EDA/웹 크롤링/파이썬 프로그래밍
02. Analysis seoul Crime
목표
- 강남구가 범죄로부터 안전한지 분석할 수 있다
- GoogleMaps, Folium, Seaborn Pandas의 Pivot_table을 사용할 수 있다
01. 데이터 개요
- 데이터 읽기
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul 복사본.csv",thousands=",",encoding="euc-kr")
crime_raw_data.head()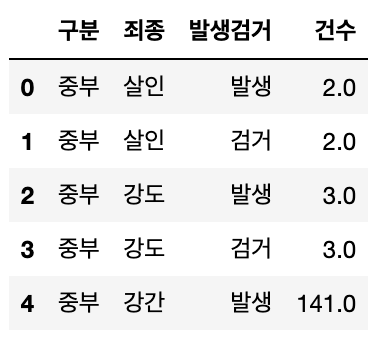
- unique로 컬럼을 확인해보니 '죄종'에 non데이터가 있는것을 확인하였다
- notnull() : null값이 아닌데이터만 반환한다
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
crime_raw_data.info()
02. 서울시 범죄 현황 데이터 정리
- pivot_table
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종","발생검거"],
aggfunc=[np.sum])
crime_station.head()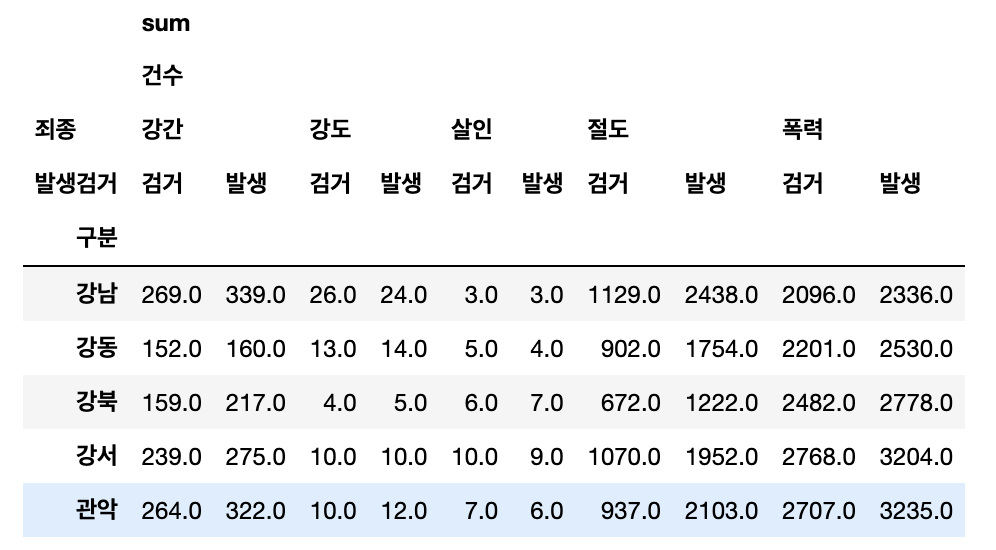
- 총 column이 4개이다. 상단의 2개 column을 날려야 한다
crime_station = crime_station.columns.droplevel([0,1]) # 다중 컬럼에서 특정 컬럼 제거
crime_station.head()
03. Python 모듈 설치
pip 명령
- python의 공식 모듈 관리자
- pip list # 지금 ds_study안에 어떤게 설치되어있는지 볼 수 있는 명령어
- pip install module_name
- pip uninstll module_name
- mac(M1)은 pip가 더 잘됨
conda 명령
- conda list
- conda install module_name
- conda uninstall module_name
- conda install -c channel_name module_name
- Windows, mac(intel)은 정상적으로 대부분 됨
04. Google Maps API 설치 및 데이터 정리
window, mac(intel)
- conda install -c conda-forge googlemaps
mac(m1)
- pip install googlemaps
'서울영등포경찰서'에 한해서 위도, 경도, 주소 알아오기
gmaps_key = "개인 API키"
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode("서울영등포경찰서",language="ko") # 필요한건 formatted_address와 좌표
tmp[0].get("geometry")["location"]["lat"]
tmp[0].get("geometry")["location"]["lng"]
tmp[0].get("formatted_address").split()[2] # 주소에서 구의 정보만 필요해서 split()한 후 2번째 값을 가져옴
[실행결과]
37.5260441
126.9008091
'영등포구'전체 데이터 적용
- '구별', 'lat', 'lng'컬럼을 만들고 non값으로 채워줌
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan- non 데이터에 values 채우기
count = 0
for idx,rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, "lat"] = lat # loc은 인덱스를 받아서 값을 반환해주는데 그 중 lat의 값을 반환해주고 그거를 우항의 lat으로 채워준다는 뜻
crime_station.loc[idx, "lng"] = lng
crime_station.loc[idx, "구별"] = tmp_gu.split()[2]
print(count)
count = count + 1 # 잘 실행되고 있는지 확인하려고 넣어줌
