'AI 예산 관리·소비 코칭 모바일 서비스' '똑똑꺼비' 프로젝트의 시그니처 기능은 사용자가 매장 앞에서 핸드폰을 한 번 흔들면, GPS 로 주변 가맹점 리스트를 띄우고, 사용자가 매장을 확인·선택하면 그 매장에서 가장 혜택 좋은 결제 카드와 사용 가능한 기프티콘을 한 화면에 보여주는 Interactive 소비 제안 입니다. 이 기능이 의미를 가지려면 사용자가 미리 등록해둔 기프티콘이 "그 매장의 기프티콘" 으로 정확히 분류되어 있어야 했고, 그 데이터 정형화의 출발점이 OCR 자동 등록이었습니다. 처음 검토했던 Tesseract 의 한국어 정확도 한계에서 출발해, GCP Vision API + 도메인 텍스트 파서(
GifticonTextParser) 의 2단 구조로 전환한 과정을 정리한 내용입니다.
1. 들어가며
똑똑꺼비의 핵심 기능은 다음과 같습니다.
| 기능 | 한 줄 | |
|---|---|---|
| 1 | AI 예산 관리 | 가입 시 월소득·카테고리별 예산을 AI가 자동 추천 |
| 2 | Interactive 소비 제안 | GPS 기반 주변 가맹점 인식 + 흔들기 → 최적 결제 카드 + 사용 가능 기프티콘 + QR |
| 3 | AI 소비 코칭 | 실시간 소비제안 알림, 월간 리포트(이상소비, 지출현황, 소비가맹점 순위, 일별 결제 현황) |
| 4 | 게이미피케이션 | 친구·아케이드 게임 기반 N빵, 몰빵 기능 |
② Interactive 소비 제안 기능에서, 사용자가 GS25 앞에서 핸드폰을 흔들었을 때 시스템은 다음 흐름을 풀어야 합니다.
흔들기
└─ GPS 좌표 + 반경 N m 이내 주변 가맹점 리스트
└─ "지금 [가맹점명] 이 맞나요?" 확인 창
└─ 사용자 확정(또는 다른 매장으로 변경)
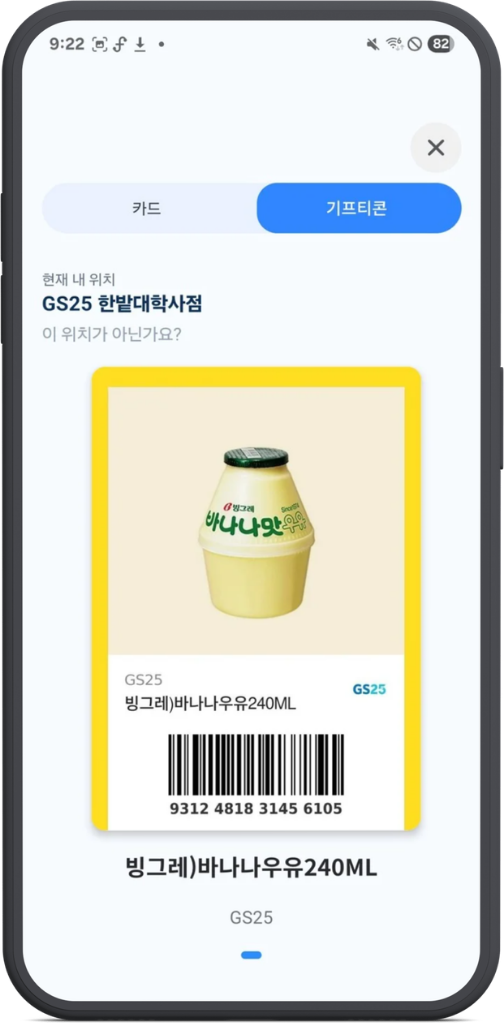
└─ 그 매장 결제 카드 추천 + 사용 가능 기프티콘 목록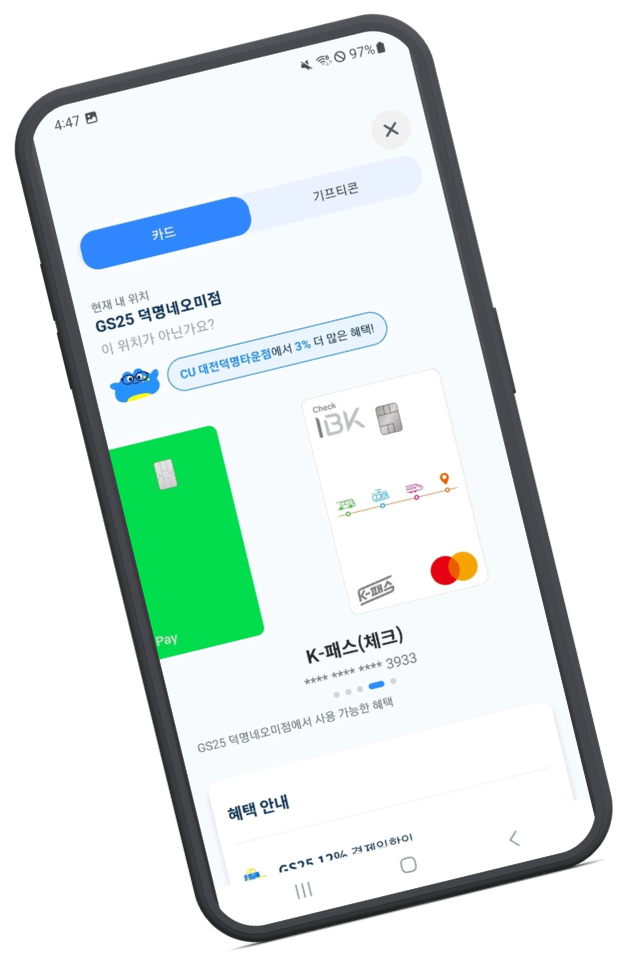
