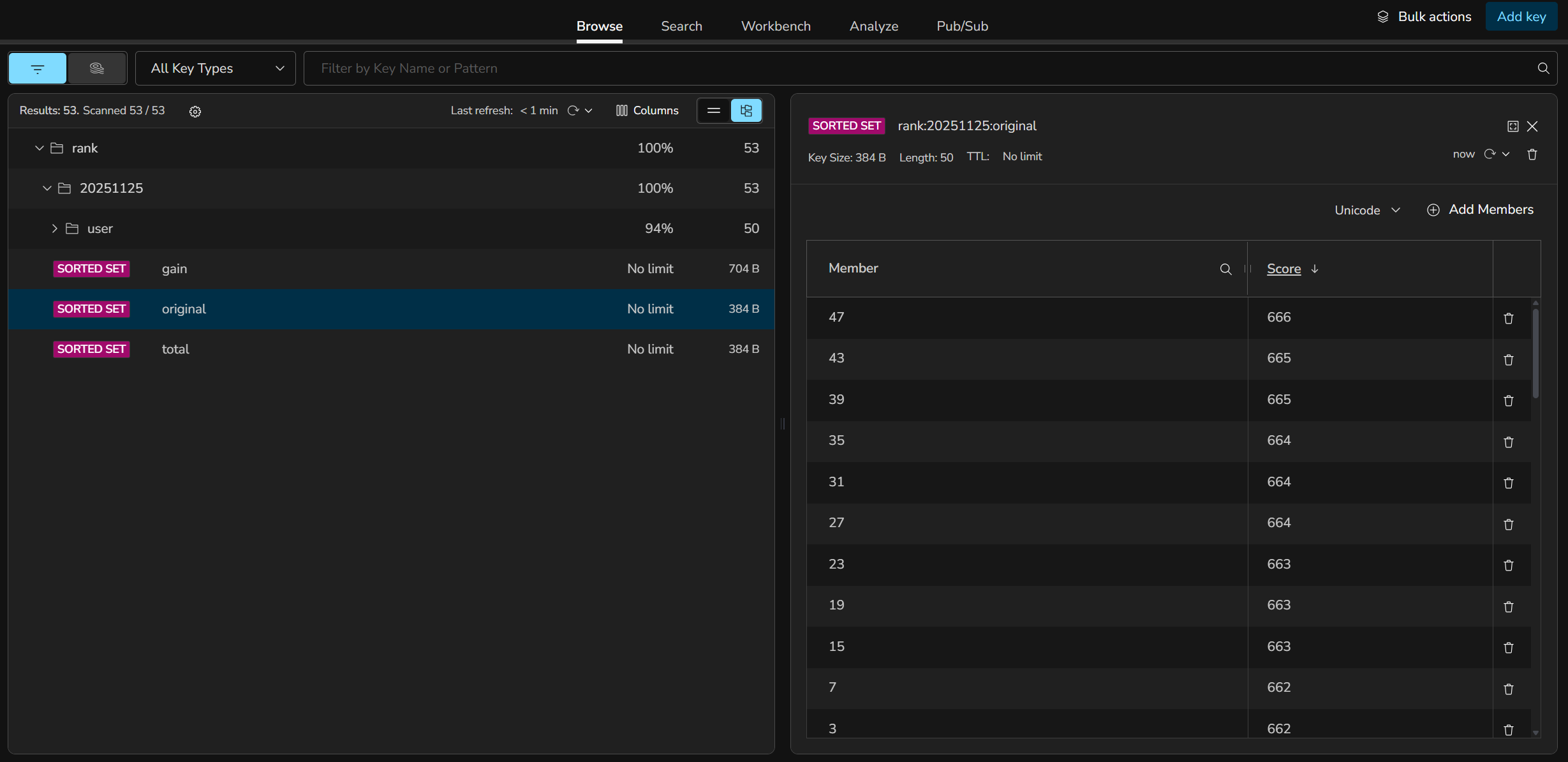
점수 변경 → 즉시 반영
운세 점수가 바뀌는 모든 도메인 이벤트(쿠키 굽기·먹기 등) 직후 다음 메서드가 호출됩니다.