crime_station.head() 
- 0번째, 1번째 컬럼 합치기
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp
[실행결과]
['강간검거',
'강간발생',
'강도검거',
'강도발생',
'살인검거',
'살인발생',
'절도검거',
'절도발생',
'폭력검거',
'폭력발생',
'구별',
'lat',
'lng']crime_station.columns = tmp
crime_station.head()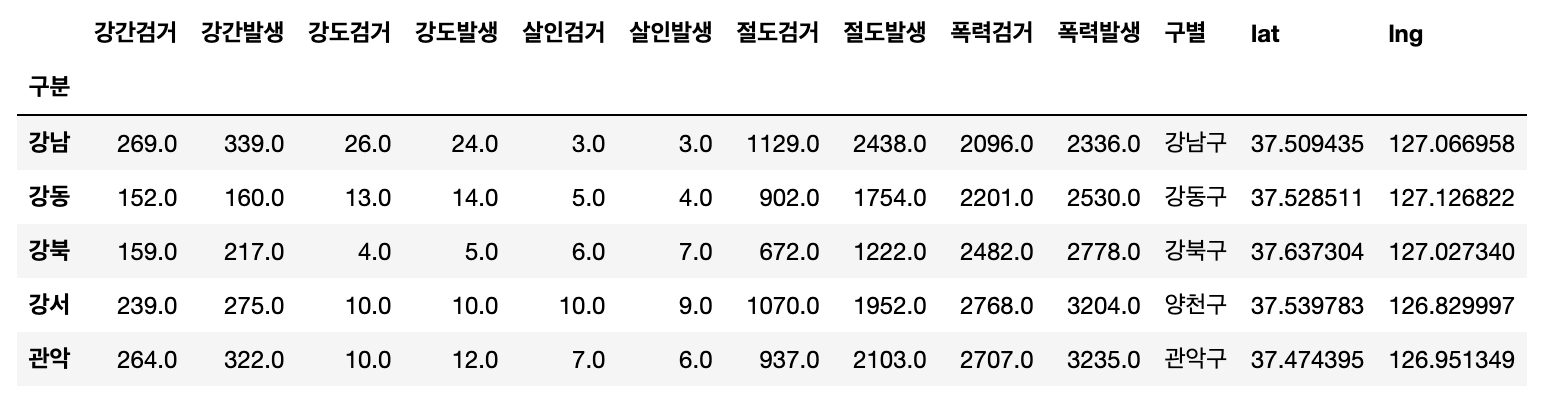
- 데이터 저장
pd.read_csv("../data/02. crime_in_Seoul_raw.csv")05. 구별 데이터로 정리
- 저장한 데이터 불러오기
crime_anal_station = pd.read_csv("../data/02. crime_in_Seoul_raw.csv",index_col=0,encoding="utf-8") # index_col은 "구분"을 인덱스로 설정- 구별 범죄발생, 범죄검거 데이터 pivot_table로 만들기
crime_anal_gu = pd.pivot_table(crime_anal_station,index="구별",aggfunc=np.sum)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis=1, inplace=True) # drop()은 소괄호임. 대괄호 쓰면 invaild syntax- 검거율 생성
num = ["강간검거","강도검거","살인검거","절도검거","폭력검거"]
den = ["강간발생","강도발생","살인발생","절도발생","폭력발생"]
crime_anal_gu[num].div(crime_anal_gu[den].values).head()- 생성한 데이터 기존 데이터에 추가
target = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
num = ["강간검거","강도검거","살인검거","절도검거","폭력검거"]
den = ["강간발생","강도발생","살인발생","절도발생","폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()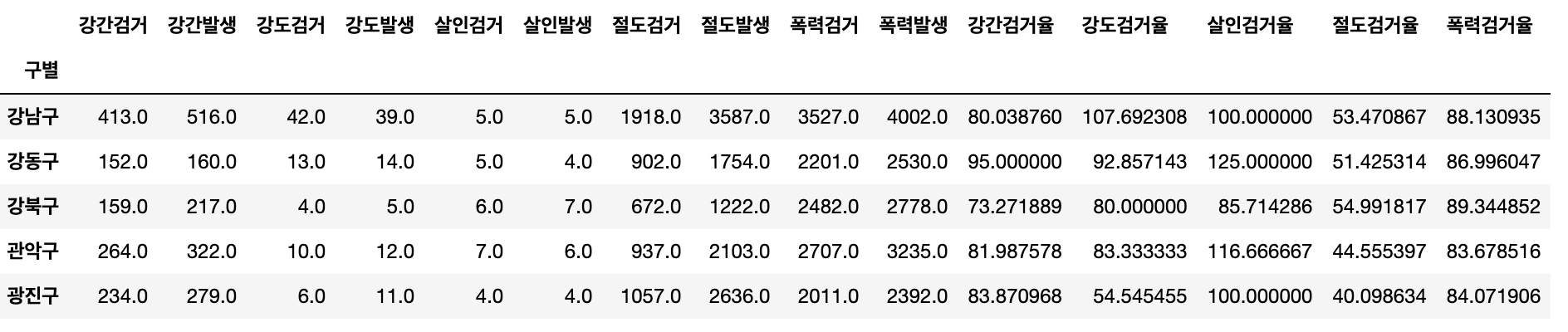
- 필요없는 column 제거(del과 drop 둘 다 써보았다)
- 100보다 큰 숫자 찾아서 100으로 바꿔줌
- column이름 변경
# 필요 없는 컬럼 제거
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
crime_anal_gu.drop(["살인검거","절도검거","폭력검거"],axis=1,inplace=True)
# 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
# 컬럼 이름 변경
crime_anal_gu.rename(columns={"강간발생":"강간","강도발생":"강도","살인발생":"살인","절도발생":"절도","폭력발생":"폭력"},inplace=True)
crime_anal_gu.head()
06. 범죄 데이터 정렬을 위한 데이터 정리
- 정규화 : 최고값은 1, 최소값은 0
# 정규화
col = ["살인", "강도", "절도","강간","폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
# norm 테이블에 검거율 추가
col2 = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]- CCTV분석에서 사용한 구별 CCTV 개수와 인구수 추가
# 데이터 가져오기
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv",index_col="구별",encoding="utf-8")
# column으로 데이터 추가
crime_anal_norm[["인구수","CCTV"]] = result_CCTV[["인구수","소계"]]