실제 결과 화면 — GS25 매장이 선택된 후 그 매장에서 가장 혜택이 좋은 결제 카드(케이패스 3933)가 한 화면에 노출됩니다.
마지막 단계 — "그 매장 결제 카드 + 사용 가능 기프티콘 목록" 이 의미를 가지려면, 사용자가 사전에 등록해둔 기프티콘 이 정확한 가맹점(franchiseId) 으로 분류되어 있어야 합니다. "스타벅스" / "Starbucks" / "스타벅스 코리아" 가 등록 시 자유롭게 입력되어 서로 다른 가맹점으로 들어가 있다면, 사용자가 흔들기 결과로 "스타벅스" 매장을 선택해도 본인의 "Starbucks" 표기 기프티콘이 매칭되지 않는 상황이 발생합니다.
따라서 기프티콘 등록 단계 에서 다음 두 가지를 동시에 풀어야 했습니다.
- 이미지 → 텍스트 (OCR 정확도)
- 텍스트 → 도메인 모델 (브랜드 캐노니컬 매핑 · 만료일 LocalDate 파싱 · 상품명 추출)
본문은 다음 흐름으로 정리합니다.
- 등록 단계가 흔들기 결과 매칭에 어떻게 이어지는가
- Tesseract(Tess4J) 한국어 OCR
- 정규식 + 캐노니컬 사전으로 후처리 보강
- GCP Vision API + 도메인 텍스트 파서 분리
- 측정 결과
2. 등록 데이터 품질이 흔들기 결과 매칭을 결정한다
기프티콘 등록은 흔들기와는 완전히 분리된 사전 단계 입니다. 사용자는 카카오톡 선물함 등에서 받은 기프티콘 이미지를 앱에 등록해 두고, 등록된 기프티콘은 서비스 DB 에 영속됩니다. 이후 매장 앞에서 흔들기를 했을 때, 시스템은 사용자가 선택한 가맹점에 매칭되는 기프티콘을 DB 에서 검색해 보여줍니다.
즉 흔들기 자체가 등록을 대체하는 게 아니라, 등록 단계에서 부여된 franchiseId 의 정확도가 흔들기 결과 화면의 정확도를 결정 하는 구조입니다.
기존 등록 폼은 다음 4 개 필드로 구성되어 있었습니다.
