
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 integer로 이루어진 변수와 cateogorical 변수로 이루어진 데이터를 통해 구매 전환으로 이루어진 고객을 예측하는 모델을 만드는 시간을 가졌습니다. 해당 모델링의 결과로 단순히 구매 전환이 이루어진 고객을 예측하는 것을 넘어, SHAP 라이브러리를 활용하여 어떤 변수들이 모델의 결과에 중요한 역할을 하는지 또한 알아보았습니다. 여기에 더해 이전 28번째 미니 프로젝트 마지막 부분에서 predict_proba() 함수를 통해 예측확률을 구하여 어떤 타켓군이 마케팅 등의 고객관리가 필요한지 확인한 과정을 이번 미니 프로젝트에서도 동일하게 적용했습니다.
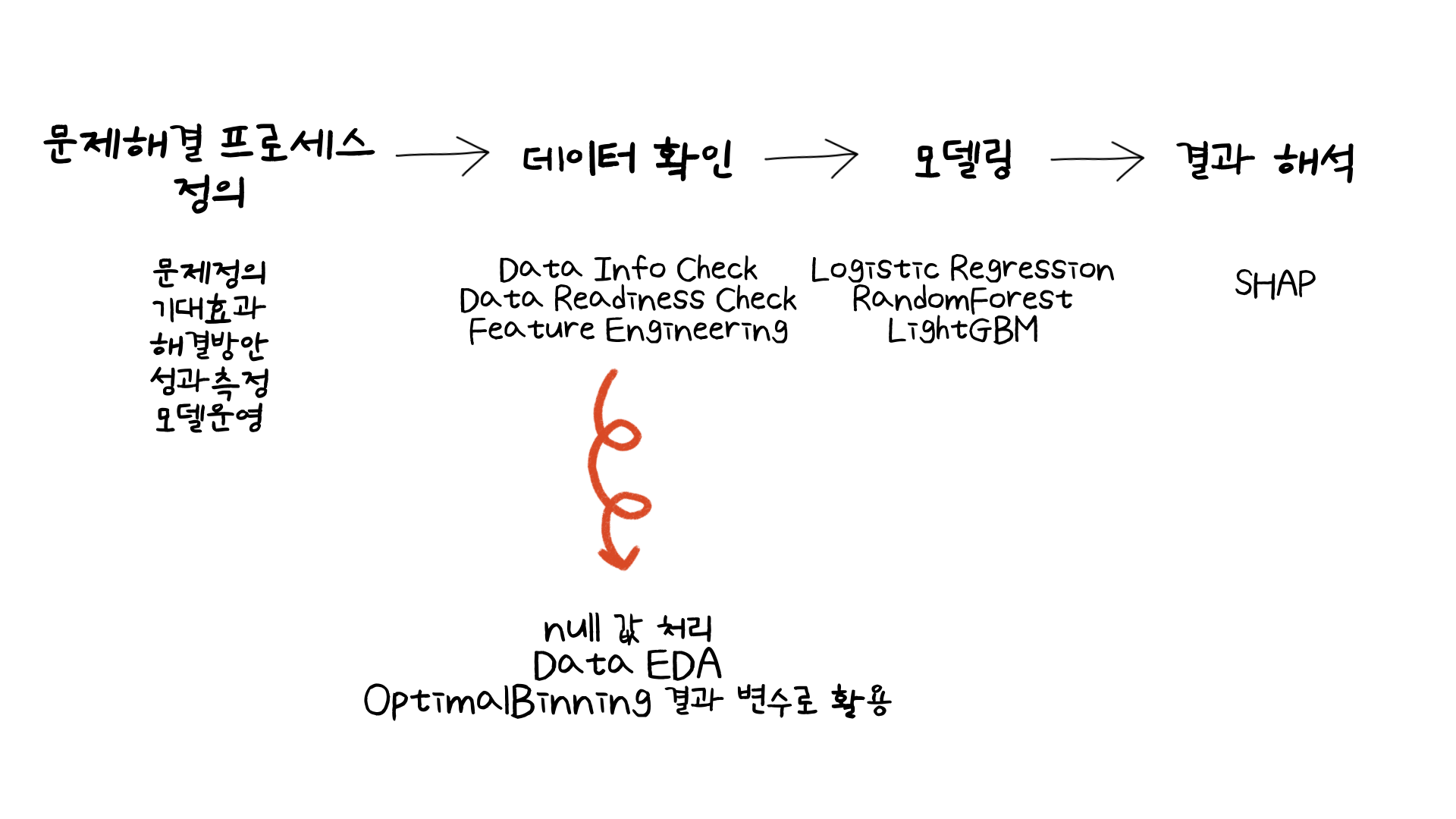
하지만 이번 글에서는 데이터 확인 단계에서 배웠던 부분을 다루어보고자 합니다. 컬럼당 null 값을 처리할 때 해당 컬럼의 평균값 등을 활용하여 채워넣는 경우도 있지만, 여기서는 제가 잘 알지 못했던 부분으로 채워넣는법을 배웠는데 그 부분에 대해 이야기해보겠습니다. 다음으로는 Data Readines Check 부분에서 Data EDA 과정에서 categorical 변수와 numerical 변수의 target ratio를 어떻게 확인했는지 다루어보겠습니다. 마지막으로는 categorical 변수의 unique한 값들을 OptimalBinning 패키지를 통해 묶어주는 변형 과정을 이야기해보겠습니다.
