
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 13번째 미니 프로젝트에서는 Fraud Dectection System (이하 FDS)의 전체적인 프로세스를 실습해보았습니다.
금융기업에서 이상거래 탐지는 매우 중요한 문제로, 다양한 금융사기에 대한 사전/사후 대응을 지원하는 시스템 구축이 중요합니다. 이상거래 탐지를 하는 기법은 아래와 같습니다.
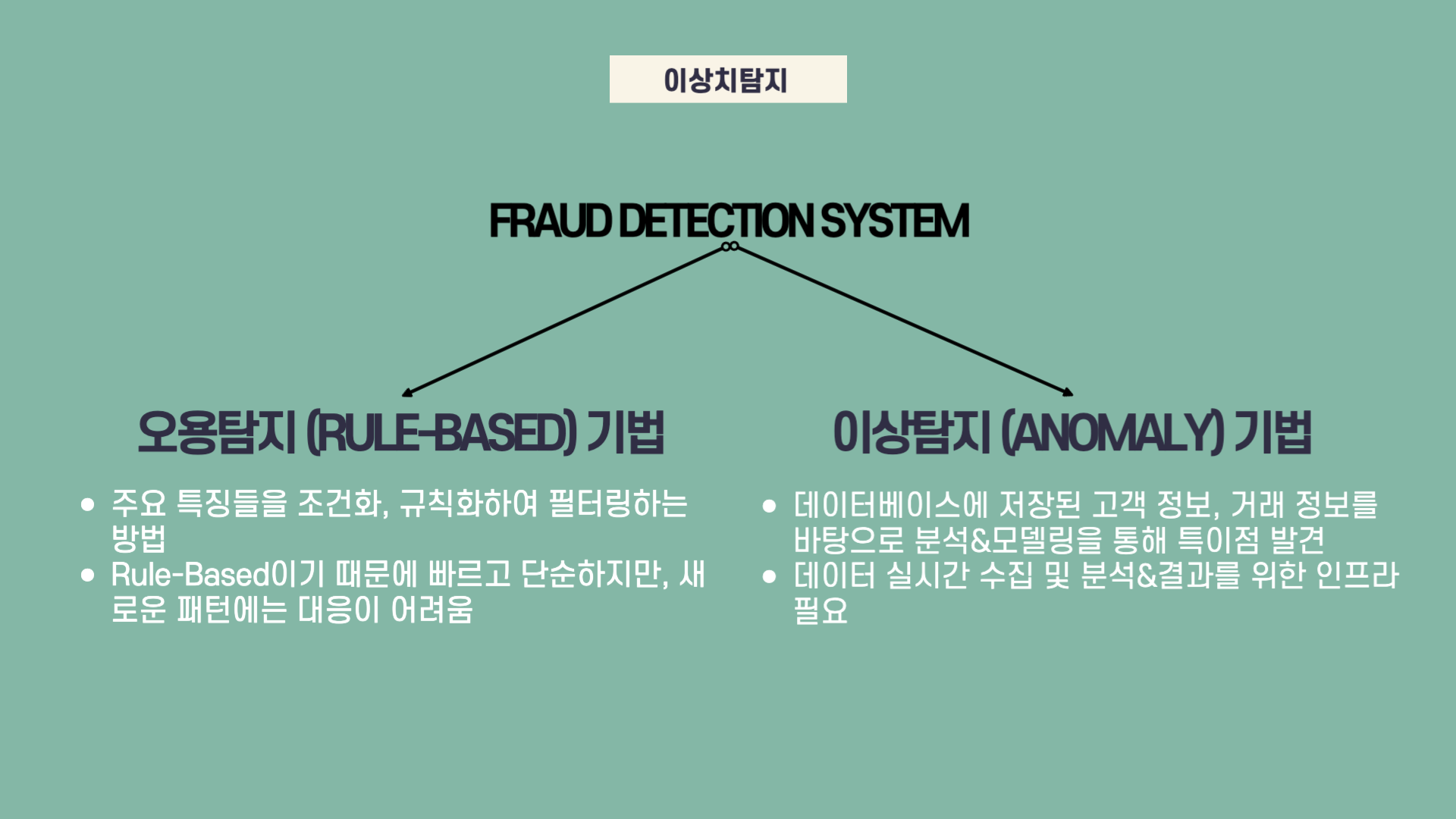
오용탐지 기법은 기존 이상 거래 혹은 사기거래에서 나타나는 주요 특징들을 조건화, 규칙화 (Rule) 하여 금융거래에 적용&필터링 하는 방법입니다. 예시로, 특정 고객이 거래하던 월 평균 금액보다 일정이상 큰 금액이 잘 거래되지 않았던 새벽에 한 번도 거래되지 않았던 계좌로 이체되는 경우 경고 메세지가 전달됩니다. 하지만 Rule을 정해놓았기 때문에 빠르고 단순한 구조일이지라도 새로운 패턴에는 대응이 어렵다는 단점이 있습니다.
