추천 시스템이란?
사용자(user)에게 관련된 아이템(item)을 추천해 주는 것
범주형 데이터를 다룬다.
(숫자 벡터로 변환한 뒤) 유사도를 계산한다.
이 숫자 벡터의 유사도를 계산하여 유사도가 가까운 (혹은 높은) 제품을 추천해 줍니다.
코사인 유사도
두 벡터 간의 코사인 값을 이용해 두 벡터의 유사도를 계산합니다.
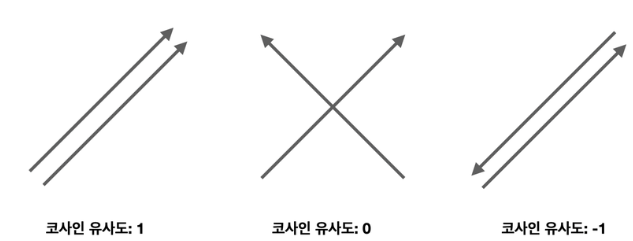
사이킷런으로 코사인유사도 구하기
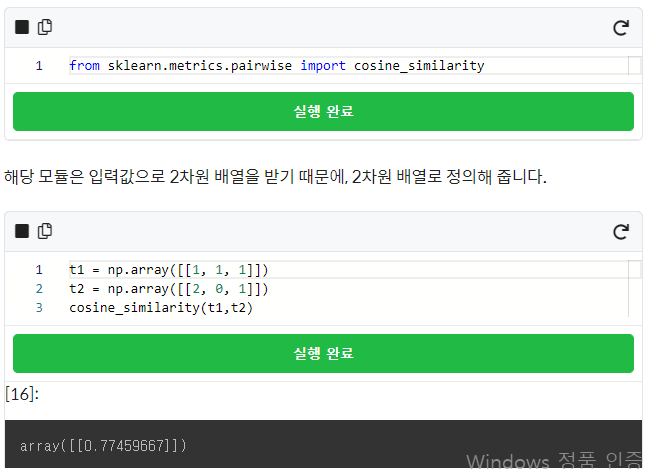
추천시스템의 종류
협업 필터링 방식
콘텐츠 기반 필터링 방식
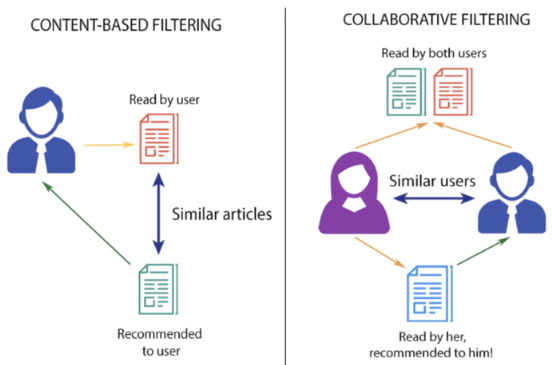
콘텐츠 기반 필터링(Content Based Filtering)
비슷한 콘텐츠의 아이템을 추천하는 방식.
(ex 아이언맨1을 봤으면 아이언맨 2, 아이언맨3을 추천해주고 마블 영화를 추천)
장르, 배우, 감독 등의 정보를 가지고 영화를 고른다.
이런 정보들이 영화의 특성(Feature) 이 되고, 이 특성이 바로 '콘텐츠'
협업 필터링(Collaborative Filtering)
과거의 사용자 행동 양식(User Behavior) 데이터를 기반으로 추천하는 방식.
협업 필터링의 기본 원리
user_id:사용자 정보
item_id:영화 정보
평점 (rating):사용자가 영화를 보고 매김. timestamp:평점 매긴 시각
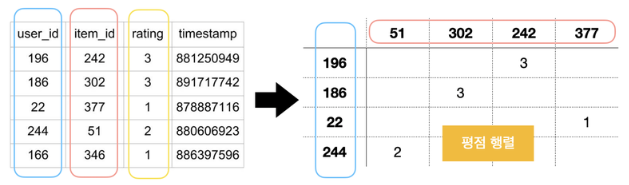
왼쪽 행렬 데이터를 사용자와 아이템 간 interaction matrix로 변환 -> '평점행렬'
굉장히 희소(sparse)한 행렬이 만들어진다.
