
들어가면서
저는 자연어처리 연구실에서 1년 반동안 지내며 여러 프로젝트를 진행해보며, bert, gpt 와 같은 여러 언어모델들과 자연어처리 방법론들은 익혀왔습니다. 그 이후에도 꾸준하게 자연어 처리에 대한 관심을 가져오고 있었는데, 최근 chatgpt의 영향으로 관심도가 높아지면서 사방에서 이에 대한 이야기들이 쏟아지고 있는 상황이 되어 조금 당황하고 있었습니다.
이번에 취업을 준비하면서 삼성소프트웨어아카데미에 들어와 활동을 하고 있었는데. 싸피에서도 인공지능, chatgpt 에 대한 관심이 높다는 것을 느꼈고, 이런 딥러닝 모델에 관한 관심에 도움이 되고자 이번 글을 적게 되었습니다.
개인적으로 여러 자연어 처리의 분야들 중에서 재미있는 포인트, 다른데 적용하기 좋은 아이디어를 가지는 부분, 장점과 단점을 비교할 수 있는 부분들에 대해 소개 하고자 합니다.
학습
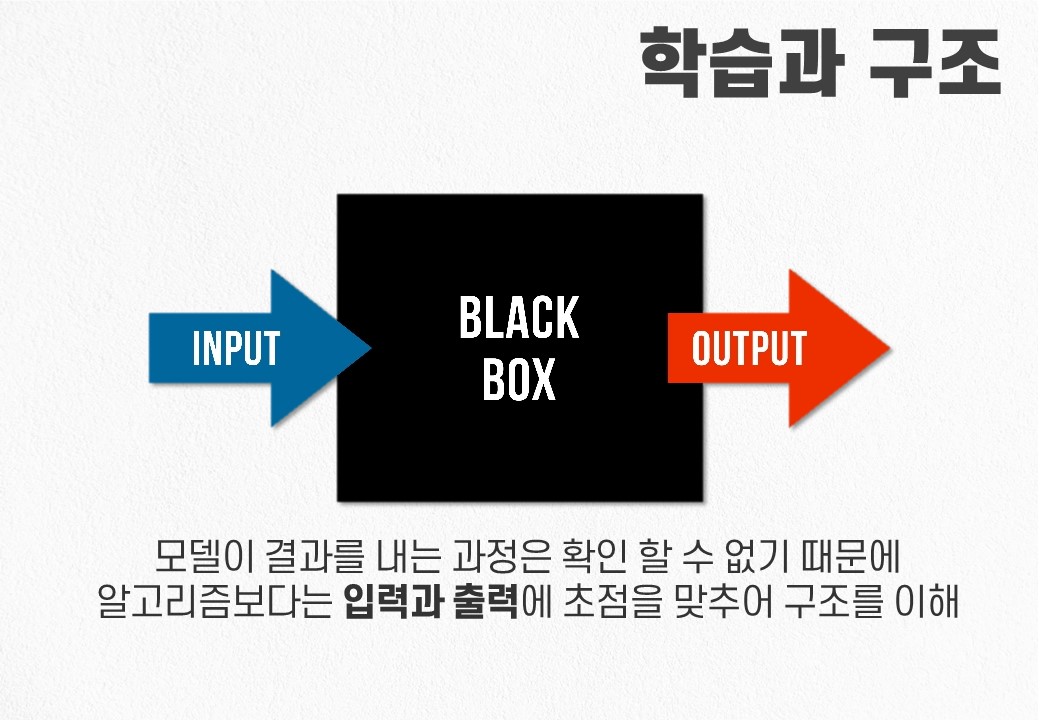
인공지능은 데이터에 의존합니다.. 입력 데이터와 출력 데이터 간의 관계를 예측하고, 예측 출력과 실제 출력 간의 차이를 줄이면서 학습을 진행하게됩니다. 예를 들어 그림을 그리는 모델의 경우, 입력 문장과 출력 그림을 일치시키도록 학습을 진행하고, 챗봇의 경우 사람의 입력에 대한 대답을 학습합니다. 따라서 데이터가 존재하지 않는 경우 학습을 진행할 수 없으며, 데이터 양이 적은 경우에는 원활한 학습이 불가능하여 정확도가 낮아지는 문제를 가집니다. 이러한 이유로 인공지능을 활용하고자 한다면 우선 데이터를 구할 수 있는지 확인하는 것이 중요합니다.
추가적으로 인공지능이 발전하여 우리의 일자리를 위협한다면 우선순위는 데이터양이 많은것이 우선될 것 입니다. 전산화하기 쉽고 저장하기 쉬운 데이터가 있는 분야들은 인공지능이 쉽게 학습하여 대체할 것 입니다.