02. what have I learned?
첫번째로 다룰부분은 null 값 처리입니다. null 값의 경우 값을 어떻게 처리하는가에 따라 모델링의 결과가 달라질 수 있습니다. 그래서 여러가지 방법이 있는데, 저는 이전에는 결측치를 채울때 컬럼의 최빈도값 혹은 평균값 (혹은 중간값)으로 채울 수 있다고 배웠습니다. 그런데 이번엔 조금 다른 방식을 배웠습니다.
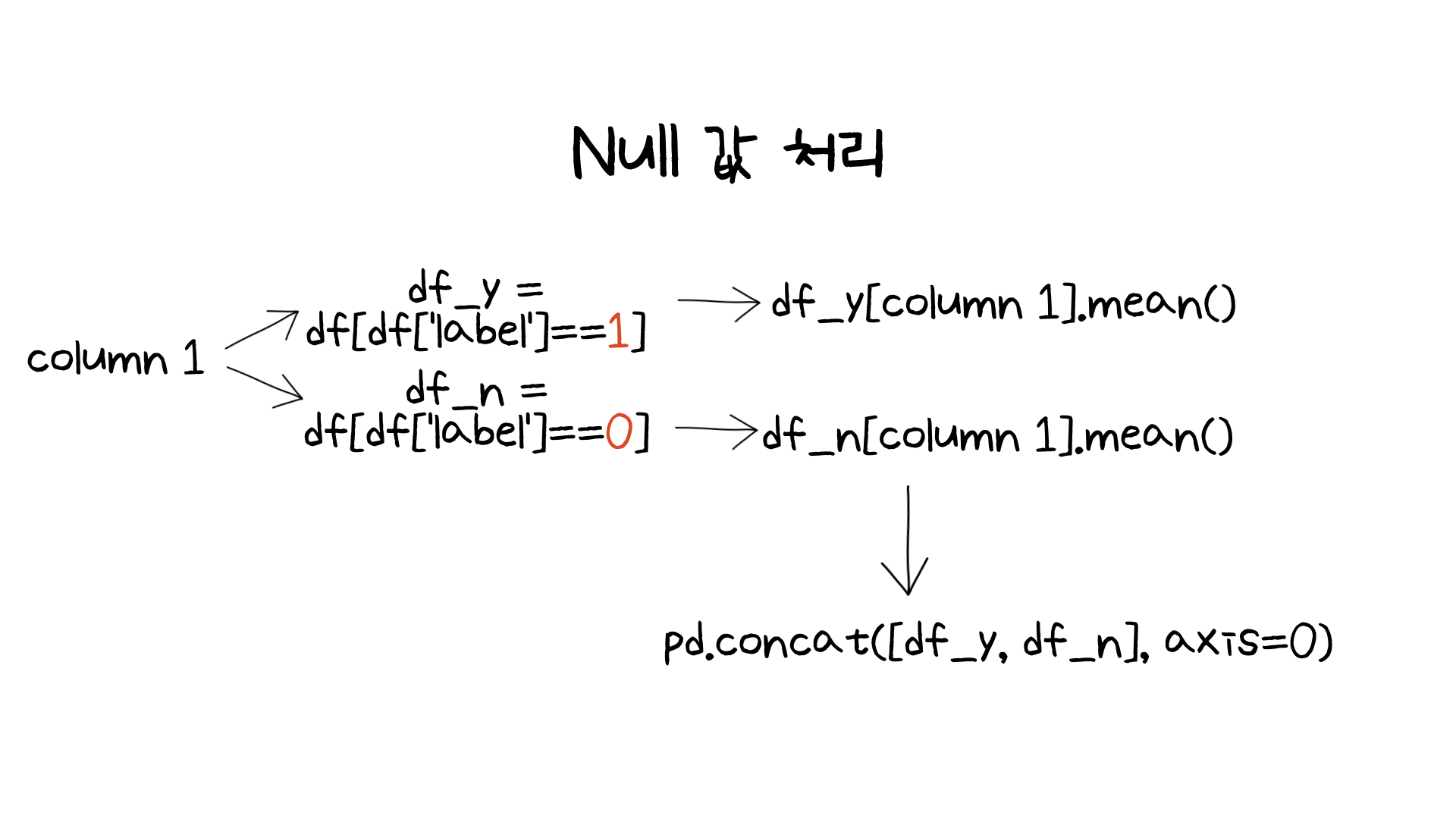
엄청 큰 차이는 없지만 조금 다른 점이라면 먼저 (binary classfication 문제이므로) target 값이 1인 데이터와 0인 데이터를 나눈 것입니다. 두 종류의 데이터로 나눈 이후 각각의 평균으로 결측치를 채운 후 다시 pandas의 concat 함수를 통해 두 데이터를 합쳐주는 방식입니다.
이렇게 한 이유는 만약 같은 클래스에 속하는 속성의 평균값을 사용하지 않고 전체 평균값으로 결측치를 채워준다면 왜곡 가능성이 있기 때문입니다. 때문에 동일유형에 속하는 데이터의 평균값으로 결측치를 채워줌으로서 왜고 가능성을 (없애는 것이 아닌) 줄이기 위해 해당 과정으로 결측치를 채워줄 수 있다는 것을 배웠습니다.
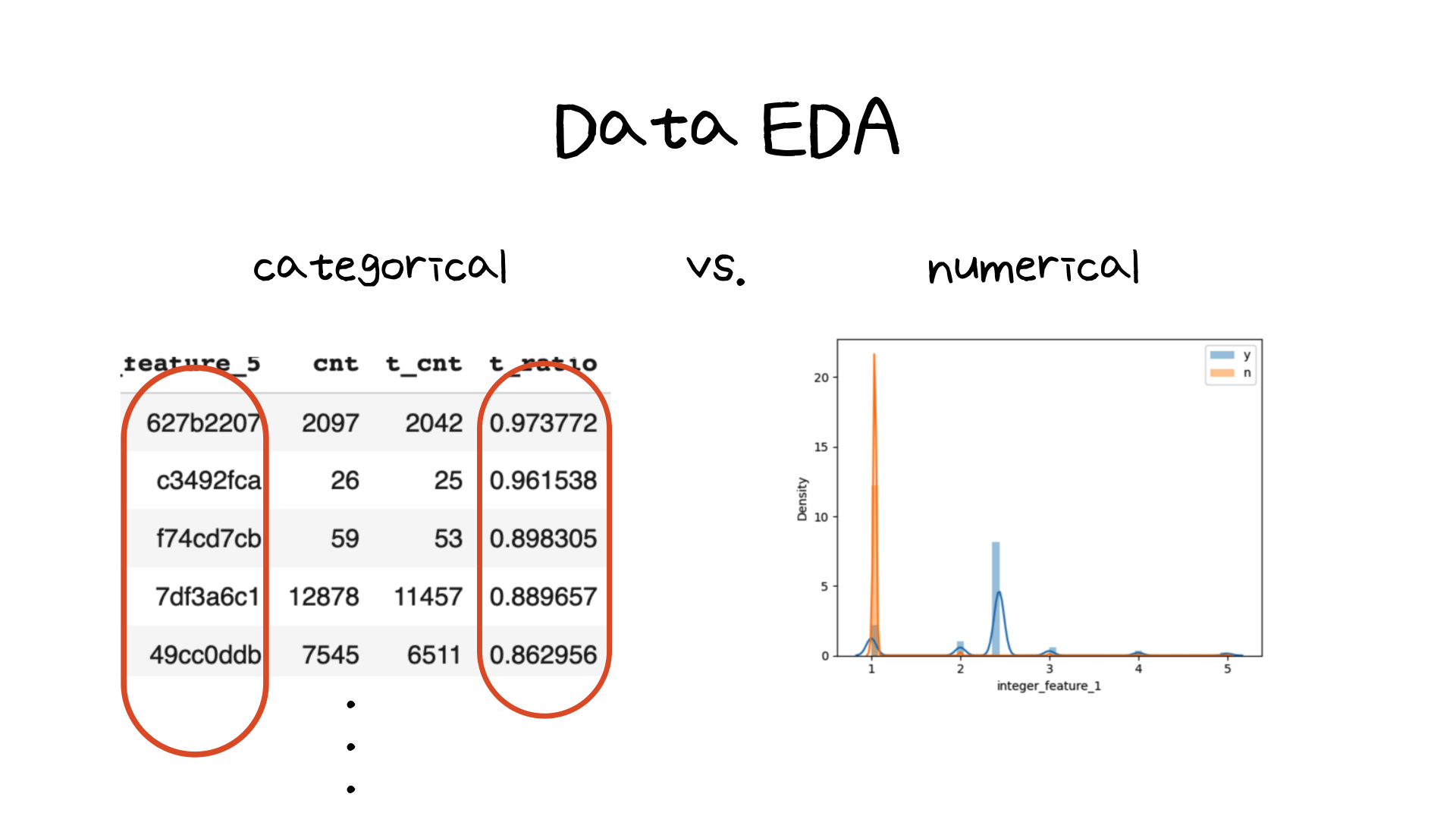
