
안녕하세요, 프론트엔드 개발자 가든입니다.
제가 회사 업무 말고 지금까지 계속 사이드 프로젝트로 개발하고 있는 백곰 서비스의 병원 조회 기능에서 웹 크롤러를 구현해 아래와 같은 기능을 구현해보려고 합니다.
- 전국 단위의 병원 정보를 가져온다. > 서비스 범위 확장
- 병원 각각의 실시간 진료 정보를 가져온다. > 1번이 확대 됨에 따라 실시간 진료 상황 기능도 확장
제가 살다살다 개발하면서 크롤러까지 만들 줄은 꿈에도 몰랐는데 말이죠,,,
회사에서 레이첼과 헨리께서 크롤러 얘기하실 때 조금 귀기울여 들을 껄 그랬습니다...
본격적으로 시작해보겠습니다.
1. 웹 크롤러 도입 개요
1) 크롤러란?
먼저 크롤링을 알아야 하는데, 크롤링(crawling) 은 웹 페이지를 그대로 가져와서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어를 크롤러(crawler)라고 부르는 것입니다.
2) 프로젝트 도입 개요
필요한 정보를 개발자가 보고 직접 api로 만들면 되는데 크롤러까지 구현을 해야겠다고 생각한 이유는 데이터 양이 이제 많아졌기 때문입니다.
저희는 질병관리청 예방접종도우미에서 각 백신별로 지원해주는 전국의 병원 목록을 가져와야했습니다.
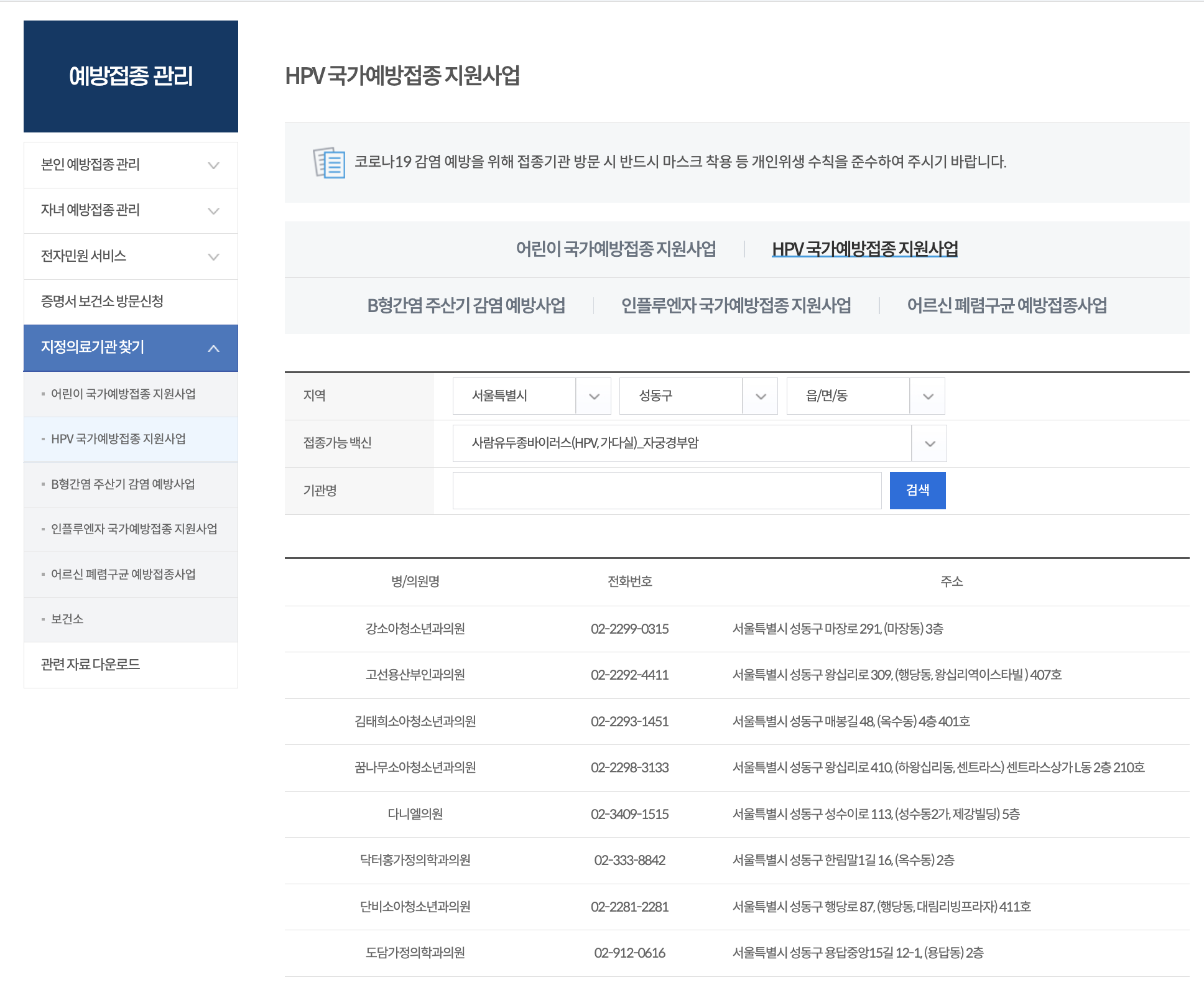
한 구 단위로만 조회해도 150개정도로 병원 수가 많기 때문에 일일히 다 데이터를 넣을 수가 없어서 크롤러를 구현하게 되었습니다 ...