경사 하강법 Gradient descent
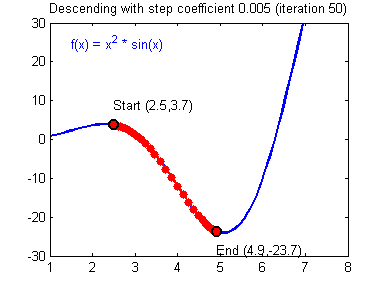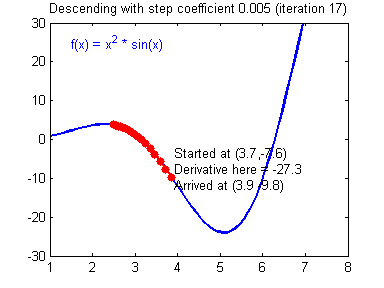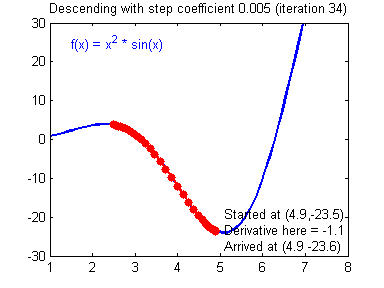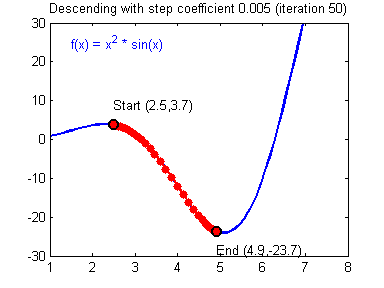
image blog
인공지능(Artificial Intelligence, AI)에서 예상 출력과 실제 출력 간의 차이를 줄이기 위해 사용되는 대표적인 알고리즘은 경사하강법(Gradient Descent)입니다. 경사하강법은 함수의 기울기(경사)를 구하고, 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복하여 결과를 찾아내는 알고리즘인데. 간단히 결과값을 보고 가중치를 변화시켜 원하는 결과값이 나올 때까지 변화시켜 가중치를 찾아내는 알고리즘입니다.
실제 결과값과 모델의 결과값을 비교하여 차이를 이용하여 가중치를 변화시키는 것을 '역전파(BackPropagation)'라고 합니다. 역전파는 손실 함수(Loss Function)을 사용하여 실제 결과값과 모델의 결과값 간의 차이를 계산하고, 이를 토대로 가중치를 조정합니다.
학습의 과정
인공지능(Artificial Intelligence, AI)의 학습 과정은 입력값과 실제 결과값을 가지고, 예상 결과값을 만든 후 평가하는 과정을 거칩니다. 이때 나타난 평가 결과를 이용하여 다시 가중치를 변화시키면서 해당 입력값에 가중치를 적용했을 때 실제 결과값이 나타나는 가중치를 찾아낼 수 있습니다.
학습 과정은 크게 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)으로 구분됩니다. 지도 학습에서는 입력값과 실제 결과값을 가지고 예측 모델을 학습시키며, 비지도 학습에서는 결과값 없이 입력값만으로 모델을 학습시킵니다. 강화 학습에서는 환경과 상호작용하며 피드백을 받아 모델을 학습시킵니다.
학습 과정에서는 주어진 데이터를 이용하여 모델을 학습시키는 과정을 반복하며, 이를 통해 최적의 가중치를 찾아내어 예상 결과값과 실제 결과값 간의 차이를 최소화합니다. 이러한 학습 과정을 통해 인공지능 모델은 점차적으로 정확도를 향상시키며, 다양한 문제를 해결할 수 있는 능력을 갖추게 됩니다.
자연어처리
자연어 처리(Natural Language Processing, NLP)는 인공지능의 한 분야로, 한국어나 영어와 같은 자연어를 처리하는 것에 초점을 맞춘 학문입니다. 인공지능이 자연어를 이해하고 처리할 수 있도록 하는 것이 목표로 합니다.
자연어 처리에서는 인공지능의 학습을 자연어에 적용시키는 방법이 중요합니다. 이를 위해 자연어 처리 모델은 텍스트 데이터를 수집하고 전처리한 후, 학습 데이터로 사용하여 모델을 학습시킵니다. 예전에는 통계적인 방식으로 맞춤법 검사나, 이진분류들의 처리를 해왔었는데. 알파고의 등장과 언어모델의 등장이후 최근에는 딥러닝 알고리즘을 적용한 인공지능 기술이 발전하면서 자연어 처리 분야에서도 높은 정확도와 성능을 보이고 있습니다.
인코딩
자연어 처리를 위해서는 문자열을 그대로 모델에 적용하는 것은 쉽지 않습니다, 이를 위해서는 문자열을 의미를 가진 데이터로 변환하는 과정이 필요로 합니다. 이 과정을 인코딩이라고 하는데, 이를 통해 문자열을 수많은 차원의 배열인 텐서로 변환합니다. 인코딩은 자연어 처리에서 매우 중요한 역할을 담당하며, 언어모델, 분류모델, 챗봇 등 다양한 자연어 처리 모델에서 필수적으로 적용되는 기술입니다.
