'운세 강화게임과 결합된 새로운 경험의 데일리 운세 플랫폼' '아그작' 프로젝트에서, 자정에 도는 랭킹 스냅샷 스케줄러가 새벽 시간대에만 Deadlock 으로 죽는 패턴을 발견하였습니다. Grafana Alert → Mattermost 로 새벽 에러를 실시간 감지한 뒤 원인을 추적하고, ShedLock + Redis 분산 락 + 매시간 분할로 해결한 과정을 정리한 내용입니다.
1. 들어가며
아그작은 사용자의 오늘 운세 점수를 기반으로 시간 단위 랭킹 을 제공하는 서비스입니다. 초기에는 매일 23:59 에 단 한 번 그날치 랭킹 스냅샷을 새로 갈아끼우는 단순 cron 으로 동작하고 있었으나, 자정 직후 새벽 시간대에 간헐적으로 Deadlock 예외 가 발생하는 현상을 확인하였습니다.
TaskUtils$LoggingErrorHandler : Unexpected error occurred in scheduled task
SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction낮 시간대에 동일 스케줄러를 임의로 트리거해 보면 문제 없이 돌고 있었기에, "왜 새벽에만 터지는가" 를 출발점으로 원인을 추적하였습니다.
본문은 다음 흐름으로 정리합니다.
- 문제 상황 진단 — Grafana Alert 로 새벽 에러 감지
- 기존 스케줄러 구조와 운영 환경 분석
- 원인 — Blue/Green 두 컨테이너의 스케줄러 동시 실행
- ShedLock + Redis 분산 락 적용 (매시간 분할 포함)
- 측정 결과 및 회고
2. 문제 상황 진단 — Grafana Alert → Mattermost
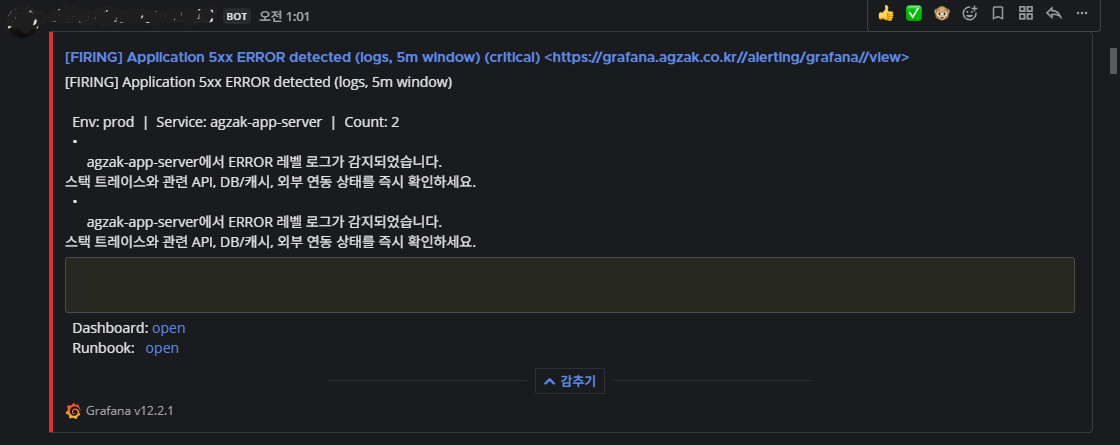
운영에는 EFK + Prometheus + Grafana 기반의 모니터링 체계가 구축되어 있었고, 5xx 또는 ERROR 레벨 로그가 5분 윈도우 내에 임계치를 넘으면 Mattermost 로 알림이 전달되도록 설정되어 있었습니다.
함께 운영 채널에는 다음과 같이 데드락 메시지를 직접 식별 한 캡처도 남아 있습니다.