이상탐지 기법은 데이터베이스에 저장된 고객들의 개인정보 (정적인 변수), 거래 정보 (동적인 변수)를 분석 및 모델링하여 특이점을 발견해내는 기법입니다. 다수의 정상 거래를 학습하여 decision boundary를 형성하면 boundary 밖에 있는 거래를 이상 거래로 탐지하는 기법입니다. 해당 기법은 오용탐지 기법과 달리 새로운 패턴을 식별할 수 있다는 장점이 있습니다. 하지만 실시간으로 서비스를 하고자 한다면 고성능 시스템은 필수입니다.
이번 미니 프로젝트에서는 이상탐지 기법을 수행했습니다. 보안상의 문제로 마스킹된 Feature들을 사용했지만, 3가지 모델(AutoEncoder, LOF, IF)를 활용하여 이상탐지 거래 시스템을 경험해볼 수 있는 시간이었습니다.
그렇다면 해당 미니 프로젝트를 어떻게 진행했는지 전체적인 진행과정을 소개해드리겠습니다.
02. 미니 프로젝트 진행과정
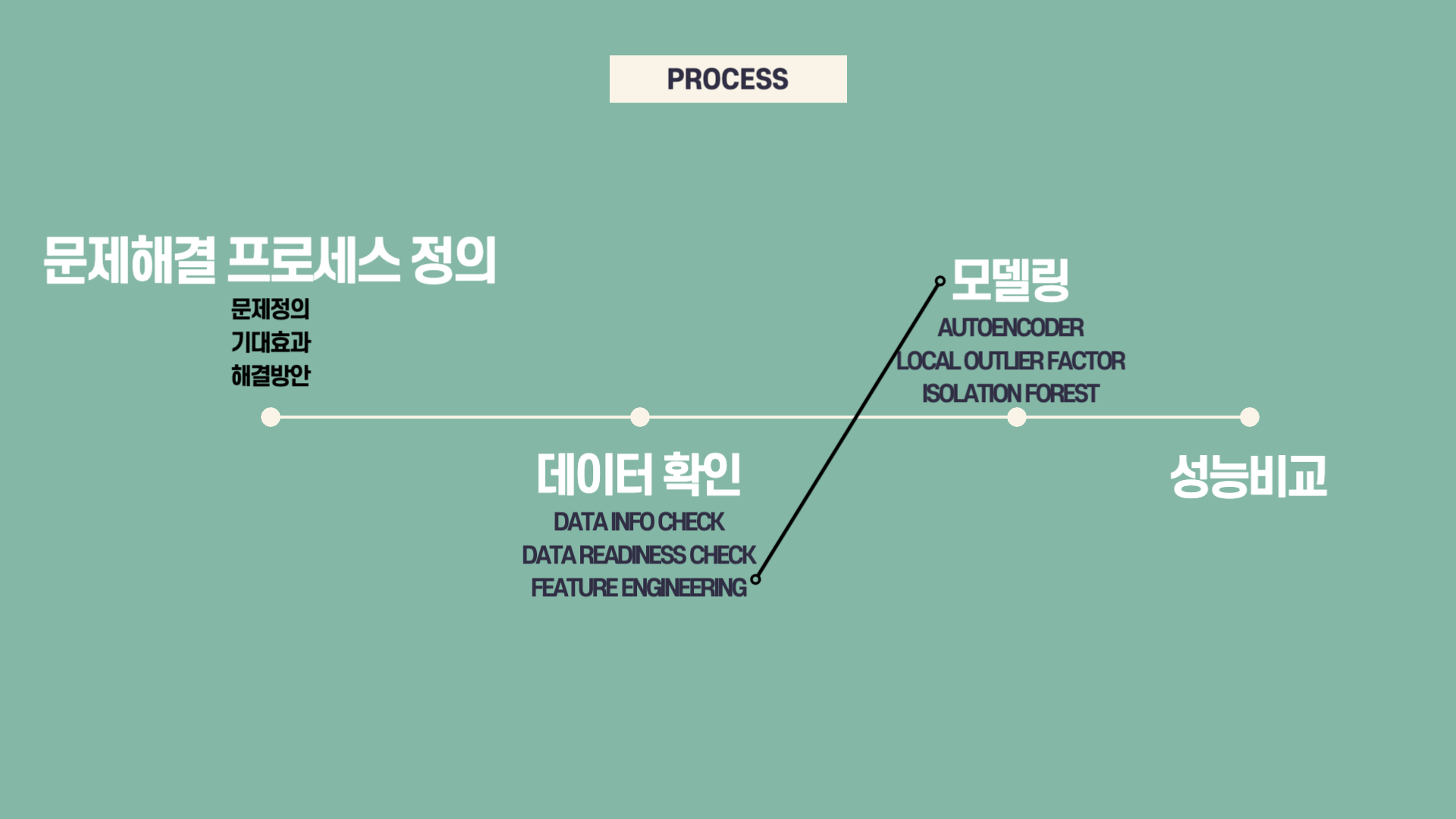
이번 미니 프로젝트의 전체적인 진행과정은 많이 복잡하지 않았습니다. 사용했던 변수의 숫자가 적고 (4개) 마스킹 되어있다보니 Data Info Check, Data Readiness Check 과정이 많이 줄었습니다.
또한, 이번에 새롭게 배운 내용으로 Feature Engineering과 Modeling을 합쳐 Feature Extraction 하는 방법을 배웠는데, 두가지 과정이 합쳐져 진행을 한 과정이 축소되었습니다.
마지막으로는 사용한 3가지 모델을 시각화하여 분석하며 마무리했습니다.
그렇다면 전체 프로세스의 시작단계인 문제해결 프로세스 정의 과정부터 조금 더 자세히 설명드리겠습니다.
