
아래 링크로 접속 부탁드립니다 :)
https://otzslayer.github.io/python/2021/10/15/multiprocesesing-using-ray.html
번거로운 멀티프로세싱 😫
우리는 제법 큰 데이터에 대한 작업을 자주 합니다. 그게 Cosine Similarity를 구하는 것이든, Correlation을 구하는 것이든 말이죠. 처음에 코드를 짜고 결과가 잘 나오기만 하면 우선은 다행입니다. 결과를 확인하여 문제가 없다면 '이걸 더 빠르게 만들 수는 없을까?'라고 생각하게 되죠. 결국 많이 고민한 뒤 병렬 처리를 하기로 마음을 먹습니다.
마음을 먹고 여러 문서를 찾아보니 파이썬에서 기본으로 제공해주는 multiprocessing이라는 표준 라이브러리가 있었습니다. 사용법을 알아보니 영 마음에 들지 않습니다. 기존 코드를 많이 바꿔야 할 것 같고, 바꾸는 코드는 잘 이해가 되지 않습니다. 그래도 적지 않은 시간을 들여서 multiprocessing 을 이용해 코드를 짜고 결과를 봤더니 제법 속도도 빨라졌습니다. 그래도 여전히 개념이 잘 이해가 안 되고, 조금 더 빠르고 단순한 방법으로 코드를 짜고 싶습니다. 무슨 방법이 없을지 고민에 빠집니다.
multiprocessing 은 어떻길래? 🐢
파이썬 STL인 multiprocessing은 병렬 처리를 시도할 때 가장 먼저 마주하게 됩니다. (Documentation)
multiprocessing은 프로세스 스포닝(Process Spawning)을 지원하여 자원 내에서 사용 가능한 다중 프로세서를 활용 가능하게 합니다. 그리고 생성한 프로세스 풀을 제어하는 프로세스 풀 객체 (Pool)를 통해 병렬 처리를 하게 됩니다. Pool 클래스 내에 프로세스 수를 설정하여 map() 이나 imap(), map_async(), imap_unordered() 등의 메서드를 사용하면 됩니다.
- 프로세스 스포닝 (Process Spawning)
: 부모 프로세스가 운영 체제에 요청하여 자식 프로세스를 생성하는 과정
풀을 이용한 간단한 예제를 살펴보겠습니다. 100만 개의 숫자로 이루어진 배열에 10을 곱하는 예제입니다. 프로세스의 수는 16개로 설정하였습니다. 일반적인 파이썬의 List Comprehension과 비교해보도록 하겠습니다. 동일한 순서로 값을 반환하기 위해 map() 메서드를 사용하였습니다.
import numpy as np
from multiprocessing import Pool
arr = np.random.random(1000000)
def mul(x):
return x * 10
# Serial Python
result = [mul(x) for x in arr]
>> Wall time: 660 ms ± 11.2 ms per loop
with Pool(processes=16) as p:
result = p.map(mul, arr)
>> Wall time: 3.82 s ± 53.1 ms per loop우선 코드를 보면 프로세스 풀을 Pool() 로 선언하고 그 안에 프로세스 수를 입력합니다. 그다음 해당 프로세스 풀에 map() 메서드로 병렬 처리된 연산 결과를 얻을 수 있습니다. 그런데 결과가 생각과는 완전 다릅니다. List Comprehension을 사용하였을 때 660 ms가 소요되었는데, 오히려 multiprocessing.Pool을 사용했을 때 6배 넘는 시간이 소요되었습니다. 원인이 무엇일까요?
덧) 사실 이 예제는 result = arr * 10 이 가장 빠르게 결과를 반환합니다.
이해를 위해서는 multiprocessing 라이브러리가 어떤 식으로 프로세스 간의 객체 전달을 수행하는 지를 알아야 합니다. multiprocessing은 큰 데이터를 다른 프로세스에 전달할 때 pickle을 사용해 직렬화(Serialize)한 뒤 전달합니다. 지금 우리는 16개의 프로세스에서 작업을 하도록 설정하였으니 그만큼의 데이터 복사본을 만들어야 하므로 큰 메모리를 사용하게 됩니다. 더불어서 여기에 역직렬화를 통해 데이터를 받아야 하므로 굉장히 큰 오버헤드가 발생합니다.