일반적인 문자열은 문자들의 아스키 코드 값만을 가지고 있기 때문에 아무런 의미적 정보를 가지고 있지 않아 처리하기 어렵습니다. 그렇기 때문에 인코딩을 통해 문자열을 수많은 차원의 배열인 텐서로 변환하면, 해당 데이터를 딥러닝 모델이나 검색기에 적용하기 용이합니다.
TF-IDF
인코딩의 대표적인 예시인 TF-IDF는 자연어 처리에서 널리 사용되는 기법 중 하나입니다. 여기서 TF는 Term Frequency, IDF는 Inverse Document Frequency를 의미 합니다. 단어의 빈도수를 문서에서의 빈도수로 나눈 것으로, 문장에서 가장 많이 나타나는 단어의 가중치가 높아지고, 여러 문서에서 자주 사용되는 조사나 대명사와 같은 일반적인 단어의 가중치는 낮아지게 됩니다. 반면, 가끔씩 사용되는 단어는 높은 가중치를 갖게 됩니다. 이를 통해 간단하게 인코딩할 수 있으며 문서 검색, 분류 등 다양한 분야에서 활용할 수 있습니다.
word2vec
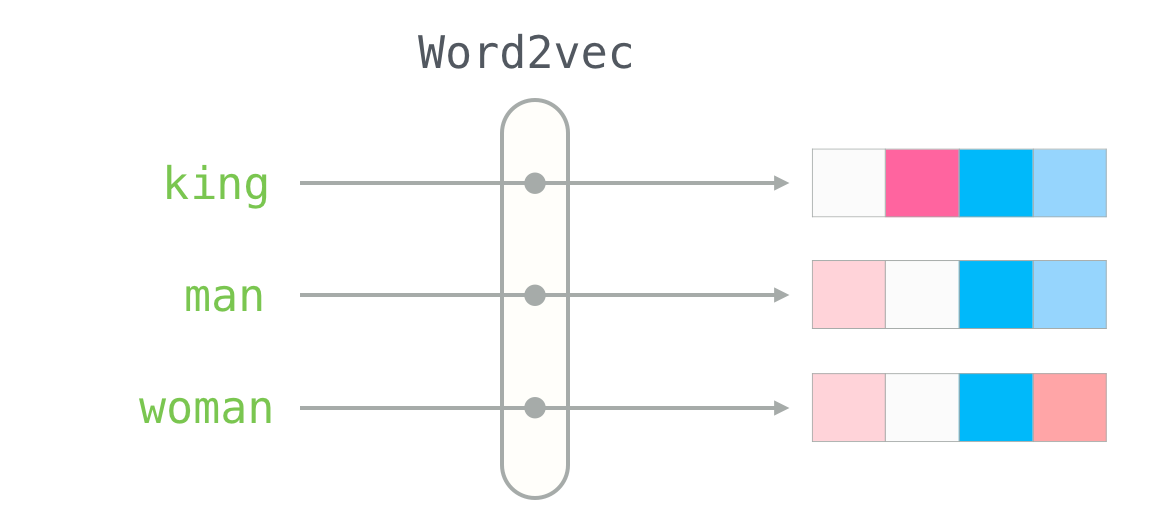
word2vec은 자연어처리에서 가장 많이 사용되는 기법 중 하나로, 단어를 벡터로 변환하여 처리하는 방식입니다. 이는 단어를 벡터 공간 상의 좌표로 나타내어 단어 간의 유사성을 계산하고, 단어의 의미와 관련된 정보를 추출할 수 있도록 해줍니다.
word2vec은 크게 CBOW와 Skip-gram 두 가지 모델로 나뉘어집니다. CBOW 모델은 주변 단어들을 이용해 중심 단어를 예측하는 방식으로 학습을 진행하며, Skip-gram 모델은 중심 단어를 가지고 주변 단어를 예측하는 방식으로 학습을 진행합니다.
이러한 학습 과정에서 word2vec 모델은 동음이의어를 처리할 수 있는데, 예를 들어 "배"라는 단어의 경우 "먹는 배"와 "타는 배"와 같은 여러 가지 의미를 가질 수 있습니다. 주변 단어들을 이용하여 처리하여 먹는 배와 이동수단의 배를 구별할 수 있고. 단어의 의미는 분산된 벡터 형태로 인코딩하게 됩니다.
시계열 데이터
시계열 데이터는 일정 시간 단위로 변하는 데이터나 일정 순서로 변하는 데이터들을 뜻합니다. 음성, 음악, 동영상, 자연어, 온도, 진동 같은 데이터들이 속합니다. 영어의 경우 단어의 순서에 따라서 문장의 의미가 변합니다. 또한 자연어는 단어와 단어, 문장과 문장의 연결에서 의미가 변하기도 하고, 문서는 문장의 연속, 문장은 단어의 연속으로 구성되기 때문에 자연어처리는 시계열 데이터를 처리하는 방식으로 처리합니다.