# 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ["살인", "강도", "절도","강간","폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col],axis=1) # numpy : axis=1 row, axis=0 column, pandas : axis=0 row, axis=1 column
# 검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용
col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col],axis=1) # axis=1은 행을 따라서 연산하는 옵션
crime_anal_norm.head()
Seaborn
- 필요한 환경 설정
# seaborn 설치
!conda install -y seaborn
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False
rc("font",family="Arial Unicode MS")
%matplotlib inline
!pip install statsmodels07. 서울시 범죄현황 데이터 시각화
- 검거율 heatmap
# '검거'컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율","검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거",ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, # 데이터 표현
fmt="f", # d:정수 f:실수
linewidths=0.5, # 박스들 사이의 간격
cmap="RdPu"
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬)")
plt.show()
drawGraph()
- 데이터 저장
crime_anal_norm.to_csv("../data/02. crime_in_Seoul_final.csv",sep=",",encoding="utf-8")folium
- 필요한 환경 설정
!pip install folium
import folium
import pandas as pd
import jsontiles option
- "OpenStreetMap"
- "Mapbox Bright" (Limited levels of zoom for free tiles)
- "Mapbox Control Room" (Limited levels of zoom for free tiles)
- "Stamen" (Terrain, Toner, and Watercolor)
- "Cloudmade" (Must pass API key)
- "Mapbox" (Must pass API key)
- "CartoDB" (positron and dark_matter)
-
folium.Marker()
- 지도에 마커 생성
m = folium.Map(
location=[37.500908 ,127.036749],
zoom_start=12,
tiles="OpenStreetMap"
)
# 뚝섬역
folium.Marker((37.54712311308356, 127.047219169117774)).add_to(m)
# 역삼역 # popup
folium.Marker(
location=[37.500908 ,127.036749],
popup="<b>Subway</b>" # 누르면 뜨는 것(html가능)
).add_to(m)
# tooltip
folium.Marker(
location=[37.500908 ,127.036749],
popup="<b>Subway</b>", # 누르면 뜨는 것(html가능)
tooltip="<i>역삼역</i>" # 마우스를 갖다 대면 뜨는 것
).add_to(m)
# Zerobase # popup에 홈페이지 연결도 가능
folium.Marker(
location=[37.54558642069953,127.05729705810472],
popup="<a href='https://zero-base.co.kr/' target=_'blink'>제로베이스</a>",