03. 문제해결 프로세스 정의
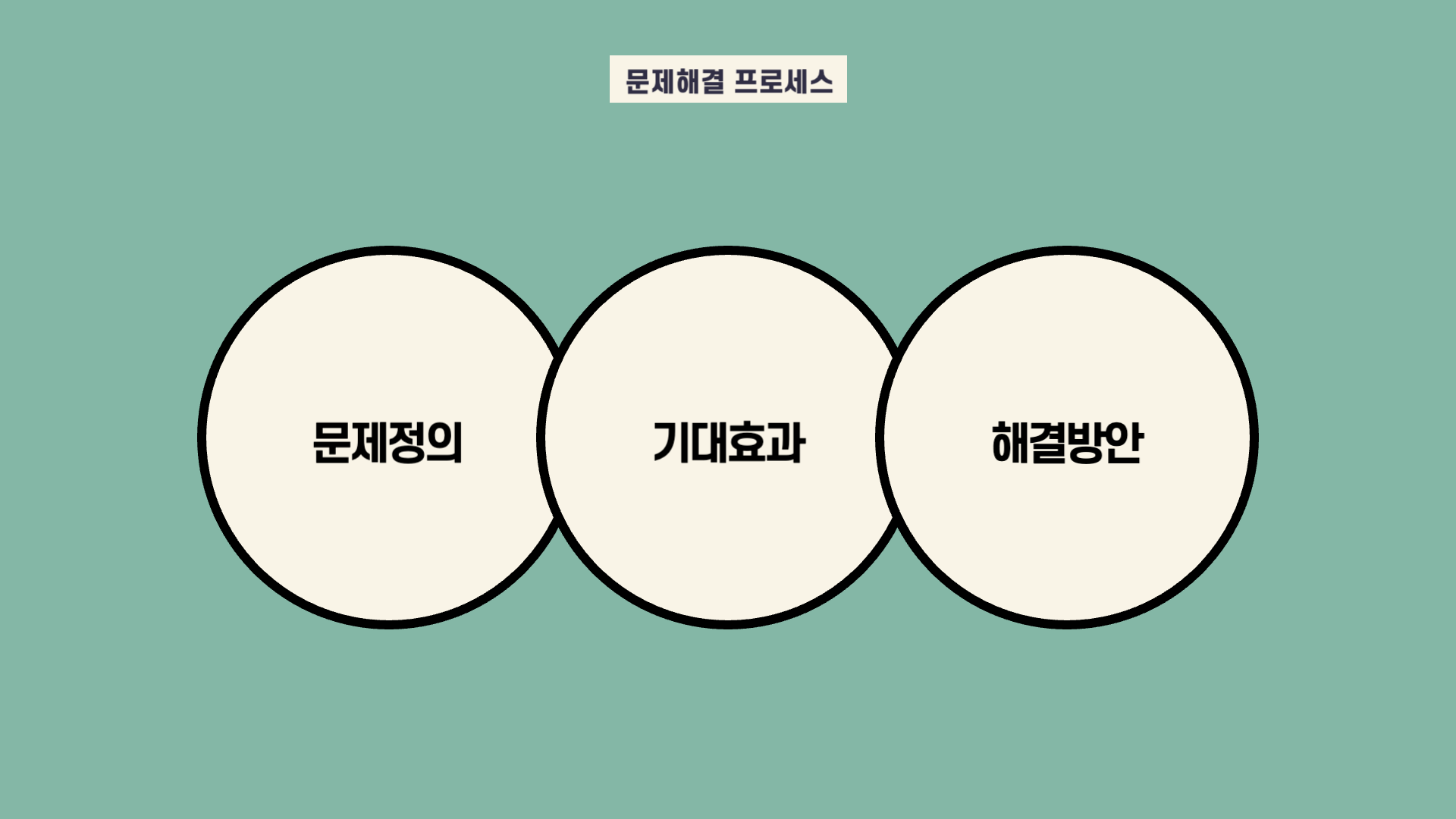
먼저 이번 미니 프로젝트에서 해결하고자 하는 문제는 처음부분에서 나왔던 이상거래 탐지입니다.
해당 문제를 해결하여 얻을 수 있는 기대효과는 금융 기업들에게 가장 중요한 고객들의 피해상황을 막을 수 있다는 것에 있습니다. 이상거래를 잘 찾아 사전에 방지하거나 혹은 사후 처리를 잘해내는 기업은 브랜드 이미지의 상승을 기대할 수 있습니다. 또한 해당 장점을 안전 마케팅으로 홍보하면 더 많은 고객들의 유입도 기대할 수 있습니다.
해결방안으로는 고객들의 정보 및 거래 정보 (비록 이번 미니프로젝트에서 활용한 변수들은 마스킹되어있지만)를 활용하여 Anomaly Detection에 활용되는 모델 3개로 모델링을 진행할 것입니다.