RNN, Recurrent Neural Network
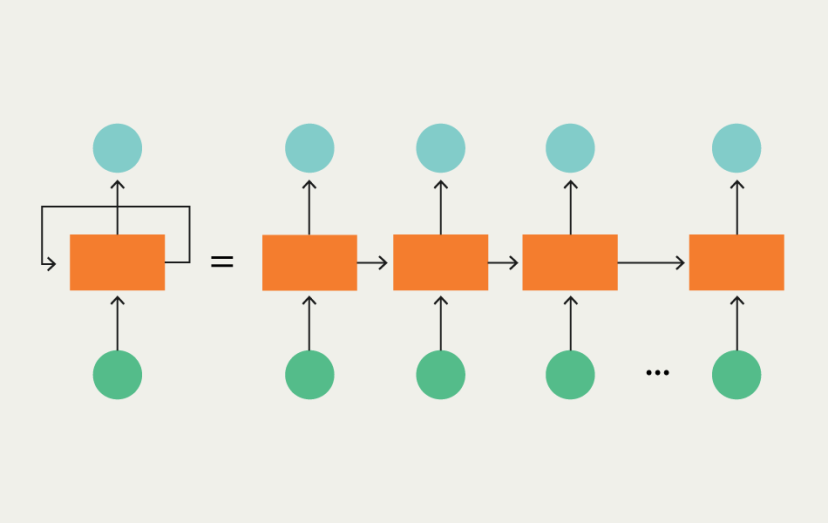
RNN(Recurrent Neural Network)은 순차적인 데이터를 처리하기 위한 딥러닝 모델 중 하나입니다. RNN은 이전 시점의 출력값을 현재 시점의 입력값으로 사용하는 구조를 가지고 있으며, 이를 통해 시계열 데이터 학습할 수 있습니다. RNN은 순환 구조를 가지고 있기 때문에 이전의 정보가 현재의 학습에 반영할 수 있습니다.
하지만 RNN은 긴 시퀀스 데이터를 처리할 때 기울기 소실(Vanishing Gradient) 문제가 발생할 수 있습니다. 이는 역전파 과정에서 이전 시점의 기울기가 지나치게 작아져 학습이 잘 이루어지지 않는 현상입니다. 이러한 문제는 다음에 나올 LSTM(Long Short-Term Memory) 에서 해결 할 수 있습니다.
LSTM
LSTM은 RNN의 한 종류로, 시계열 데이터를 처리하면서 발생할 수 있는 기울기 소실 문제를 개선하기 위해 고안되었습니다. LSTM은 기존 RNN에서 사용되는 은닉상태 외에 새로운 구조인 cell state(셀 상태)를 도입하여 작동합니다.
LSTM은 input gate, forget gate, output gate로 구성됩니다. 각각의 게이트는 sigmoid 함수와 pointwise multiplication 연산을 통해 제어되며, 셀 상태와 은닉 상태의 값을 결정한다. 이렇게 게이트가 셀 상태를 조절하면서 기울기 소실 문제를 해결할 수 있습니다.
input gate는 현재 시점에서 어떤 정보를 셀 상태에 입력할 것인지를 결정하며, forget gate는 이전 시점의 셀 상태를 얼마나 유지할 것인지를 결정합니다. 마지막으로 output gate는 현재 시점의 은닉 상태를 결정하며, 이는 다음 시점의 셀 상태를 결정하는 데 사용됩니다.
seq2seq
seq2seq 모델은 인코더와 디코더 모델로 구성된 시계열 데이터 처리 모델입니다. 이 모델은 시계열 데이터를 입력으로 받아 내부적으로 추상화된 가중치를 생성하고, 이 가중치를 활용하여 출력을 생성하는 방식으로 동작합니다. 이러한 모델은 챗봇, 기계번역 등 다양한 분야에서 활용될 수 있는데. 예를 들어, 챗봇에서는 사용자가 입력한 문장을 인코더를 통해 처리하고, 디코더를 통해 적절한 응답을 생성합니다. 또한 기계번역에서는 원문을 인코더로 처리하여 추상화된 가중치를 생성하고, 디코더를 통해 번역된 문장을 출력합니다.
Transfomer

트랜스포머(Transformer)는 인코더와 디코더 구조를 가진 모델입다. 이 모델은 LSTM과 같은 순환 신경망(RNN)이 아닌, self-attention 메커니즘을 사용합니다. 이를 통해 입력 단어들 중 중요한 가중치들을 집중적으로 다루고, 필요 없는 가중치들의 영향력을 낮추어 학습을 진행하게 됩니다. 이러한 attention 메커니즘의 특징으로 인해 트랜스포머는 LSTM과 비교하여 더욱 발전된 결과물을 낼 수 있었습니다.
언어 모델
언어 모델(Language model)은 주어진 단어들의 순서를 학습하여, 어떤 단어가 주어졌을 때 그 다음에 나올 가능성이 높은 단어를 예측하는 것을 목적으로 합니다.
언어 모델은 대체로 대량의 말뭉치(corpus)를 사용하여 사전 학습(pre-training)을 합니다. 이 때 입력된 단어들 중에서 일부 단어를 가리는 마스킹(masking)한 후, 이를 예측하도록 학습합니다. 이를 통해 모델은 문장의 구조와 단어들 간의 상호작용을 파악하고, 자연어를 이해하는 능력을 높입니다.
