
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 신용카드 연체 문제를 다루어보았습니다. 한 회사가 공격적인 마케팅을 통해 많은 고객을 끌어모아 신규 카드 가입 발급률이 올랐습니다. 하지만, 가입 발급률이 높아진만큼 카드 대금 연체를 하는 고객들도 많아졌습니다. 연체율이 높아질수록 카드 대금 회수 지연으로 인해 자금의 유동성 문제가 발생하고 있습니다. 때문에 그 회사는 연체 가능성이 높은 고객을 예측하고 사전 관리 (관리 프로그램 및 마케팅)를 통해 카드 연체율을 낮춰보고자 하는 것이 이번 미니 프로젝트의 시나리오였습니다.
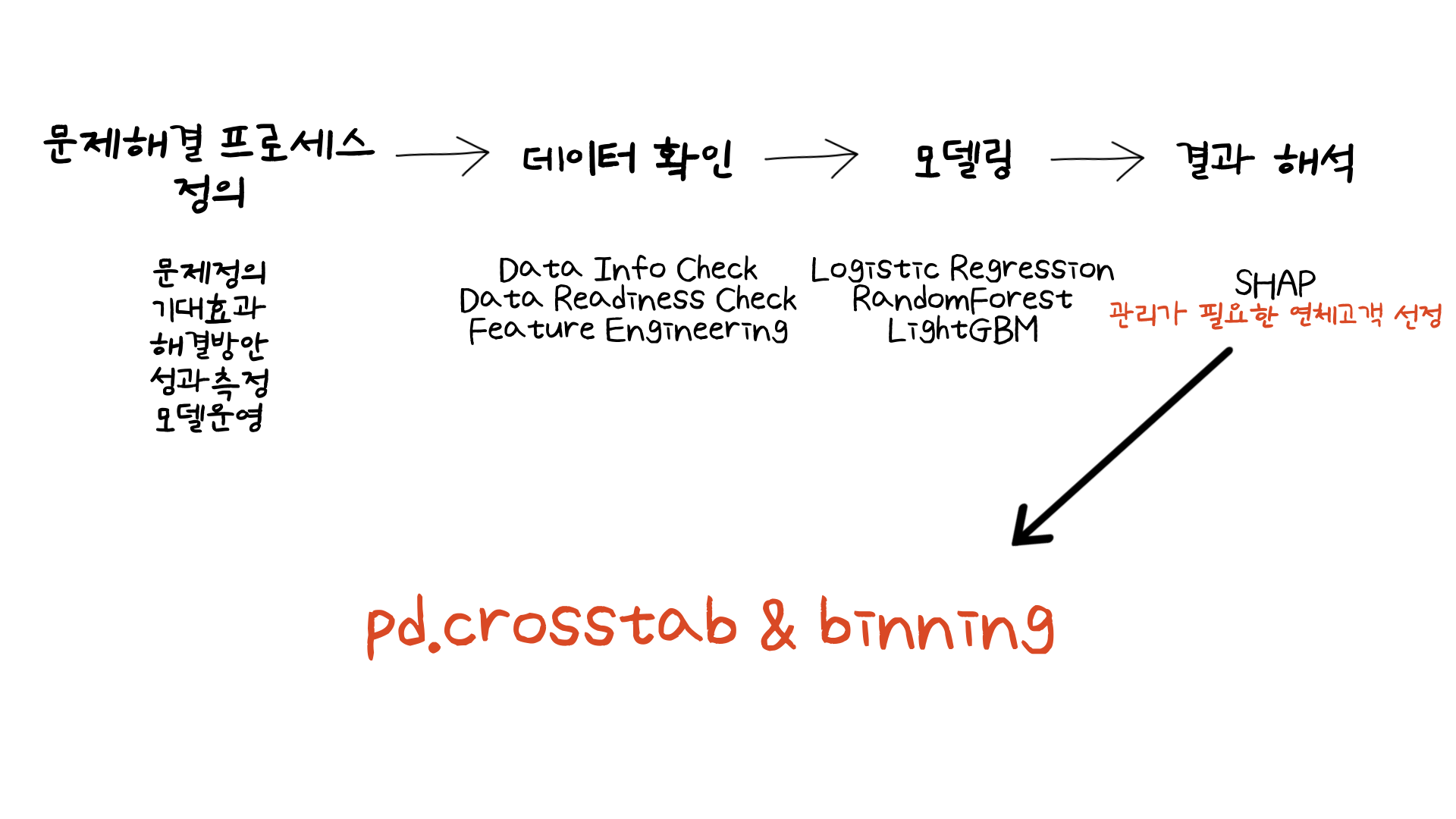
이번 글에서 중점적으로 다루어볼 부분은 모델링이 끝난 후 사전 관리가 필요한 고객들을 선정하는 과정입니다. pandas의 crosstab 함수를 통해 어떤 고객을 선정하는지 알아보겠습니다.
02. 관리가 필요한 고객군 선정

3가지 계열이 다른 모델을 사용한 결과 LightGBM을 선택했습니다. 다음으로 0과 1의 예측확률을 알려주는 .predict_proba() 함수를 통해 예측값이 아닌 1의 예측확률 값들을 가져왔습니다. 이후 pandas의 cut 함수를 이용하여 임의로 정한 [0.0, 0.3, 0.6, 1.0] 값을 사용하여 [0.0, 0.3), [0.3, 0.6), [0.6, 1.0)의 예측확률 값의 구간을 만들어주었습니다. 다음으로 pandas의 crosstab 함수를 이용하여 나누어진 구간에 따라 (1,0으로 이루어진) y_test 값의 개수를 나타냈습니다. crosstab 결괏값은 위 이미지의 맨 하단에 있습니다.
다음으로는 구간마다 1 값의 비율을 알아내기 위해 'ratio' 컬럼을 만들어, 1 개수의 값을 구간마다의 값 전체값으로 나누어주었습니다. 그렇게 하면 구간마다의 1의 비율값이 나오는데, 이를 y_test 값의 1의 비율 (여기서는 0.64)로 나누어주었습니다. 그 결괏값은 'Lift' 컬럼에 나와있습니다. 만약 Lift값이 1을 넘는다면 해당 구간의 1의 값의 비율이 y_test의 1의 비율을 넘는다는 의미입니다. [0.6, 1.0) 구간의 Lift 값을 보면 1이 넘는데 이는 해당 구간의 1의 값의 비율이 0.64를 넘기 때문입니다. 즉, 해당 구간은 연체확률이 전체 64%보다 높은 것입니다.
그래서 사전관리가 필요한 고객군은 [0.6, 1.0) 구간 안에 있는 고객들일 것입니다. 혹은 bins = []의 구간을 더 세분화하여 쪼개거나 값은 변경하거나, 혹은 'Lift' 컬럼의 임계값을 전체 확률 0.64가 아닌 다른 값으로 정하여 사전관리 고객군을 선정하는 방법도 있을 것입니다.
03. 정리
이번 시간에는 예측결과 확률을 이용하여 타켓팅할 고객군을 찾는 방법을 다루어보았습니다. 아직 많이 익숙한 부분은 아니기에 이해를 하는데 시간이 조금 걸렸습니다 (bins과 pd.crosstab을 결합하는 부분을 이해하는데 시간이 좀 걸렸네요). 하지만 유용한 개념인 만큼 나중에 사용할 수 있도록 몇번 더 코드를 복기하며 다른 데이터에도 적용해보고자 합니다. 이상입니다!
부족한 글 읽어주셔서 감사합니다:) 피드백은 언제나 환영입니다:)