public void upsertTodayUser(Long memberId, String nickname,
Integer total, Integer original) {
LocalDate d = today();
double gain = RankCalculator.increasePct(original, total);
redis.executePipelined((RedisCallback<Object>) connection -> {
HashOperations<String, String, String> h = redis.opsForHash();
ZSetOperations<String, String> z = redis.opsForZSet();
if (nickname != null) h.put(hUser(d, memberId), "nickname", nickname);
if (total != null) h.put(hUser(d, memberId), "total", String.valueOf(total));
if (original != null) h.put(hUser(d, memberId), "original", String.valueOf(original));
if (total != null) z.add(zTotal(d), String.valueOf(memberId), total.doubleValue());
if (original != null) z.add(zOriginal(d), String.valueOf(memberId), original.doubleValue());
z.add(zGain(d), String.valueOf(memberId), gain);
return null;
});
}ZSET ZADD 는 O(log N) 으로 끝나기 때문에, 점수 갱신 자체가 DB 정렬 한 번보다 압도적으로 가볍습니다.
TOP N 읽기
// 오늘 TOP N — Redis 만으로 끝남
public List<UserRow> readTop(LocalDate d, String zset, int limit) {
Set<TypedTuple<String>> rows =
redis.opsForZSet().reverseRangeWithScores(zset, 0, Math.max(0, limit-1));
// ZSET 결과 + HASH 보강 후 반환
// ...
}ZREVRANGE 0 N-1 WITHSCORES 한 번이면 정렬된 상태가 그대로 나옵니다.
"내 등수" 단건 조회
public Integer zrevRank1Base(String zset, long memberId) {
if (!redis.hasKey(zset)) return null;
Long zero = redis.opsForZSet().reverseRank(zset, String.valueOf(memberId));
return zero == null ? null : (int)(zero + 1);
}ZREVRANK 는 O(log N) 으로 등수를 바로 반환합니다. 별도 카운트 쿼리·메모리 정렬 없이 끝납니다.
5. 동기화 전략 — 시간당 reseed + 매시간 스냅샷
Redis 가 빠르고 가볍지만, 단일 실패점이 되면 곤란 합니다. 따라서 두 가지 동기화 잡을 두어 정합성·내구성을 함께 챙겼습니다.
시간당 Reseed (MySQL → Redis)
@Scheduled(cron = "0 55 * * * *", zone = "Asia/Seoul")
@SchedulerLock(name = "rankingReseed", lockAtMostFor = "PT4M", lockAtLeastFor = "PT10S")
public void hourlyReseedRedis() {
rankingService.reseedRedisFromMysqlToday();
rankingService.pruneTodayOrphans();
}@Transactional
public void reseedRedisFromMysqlToday() {
LocalDate today = redisStore.today();
var fortunes = mysqlStore.fortunes(today);
if (fortunes.isEmpty()) return;
// ZSET 사이즈와 MySQL 행 수가 다르면 리씨드
Long zcard = redisStore.zcard(redisStore.zTotal(today));
boolean needsReseed = (zcard == null) || (zcard.intValue() != fortunes.size());
if (!needsReseed) return;
var rows = fortunes.stream().map(...).toList();
try {
redisStore.bulkUpsertTodayUsers(rows);
} catch (Exception e) {
log.warn("Redis reseed failed: {}", e.getMessage());
}
}핵심 포인트:
ZCARD와 MySQL 행 수가 같으면 noop — 매시간 강제로 갈아엎지 않음- 다르면 bulk upsert 로 ZSET·HASH 한 번에 채움 (Redis 파이프라이닝)
- 실패해도 예외를 그대로 던지지 않고 로그만 — Redis 가 잠깐 문제여도 다음 요청에서 회복
매시간 스냅샷 (Redis → MySQL ranking)
@Scheduled(cron = "55 59 * * * *", zone = "Asia/Seoul")
@SchedulerLock(name = "rankingSnapshot", lockAtMostFor = "PT4M", lockAtLeastFor = "PT20S")
public void todayRebuild() {
rankingService.rebuildTodaySnapshot();
}@Transactional
public void rebuildTodaySnapshot() {
LocalDate today = redisStore.today();
var all = redisStore.readTop(today, redisStore.zTotal(today), Integer.MAX_VALUE);
if (all == null || all.isEmpty()) {
mysqlStore.replaceTodaySnapshot(today, List.of());
return;
}
// 탈퇴 회원 등 고아 데이터 제거
Set<Long> ids = all.stream().map(UserRow::memberId).collect(Collectors.toSet());
Set<Long> alive = mysqlStore.existingMemberIds(ids);
int rank = 1;
List<Ranking> rows = new ArrayList<>(alive.size());
for (var r : all) {
if (!alive.contains(r.memberId())) continue;
rows.add(Ranking.builder()
.member(mysqlStore.refMember(r.memberId()))
.date(today).rankNo(rank++)
.totalScore(r.total()).originalTotalScore(r.original())
.build());
}
mysqlStore.replaceTodaySnapshot(today, rows);
}스냅샷 단계에서 회원 탈퇴 등으로 발생한 Redis 고아 데이터 를 정리하는 로직을 함께 둠으로써, ZSET 이 시간이 지날수록 부풀어 오르는 문제를 막았습니다.