- 브랜드(franchise) — 드롭다운 검색 (스타벅스 / 배스킨라빈스 / 배달의민족 …)
- 상품명(label) — 자유 입력 ("아메리카노 Tall" 같은 형태)
- 만료일(expiresAt) — 날짜 피커
- 이미지(imageUrl) — 파일 첨부
이 자유 입력 방식이 등록 단계와 이후 흔들기 매칭 단계에 누적시키는 문제는 다음과 같았습니다.
| 항목 | 등록 단계의 문제 | 흔들기 결과 매칭 단계에서의 영향 |
|---|---|---|
| 브랜드 표기 흔들림 | "스타벅스" / "Starbucks" / "스타벅스 코리아" 가 서로 다른 franchiseId 로 저장 | 사용자가 흔들기로 "스타벅스" 매장을 선택했는데, 본인 "Starbucks" 표기 기프티콘이 다른 ID 로 등록되어 매칭 실패 |
| 입력 부담 | 한 장당 4 칸 직접 입력 — 12 장이면 48 칸 | 사용자가 등록 자체를 포기 → 흔들기 결과 화면에서 보여줄 기프티콘이 없음 |
| 만료일 형식 흔들림 | "2025.11.30" / "2025-11-30" / "2025년 11월 30일" 자유 입력 | LocalDate 파싱 실패 → 만료된 기프티콘이 "사용 가능" 으로 노출되거나, 정상 기프티콘이 누락 |
즉 "흔들면 매장에서 쓸 수 있는 내 기프티콘이 정확히 뜬다" 라는 시그니처 결과 화면의 품질이 사용자가 사전에 입력한 등록 데이터 품질에 그대로 종속 되어 있었습니다. 자동 추출과 정규화가 같이 풀려야 했습니다.
사용자가 등록해 둔 기프티콘이 스타벅스 / 이디야 / 탐앤탐스 등 매장 단위로 정확히 그룹화 되어 있어야, 흔들기 후 매장 선택 단계에서 곧바로 매칭되는 기프티콘을 꺼내올 수 있습니다.
3. Tesseract (Tess4J)
처음에는 외부 비용 없이 자체 OCR 을 돌리는 쪽을 우선 검토하였습니다. JVM 환경에서 가장 흔한 옵션은 Tess4J (Tesseract 의 Java 바인딩) 입니다.
implementation 'net.sourceforge.tess4j:tess4j:5.12.0'구현 시도
Tesseract tess = new Tesseract();
tess.setDatapath("/usr/share/tesseract-ocr/4.00/tessdata");
tess.setLanguage("kor+eng");
String text = tess.doOCR(imageFile);샘플 기프티콘 이미지(스타벅스 / 배스킨라빈스 / GS25 / CU 등) 를 모아 OCR 을 돌려보았습니다. 결과 텍스트 품질에 다음과 같은 한계가 드러났습니다.
| 항목 | 문제 |
|---|---|
| 한국어 정확도 | 디자인 폰트·흘림체가 들어간 카카오톡 선물함 카드에서 ㅁ↔ㅇ, ㅈ↔ㅊ 자모 오인식 빈발 |
| 바코드 영역 노이즈 | 1D/2D 바코드가 텍스트로 잘못 인식되어 ㅁ ㅁ I I I 같은 쓰레기 토큰 생성 |
| 줄바꿈/레이아웃 손실 | "교환처: 스타벅스" 한 줄이 교환처:\n\n스 타 벅\n스 로 끊어짐 |
| 의존성 무게 | Tesseract 네이티브 바이너리 + tessdata 한국어 모델(~14MB) 을 컨테이너 이미지에 포함 |
| 운영 부담 | Tesseract 버전 / 한국어 모델 버전 별도 관리 |
참고
Tesseract 의 한국어 정확도는 인쇄체 본문 에는 충분하지만, 광고/패키징 디자인 텍스트 에서는 떨어지는 것으로 알려져 있습니다. 기프티콘 카드는 후자에 해당합니다.
이 단계에서 OCR 결과 텍스트 자체의 품질이 너무 흔들렸기 때문에, 후처리 정규식·사전이 무엇을 해도 입력 노이즈가 그대로 따라오는 상황이었습니다.
