알고리즘
- 알고리즘을 구현하는 코드는 파이참에 작성해놓은 것을 보고 참고하면 된다
- 이해가 가지 않는 부분이 특별히 있지는 않았고 정해진 알고리즘을 구현하는 방법을 배우는 부분이기 때문에 강의에서 설명해주는 코드를 똑같이 따라했다
- 강의에서 설명이 부족한 부분은 유튜브를 참고하여 학습하면 이해가 더 쉽게 되었다
- 그래서 스터디 노트를 따로 작성하지 않고 파이참에 실행한 코드를 참고하면 될 것 같다
EDA/웹 크롤링/파이썬 프로그래밍
01. Analysis seoul CCTV
목표
- 서울시 구별 CCTV의 개수를 그래프로 나타내고 경향선을 나타내 인구대비 많은 구와 적은 구 등을 알아볼 수 있다
- pandas, numpy, matplotlib 등을 이용하여 데이터를 불러오고 가공하고 시각화할 수 있다
1. 데이터 읽기
Pandas 기초
Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
단일 프로세스에서는 최대 효율
코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
누군가 스테로이드를 맞은 엑셀로 표현함
- encoding : 한글이 깨지거나 하는걸 방지
CTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV 복사본.csv", encoding="utf-8")- head() : 상단의 5개의 데이터를 불러와준다
CCTV_Seoul.head()
- tail() : 하단의 5개의 데이터를 불러와준다
CCTV_Seoul.tail()- rename() : 데이터의 이름을 바꿔준다
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