tootlp="<i>Zerobse</i>"
).add_to(m)
m
-
folium.Icon()
- https://fontawesome.com/v5/search - https://getbootstrap.com/docs/3.3/components/
m = folium.Map(
location=[37.500908 ,127.036749],
zoom_start=12,
tiles="OpenStreetMap"
)
# icon basic
folium.Marker(
(37.54712311308356, 127.047219169117774),
icon=folium.Icon(color="black",icon="info-sign")
).add_to(m)
# icon icon_color
folium.Marker(
location=[37.500908 ,127.036749],
popup="<b>Subway</b>",
tooltip="icon color",
icon=folium.Icon(
color="red",
icon_color="blue",
icon="cloud"
)
).add_to(m)
# Icon custom
folium.Marker(
location=[37.5403903907497, 127.06913328776446], # 건대입구역
popup="건대입구역",
tooltip="icon custom",
icon=folium.Icon(
color="purple",
icon_color="white",
icon="heart", # font awesome에 가면 참고 사이트가 있다
angle=50, # 기울어지는 각도
prefix="fa" # prefix를 fa로 줘야 나타나는 아이콘이 있다
)
).add_to(m)
m
- folium.LatLngPopup()
m = folium.Map(
location=[37.500908 ,127.036749],
zoom_start=12,
tiles="OpenStreetMap"
)
m.add_child(folium.LatLngPopup())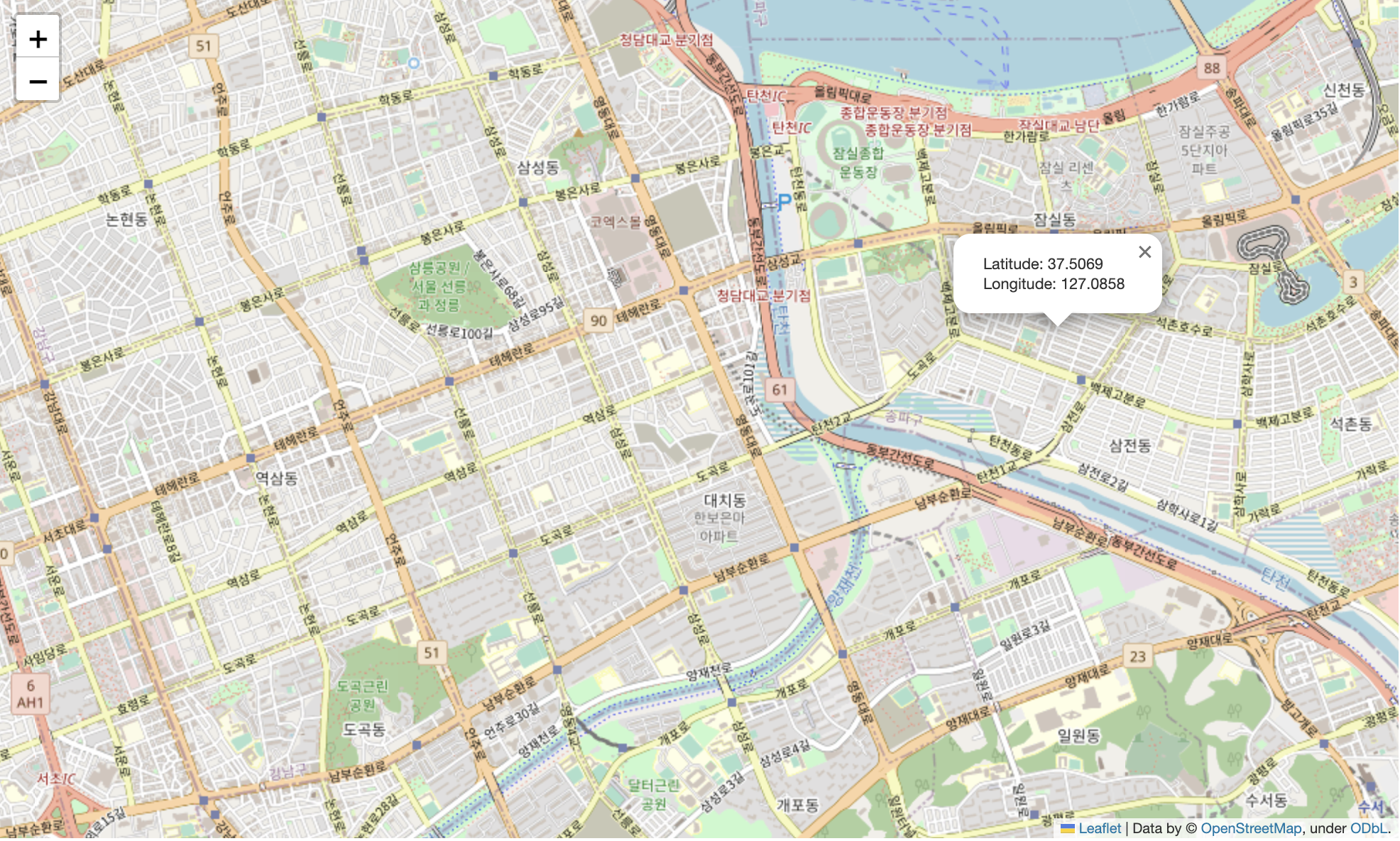
- folium.Circle(), folium.CircleMarker()
m = folium.Map(
location=[37.4974 ,127.0563],
zoom_start=14,
tiles="OpenStreetMap"
)
# Circle
folium.Circle(
location=[37.4985,127.0554], # 집
radius=100,
fill=True, # True하면 안에 옅은색으로 칠해짐
color="#eb8c34",
fill_color="red",
popup="Circle Popup",
tooltip="Circle Tooltip"
).add_to(m)
# CircleMarker # Circle이랑 원형크기 말고 다른건 다 같음
folium.CircleMarker(
location=[37.4963,127.0529], # 한티역
radius=30,
fill=True, # True하면 안에 옅은색으로 칠해짐
color="#c538e8",
fill_color="#c538e8",
popup="CircleMarker Popup",
tooltip="CircleMarker Tooltip"
).add_to(m)
m
-
folium.Choropleth
- 지도 위에 경계선을 그려주는 명령어
state_data = pd.read_csv("../data/02. US_Unemployment_Oct2012 복사본.csv")
m = folium.Map([43,-102],zoom_start=2)
folium.Choropleth(
geo_data="../data/02. us-states 복사본.json", # 경계선 좌표값이 담긴 데이터
data=state_data, # Series or DataFrame
columns=["State","Unemployment"], # DataFrame columns
key_on="feature.id",
fill_color="BuPu",
fill_opacity=0.8, # 0~1
line_opacity=1, # 0~!