스냅샷이 끝난 직후 MySQL ranking 테이블을 보면, 해당 일자의 ZSET 결과가 (member_id, date, rank_no, total_score, original_total_score) 컬럼에 rank_no 1번부터 차례대로 영속 저장되어 있는 것을 확인할 수 있습니다.
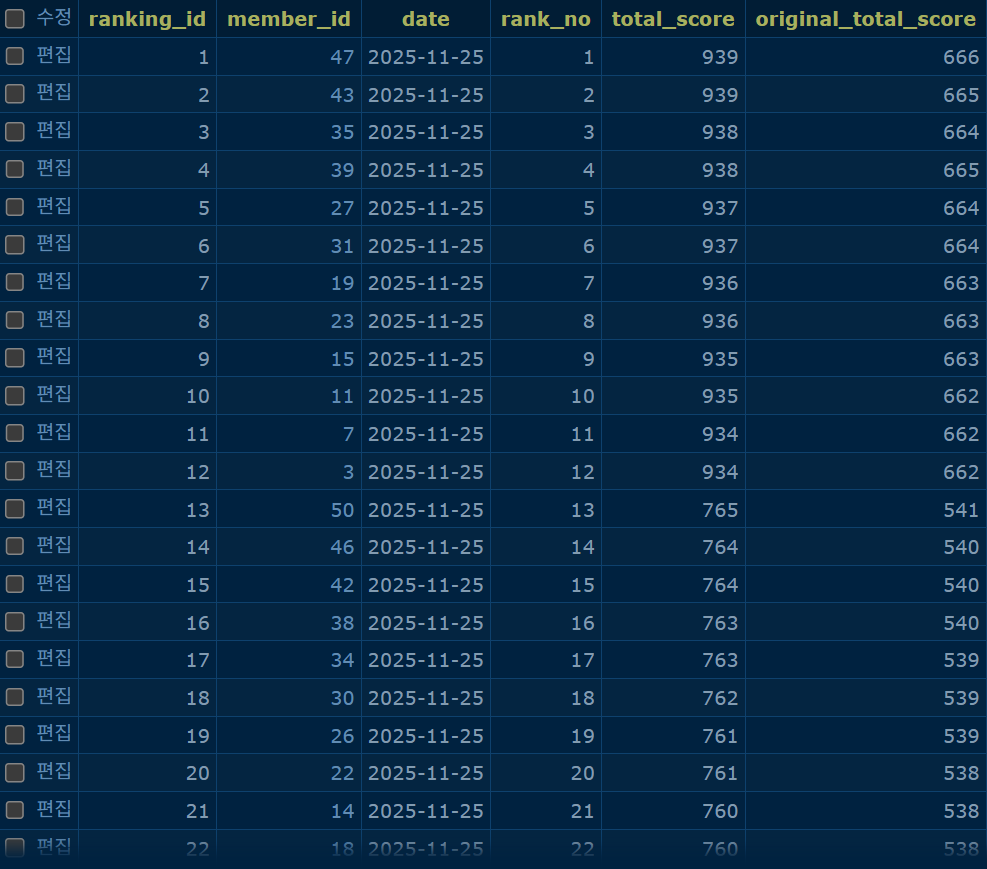
이 시점 이후로는 Fortune 의 점수가 다시 갱신되더라도 이미 영속 저장된 과거 일자 랭킹은 더 이상 흔들리지 않습니다. 어제 1등이었던 사용자는 오늘 점수가 어떻게 변하든 어제 시점에서는 그대로 1등입니다.