# 마지막에 inplace=True를 넣어줘야 원본 데이터가 변경된다
- header : 위에서 몇번째 인덱스부터 가져올건지
- usecols : 사용할 열
series
- series : index와 value로 이루어져 있다. 한 가지 데이터 타입만 가질 수 있다
import pandas as pd
import numpy as np
pd.Series([1,2,3,4])
[실행결과]
0 1
1 2
2 3
3 4
dtype: int64- pandas에서 object는 string이다
- 날짜데이터
dates = pd.date_range("20200101",periods=6)
dates
[실행결과]
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06'],
dtype='datetime64[ns]', freq='D')DataFrame
- pd.Seris()
- index, value - pd.DataFrame()
- index, value, column
df = pd.DataFrame( value, index, columns)- df.describe() : 각종 통계량을 요약해서 출력
데이터 정렬
- df.sort_values(by="B") : B를 기준으로 오름차순 정렬
- df.sort_values(by="B",ascending=False) : B를 기준으로 내림차순 정렬
슬라이싱
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼 이름으로 슬라이싱 하는 경우에는 끝을 포함한다
location
- loc : 인덱스 이름으로 특정 행, 열을 선택한다
df.loc["20200102":"20200104",["A","D"]]- iloc : 컴퓨터가 인식하는 인덱스 값으로 선택
df.iloc[3:5,0:2]isin
- isin() : 특정 요소가 있는지 확인
- True, False로 반환
df["E"].isin(["two","five"])특정 컬럼 제거
- del
del df["E"]- drop
(axis=0 가로, axis=1 세로)
df.drop(["20200104"],axis=0) 4. 두 데이터 합치기
Pandas에서 데이터 프레임을 병합하는 방법
- 딕셔너리 안의 리스트 형태 : 열 단위로 데이터 저장
left = pd.DataFrame({
"key":["K0","K4","K2","K3"],
"A":["A0","A1","A2","A3"],
"B":["B0","B1","B2","B3"]
})
left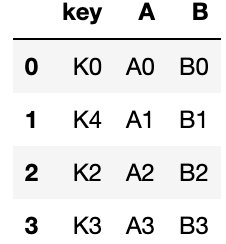
- 리스트 안의 딕셔너리 형태 : 행 단위로 데이터 저장
right = pd.DataFrame([
{"key":"K0","C":"C0","D":"D0"},
{"key":"K1","C":"C1","D":"D1"},
{"key":"K2","C":"C2","D":"D2"},
{"key":"K3","C":"C3","D":"D3"}
])
right
- pd.merge() :
-두 데이터 프레임에서 컬럼이난 인덱스를 기준으로 잡고 병합하는 방법
-기준이 되는 컬럼이나 인덱스를 키값이라고 한다
-기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 한다 - on은 양쪽 데이터프레임 중에서 key를 키값으로 잡고 병합하겠다는 뜻
- how="inner" : 교집합
how="outer" : 합집합