[FIRING] Application 5xx ERROR detected (logs, 5m window) (critical)
Env: prod | Service: agzak-app-server | Count: 2
- 최근 5분 이내 ERROR 레벨 로그가 발생했습니다.해당 알림을 통해 새벽 시간대에 다음과 같은 패턴으로 ERROR 가 발생되고 있다는 사실을 확인하였습니다.
| 항목 | 내용 |
|---|---|
| 발생 시각 | KST 기준 새벽 (01:00 ~ 01:05 부근) |
| 주기 | 23:59 cron (1일 1회) — 발화 후 자정대 ERROR 누적이 5분 윈도우 임계치를 넘기면서 알림 발송 |
| 메시지 | Deadlock found when trying to get lock; try restarting transaction |
| 영향 | 그날치 랭킹 스냅샷이 깨지거나 누락 |
3. 기존 스케줄러 구조와 운영 환경 분석
문제가 일어난 스케줄러는 RankingScheduler 의 단일 메서드입니다. 당시에는 하루 한 번 23:59 에 그날치 랭킹을 통째로 갈아끼우는 단순 cron 이었습니다.
@Component
@EnableScheduling
@RequiredArgsConstructor
public class RankingScheduler {
private final RankingService rankingService;
/** 매일 23:59: 그날치 ranking 스냅샷을 통째로 재생성 */
@Scheduled(cron = "0 59 23 * * *", zone = "Asia/Seoul")
public void todayRebuild() {
rankingService.rebuildTodaySnapshot();
}
}rebuildTodaySnapshot() 의 핵심은 해당 날짜 스냅샷을 통째로 교체 하는 부분입니다.
@Transactional
public void replaceTodaySnapshot(LocalDate date, List<Ranking> rows) {