legend_name="Unemployment rate (%)"
).add_to(m)
m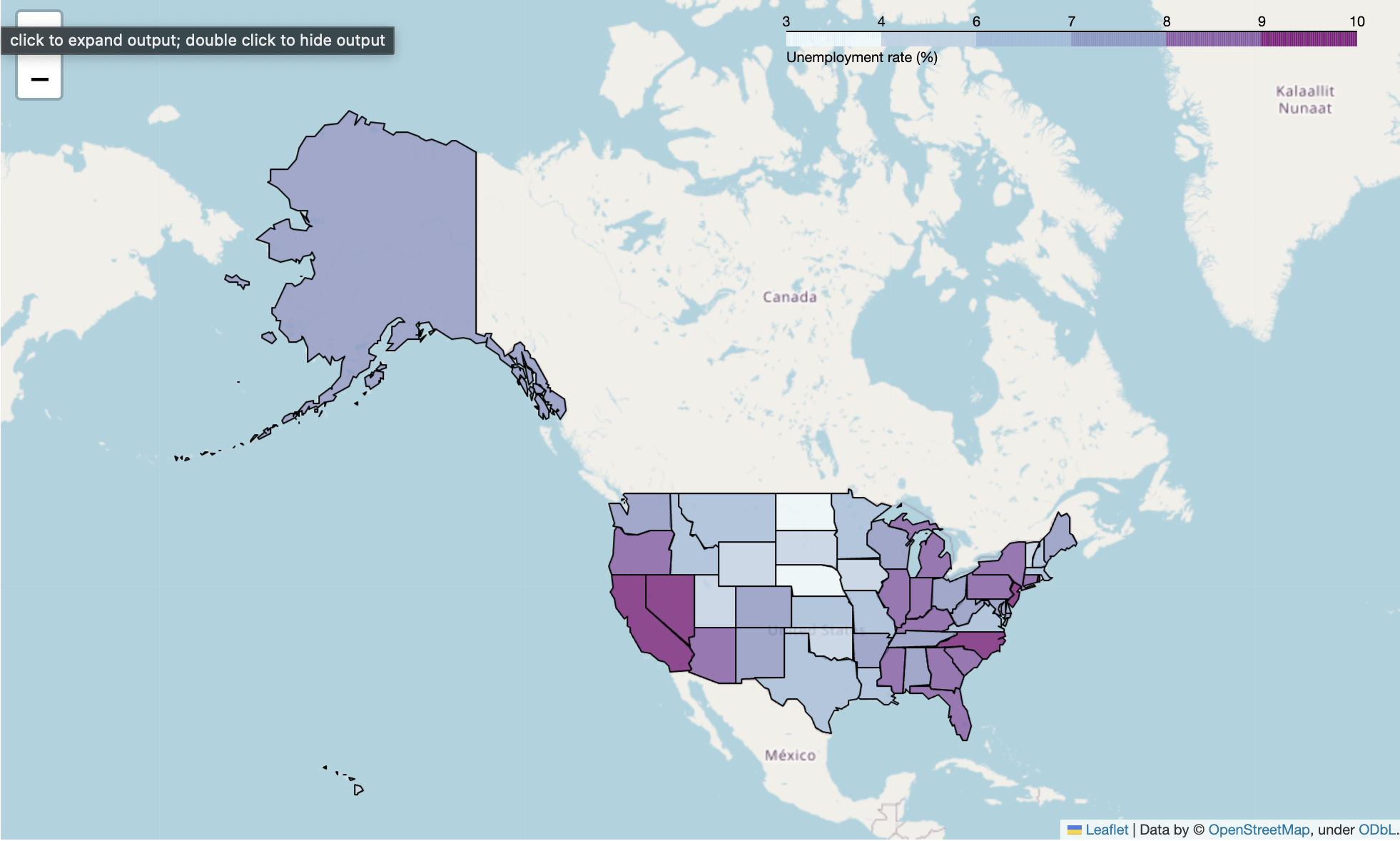
08. 서울시 범죄 현황에 대한 지도 시각화
- 5대범죄 발생 건수 시각화
# 데이터 가져오기
crime_anal_norm = pd.read_csv("../data/02. crime_in_Seoul_final 복사본.csv", index_col=0, encoding="utf-8") # 복사본 쓰는 이유는 강의와 값이 같기 위해서
geo_path = "../data/02. skorea_municipalities_geo_simple 복사본.json"
geo_str = json.load(open(geo_path,encoding="utf-8"))
# 5대 범죄 발생 건수 지도 시각화
my_map = folium.Map(
location=[37.5502,126.982],
zoom_start=11,
tiles="Stamen Toner"
)
# 경계 그리기
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 5대 범죄 발생건수"