4. 정규식 + 캐노니컬 사전으로 후처리 보강
OCR 결과를 그대로 쓰지 못한다면, 결과 텍스트 위에 강한 정규식 + 캐노니컬 사전 을 얹어 보정해 보기로 했습니다.
// 흘림체로 깨진 "스 타 벅 스" → "스타벅스" 복원 시도
text = text.replaceAll("(\\S)\\s+(?=\\S)", "$1");
// 만료일 패턴 — 다중 구분자 흡수
Matcher m = Pattern.compile(
"(20\\d{2})[./년 -]\\s*(\\d{1,2})[./월 -]\\s*(\\d{1,2})"
).matcher(text);
// 브랜드 캐노니컬 사전 (예시)
Map<String, String> CANON = Map.of(
"starbucks", "스타벅스",
"스타벅스코리아", "스타벅스",
"STARBUCKS", "스타벅스"
);확인된 한계
- 정규식이 잡는 패턴 ⊂ OCR 이 흐트러뜨린 패턴 — 흘려쓰기 + 자모 오인식 이 결합되면 어떤 정규식도 회복 불가
- 캐노니컬 사전을 두껍게 만들수록 새 브랜드 추가 비용 ↑
- 사용자가 수정한 결과를 학습 데이터로 모으기엔 운영 부담 큼
→ "OCR 텍스트 품질을 끌어올리지 않는 한 정규식 후처리는 한계가 명확하다" 가 결론이었습니다. OCR 엔진 자체를 교체하는 쪽이 본질적인 해법 이라는 판단으로 다음 단계로 넘어갔습니다.
5. GCP Vision API + 도메인 텍스트 파서 분리
5-1. 선택 이유
GCP Vision API 의 TEXT_DETECTION 은 다음 측면에서 Tesseract 보다 유리했습니다.
- 한국어 광고/패키징 디자인 폰트 에 학습된 OCR 모델
- 줄/블록 단위 레이아웃 정보까지 함께 반환 → 정형화 단계가 훨씬 가벼움
- 인프라/모델 관리 부담 0 — credentials JSON 한 장만 컨테이너에 주입
무료체험 계정을 사용하여 부담을 줄였습니다.
5-2. 인터페이스로 분리한 OCR 클라이언트
OCR 엔진 자체는 향후 교체 여지가 있다고 판단해 OcrClient 인터페이스로 추상화하였습니다.
public interface OcrClient {
String extractText(byte[] imageBytes) throws Exception;
}@Component
@ConditionalOnProperty(name = "app.ocr.provider", havingValue = "vision", matchIfMissing = true)
public class VisionOcrClient implements OcrClient {
@Value("${app.ocr.credentials-path:}")
private String credentialsPath;
@Override
public String extractText(byte[] imageBytes) throws Exception {
var settings = ImageAnnotatorSettings.newBuilder();
if (!credentialsPath.isBlank()) {
try (var in = Files.newInputStream(Path.of(credentialsPath))) {
var creds = GoogleCredentials.fromStream(in)
.createScoped(List.of("https://www.googleapis.com/auth/cloud-platform"));
settings.setCredentialsProvider(FixedCredentialsProvider.create(creds));
}
}
try (var client = ImageAnnotatorClient.create(settings.build())) {
var img = Image.newBuilder().setContent(ByteString.copyFrom(imageBytes)).build();
var feat = Feature.newBuilder().setType(Feature.Type.TEXT_DETECTION).build();
var req = AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
var res = client.batchAnnotateImages(List.of(req)).getResponses(0);
if (res.hasError())
throw new IllegalStateException("OCR error: " + res.getError().getMessage());
return res.getTextAnnotationsList().isEmpty()
? "" : res.getTextAnnotationsList().get(0).getDescription();
}
}
}핵심 포인트
@ConditionalOnProperty—app.ocr.provider=vision기본값. 향후 다른 엔진으로 교체할 때 빈 자체로 차단- credentials 두 가지 경로 — 명시적 파일 경로 / ADC(Application Default Credentials) 자동 fallback
- 응답에서
getTextAnnotationsList().get(0)만 꺼내면 줄/블록 정보까지 합쳐진 전체 텍스트 한 덩어리
5-3. OCR 텍스트 → 도메인 모델 정형화 (GifticonTextParser)
OCR 결과 품질이 안정되었으니, 이제 정형화 책임만 따로 떼서 도메인 텍스트 파서로 분리하였습니다. OCR 엔진과 도메인 정형화가 같은 클래스에 있으면 엔진 교체 시 변경 영역이 광범위해지기 때문입니다.