04. 데이터 확인
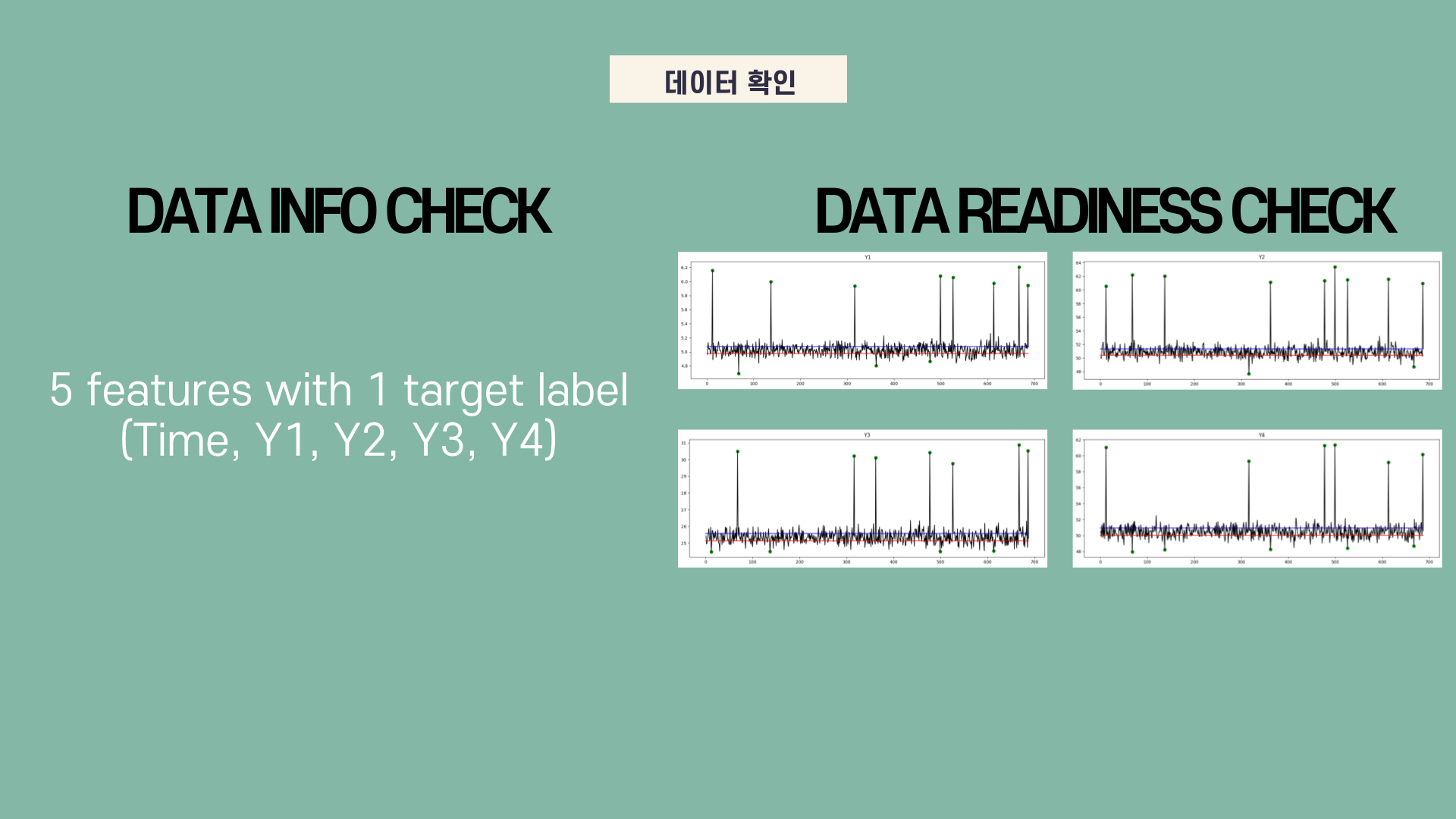
간단하게 데이터 정보를 확인하면, 이번에 사용된 변수는 (마스킹된) 5가지 변수입니다. Feature에 시간정보가 들어가 있기 때문에 나중에 훈련 데이터와 검증 데이터를 나눌 때 shuffle을 하지 않고 나누었습니다.
다음으로 변수에 따라 이상 거래 (target label = 1)가 어떻게 구분되었는지 보기 위해 matplotlib.pyplot.plot을 활용하여 데이터를 시각화했습니다.