rankingRepository.deleteByDate(date); // ① 그날치 ranking 전부 삭제
if (rows != null && !rows.isEmpty()) {
rankingRepository.saveAll(rows); // ② 새 랭킹 일괄 INSERT
}
}운영 환경은 다음과 같이 구성되어 있습니다.
- AWS EC2 단일 인스턴스 위에 Docker compose 로 서비스 기동
- 백엔드는 Blue/Green 무중단 배포 구조 — 두 컨테이너(
agzak-app-blue,agzak-app-green) 가 nginx 뒤에서 트래픽을 나눠 받음 - 두 컨테이너 모두 동일한 MySQL/Redis 를 바라봄
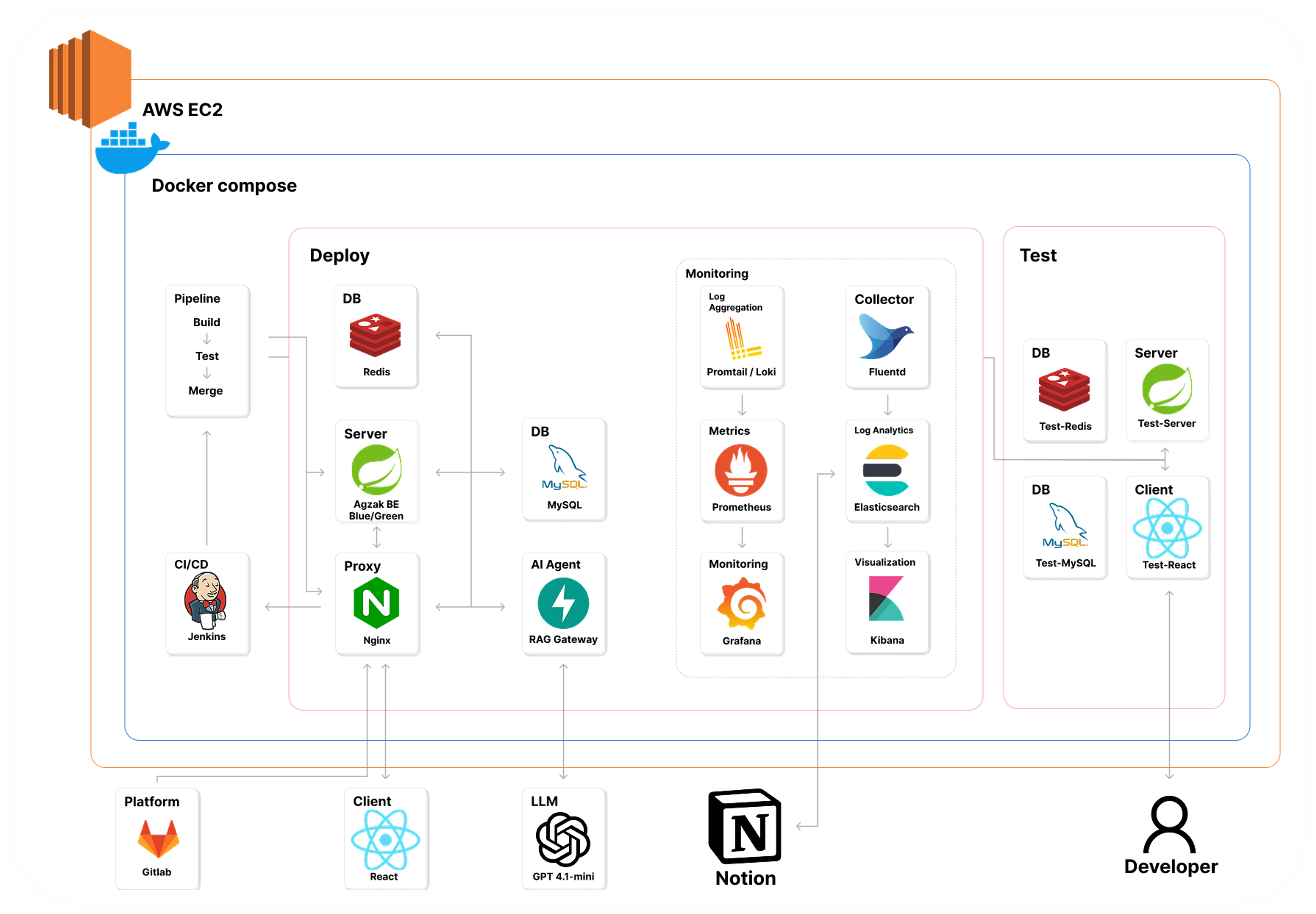
CI/CD 부분만 따로 보면 다음과 같이 Jenkins → Spring BE(Blue/Green) → Nginx 흐름이 잡혀 있습니다.
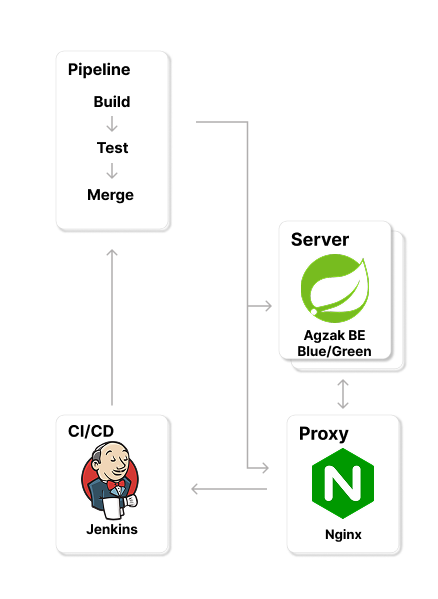
이 환경에서 "왜 동시에 두 인스턴스가 같은 스케줄러를 돌고 있는가?" 가 사건의 진짜 원인이 됩니다.
4. 원인 — Blue/Green 두 컨테이너의 스케줄러 동시 실행
@Scheduled 어노테이션은 각 JVM 마다 독립적으로 동작 합니다. 즉 Blue 와 Green 두 컨테이너가 동시에 떠 있는 상태에서는, 양쪽이 같은 cron 시각에 동일한 스케줄러를 동시에 실행 합니다.
이 상태에서 두 컨테이너가 23:59 정각에 동시에 다음을 수행하게 됩니다.
[Blue] TX-A: DELETE FROM ranking WHERE date = '2025-11-18'
[Green] TX-B: DELETE FROM ranking WHERE date = '2025-11-18'
[Blue] TX-A: INSERT INTO ranking (...) VALUES (...) x N
[Green] TX-B: INSERT INTO ranking (...) VALUES (...) x Nranking 테이블에는 (member_id, date) 복합 유니크 제약과 (date, rank_no) 인덱스가 잡혀 있습니다.