협업 필터링의 종류
사용자 기반, 아이템 기반, 잠재요인(latent factor) 방식
사용자 기반 협업 필터링
-당신과 비슷한 고객들이 다음 상품을 구매했습니다.
아이템 기반 협업 필터링
아이템 간의 유사도를 측정하여 해당 아이템을 추천하는 방식.
일반적으로 사용자 기반보다 아이템 기반 방식이 정확도가 더 높다고 함.
-이 상품을 선택한 다른 고객들은 다음 상품을 구매했습니다.
잠재요인(latent factor) 방식
평점행렬을 행렬 인수분해(matrix factorization)를 통해 잠재요인(latent factor)을 분석
행렬 인수분해
행렬 인수분해의 기법
SVD(Singular Vector Decomposition)
ALS(Alternating Least Squares)
NMF(Non-negative Matrix Factorization)
SVD(특잇값 분해)
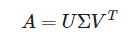
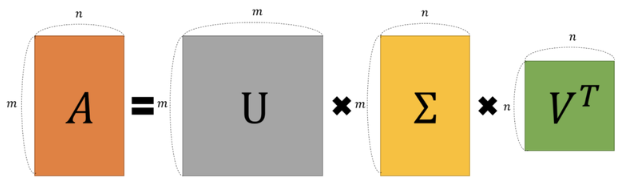
SVD를 사용하는 이유?
"정보 복원"을 위해 사용.
특이값 분해는 분해되는 과정보다 분해된 행렬을 다시 조합하는 과정에서 빛을 발함.
기존의 U,Σ,VTU,Σ,VT로 분해되어 있던 AA행렬을 특이값 p개만을 이용해 A’라는 행렬로 ‘부분 복원’ 할 수 있음.
특이값의 크기에 따라 A의 정보량이 결정.
따라서 값이 큰 몇 개의 특이값들만으로 충분한 유용정보를 유지 가능.
행렬 인수분해와 잠재요인 협업 필터링
SVD(특이값 분해)를 평가행렬에 적용해 잠재요인을 분석하는 도식화 그림
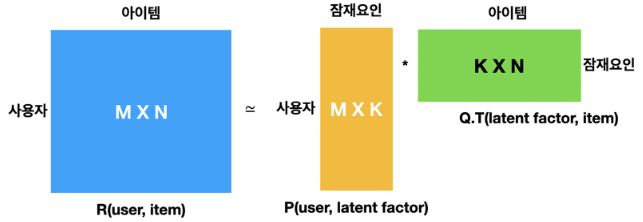
R: 사용자와 아이템 사이의 행렬
P: 사용자와 잠재요인 사이의 행렬
Q: 아이템과 잠재요인 사이의 행렬 —> 전치 행렬 형태
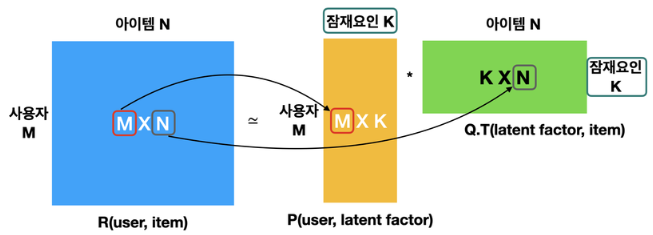
사용자가 아이템에 대한 평점을 매기는 요인: 배우, 감독, 장르, 가격, 분위기 등등. 매우 주관적임.
따라서, 사용자가 평점 매기는 요인을 그냥 "잠재요인"으로 취급 -> 그것을 SVD기법으로 분해하고 다시 합침 -> 영화에 평점을 매긴 이유를 벡터화하여 이를 기반으로 추천
넷플릭스나 왓챠, 유튜브 같은 대 기업에서 사용하여 그 효과를 입증한 방법.
실제 추천 시스템
실제로 YouTube나 Netflix 같은 대형 기업에서는 추천에 더 많은 것들을 고려.
가장 중요한 지표가 바로 클릭률(CTR, Click Through Rate)