2. 본격적인 크롤러 구현
1) 기술 스택 선정
OK 이제 크롤러를 구현하기 위해 어떤 기술스택으로 구현해야할지 고민을 시작했습니다.
크롤러로 많이 구현하는 기술 스택이 puppteer, Selenium이 대표적으로 있는데 대부분 파이썬을 사용하는 레퍼런스가 많이 있었습니다.. 저는 일평생 써본게 Js밖에 없었기 때문에 Js로 크롤러를 구현해야했는데요!
바로 puppteer + JS 로 크롤러를 1차적으로 구현해보기로 했습니다 !!
2) 크롤러 기본 구현
크롤러의 기본 뼈대만 잡기위해서는 많은 패키지나, 외부 코드를 사용하지 않아도 되었어요 ,
puppteer 사용을 위해 필요한 패키지를 먼저 설치해줍니다.
"axios": "^1.7.2",
"crawler": "^1.5.0",
"puppeteer": "^22.10.0"크롤러 파일을 만들고 다음과 같은 기본 코드를 구현해줍니다!
1. puppteer 모듈 불러오기
const puppeteer = require('puppeteer');
크롤러 최상단에 모듈을 불러와줍니다.
2. 비동기 함수를 정의
크롤링할 웹페이지의 동적 컨텐츠를 가져오기 위한 scrapeDynamicContent 함수를 비동기로 정의합니다. 이때 이 함수는 URL을 인자로 받아 해당 페이지에서 필요한 데이터를 추출해주는 역할입니다.
그 다음에 브라우저 인스턴스 생성해줘야하는데요, Puppeteer의 launch 메서드를 사용하여 브라우저 인스턴스를 생성합니다. 여기서 headless: false 옵션을 주면 브라우저가 실제로 화면에 표시되어 작동하는 것을 볼 수 있습니다. 추가적인 args 옵션으로는 보안 관련 설정을 비활성화해서 최소한 봇으로 감지 되지 않도록 해주는 역할을 해줍니다 (playwright의 구글 봇 악몽이..)
async function scrapeDynamicContent(url) {
const browser = await puppeteer.launch({
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox']
...
});
}
3. 새 페이지로 열어주기!
브라우저에서 새 탭을 열고, CSP(콘텐츠 보안 정책)를 우회하도록 구현해주어야해요! 또한 사용자 에이전트를 설정하여 일반 브라우저에서 접속하는 것처럼 보이게 합니다 > 이것도 질병관리청 홈페이지에 보안으로 감지되는 것을 뚫어내기 위함 때문입니다 사용자가 직접 조회할때랑 비슷하게 되도록 짜줘야합니다
const page = await browser.newPage();
await page.setBypassCSP(true);
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36');
4. 페이지로 이동하고, 동적 요소를 구현하기
특정 셀렉터가 페이지에 나타날 때까지 기다린 후, 해당 셀렉터를 이용하여 동작을 수행합니다. 예를 들어, 특정 지역을 선택하고, 그 지역에 맞는 요청을 서버에 보내도록 해야합니다.