pd.merge(left, right, how="inner", on="key") - key를 기준으로 데이터를 합치는데 left에 있는 데이터를 기준으로 합치라는 뜻
pd.merge(left, right, how="left", on="key")인덱스 변경
- set_index() : 선택한 컬럼을 데이터 프레임의 인덱스로 지정
상관계수
- corr() : correlation의 약자이다. 상관계수 0.2 이상부터 유의미한 값을 갖는다
matplotlib 기초
matplotlib 그래프 기본 형태
plt.figure(figsize=(10,6))
plt.plot(x,y)
plt.show
import matplotlib.pyplot as plt # pyplot의 시각화 기능을 사용함
from matplotlib import rc
rc("font", family="Arial Unicode MS") # 한글 설정
# %matplotlib inline 이거 혹은 아랫줄 둘중 하나로 쓰면 됨
get_ipython().run_line_magic("matplotlib","inline")
plt.figure(figsize=(10,6)) # 도화지 사이즈
plt.plot([0,1,2,3,4,5,6,7,8,9],[1,1,2,3,4,2,3,5,-1,3]) # x,y축 데이터
plt.show()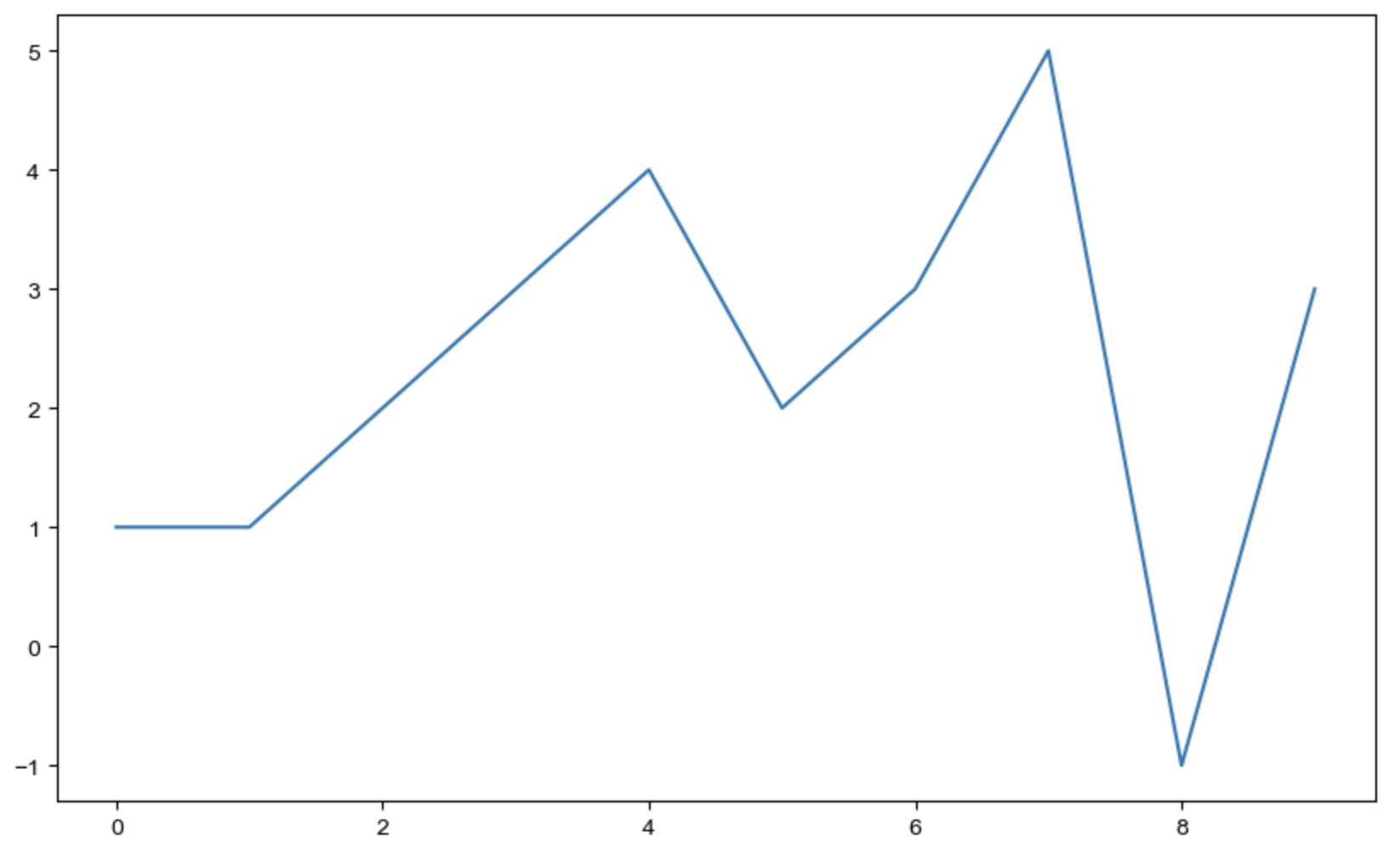
5. 데이터 시각화
- matplotlib.pyplot 모듈을 불러오고 필요한 설정을 해준다
import matplotlib.pyplot as plt
plt.rcParams["axes.unicode_minus"] = False # 마이너스 부호 때문에 한글이 깨질 수가 있어 주는 설정