덧) 이 예제에서는 드러나지 않지만 선언해놓은 프로세스 풀을 닫지 않은 채로 방치하는 경우, 프로세스가 메모리에 계속해서 남는 현상인 메모리 누수도 발생합니다. 물론 이를 해결하기 위해 비동기적으로 병렬 처리를 하고 contextlib 라이브러리의 closing() 함수를 이용하기도 합니다.
간략하게 말하자면 프로세스에 데이터를 전달하는 행위가 많아짐에 따라 오히려 수행 시간에 악영향을 미치게 됩니다. 사실 위 예제가 매우 단순하기 때문에 이 같은 문제가 훨씬 두드러지게 보이는 것은 사실입니다. 조금 더 복잡한 연산이 들어가는 경우에는 multiprocessing이 더 빠른 속도를 보입니다만 위에서 언급한 메모리 문제는 사라지지 않습니다. 기존에 작성한 코드의 형태까지 바꿨음에도 많은 문제가 있어 원하는 병렬 처리를 하지 못했습니다. 방법이 없는걸까요?
Ray를 만나다! 🙌
![]()
심각한 고민에 빠져있던 중 단비와도 같은 라이브러리를 발견합니다. 바로 Ray입니다. Ray는 분산 애플리케이션을 위한 단순하고 범용적인 API를 제공합니다. Ray는 multiprocessing에 비해 여러 가지 장점을 가지고 있습니다.
- 병렬 처리를 위해 코드를 뜯어 고칠 필요가 없습니다.
multiprocessing에서 발생하는 직렬화 오버헤드 문제가 발생하지 않습니다.- 빠릅니다! 🏃
위에서 다루었던 예제를 Ray에서는 어떻게 할 수 있는지 아래 코드로 살펴보겠습니다.
import ray
ray.init(num_cpus=16)
@ray.remote
def mul(x):
return x * 10
arr = ray.put(arr)
result = ray.get(mul.remote(arr))
>> 34.6 ms ± 12.3 ms per loop우선 코드가 매우 간결합니다. 기존 함수에 데코레이터(Decorator)를 추가하고, 함수를 호출할 때 remote() 메서드를 이용하는 것 말고는 큰 차이가 없습니다. 게다가 수행 시간은 기본 파이썬보다 매우 빠른 것을 알 수 있습니다. Ray가 이렇게 빠를 수 있는 이유는 아래와 같습니다.
Ray는 multiprocessing 에서 발생하는 직렬화 오버헤드를 해결하기 위해 Apache Arrow를 사용합니다. Apache Arrow는 행(Row) 기반이 아닌 컬럼 기반의 인메모리 포맷으로 Zero-Copy 직렬화를 수행합니다. 또한 직렬화된 데이터를 인메모리 객체 저장소 (In-Memory Object Store)인 Plasma를 이용해 직렬화된 데이터를 빠르게 공유합니다.
(Reference 1) (Reference 2)
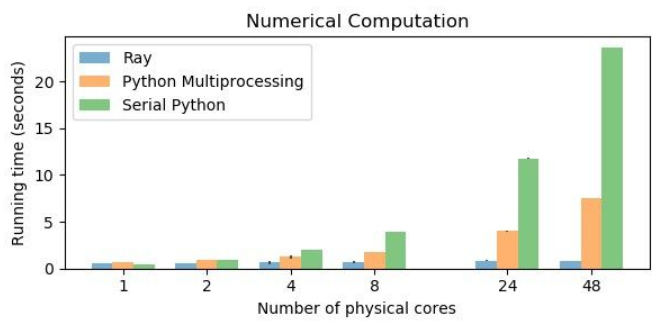
아래 차트는 기본 파이썬, multiprocessing, Ray의 수치 계산에 대한 속도 차이를 보여줍니다. 물리적 코어의 수가 늘어날 수록 Ray의 성능이 다른 라이브러리에 비해 상대적으로 압도적인 것을 볼 수 있습니다.
이제 Ray에 대해서 더 자세히 알아볼 때입니다. Ray의 철학은 무엇인지, 무엇으로 구성되어 있는지, 어떻게 사용하는지 알아봅시다.