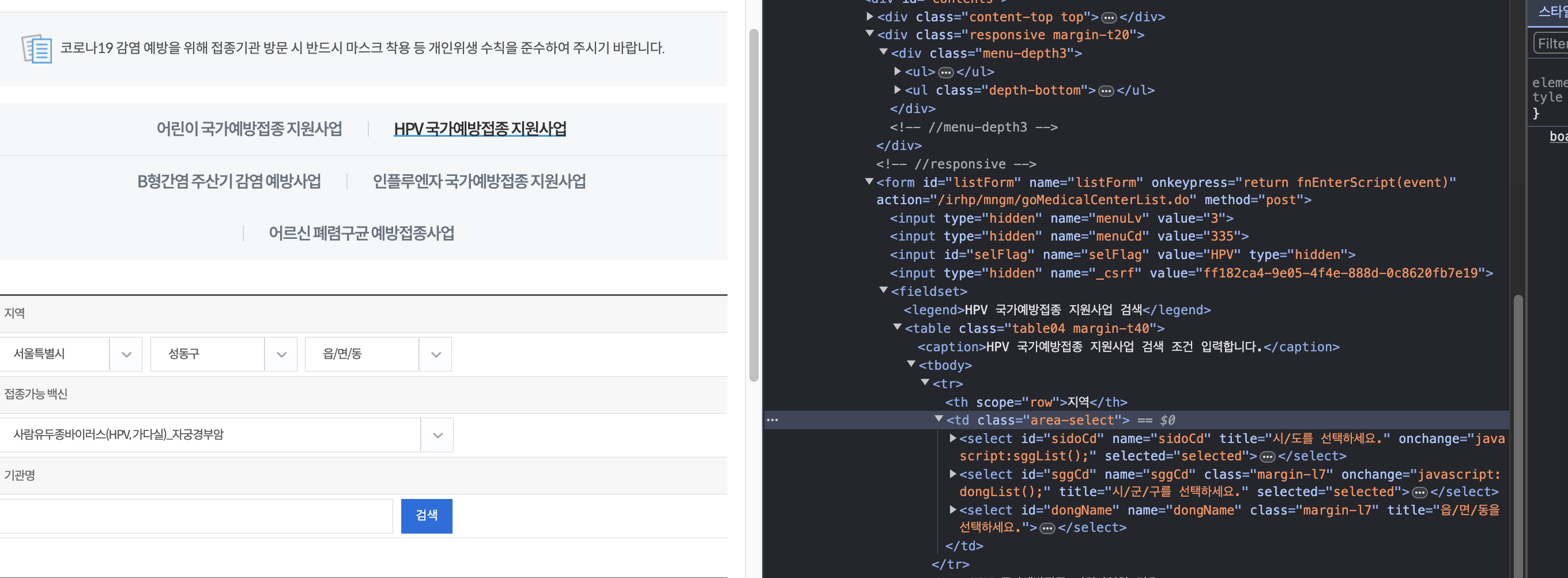
이게 왜 이렇게 구현해야했냐면, 제가 크롤링하는 페이지가 그 안에 데이터들을 조회하면서 url이 바뀌는게 아니기 때문이었습니다. 따라서 개발자 도구로 해당 요소의 html 요소를 파악하고 그거에 맞게 셀렉터를 구현해줘야합니다.
그리고 아래의 예시코드는 특정 시, 특정 구를 선택하는 것인데요, 모든 장소의 value 값을 db에 넣고 이를 셀렉터가 각각을 매칭에 검색할 수 있도록 해야합니다.
await page.waitForSelector('#sidoCd');
await page.select('#sidoCd', '11'); // 서울 특별시 선택
await page.waitForTimeout(1000); // 1초 대기
await page.evaluate(() => sggList()); // 함수 실행
await page.waitForSelector('#sggCd');
await page.select('#sggCd', '11200'); // 구 선택
await page.waitForTimeout(1000);
각 지역마다의 value 값은 개발자 도구를 열어서 확인할 수 있었습니다.