다음으로 배운 내용은 Data EDA 단계에서 categorical과 numerical 변수(컬럼)들의 target 분포를 확인하는 과정입니다. categorical 변수의 경우 unique한 값들이 있기 때문에, 1과 0의 target 값 분포를 계산을 통해 확인이 가능합니다. 하지만 numerical 변수들의 경우 연속형 변수이므로 두개의 target에 따라 이분법적으로 확인하기는 어렵습니다. 그래서 직접 그래프로 나타내어 분포를 확인할 수 있었습니다.
위 이미지에서 오른쪽에 해당하는 부분이 한 numerical 변수의 target 값 1과 0에 대한 분포입니다. 위 컬럼은 비록 그나마 깔끔하게 값의 분포가 서로 멀어져있는 것을 확인할 수 있습니다 (이를 통해 해당 변수는 모델링에 중요한 역할을 한다는 것을 어느정도 예상해볼 수 있었습니다). 하지만 다른 변수들의 경우 그 분포가 크게 차이가 나지 않았습니다.

마지막은 OptimalBinning을 이용한 feature 변형입니다. 이번 미니 프로젝트의 변수들은 명확히 명시된 변수들이 아닌 어느 정도 마스킹된 변수들이었습니다 (ex. categorical_feature_1, 2, etc). 