@Table(
name = "ranking",
uniqueConstraints = {
@UniqueConstraint(name = "UQ_ranking_member_date", columnNames = {"member_id", "date"})
},
indexes = { @Index(name = "IDX_ranking_date_rank", columnList = "date, rank_no") }
)이 구조에서는 다음 시나리오로 Deadlock 이 발생합니다.
| 단계 | Blue (TX-A) | Green (TX-B) |
|---|---|---|
| ① | DELETE row 1~50 (gap lock + row lock) | (대기) |
| ② | (대기) | DELETE row 51~100 |
| ③ | INSERT (member=10, date=오늘) — TX-B 가 잡은 락 대기 | INSERT (member=20, date=오늘) — TX-A 가 잡은 락 대기 |
| ④ | Deadlock victim 선정 → 한쪽 ROLLBACK |
참고
InnoDB 는 인덱스 단위로 락을 잡고,DELETE ... WHERE date = ?는 인덱스 범위 락(gap + record lock) 을 광범위하게 점유합니다. 두 트랜잭션이 같은 범위에 동시에 들어오면 락 획득 순서가 어긋나는 순간 Deadlock 이 발생할 수 있습니다.
실제로 동일 시나리오를 로컬에서 재현하여 SHOW ENGINE INNODB STATUS 의 LATEST DETECTED DEADLOCK 섹션을 확인하면, 두 트랜잭션이 서로의 gap lock 을 기다리다 한쪽이 victim 으로 롤백되는 구조가 그대로 드러납니다.
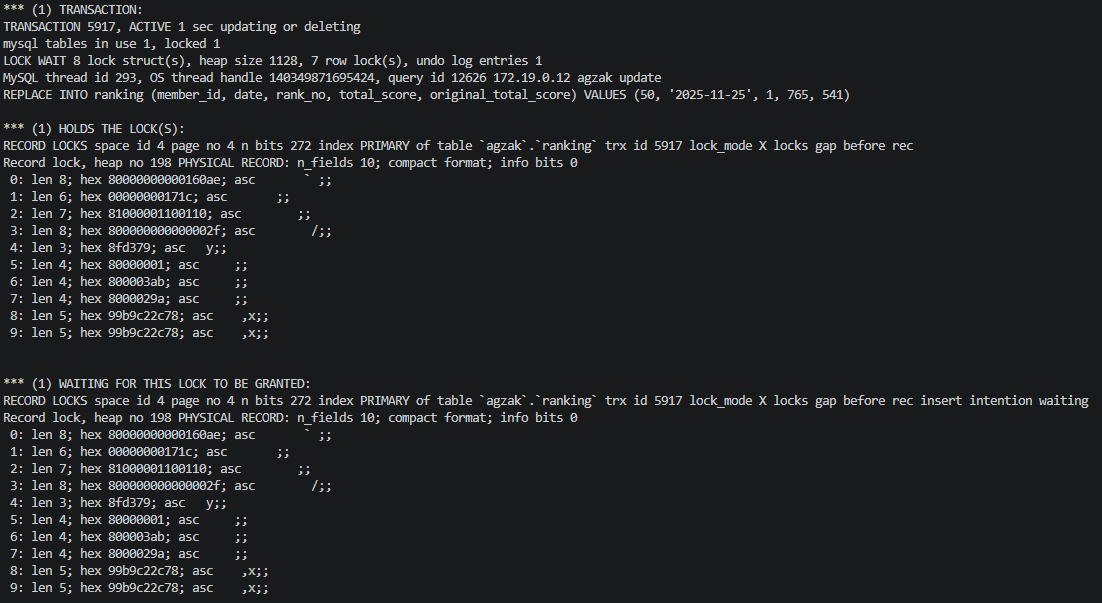
위 캡처는 Blue 컨테이너의 트랜잭션이 ranking 테이블 PRIMARY 인덱스 위에서 lock_mode X locks gap before rec 를 보유한 채로 자신의 insert intention 락을 또다시 기다리고 있는 상태를 보여줍니다. Green 쪽도 같은 상태에 들어가면 InnoDB 가 한쪽을 victim 으로 골라 ROLLBACK 합니다.
