
🏞 배경
ML은 기본적으로 많은 실험을 거쳐서 최적의 모델을 찾아 이를 배포하고 제품화합니다. 수많은 Feature, 알고리즘, Hyper-parameter의 구성을 다양하게 시도하여 모델을 튜닝하게 됩니다. 하지만 Feature가 많아지고 알고리즘이 복잡해질 수록 최적의 모델을 찾기란 쉽지 않습니다. 너무 많은 경우의 수가 발생하기 때문입니다. 일반적으로 많이 사용하는 Grid Search는 스키마가 간단하지만 후보군 내의 모든 구성을 다 테스트하기 때문에 많은 시간이 걸립니다. 그래서 최근에는 Bayesian Optimization에 기반을 둔 튜닝 자동화를 많이 시도합니다. 튜닝할 Hyper-parameter의 후보군만 정해주면 자동으로 최적의 구성을 찾아주기 때문입니다.
이렇게 많은 실험을 하게 되면 실험 결과를 관리하기 어렵습니다. 특히 Jupyter Notebook 과 같은 인터랙티브 환경에서 실험을 하게 되면 결과를 트래킹하기 어렵고, 만약 하나하나 로깅을 하더라도 결과를 정리하여 보기는 여전히 어렵습니다. 그 뿐만 아니라 결과를 트래킹하기 어렵기 때문에 지금까지 수행한 실험을 재현하기도 어렵습니다. 데이터 사이언티스트들은 이런 많은 문제를 해결하기 위해 공개된 오픈소스 툴이 많이 사용하곤 합니다. 이 아티클에서는 재현 가능한 실험과 실험 결과 트래킹을 위해 MLflow와 Optuna를 사용하는 방법에 대해 소개하고자 합니다.
⚠️ 주의
본 아티클은 Bayesian Optimization이 무엇인지 알고, Optuna를 어느 정도 사용해 본 경험이 있다는 가정을 하고 작성하였습니다. 만약 Optuna를 사용해보지 않았다면 잘 설명이 된 가이드들이 많으므로 여기에서는 다루지 않겠습니다.
🛠 도구 알아보기
MLflow
MLflow는 데이터브릭스(Databricks)에서 만든 ML 라이프 사이클을 End-to-end로 관리할 수 있는 오픈소스 툴입니다. 얼마 전만 하더라도 대표적인 MLOps 툴로 실제 서빙 환경에서도 자주 사용되던 툴로 기억합니다. 굉장히 많은 ML 프레임워크와 통합이 가능하고 REST API 등을 통한 모델 서빙이 굉장히 간편했기 때문인데요. 최근에는 BentoML과 같은 더 좋은 툴이 많이 생겨서 그 자리를 내주었고, MLflow는 실험 트래킹이나 재현 가능한 형태로 패키징하는 용도로 많이 사용하고 있습니다. 이 아티클에서 소개하는 MLflow 컴포넌트는 MLflow Tracking입니다. MLflow 오피셜 문서에서는 MLflow Tracking을 이렇게 소개하고 있습니다.
MLflow Tracking은 사용자가 ML 코드를 실행하고 결과를 시각화할 때 파라미터, 코드 버전, 메트릭(metrics), 아티팩트(artifacts)에 대한 로그를 작성하기 위한 API와 UI를 제공합니다.
Optuna
Optuna는 ML 알고리즘의 하이퍼파라미터 튜닝을 자동화해주는 오픈소스 툴입니다. 유사한 툴로 Hyperopt가 있지만 사용성과 문서화, 시각화 제공 여부 등에서 Optuna의 손을 들어주는 경우가 많죠. Optuna는 사용하기 쉽고 많은 ML 프레임워크와의 통합이 가능하며 모델 튜닝에 대한 세부적인 정보를 제공합니다. (덧. 최근 2.0 릴리즈 버전에서 MLflow와의 통합을 위해 MLflow용 콜백 API를 제공하고 있습니다.)
💻 도구 사용하기
준비
MLflow와 Optuna를 설치해줍니다.
$ pip install -U mlflow optuna데이터는 캐글에서 House Price - Advanced Regression Techniques
대회의 데이터를 활용했습니다.