언어 모델은 세부조정(fine-tuning)을 통해 특정 목적에 맞는 모델로 발전시킬 수 있는데. 예를 들어, 챗봇, 개체명 인식, 기계독해 등과 같은 작업을 위한 모델로 개발 할 수 있습니다.
GPT, Generative Pre-trained Transformer
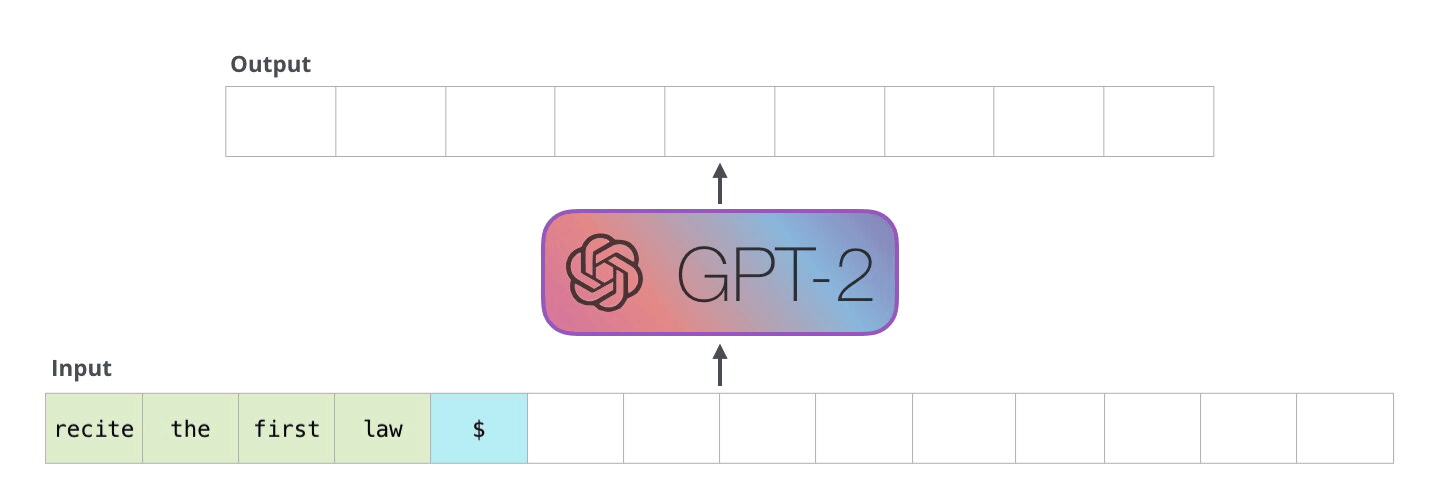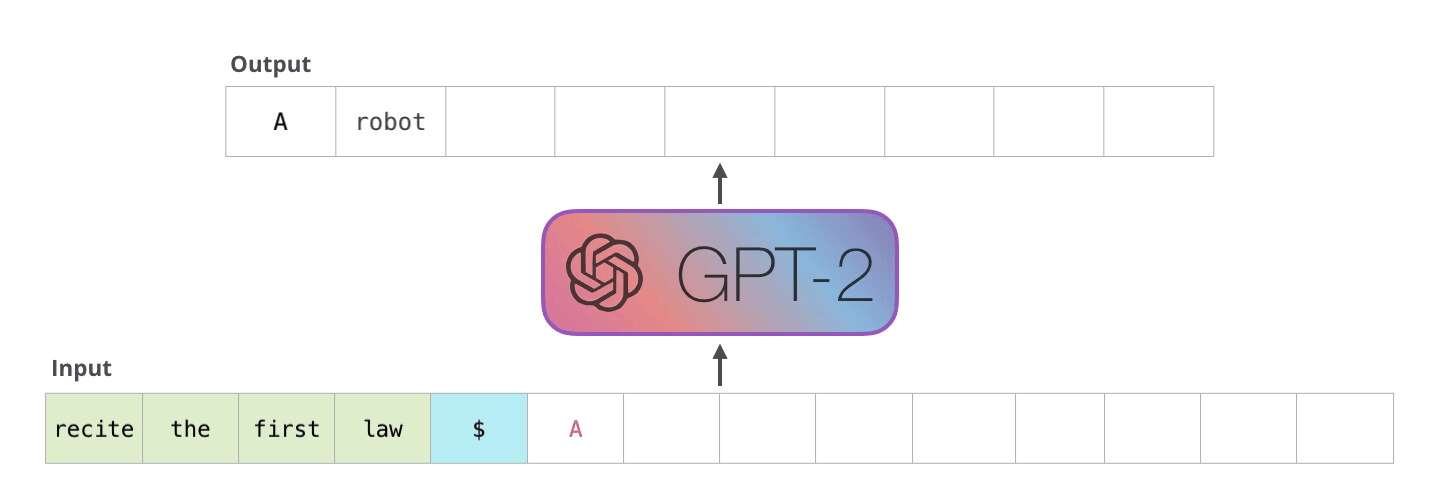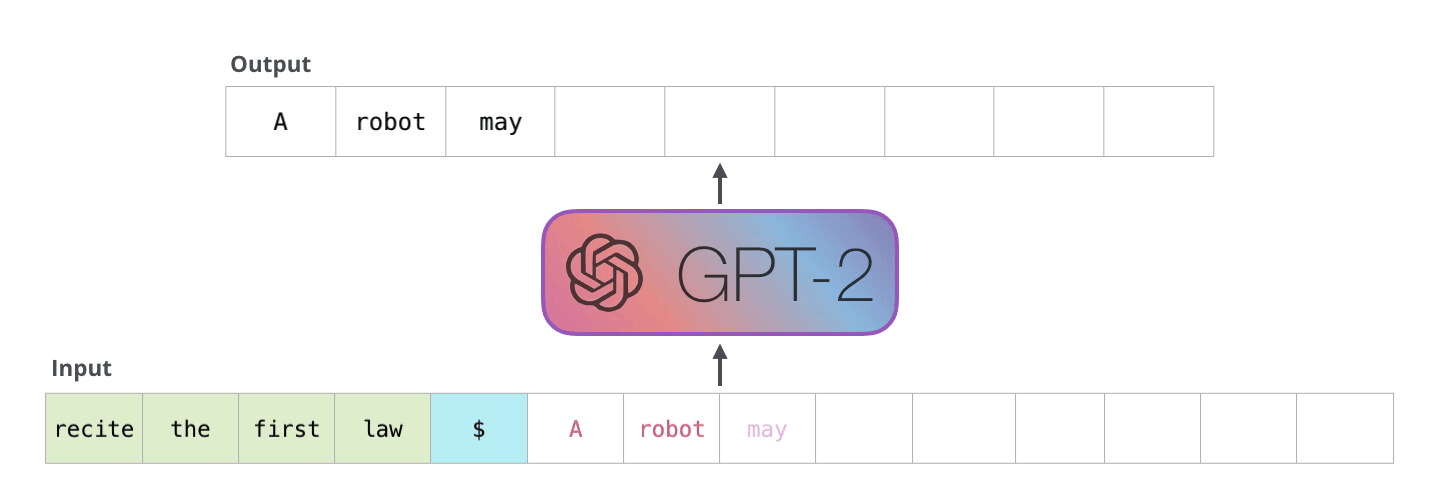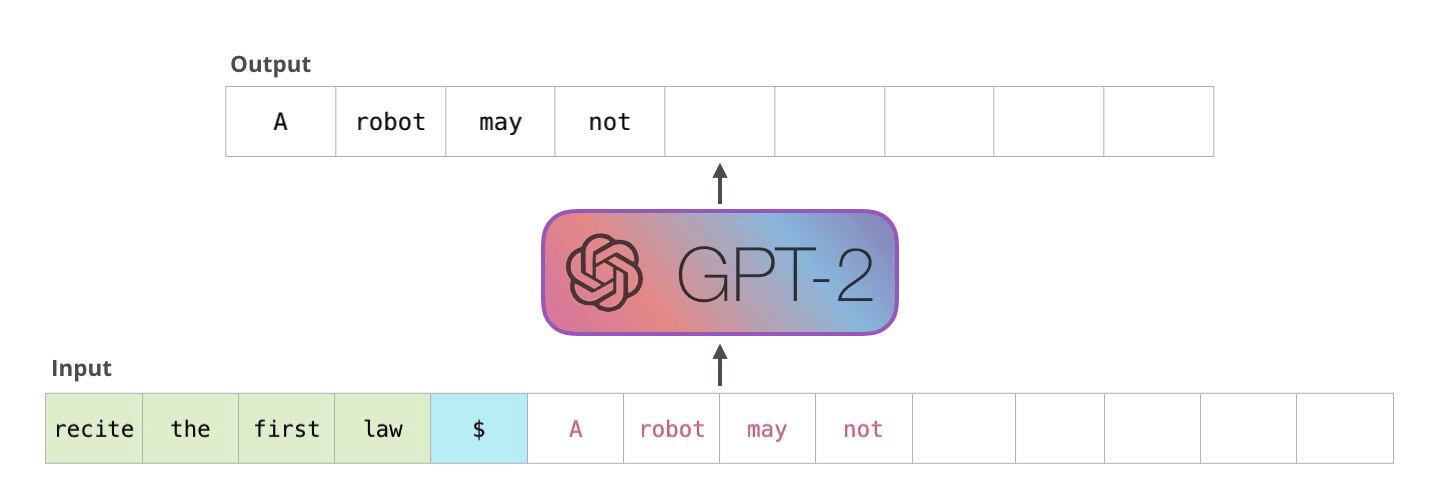
GPT는 생성 모델 중 하나로, 트랜스포머, 언어 모델을 기반으로 문장을 생성하는 모델입니다. 입력된 문장을 일정한 단위로 분할하고, 다음 단어를 생성하는 방식으로 동작합니다. 생성된 다음 단어와 입력된 단어를 반복하여 문장 생성을 진행하는데, 이를 '자기 회귀'라고 합니다. 현재 대부분의 언어 생성 모델이 이와 같은 방식으로 생성되고 있습니다. GPT 모델에는 추가 학습을 통해 사용자 태그와 함께 모델을 학습시켜, 챗봇을 만들수 있습니다.