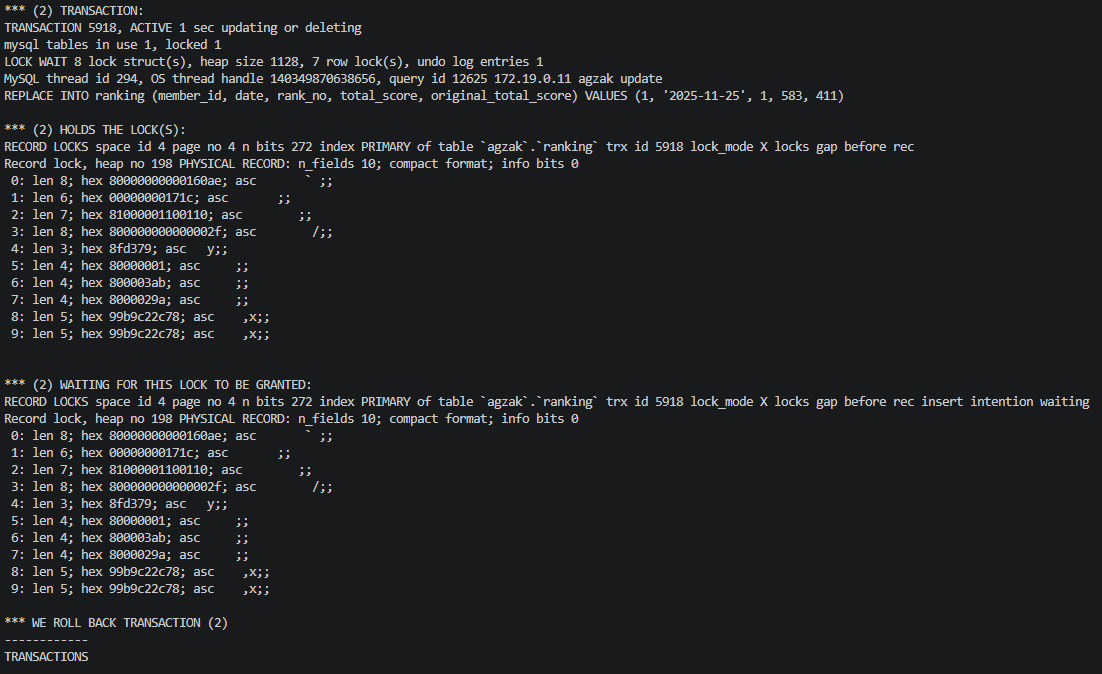
InnoDB 가 *** WE ROLL BACK TRANSACTION (2) 로 victim 을 명시하는 부분이 운영 환경에서 보이던 Deadlock found when trying to get lock; SQLState 40001 의 직접적인 원인이었습니다.
그렇다면 왜 새벽(자정 직후)에만 터지는가?
당시 스케줄러는 매일 23:59 단 한 번 만 도는 cron 이었기 때문에, 매일 같은 시각에 두 컨테이너가 거의 밀리초 단위로 동시에 트리거됩니다. 더불어 자정 직후에는 외부 트래픽이 거의 없어 다른 SQL 의 간섭이 들어오지 않으니, 두 트랜잭션의 락 획득 시점이 정확히 같은 윈도우 에 진입합니다.
즉, 자정 Deadlock 은 다음 두 조건이 동시에 만족된 결과였습니다.
- 1일 1회 정시 cron — 두 컨테이너가 동일 시각에 ms 단위로 동기화되어 출발
- 외부 트래픽 0 — 다른 트랜잭션이 락 윈도우를 흩뜨릴 여지가 없음
5. ShedLock + Redis 분산 락 적용 (매시간 분할 포함)
해결은 두 가지를 함께 적용하는 형태로 진행하였습니다.
- ShedLock + Redis 분산 락 — Blue/Green 두 컨테이너가 떠 있어도 한쪽만 실제 작업 수행
- 자정 1회 → 매시간 분할 — 시간 단위 랭킹 요구사항에도 맞춰,
@Scheduled를 매시간 cron 으로 잘게 쪼갬
ShedLock(net.javacrumbs.shedlock) 은 다중 인스턴스 환경에서 @Scheduled 가 한 번만 실행되도록 보장 해주는 라이브러리입니다. 이미 운영에 사용 중이던 Redis 를 락 저장소로 그대로 활용할 수 있어 추가 인프라 부담이 없었습니다.