$ kaggle competitions download -c house-prices-advanced-regression-techniques[데이터 전처리]
데이터 전처리는 간단하게 진행합니다. 수치형 변수는 최빈값으로 결측값을 메꾸고 MinMaxScaler()를 적용합니다. 범주형 변수는 결측 범주를 "None"으로 채워줍니다.
from typingimport List
import numpyas np
import pandasas pd
from sklearn.composeimport ColumnTransformer
from sklearn.imputeimport SimpleImputer
from sklearn.pipelineimport Pipeline
from sklearn.preprocessingimport MinMaxScaler
def load_data() -> tuple[pd.DataFrame, np.ndarray]:
df = pd.read_csv("./data/train.csv")
y = np.log1p(df["SalePrice"].ravel())
X = df.drop(["Id", "Alley", "PoolQC", "Fence",
"MiscFeature", "SalePrice"], axis=1)
return X, y
def identify_column_types(X: pd.DataFrame) -> tuple[List, List]:
num_cols = X.select_dtypes("number").columns.tolist()
cat_cols = X.select_dtypes("object").columns.tolist()
return num_cols, cat_cols
def make_preprocess_pipeline(num_cols, cat_cols) -> ColumnTransformer:
num_processor = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("scaler", MinMaxScaler())
])
cat_processor = Pipeline(steps=[
("imputer", SimpleImputer(strategy="constant",
fill_value="None"))
])
preprocessor = ColumnTransformer([
("num", num_processor, num_cols),
("cat", cat_processor, cat_cols)
])
return preprocessor
X, y = load_data()
num_cols, cat_cols = identify_column_types(X)
preprocessor = make_preprocess_pipeline(num_cols, cat_cols)
X_ = pd.DataFrame(preprocessor.fit_transform(X, y),
columns=num_cols+cat_cols)모델링 (CatBoost + Optuna)
모델링을 위한 알고리즘은 범주형 변수가 많기 때문에 CatBoost를 사용합니다. 튜닝할 하이퍼파라미터는 max_depth, learning_rate, subsample, l2_leaf_reg 입니다. 각각에 대한 설명은 공식 문서에서 확인하시기 바랍니다. 하이퍼파라미터 튜닝을 위해 5-fold Cross Validation을 수행하여 가장 낮은 RMSLE (Root Mean Squared Logarithmic Error)를 갖는 모델을 탐색합니다. Optuna를 이용하여 모델을 튜닝하고, Optuna Optimizer에 사용할 Pruner는 HyperbandPruner 를 사용합니다. 다른 Pruner를 사용해도 무방합니다.
import catboost
import optuna
class Objective(object):
def __init__(self, pool):
self.pool = pool
def __call__(self, trial):
pool =self.pool
max_depth = trial.suggest_int("max_depth", 3, 10)
learning_rate = trial.suggest_float("learning_rate", 0.05, 0.3)
subsample = trial.suggest_float("subsample", 0.75, 1)
l2_leaf_reg = trial.suggest_float("l2_leaf_reg", 1e-5, 1e-1, log=True)
params = {"loss_function": "RMSE",
"depth": max_depth,
"learning_rate": learning_rate,
"subsample": subsample,
"l2_leaf_reg": l2_leaf_reg}
cv_result = catboost.cv(pool=pool,
params=params,
num_boost_round=1000,
nfold=5,
seed=0,
early_stfopping_rounds=30,
verbose=False)
rmsle = cv_result["test-RMSE-mean"].min()
return rmsle
pool = catboost.Pool(X_, label=y, cat_features=cat_cols)
objective = Objective(pool)
study = optuna.create_study(
study_name="house_price_prediction",
direction="minimize",
pruner=optuna.pruners.HyperbandPruner(max_resource="auto")
)MLflow 콜백(Callback) 적용
이제 여기에 MLflow를 위한 콜백을 적용합니다. 해당 콜백을 적용하면 코드가 위치한 폴더에 모델의 학습 정보가 저장되고 추후에 Web UI를 통해서 결과를 확인할 수 있습니다. Optuna에 MLflow를 위한 콜백을 위한 클래스인 MLflowCallback이 있고, 여기에 저장될 폴더명인 tracking_uri와 확인할 모델 메트릭명을 metric_name 으로 설정하여 Optuna Study에 사용하면 됩니다. 50번의 Trial을 수행하는 동안 모델 학습 정보는 ./mlruns 에 저장됩니다.
from optuna.integration.mlflowimport MLflowCallback
def make_mlflow_callback():
cb = MLflowCallback(
tracking_uri="mlruns",
metric_name="RMSLE"
)
return cb
mlflow_cb = make_mlflow_callback()
study.optimize(objective, n_trials=50, callbacks=[mlflow_cb])Web UI 확인
최적화 중, 또는 최적화 완료 후에 mlruns 폴더가 있는 경로에서 다음 명령어를 입력합니다.
$ mlflow ui그러면 로컬호스트에 5000번 포트를 통해서 UI 페이지로 접근할 수 있습니다.
https://127.0.0.1:5000tracking_uri가 있는 폴더에서 제대로 실행했다면 아래와 같은 UI 페이지를 확인할 수 있습니다.