GifticonTextParser 는 다음 세 함수만 노출합니다.
findBrand(String text) → StringfindExpiry(String text) → LocalDatefindLabel(String text, String brand) → String
각각의 전략은 다음과 같습니다.
브랜드 — 2단 fallback + 캐노니컬 매핑
1순위 : "교환처:" 라벨 뒤 텍스트 → 정규식 캡처
2순위 : 상위 6 줄 토큰 빈도 분석 → ≥ 2 회 등장한 토큰
캐노니컬 사전 (77 개)
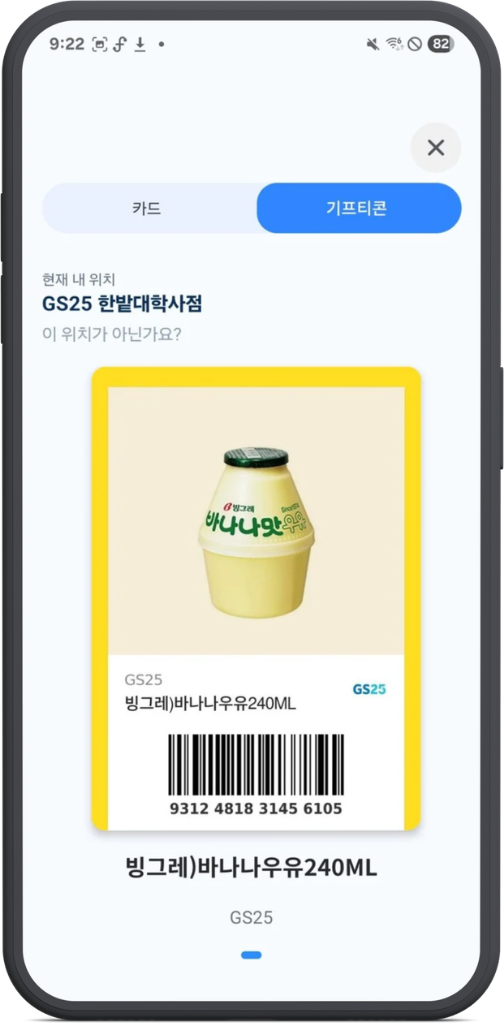
"starbucks" / "스타벅스 코리아" / "STARBUCKS" → "스타벅스"이 캐노니컬 매핑이 곧 흔들기 결과 매칭의 조인 키 입니다. 사용자가 흔들기 후 가맹점을 선택하면 그 가맹점의 franchiseId 가 결정되고, 사용자 기프티콘은 정규화된 franchiseId 로 즉시 검색됩니다.
매칭이 끝나면 사용자는 추가 입력 없이 바로 사용 가능한 기프티콘 바코드를 노출받게 됩니다 — 예: GS25 매장 선택 후 등록해둔 바나나우유 기프티콘이 즉시 노출.
만료일 — 다중 형식 정규식
Pattern.compile("(20\\d{2})[./년- ]\\s*(\\d{1,2})[./월- ]\\s*(\\d{1,2})")
// "2025/11/30" / "2025.11.30" / "2025년 11월 30일" / "2025-11-30" 모두 흡수LocalDate 로 변환되어야 흔들기 결과 화면에서 만료된 기프티콘을 자동으로 걸러낼 수 있습니다.
상품명 — 스코어링
| 신호 | 점수 |
|---|---|
| 한글 포함 | +2 |
힌트 키워드 (교환권, 이용권, 용량 단위) | +3 |
용량 표기 (Tall, 300ml) | +2 |
| 60자 이상 | -∞ (탈락) |
| 브랜드명 자체 / 바코드 / 로고 토큰 | -∞ (블랙리스트) |
상위 점수 후보 한 개를 label 로 채택합니다.