참고 — 두 스케줄러는 모두
@SchedulerLock으로 보호됩니다.
Blue/Green 두 컨테이너가 떠 있어도 한쪽만 실제 실행됩니다.
자세한 배경은 별도 포스팅 새벽 랭킹 스케줄러 Deadlock 트러블슈팅 에 정리하였습니다.
읽기 fallback
Redis 가 아예 죽어 있는 상황을 대비하여 읽기 경로에는 fallback 을 두었습니다.
public RankingListDto getTodayTopN(int limit) {
LocalDate d = redisStore.today();
try {
var total = redisStore.readTop(d, redisStore.zTotal(d), limit);
var original = redisStore.readTop(d, redisStore.zOriginal(d), limit);
var gain = redisStore.readTop(d, redisStore.zGain(d), limit);
if (모두 비어있으면) return getSnapshotTopN(d, limit); // MySQL 스냅샷
return /* Redis 결과 가공 */;
} catch (Exception e) {
return getSnapshotTopN(d, limit); // MySQL 스냅샷
}
}오늘 랭킹이라도 Redis 에 데이터가 없거나 예외가 나면, 마지막 정시 스냅샷 으로 자동 대체됩니다. 사용자 입장에서는 잠시 갱신이 멈춘 것처럼 보이지만, 5xx 에러는 발생하지 않습니다.
6. 측정 결과
참고
본 프로젝트는 실 사용자 트래픽이 큰 상용 서비스가 아닌 개발·배포 단계의 자율 프로젝트이므로, 아래 수치는 EFK 수집 로그와 MySQL Slow Query 카운트, 자체 부하 테스트 기반 입니다.
Before vs After (랭킹 응답 경로)
| 항목 | Before (MySQL ORDER BY) | After (Redis ZSET) |
|---|---|---|
| 오늘 TOP 100 응답 | Fortune 풀스캔 + 메모리 정렬 | ZREVRANGE 0 99 단건 |
| 세 가지 정렬 (total/orig/gain) | 정렬 3회 / 메모리 | ZSET 3개 — 각 O(log N) |
| 내 등수 조회 | 별도 SELECT + 정렬 | ZREVRANK O(log N) |