RLHF, human feedback reinforcement learning
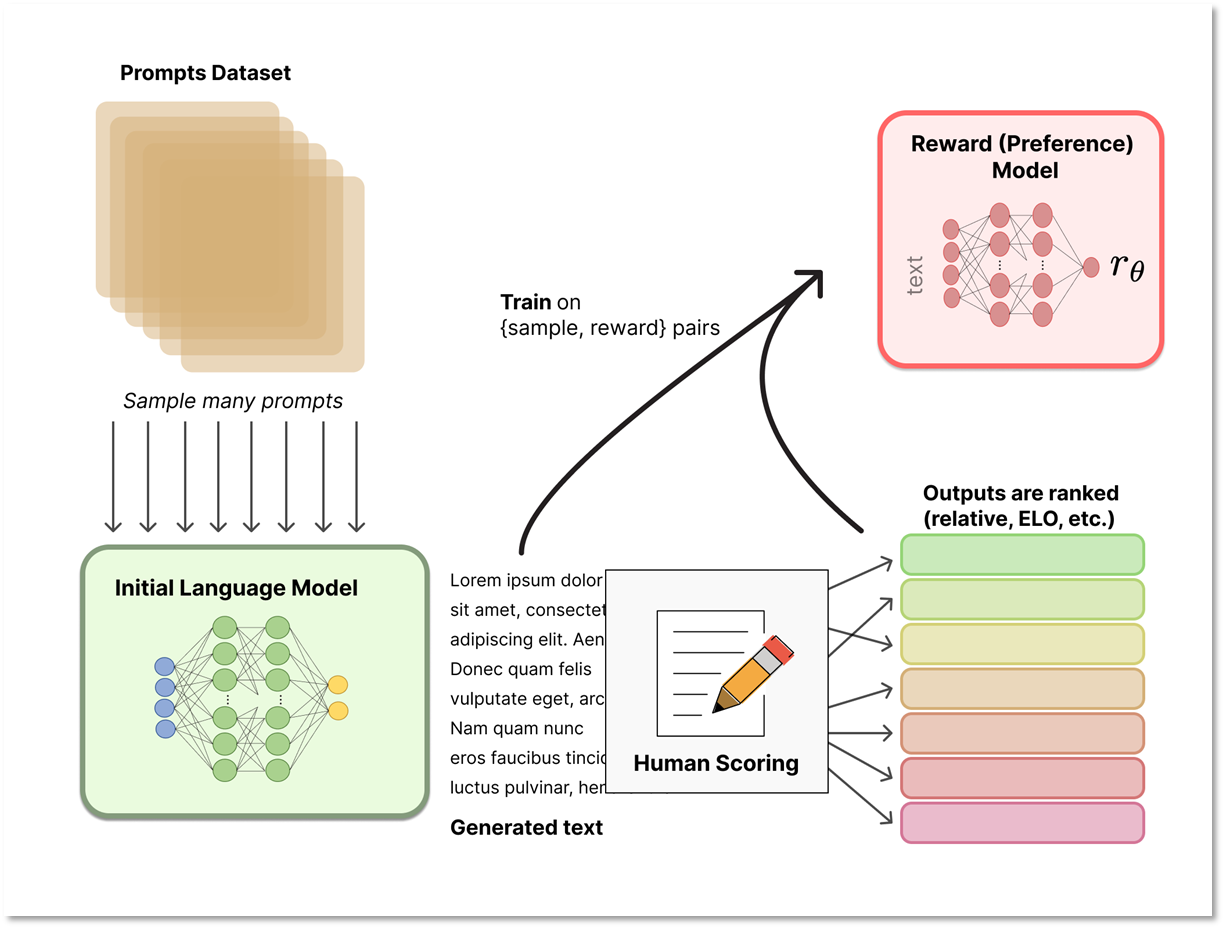
RLHF은 사람의 피드백을 활용하여 강화학습을 진행하는 방식으로, ChatGPT에서 사용되고 있습니다. 이 방법은 보상함수의 점수를 높이는 강화학습과 달리 모델이 생성한 여러 결과물을 순서대로 평가하여 사람이 선호하는 순서대로 순위를 매기는 방식으로 진행됩니다. 이후 모델의 결과물을 입력으로, 순위를 출력으로 하는 RM(Rank Model) 모델을 학습하고, 이를 GPT 모델의 강화학습에 사용하여 매번 사람이 피드백하는 것을 모델에게 넘겨 사람의 선호를 반영하는 강화학습을 진행합니다.