의존성
implementation 'net.javacrumbs.shedlock:shedlock-spring:5.15.1'
implementation 'net.javacrumbs.shedlock:shedlock-provider-redis-spring:5.15.1'LockProvider 설정
@Configuration
public class SchedulerLockConfig {
@Bean
public LockProvider lockProvider(StringRedisTemplate stringRedisTemplate) {
return new RedisLockProvider(
Objects.requireNonNull(stringRedisTemplate.getConnectionFactory()),
"shedlock:agzak" // Redis key prefix
);
}
}매시간 분할 + @SchedulerLock 적용
@Component
@EnableScheduling
@RequiredArgsConstructor
public class RankingScheduler {
private final RankingService rankingService;
/** 매시간 59분 55초: Redis → MySQL 스냅샷 재생성 */
@Scheduled(cron = "55 59 * * * *", zone = "Asia/Seoul")
@SchedulerLock(name = "rankingSnapshot", lockAtMostFor = "PT4M", lockAtLeastFor = "PT20S")
public void todayRebuild() {
rankingService.rebuildTodaySnapshot();
}
/** 매시간 55분: MySQL → Redis 리씨드 (정합성 보정) */
@Scheduled(cron = "0 55 * * * *", zone = "Asia/Seoul")
@SchedulerLock(name = "rankingReseed", lockAtMostFor = "PT4M", lockAtLeastFor = "PT10S")
public void hourlyReseedRedis() {
rankingService.reseedRedisFromMysqlToday();
int pruned = rankingService.pruneTodayOrphans();
if (pruned > 0) log.info("Pruned {} orphan(s) after reseed", pruned);
}
}각 옵션의 의미는 다음과 같습니다.
| 옵션 | 값 | 의미 |
|---|---|---|
name | rankingSnapshot / rankingReseed | Redis 키. 같은 이름이면 글로벌 단일 실행 보장 |
lockAtMostFor | PT4M (4분) | 락을 최대로 보유할 시간. JVM 이 죽어도 이 시간 후엔 자동 해제 |
lockAtLeastFor | PT20S / PT10S | 너무 빠른 재실행을 막기 위한 최소 보유 시간 |
동작 흐름
55분 정각
├─ Blue: RedisLockProvider.lock("rankingReseed") → SET NX 성공 → 실행
└─ Green: RedisLockProvider.lock("rankingReseed") → SET NX 실패 → 스킵내부적으로는 Redis SET key value NX PX <ms> 명령을 사용하기 때문에, 두 컨테이너가 정확히 동시에 시도해도 한쪽만 락을 획득 합니다. 락을 못 받은 쪽은 조용히 메서드를 빠져나갑니다.
이 구성으로 "Blue/Green 동시 실행" 이라는 근본 원인이 사라지고, 자정 1회 → 매시간 분할로 바뀌면서 만에 하나 한 사이클이 깨져도 다음 시간 cron 에서 자동 회복 되는 안전망이 생깁니다.
Grafana 의 Loki 로그 패널에서 두 컨테이너의 동작을 함께 보면, 한쪽은 ACQUIRED — snapshot ok, 다른 쪽은 skipped — locked by ... 가 매 사이클마다 교차로 찍히는 것을 확인할 수 있습니다.