rc("font", family="Arial Unicode MS")
%matplotlib inline- 지금까지 가공한 데이터를 이용해서 인구대비 CCTV가 많은 구를 나타낸다
def drawGraph():
data_result["CCTV비율"].sort_values().plot(
kind="barh",grid=True,title="인구 대비 CCTV가 가장 많은 구",figsize=(10,10));
drawGraph()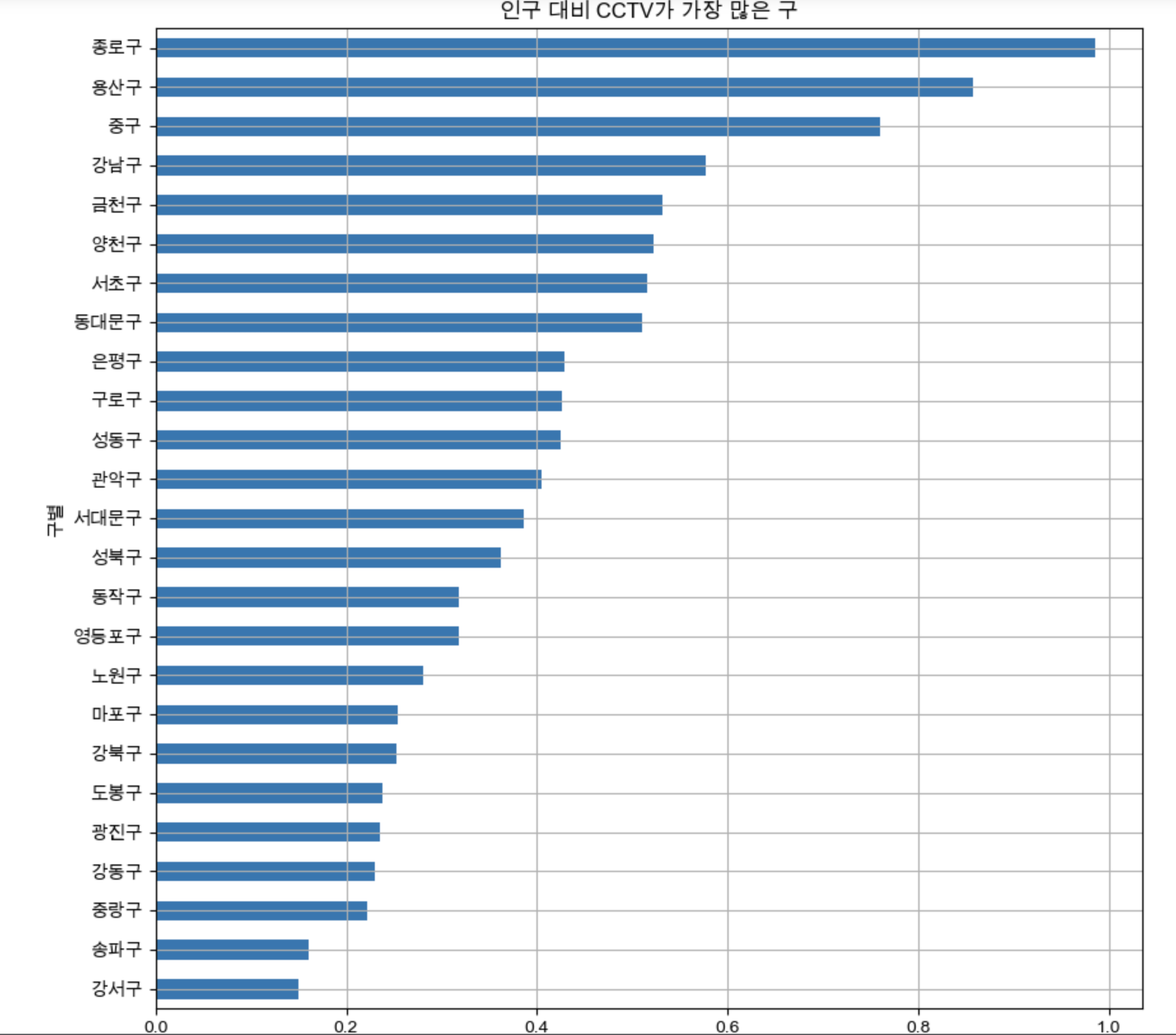
6. 데이터의 경향 표시
Numpy를 이용한 1차 직선 만들기
-
np.polyfit(): 직선을 구성하기 위한 계수를 계산
-
np.poly1d(): polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
-
np.linspace(a,b,n): a부터 b까지 n개의 등간격 데이터 생성
-
위의 함수를 이용하여 경향선을 생성해주고 인구수와 소계(CCTV개수)를 이용하여 scatter plot을 만든 후 하나의 그래프로 나타내준다
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"],s=50)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") # lw는 굵기
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()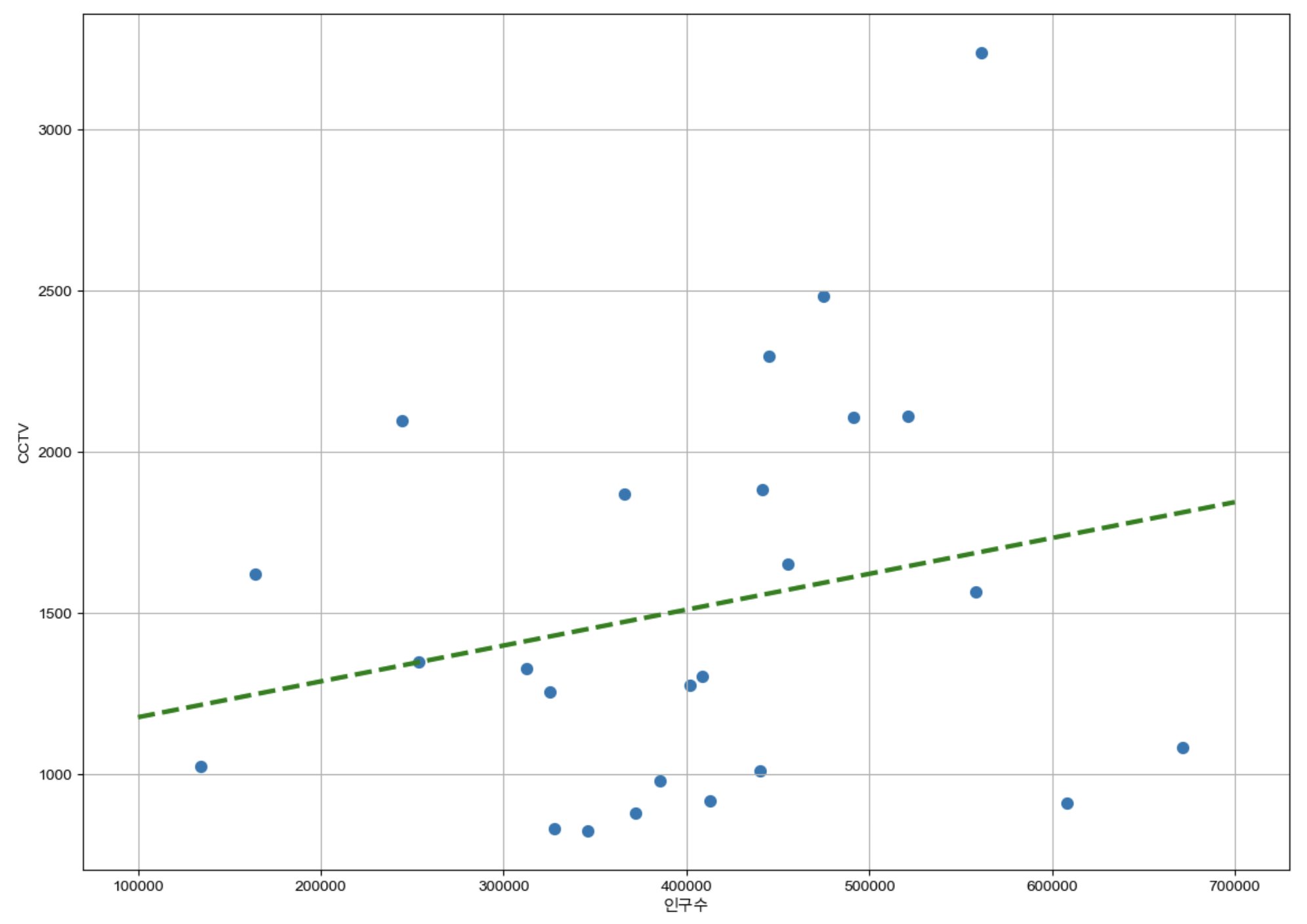
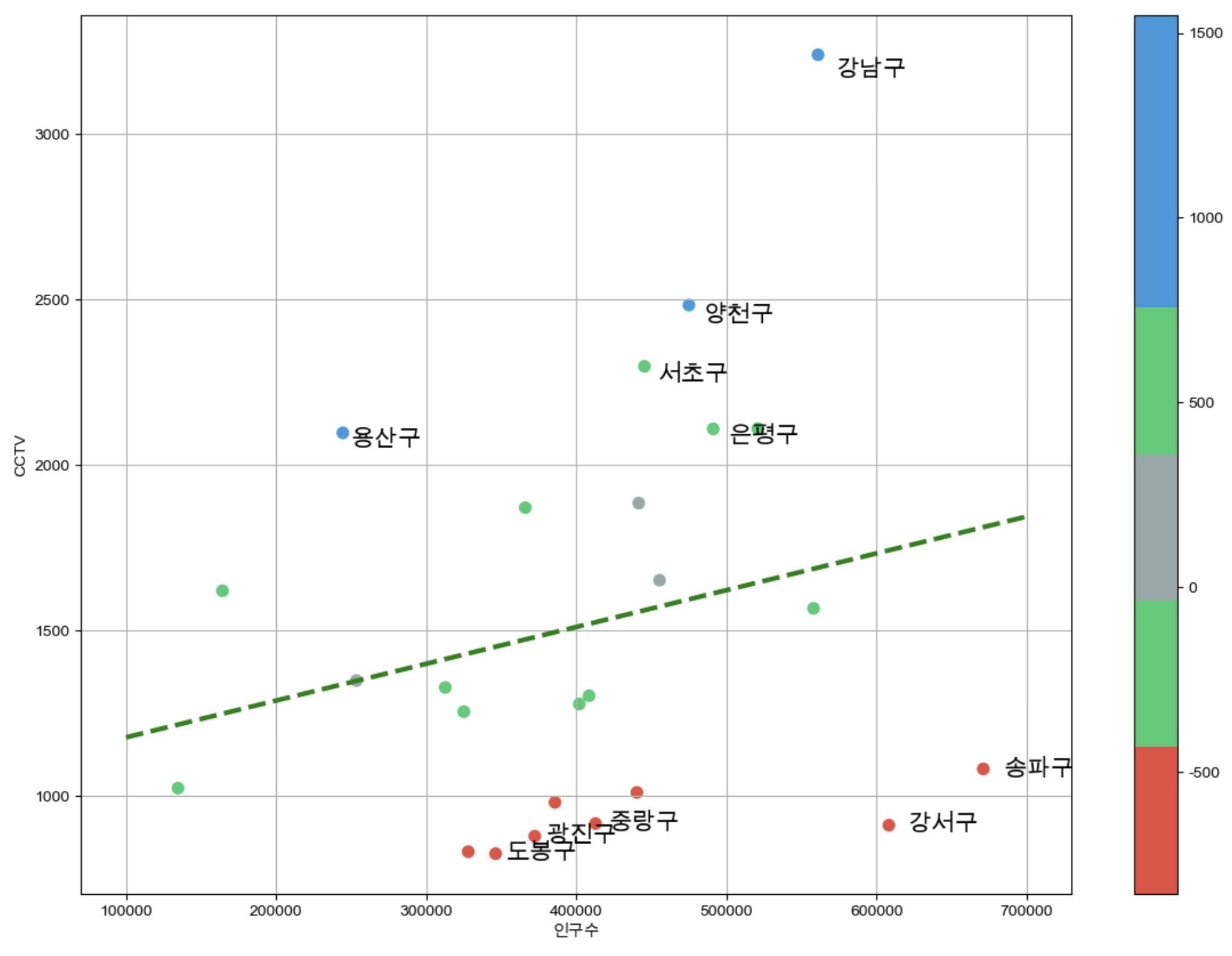
7. 강조하고 싶은 데이터 시각화
- 경향선 함수(f1)에 x값(인구수)를 넣으면 경향선에 대한 CCTV개수가 나온다. 따라서 경향선과의 오차는
'오차 = 구별CCTV개수 - f1(인구수)'이다
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])- 오차를 기준으로
colormap을 이용하여 보기쉽게 나타내주고 차이가 많이나는 상위 5개, 하위 5개는 그래프에 이름을 따로 찍어준다
from matplotlib.colors import ListedColormap
# colormap을 사용자 정의(user define)로 세팅
color_step = ["#e74c3e","#2ecc71","#95a9a6","#2ecc71","#3498db","#3498db"]
my_cmap = ListedColormap(color_step)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"],s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
# 상위 5개
plt.text(
df_sort_f["인구수"][n] * 1.02, # x좌표(데이터의 이름을 찍어줌 / 마크에서 조금 떨어진 곳에 표시하기 위해 숫자를 곱해줌)
df_sort_f["소계"][n] * 0.98, # y좌표
df_sort_f.index[n], # title
fontsize=15
)
# 하위 5개
plt.text(
df_sort_t["인구수"][n] * 1.02,
df_sort_t["소계"][n] * 0.98,
df_sort_t.index[n],
fontsize=15
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()