ChatGPT
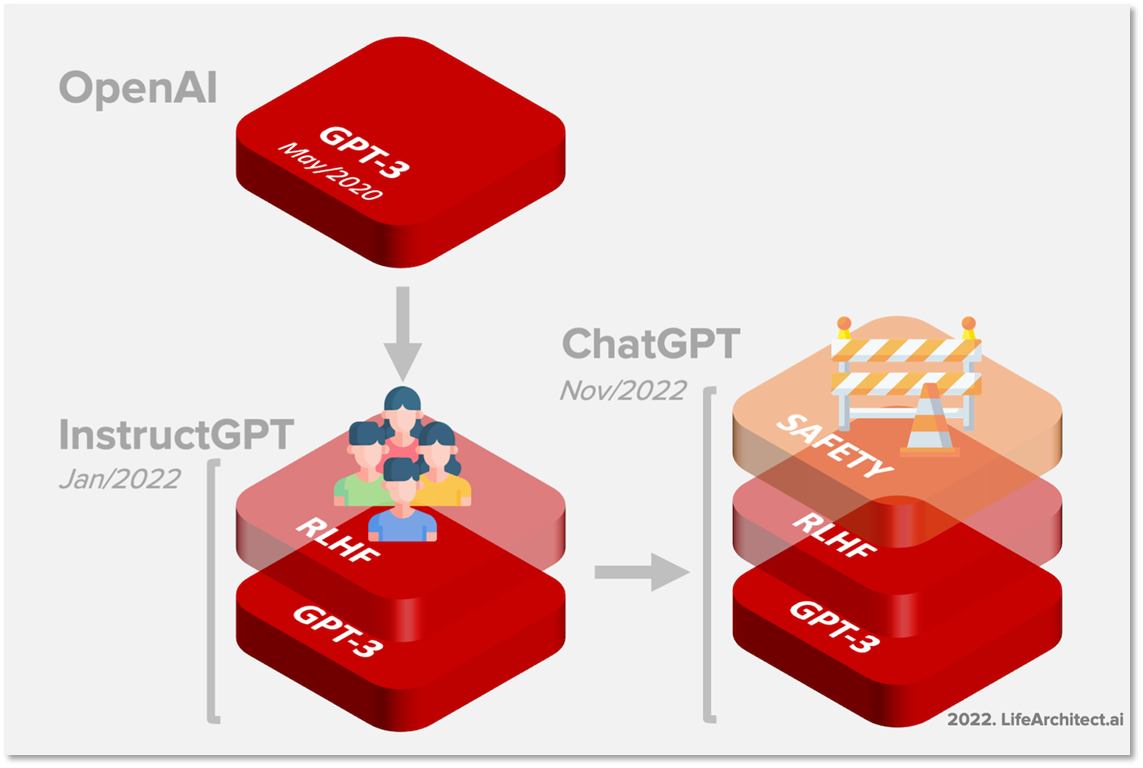
ChatGPT는 HFRL 강화학습을 통해 만들어진 모델로, 필터링을 거쳐 일반 사용자들에게 공개되었습니다. ChatGPT의 목적은 여러 데이터에서 학습한 입력 문장들에 대한 '자연스러운 문장'을 생성하는 것인데. 그렇기에 결과물에 대한 근거는 없습니다. 생성된 문장들은 모델의 내부 가중치에 대한 결과물일 뿐, 모델이 왜 그러한 가중치를 선택했는지 알 수 없는 블랙박스 모델의 한계 때문입니다. 이에 ChatGPT의 거짓말은 의도적인 거짓말과는 달리 모델이 최선을 다한 결과물일 뿐이므로. 따라서 정보 검색(IR)이나, MENN, turing machine, 다른 모델과의 결합을 통해 ChatGPT의 단점인 근거 부재를 보완하고 더 나은 성과를 달성할 수 있을 것 입니다.
첨삭
여기까지 읽으시느랴 고생하셨습니다. 쉬운부분만 추려낸다고 했는데 아무래도 어려운 내용들이라 조금 복잡해지더라구요. 지금까지의 글은 사실 제가 기본적으로 작성한 글에서 문체 정도를 다듬고 내용을 수정하는 첨삭을 chat gpt를 통해 시도 해보았습니다. 저의 글의 문체가 조금 어색하고 딱딱하게 작성하는 편인여서 걱정했는데 생각보다 괜찮은 결과물이 나온것 같네요. 사용해보니 앞서서 말했던 gpt 의 파인튜닝에서 사용하던 tag 대신 사용자의 의사를 파악하고 결과물을 낸다는 것으로 느껴졌습니다. 한편으로는 앞으로의 개발자라는 직업에 대한 걱정도 들지만. 앞으로의 모델의 발전이 기대되네요.

자료 출처, 참고 문헌
https://wikidocs.net/book/2155 내 자연어 처리의 스승
https://jalammar.github.io/ 시각화된 모델의 구조
https://openai.com/blog/chatgpt/
https://www.telusinternational.com/insights/ai-data/article/difference-between-cnn-and-rnn