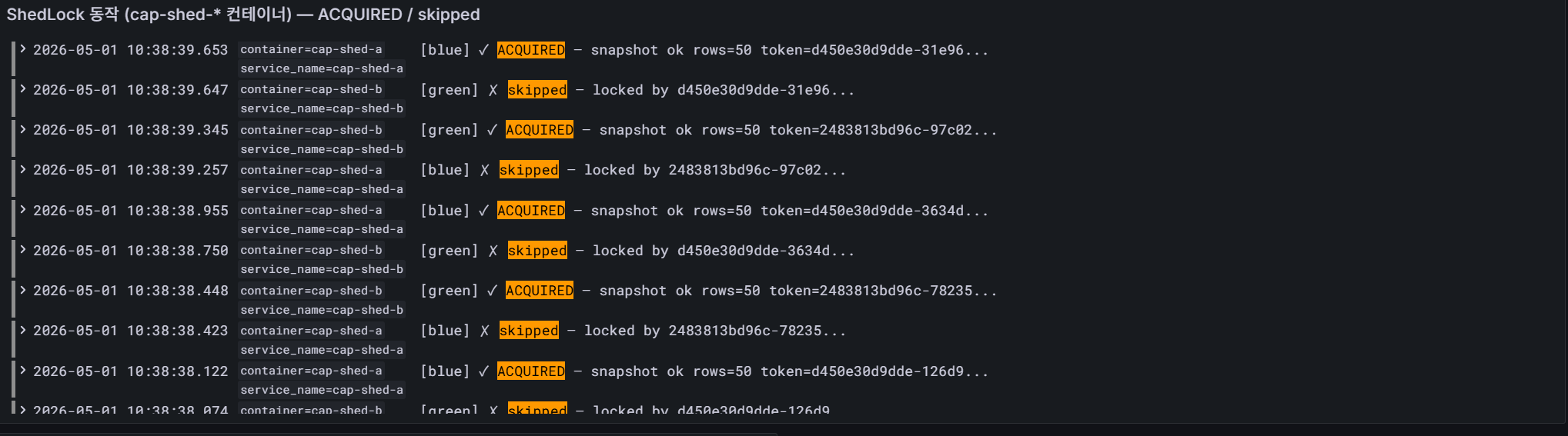
같은 시각에 양쪽이 동시에 트리거되어도 실제 DB 작업은 단 한 번만 수행되며, 락 토큰(d450e30d9dde-..., 2483813bd96c-...) 으로 어느 인스턴스가 락을 잡았는지 추적이 가능합니다.
참고 — 위 Grafana 캡처는 로컬 재현 환경에서 캡처한 자료입니다.
6. 측정 결과
ShedLock + 매시간 분할 적용 전후를 운영 로그 기준으로 비교하였습니다.
Before vs After
| 항목 | Before | After (ShedLock + 매시간 분할) |
|---|---|---|
| 자정 시간대 Deadlock 알림 | 1일 1회 | 0건 |
| 랭킹 스냅샷 누락 | 발견됨 | 0건 |
| 스케줄러 중복 실행 흔적 (로그) | 두 컨테이너 모두 시작 로그 | 한쪽만 시작 + 다른 쪽 즉시 스킵 |
| 운영 부담 | 인스턴스별 수동 관리 필요 | 무관, 자동 |
7. 회고 및 정리
@Scheduled 는 인스턴스마다 독립 실행이 기본값입니다.
Blue/Green 구조에서 이것이 데드락으로 이어진다는 사실은 직접 겪기 전까지는 실감하기 어려웠습니다.
"트래픽 0 + 정시 cron" 조합은 생각보다 위험합니다.
자정처럼 조용한 시간대는 오히려 두 인스턴스의 락 획득 윈도우가 완벽히 겹쳐 충돌 확률이 높아집니다. 시간 단위 분할이 이 윈도우를 흩뜨리는 데 유효했습니다.
알람 없이는 새벽 장애를 모르고 지나쳤을 것입니다.
모든 추적의 출발점은 Mattermost 로 들어온 FIRING 한 줄이었습니다. 모니터링·알람 체계 자체가 인프라의 일부라는 점을 다시 확인했습니다.
마무리
본 포스팅에서는 자정에만 발생하던 랭킹 스케줄러 Deadlock 의 원인을 추적하고, ShedLock + Redis 분산 락 + 매시간 분할로 해결한 과정을 정리하였습니다.
핵심 요약
@Scheduled는 인스턴스마다 독립 실행이라는 기본 동작을 인지할 것.- 무중단 배포 환경에서는 분산 락으로 단일 실행을 명시적으로 보장 하는 것이 표준 해법.
- "정시 cron + 트래픽 0 시간대" 라는 조합은 동시 출발 확률이 높아 데드락에 취약 — 시간 분할이 함께 가야 안전.
- 알람·리포트 체계가 갖춰져 있을 때, 자정 같은 비활성 시간대 장애도 표면 위로 끌어올릴 수 있음.
