openai의 whisper API
코드 작성
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("OPEN_API_KEY")
client = OpenAI(api_key=api_key)
audio_file = <파일 경로>
with open(audio_file, 'rb') as audio :
transcription = client.audio.transcriptions.create(
model='whisper-1',
file=audio
)
print(transcription)HugginFace openai/whisper-large-v3-turbo
모델 사용하기
-
https://huggingface.co/ 에 접속하여
openai/whisper-large-v3-turbo검색. -
예제를 통해서 실행하면 되지만 기본적으로 ffmpeg이 설치되어 있어야함.
-
https://www.gyan.dev/ffmpeg/builds/ 에 접속하여
ffmpeg-release-full-shared.7z다운로드 -
압축해제후
import torch전 라인에os.add_dll_directory(str(Path(<압축 해제한 ffmpeg 폴더의 bin 폴더 경로>)))추가.파이썬 3.8 버전부터는 Windows 보안 강화로 인해 os.environ['PATH']에 경로를 추가하는 것만으로는 DLL 파일을 불러올 수 없습니다.
경로내 dll파일이 존재해야합니다. -
huggingface의 예제를 그대로 가져와 코드를 추가후. 실행합니다.
혹시, 오류가 발생하지 않으나 결과값이 비어있거나 이상하게 나온다면
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32부분에서 torch.float32로 변경하여 사용해보시기 바랍니다. -
정상 작동 코드
import os
from pathlib import Path
os.environ["PATH"] += os.pathsep + r"<ffmpeg bin 폴더 경로>"
os.add_dll_directory(str(Path(r"<ffmpeg bin 폴더 경로>")))
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
return_timestamps=True
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
csv로 저장
- 이렇게 뽑아낸 결과를 통해서 언제 어떤 말을 했는지 알 수 있다.
- csv로 저장해보자.
start_end_text = []
for chunk in result["chunks"] :
start = chunk["timestamp"][0]
end = chunk["timestamp"][1]
text = chunk["text"]
start_end_text.append([start, end, text])
import pandas as pd
df = pd.DataFrame(start_end_text, columns=["start", 'end', 'text'])
df.to_csv("lsy_audio_2023_58s.csv", index=False, sep="|")
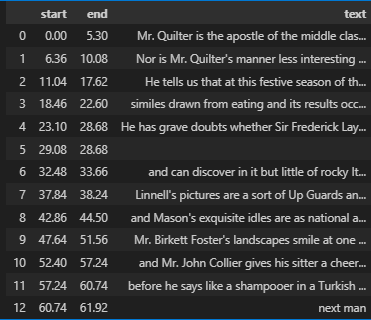
display(df)- 결과
오류 해결
- torchcodec 호환성 문제.
- 다른 기능이 정상적으로 동작하지 않아. torch 버전을 2.8.0 으로 낮췄다. 당연히 다른 것들도..
- 여기서 계속 ffmpeg 오류가 발생한 것이다.
- 내가 사용중인 ffmpeg 버전이 8.0.1 이었고, 다른 곳에서 보니 7.1.1 버전으로 사용했다고 해서 ffmpeg을 7.1.1 버전으로 설치후 동작했더니 정상 작동하였다.
이슈 참고 : https://github.com/meta-pytorch/torchcodec/issues/1108
https://github.com/meta-pytorch/torchcodec/issues/912#issuecomment-3450048176

조금씩 앞으로