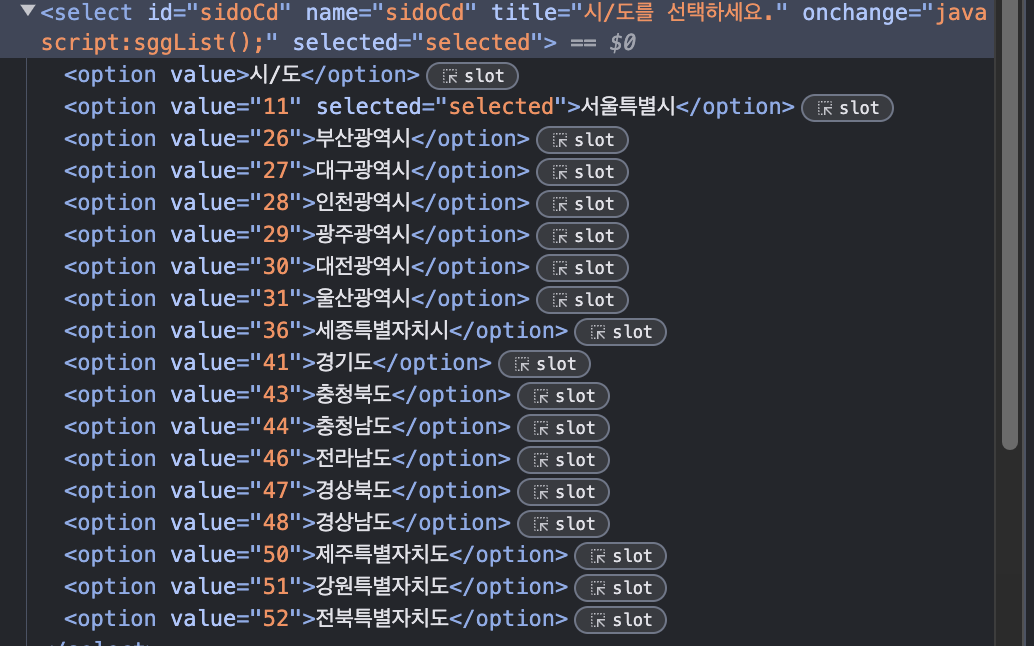
저 option value 값에 들어가는 것을 파악하고 자동화 할 수 있도록 추가로 구현했습니다.
5. 결과 추출
최종적으로 필요한 데이터가 있는 테이블을 기다린 후, 해당 데이터를 추출하면 됩니다!
await page.waitForSelector('input.sch-btn');
await page.click('input.sch-btn');
await page.waitForSelector('table.table05', { timeout: 60000 });
const results = await page.evaluate(() => {
const rows = Array.from(document.querySelectorAll('table.table05 tbody tr'));
return rows.map(row => {
const columns = row.querySelectorAll('td');
return {
병의원명: columns[0].innerText.trim(),
주소: columns[2].innerText.trim()
};
});
});
위와 같이 함수를 구현하고 나서 이를 제어하는 main 파일(예시)에 다음과 같이 url을 넣어 구현해주면 간단하게 짜볼 수 있습니다.
6. 제어 main에서 실행
async function main() {
const url = 'https://nip.kdca.go.kr/irhp/mngm/goMedicalCenterList.do';
const dynamicContent = await scrapeDynamicContent(url);
console.log(dynamicContent);
}
main();
위와 같이 구현하고 나면 콘솔에 리턴한
병의원명: 강소아청소년과의원
주소: 서울특별시 성동구 마장로 291, (마장동) 3층형식으로 데이터가 출력되는 것을 확인할 수 있습니다 ;)
이 다음에는 서버개발자와 함께 db에 데이터를 저장하도록 연결해 구현해야합니다.
3) 크롤러 자동화
저는 위의 크롤러를 자동화하기 위해서 도커와 쿠버네티스를 쓸지 고민했는데요...
저희 서비스의 서버개발자가 aws Lamda를 도입하셔서 저도 aws Lamda로 서버 유지 관리 없이 크롤링 코드를 실행하도록 구현하기로 했습니다. AWS Lamda 말고도 앞서 언급한 도커와 쿠버네티스로도 자동화를 관리할 수 있으니 프로젝트 상황에 맞게 사용하는 것이 좋을 것 같습니다 !!
3. 앞으로의 계획
우선 전국 단위의 병원 데이터를 크롤러로 다 가져오는 결과를 얻었지만
이때 어려움을 겪었던 부분은 바로 "보안" 이었습니다... 크롤러가 안정화되지 않아서 사이트 보안을 뚫기가 진짜 쉽지 않았고 이거 핸들링하는 과정에서 난항을 겪었습니다. 사용자가 접속하는 것으로 보이기 위해 playwright 구글 로그인 테스트코드 짤때 고민했던게 도움이 되었습니다...
헤드리스 공부부터 차근차근해서 더 탄탄한 크롤러로디벨롭 시키고 싶습니다!
또한 그 다음 기능인 해당 병원 정보들의 실시간 진료 정보를 가져오는 것은 저희가 네이버 map API를 사용하고 있는데, 네이버는 크롤러를 무조건 막는것 같았습니다 해도해도 계속 봇에 걸리는 이슈가.. 그래서 카카오 맵으로 접근해야하나 골머리를 앓고 있습니다
다음 포스팅은 aws 람다 자동화 구축, 그리고 실시간 진료정보를 가져오는 거 구현하는 과정을 담아볼게요!