Ray의 철학은 뭘까? 🤔
병렬 처리가 해주어야 하는 것들은 무엇이 있을까요? Ray를 만든 Anyscale의 공동 설립자이자 CEO인 Robert Nishihara는 본인의 Medium 아티클에서 병렬 처리란 아래의 요구사항을 반드시 만족해야 한다고 말했습니다.
- 둘 이상의 머신에서 동일한 코드로 실행이 가능해야 한다.
- Stateful하고 상호간 통신 가능한 Microservice와 Actor를 구축할 수 있어야 한다.
- 장애 대응이 적절히 이루어져야 한다.
- 큰 객체와 수치 데이터를 효율적으로 다룰 수 있어야한다.
multiprocessing은 위 요구사항을 대다수 만족하지 못합니다. 하지만 Ray는 이 모든 요구사항을 만족시킬 뿐만 아니라, 이것들을 단순한 방법으로 해결할 수 있게 해줍니다. 더 나아가 머신러닝 전반에 걸쳐 병렬 처리가 가능하도록 다양한 추가 라이브러리를 개발하고, 다른 라이브러리, 퍼블릭 클라우드와의 통합을 통해 Ray Ecosystem을 구축하고 있습니다. 아래 이미지는 Ray Ecosystem 전반을 보여줍니다. 우리가 머신러닝을 사용할 때 거쳐야하는 모든 단계에서 Ray와 관련된 라이브러리를 만날 수 있습니다.

Ray는 무엇으로 구성되어 있을까? ⚙️
Ray의 목표 중 하나는 병렬 처리를 위한 간단하지만 범용적인 API를 제공하는 것입니다. 실제로도 Ray를 사용하면 잘 모르더라도 병렬 처리를 손쉽게 할 수 있습니다. 하지만 Ray를 더 잘 사용하기 위해서는 Ray의 구성요소를 이해하는 것이 큰 도움이 됩니다. 알아야 할 핵심적인 구성요소도 많지 않습니다. Task, Object, Actor가 전부입니다. 만약 이 내용이 잘 이해가 되지 않는다면 다음 내용으로 넘어가도 좋습니다!
Task
- 호출하는 곳과 다른 프로세스에서 실행되는 함수 또는 클래스입니다.
- 위에서 한 것처럼 함수를
@ray.remote라는 데코레이터로 감쌌다면 그 함수는 Task라고 부릅니다. - Remote Function이라고도 부르며, 호출자와는 비동기적(asynchronously)으로 실행됩니다.
remote()메서드를 써서 호출 가능하며ObjectRef라는 값을 반환합니다.ray.get(ObjectRef)를 하여 Task를 실행하고 값을 반환받을 수 있습니다.
Object
- Task를 통해서 반환되거나
ray.put()을 통해 생성되는 값입니다. - 데이터의 크기가 큰 경우
ray.put()을 통해 Object로 만들어 Ray에서 빠르게 사용할 수 있습니다.다만 Object는 Spark의 RDD와 같이 immutable합니다.
Actor
- Stateful한 워커 프로세스입니다.
@ray.remote를 통해서 Actor Class로 만들 수 있고, 이 클래스의 메서드 호출은 Stateful Task가 됩니다.
Ray는 어떻게 사용할까? 💻
설치
pip install ray를 통해 쉽게 설치할 수 있습니다. 다만 윈도우에 설치하기 위해서는 Visual C++ 런타임이 설치되어 있어야 합니다. 윈도우 의존성 관련해선 해당 페이지를 확인하시기 바랍니다.
사용법
우선 Ray를 임포트합니다.
import ray그 후에 반드시 Ray를 실행해줘야 합니다.
ray.init()실행 후에는 많은 메시지가 출력되는데 그 중에서 View the Ray dashboard at http://127.0.0.1:8265 와 같은 내용이 있습니다. 일반적인 환경에서 8265 포트가 열려 있다면 위 주소에서 대시보드를 확인할 수 있습니다. 대시보드에서는 자원 사용량, 현재 설정 등 다양한 정보를 확인할 수 있습니다.