).add_to(my_map)
my_map
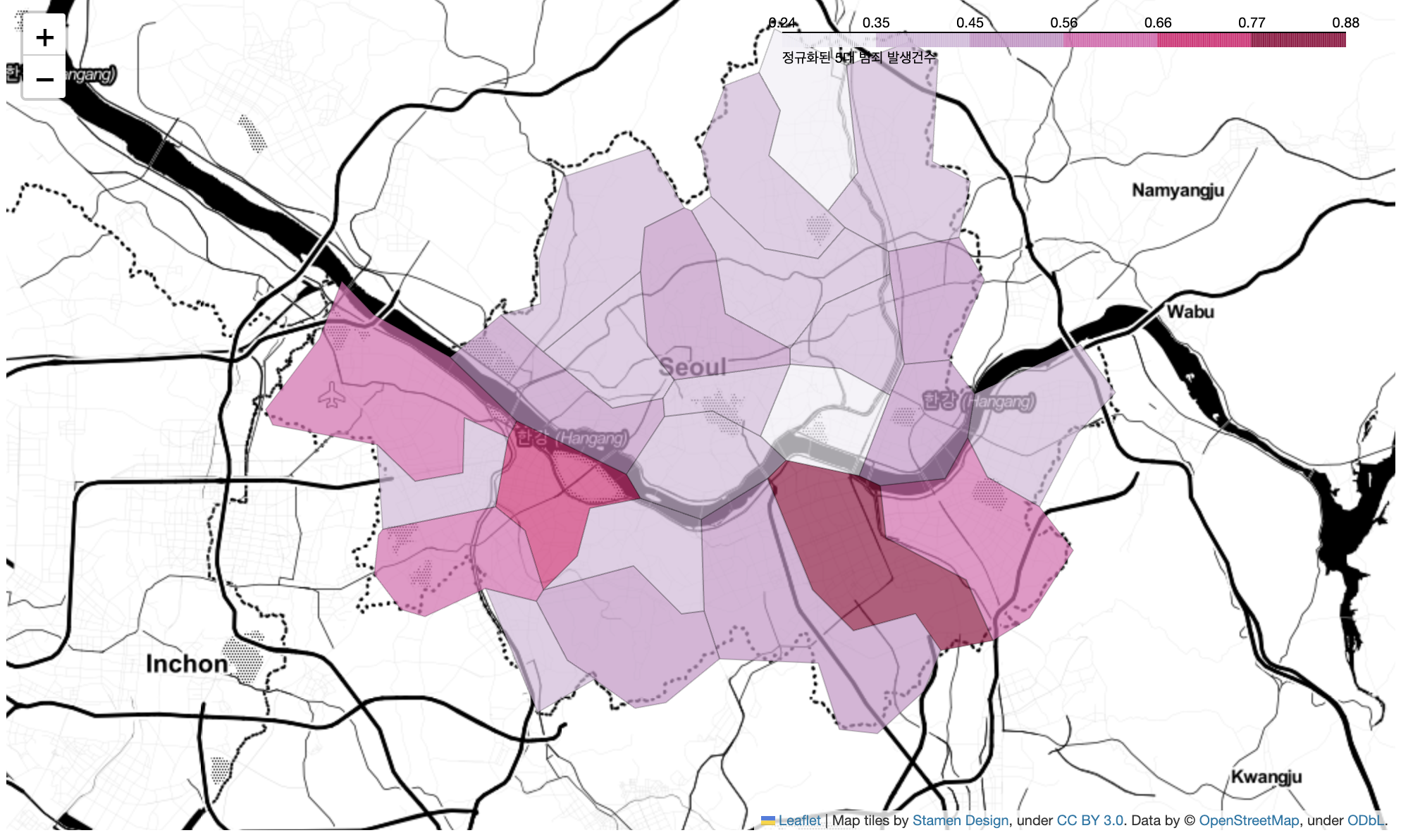
- 인구대비 범죄 건수 시각화
# 인구 대비 범죄 건수 지도 시각화
tmp_criminal = crime_anal_norm["범죄"] / crime_anal_norm["인구수"]
my_map = folium.Map(
location=[37.5502,126.982],
zoom_start=11,
tiles="Stamen Toner"
)
# 경계 그리기
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=tmp_criminal,
columns=[crime_anal_norm.index, tmp_criminal],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 인구 대비 범죄 발생건수"
).add_to(my_map)
my_map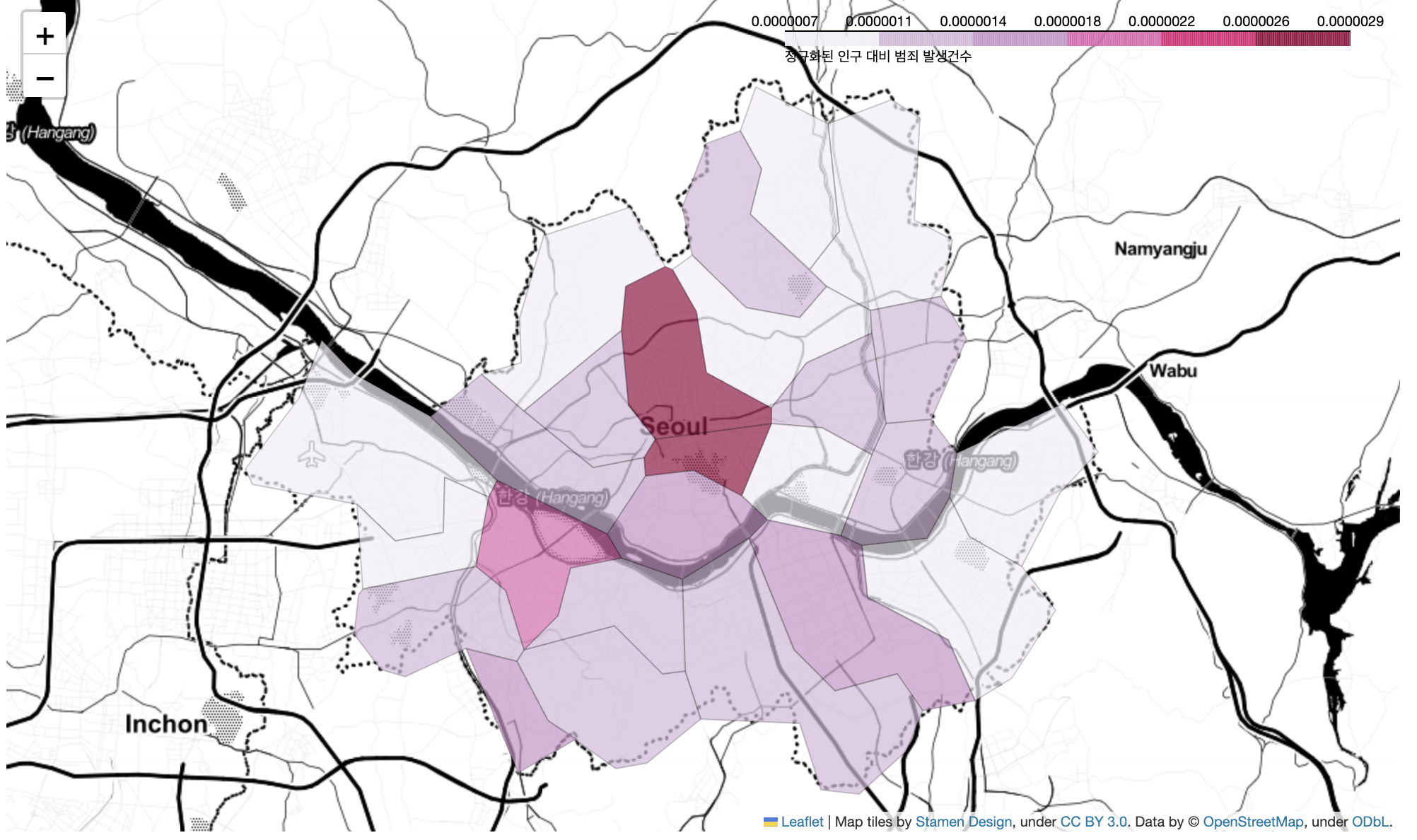
- 경찰서별 정보를 범죄발생과 함께 정리