그런데 unique한 값들이 너무 많다보니 (2000개가 넘는 것도 있었습니다) 차원의 수가 너무 컸습니다. 때문에 원핫인코딩 혹은 레이블 인코딩을 한다면 데이터가 sparse해져 모델의 결과가 떨어질 우려가 있었습니다.
그래서 IV 값을 찾기위해 사용한 OptimalBinning 라이브러리를 활용하여 임의로 unique한 값들을 묶어주었습니다. 그 결과 위의 이미지와 같이 20개 아래로 값들이 묶인 것을 확인할 수 있었습니다. 이 변수들을 토대로 모델링을 돌린 결과 다행히(?) 모델의 결과도 나쁘지 않게 나왔습니다.
03. 마무리하며
이번 글에서는 모델링 전 데이터를 다루는 과정에 집중했습니다. 모델의 연료인 데이터를 잘 정제하는 것은 중요하기에 이번에 배운 내용을 다시 복습하며 어떻게 적용할지 연습해보려고 합니다.
또한 이번 실습에서 활용한 데이터의 개수는 20만개가 넘었습니다. 때문에 모델링 및 bayesian optimization을 활용한 하이퍼 파라미터 튜닝을 할 때 시간이 오래걸렸습니다. 실제로 현업시에는 이보다 더 많은 데이터를 다루게 된다고 합니다. 그래서 모델링 등을 할 때 항상 신중하게 데이터를 확인하는 사전과정을 거쳐야 할 것 같습니다. 이상입니다!
부족한 글 읽어주셔서 감사합니다:) 피드백은 언제나 환영입니다:)