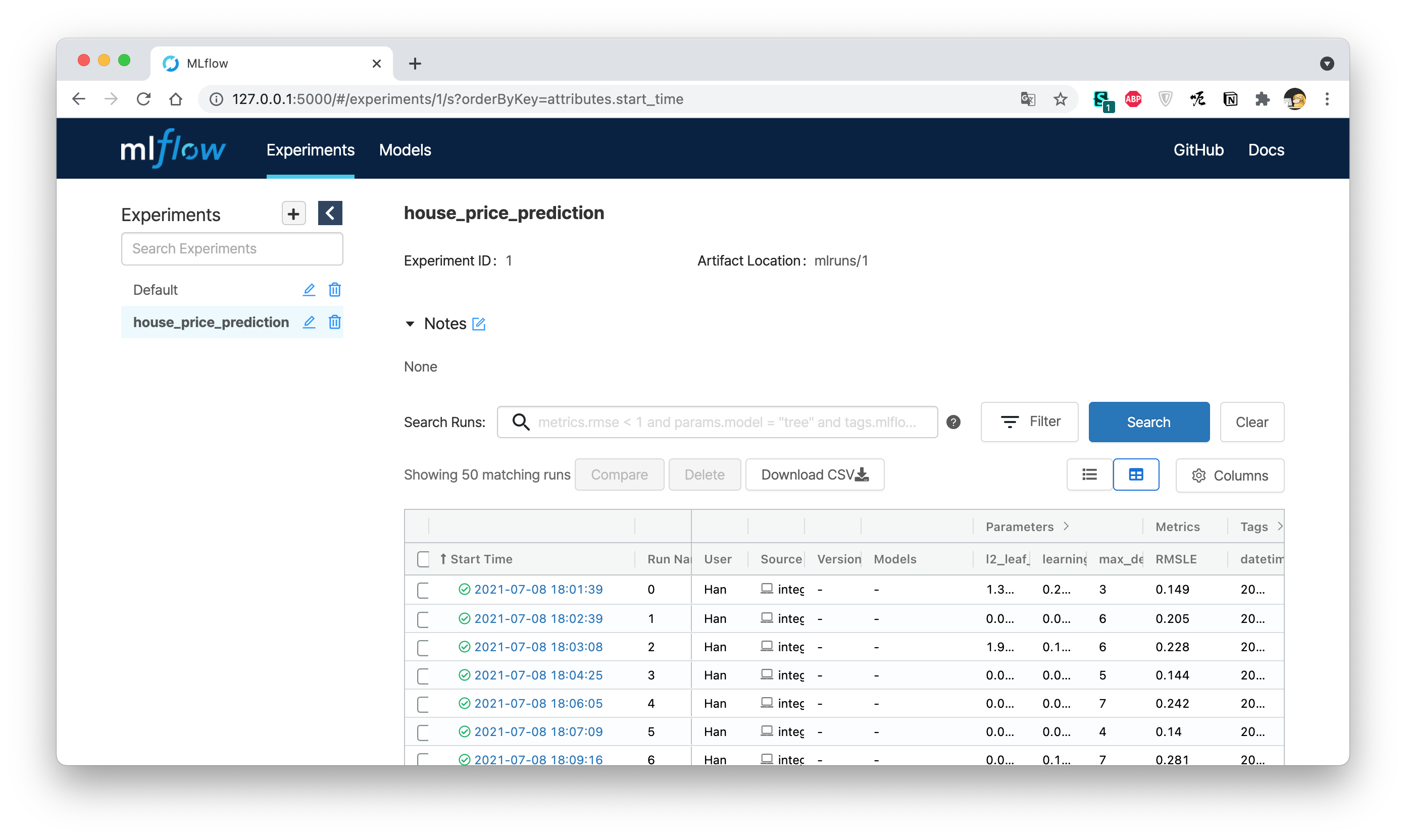
모델의 시작 시간, 각 하이퍼파라미터 값, RMSLE 메트릭 등 코드에 작성한 모든 설정값을 확인할 수 있습니다.
🎯 요약
MLflow와 Optuna를 사용하면 모델의 재현은 물론, 각 실험의 결과를 길지 않은 코드 작성으로 보기 쉽게 관리할 수 있습니다. 특히 각 라이브러리가 업데이트되면서 다른 ML 프레임워크와의 통합이 가속화되고 제공하는 범위가 넓어지면서 더욱이 활용성이 높아지고 있습니다.
본 아티클에서는 MLflow와 Optuna의 기능 일부만을 사용했을 뿐, 각 라이브러리는 ML 모델을 자주 개발하고 실험하는 데이터 사이언티스트들에게 훌륭한 기능들이 많습니다. 예를 들어 MLflow의 MLflow Project나 Optuna의 시각화 기능이 있습니다. Medium 아티클이나 공식 문서 내의 튜토리얼을 확인하셔서 업무 생산성을 높일 수 있는 기회를 놓치지 않으셨으면 합니다.