| 과거 일자 조회 | Fortune 변경 시 결과 변동 | ranking 스냅샷에서 그대로 보존 |
| Slow Query 발생 빈도 | 측정됨 | 0건 유지 (운영 기간 동안) |
운영 모니터링 — Slow Query 0건 유지
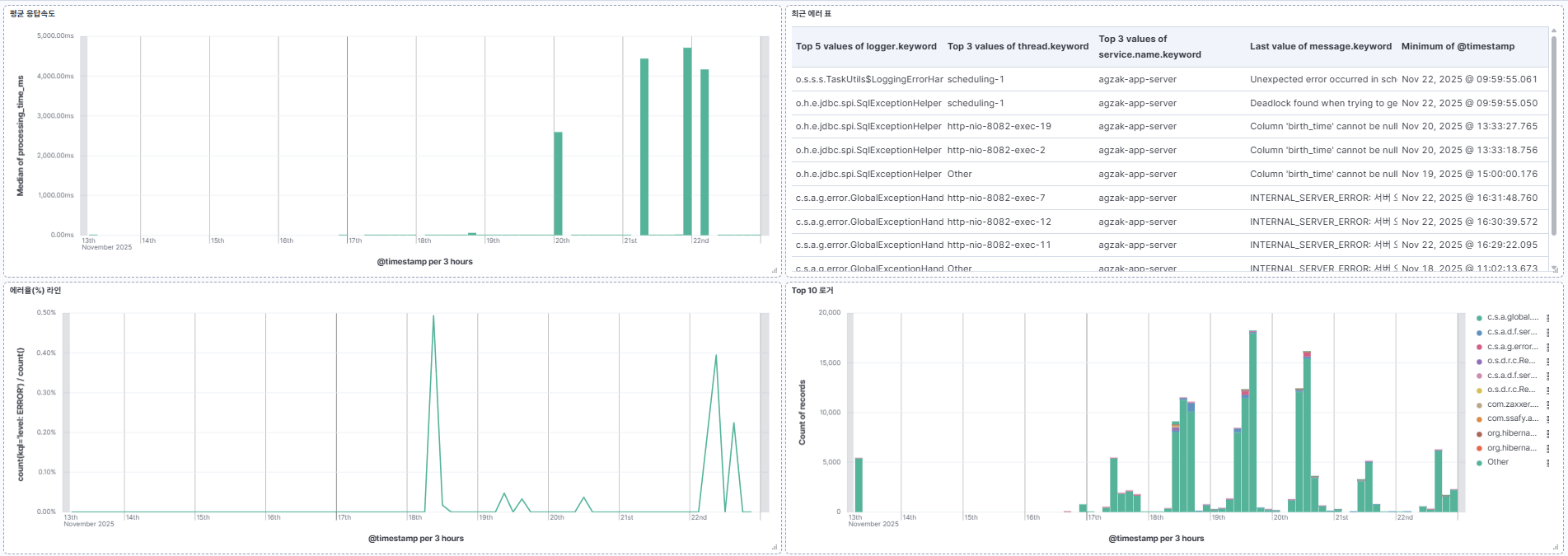
런칭 직후에는 MySQL QPS 가 일시적으로 300~500 까지 튀는 구간이 있었으나, 이번 저장소 분리 이후 일상 QPS 가 한 자리 수까지 내려갔고, EFK 기반 일별 리포트에서 추적한 Slow Query 카운트는 0건 으로 유지되었습니다.
또한 EFK 파이프라인을 통해 일별·주별 로그 분포를 Kibana 대시보드에서도 확인하였습니다.
사용자 체감
- 게임을 통해 점수를 강화한 직후 랭킹 페이지에서 즉시 반영 되는 모습 확인 (캐시 TTL 대기 X)
- 과거 일자(전날·전주) 랭킹은 그 시점 그대로 보존 — Fortune 데이터가 갱신되어도 흔들리지 않음
7. 회고 및 정리
같은 "랭킹" 이라도 요구가 다르면 저장소를 분리해야 합니다.
갱신 빈도·보존 요구·정렬 비용이 다른 두 도메인을 단일 테이블에 끼워 맞추려 했던 것이 비용을 키운 원인이었습니다.
ZSET 은 "정렬 결과를 자료 구조로 갖는 것" 입니다.
ORDER BY 가 매번 정렬 비용을 지불하는 반면, ZSET 은 ZADD 시점에 O(log N) 으로 정렬 상태를 유지합니다. ZREVRANGE / ZREVRANK 는 그 상태를 그대로 꺼내기만 합니다.
fallback + reseed 없는 Redis 1차 저장소는 단일 장애점입니다.
읽기 fallback(MySQL 스냅샷 대체), 시간당 reseed(정합성 자동 회복), 고아 데이터 prune — 세 가지를 함께 뒀기 때문에 운영 부담 없이 유지할 수 있었습니다.
마무리
본 포스팅에서는 랭킹 데이터를 Redis ZSET 실시간 + MySQL 스냅샷 보관 두 저장소로 분리한 의사결정 과정을 정리하였습니다.
핵심 요약
- 점수 갱신 즉시 반영은 ZSET
ZADD(O(log N)). - TOP N 응답은
ZREVRANGE단건 호출 로 정렬 비용 0. - "내 등수" 는
ZREVRANK로 별도 쿼리 없이. - 과거 일자는 MySQL
ranking스냅샷 으로 영속 보존.