여기까지 문제가 없었다면 병렬 처리하여 실행할 함수에 데코레이터를 추가합니다. 예를 들어 큰 행렬 두 개를 만들어 Dot Product를 수행한다고 할 때, 다음의 함수들을 작성하게 됩니다.
import numpy as np
def create_matrix(size):
return np.random.normal(size=size)
def multiply_matrices(x, y):
return np.dot(x, y)위 두 함수를 각각 데코레이터를 추가하여 병렬처리 한다면 아래 코드가 되겠죠.
import numpy as np
@ray.remote
def create_matrix(size):
return np.random.normal(size=size)
@ray.remote
def multiply_matrices(x, y):
return np.dot(x, y)이제 각각의 함수는 Remote Function이 되었습니다. 결과만 얻으면 하고자 하는 일은 마무리됩니다. Remote Function들에 remote() 메서드를 사용하여 호출합니다.
x_id = create_matrix.remote([1000, 1000])
y_id = create_matrix.remote([1000, 1000])
z_id = multiply_matrices.remote(x_id, y_id)여기까지 하셨다면 마지막으로 Task를 실행해서 값을 반환 받을 수 있습니다. ray.get() 을 사용하면 됩니다.
z = ray.get(z_id)Ray의 사용이 끝났다면 프로세스를 종료해야 합니다.
ray.shutdown()Tips
- 큰 데이터를 반복적으로 사용하게 된다면
ray.put()을 사용해 메모리 사용을 줄일 수 있습니다.ray.put()은 데이터를 공유 메모리에 저장하여 복사본을 만들지 않고 모든 프로세스에서 접근할 수 있습니다. 사실은 첫 예제에서 이미 사용을 하고 있었습니다.
import numpy as np
import ray
ray.init(num_cpus=16)
arr = np.random.random(1000000)
@ray.remote
def mul(x):
return x * 10
arr = ray.put(arr)
result = ray.get(mul.remote(arr))- 크기가 작은 작업들을 모두 Ray의 Task로 만들지 않도록 합니다. 오히려 스케줄링이나 내부 커뮤니케이션으로 인해 불필요한 오버헤드가 생길 수 있습니다. Ray가 아무리 빠르더라도 많이 호출하여 사용할 필요는 없습니다. 큰 Task를 생성해서 작은 함수를 여러 번 실행하도록 하는 것이 성능에 도움을 줄 수 있습니다.
- Ray와 TensorFlow를 함께 사용할 때 Pickling 이슈가 발생하는 것으로 알려져 있습니다. 공식 문서에서도 찾을 수 있지만, 이 경우에는
import tensorflow as tf를 Remote Function 안에서 호출하여 해결할 수 있다고 알려져 있습니다.
더 많은 팁은 RiseLab의 페이지를 확인하시기 바랍니다.
마무리 🙇
과거와 다르게 요즘에는 쉽고 편하게 프로그램의 실행 속도를 개선할 수 있는 라이브러리들이 많아졌습니다. Stack Overflow에서 머리를 쥐어뜯어가며 문제를 해결하지 않아도 될 정도로 유저 친화적인 라이브러리들 말이죠. 글에서 소개한 Ray는 그 대표 주자입니다. Ray 뿐만 아니라 Dask나 Ray에 기반에 둔 Modin 등 활용성이 높은 라이브러리가 굉장히 많습니다. 조금만 이해하여 업무나 프로젝트에 활용한다면 높은 생산성을 확보할 수 있지 않을까 싶습니다.
References 📚
- https://zzsza.github.io/mlops/2021/01/03/python-ray/
- https://riiidtechblog.medium.com/ray-%ED%99%95%EC%9E%A5-%EA%B0%80%EB%8A%A5%ED%95%9C-%EA%B3%A0%EC%84%B1%EB%8A%A5-%EB%B6%84%EC%82%B0-%EB%B3%91%EB%A0%AC-machine-learning-%ED%94%84%EB%A0%88%EC%9E%84%EC%9B%8C%ED%81%AC-f17f9c9cbef3
- https://rise.cs.berkeley.edu/blog/ray-tips-for-first-time-users/
- https://towardsdatascience.com/modern-parallel-and-distributed-python-a-quick-tutorial-on-ray-99f8d70369b8
- https://github.com/ray-project/ray


좋은 포스팅 감사드립니다!