5-4. 호출 흐름
@PostMapping(consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResponseEntity<GifticonCreateResponse> upload(@RequestPart MultipartFile file) {
Long userId = SecurityUtils.currentUserIdOrNull();
return ResponseEntity.ok(gifticonService.createFromUpload(userId, file));
}@Transactional
public GifticonCreateResponse createFromUpload(Long userId, MultipartFile file) {
String text = ocrClient.extractText(file.getBytes()); // ① 외부 OCR
if (!isGifticon(text)) throw new InvalidGifticonImage(); // ② 가드 (키워드 + 바코드 패턴)
String brand = parser.findBrand(text); // ③ 정형화
LocalDate exp = parser.findExpiry(text);
String label = parser.findLabel(text, brand);
Franchise fr = franchiseService.findOrCreate(brand); // ④ 캐노니컬 매핑
Gifticon g = gifticonRepository.save(Gifticon.of(userId, fr, label, exp, imageUrl));
return GifticonCreateResponse.from(g, text); // ocrPreview 도 함께 반환
}핵심
- OCR 호출 과 도메인 정형화 가 깨끗이 분리됨 → 엔진 교체 비용 ↓
- 응답에
ocrPreview를 함께 내려, 사용자가 부정확한 필드를 즉시 손볼 수 있도록 UX 보조 franchiseService.findOrCreate(brand)가 곧 흔들기 결과 매칭이 의존하는 정규화 지점
6. 측정 결과
Before vs After
| 항목 | Before (수기 입력) | Tesseract 시도 | After (Vision + Parser) |
|---|---|---|---|
| 등록 입력 칸 | 4 개 (브랜드·상품명·만료일·이미지) | 4 개 (자동 후 사용자 수정) | 1 개 (이미지만) |
| 브랜드 표기 | "스타벅스" / "Starbucks" / "스타벅스 코리아" 혼재 | 흘려쓰기로 회복 불가 다수 | 캐노니컬 매핑 1 개 |
| 만료일 파싱 실패 | 자유 입력 → 형식 흔들리면 NULL | OCR 노이즈로 정규식 매치 실패 빈발 | 다중 형식 정규식 — 자율 테스트셋 거의 100% 매치 |
| 정형 정확도 | — | 약 60% (브랜드+만료일+상품명 동시 추출) | 약 95%+ |
| 흔들기 결과 매칭 | 등록 표기에 따라 매칭 실패 빈발 | OCR 노이즈로 동일 | franchiseId 단위 정확 매칭 |
| 운영 부담 | — | Tesseract 버전·모델 별도 관리 | 0 — 외부 SaaS |
참고
위 정확도 수치는 자율 테스트셋(팀·지인 보유 기프티콘 약 50 장) 기준입니다.
마무리
본 포스팅에서는 똑똑꺼비 프로젝트의 Interactive 소비 제안(흔들기 → 가맹점 선택 → 카드/기프티콘) 이 의미를 가지기 위한 데이터 인프라로서, 기프티콘 자동 등록 OCR 을 Tesseract 후처리에서 GCP Vision API + 도메인 정규화 분리 구조로 전환한 과정을 정리하였습니다.
| 시도 | 결과 | 한계 / 의의 |
|---|---|---|
| 수기 입력 | 동작 | 등록 부담 + 표기 흔들림으로 흔들기 결과 매칭 실패 |
| Tesseract + 정규식 | 부분 동작 | 한국어 광고·패키징 폰트 정확도 한계 |
| GCP Vision API + GifticonTextParser | 해결 | 엔진 교체 비용 0 (인터페이스 분리), 정형화 정확도 ~95%, 흔들기 매칭 정확 |
핵심 요약
- OCR 엔진 품질 자체 가 후처리 정규식의 상한선을 결정.
- 엔진(
OcrClient) 과 도메인 정규화(GifticonTextParser) 의 책임을 처음부터 분리 해야 교체 비용이 작아짐. - 자동 추출만으로는 부족 — 캐노니컬 매핑(브랜드 사전) 이 시그니처 기능(흔들기 후 가맹점 선택 시의 기프티콘 매칭) 의 조인 키 품질을 결정.