# 데이터 가져오기
crime_anal_station = pd.read_csv("../data/02. crime_in_Seoul_raw 복사본.csv", encoding="utf-8")
# 정규화 및 검거 column 추가
col = ["살인검거","강도검거","강간검거","절도검거","폭력검거"]
tmp = crime_anal_station[col] / crime_anal_station[col].max() # 정규화 0~1
crime_anal_station["검거"] = np.mean(tmp, axis=1) # numpy axis=1 행(가로), pandas axis=1 열(세로)
# 경찰서 위치 마커 표시
my_map = folium.Map(
location=[37.5502,126.982], zoom_start=11
)
for idx, rows in crime_anal_station.iterrows():
folium.Marker(
location=[rows["lat"],rows["lng"]],
).add_to(my_map)
my_map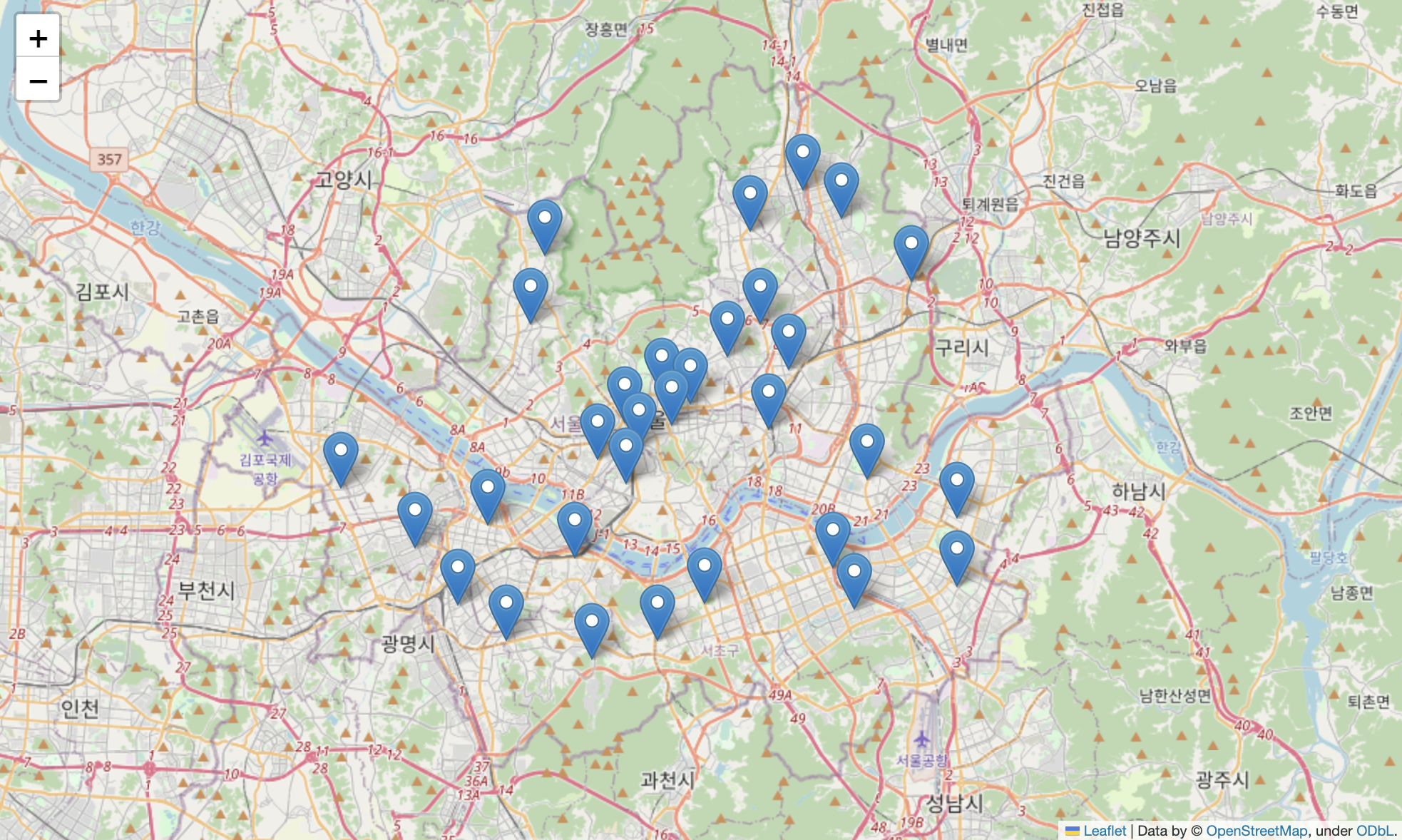
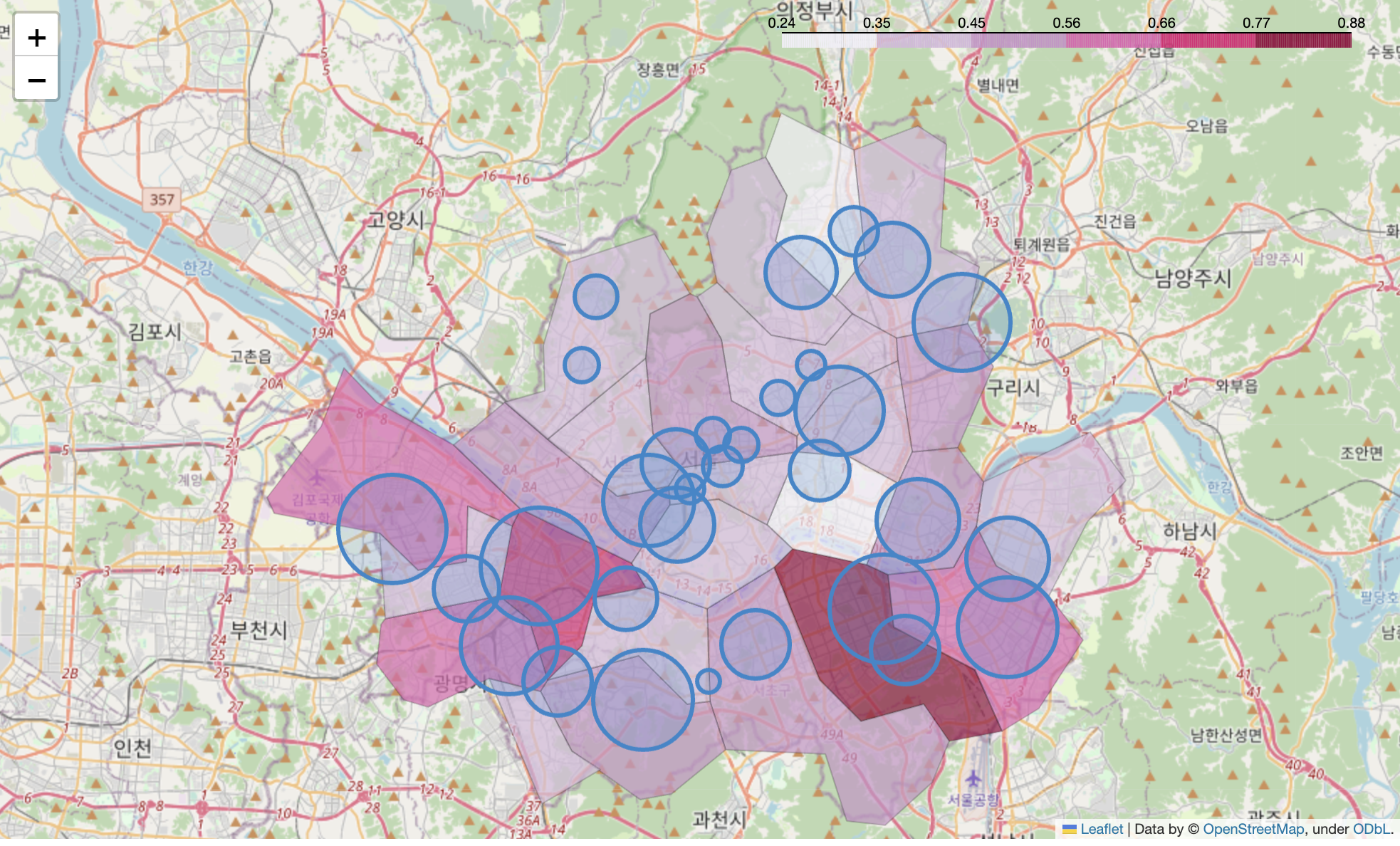
- 경찰서별 검거율 시각화
# 검거에 값을 곱한 뒤 원의 넓이 적용
my_map = folium.Map(
location=[37.5502,126.982], zoom_start=11
)
# 경계선
folium.Choropleth(
geo_data=geo_str,
data=crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2
).add_to(my_map)
# 경찰서별 검거율
for idx, rows in crime_anal_station.iterrows():
folium.CircleMarker(
location=[rows["lat"],rows["lng"]],
radius=rows["검거"] * 50,
popup=rows["구분"] + " : =" + "%.2f" % rows["검거"],
color="#3186cc",
fill=True,
fill_color="#3186cc"
).add_to(my_map)
my_map