05. Feature Engineering & Modeling
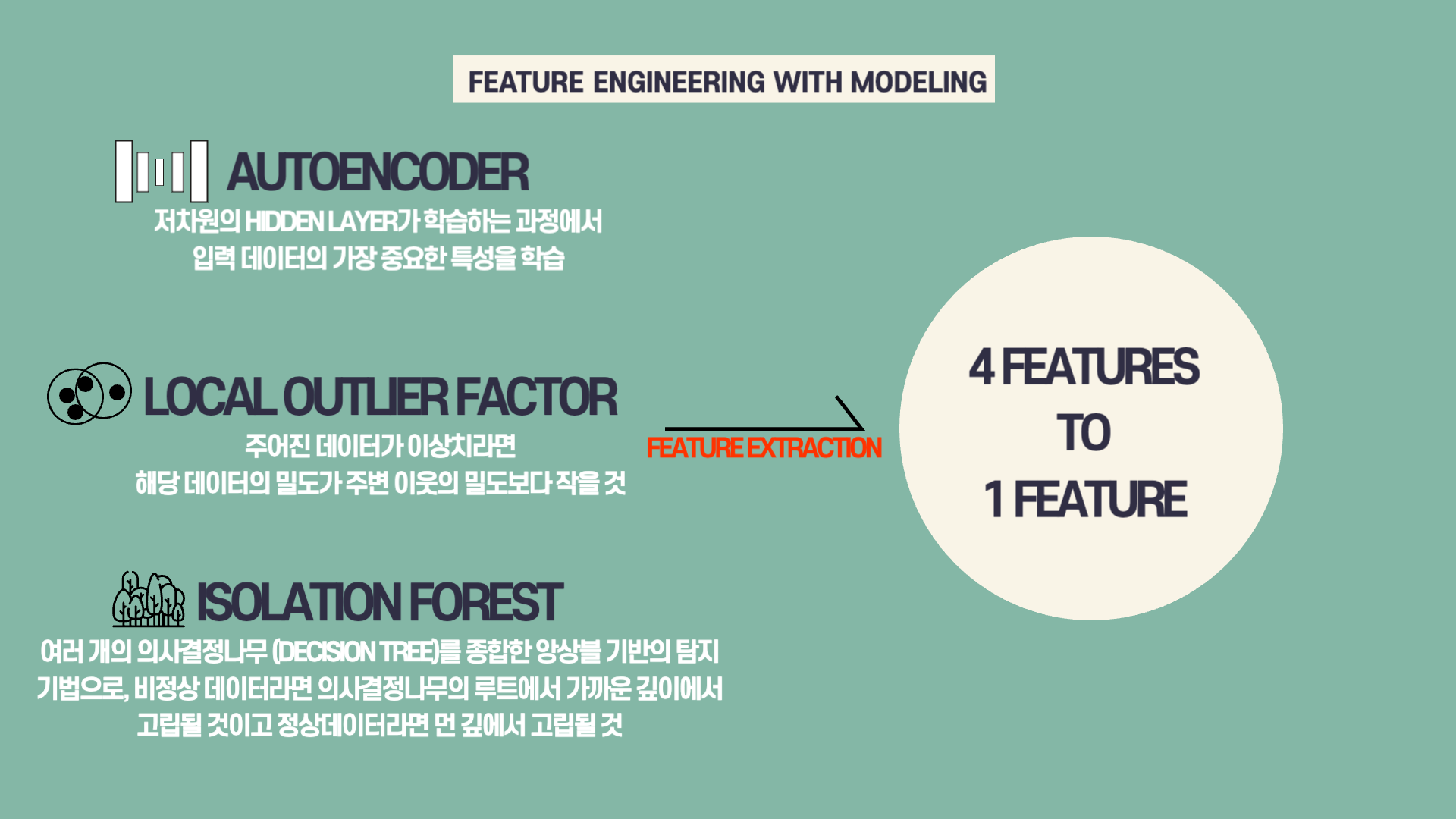
이번 미니 프로젝트에서 어떻게 보면 가장 중요했던 부분은 Feature Extraction을 위해 Featrure Engineering과 Modeling을 함께 진행한 부분이었습니다.
먼저 이번 미니 프로젝트에서 Feature Extraction을 한 이유는 데이터의 사이즈를 줄일 수 있도록 도와주기 때문입니다. 물론 이번 미니 프로젝트에서 사용된 변수의 경우 4가지 밖에 되지 않아 데이터의 사이즈를 줄이는 것은 필요가 있지 않았을 것입니다. 하지만 현업에서는 매우 많은 행과 더불어 정말 많은 (이전 미니 프로젝트에서 300개가 넘는 feature가 있었던 것처럼) feature들이 있는 경우가 많기에, 해당 가공 과정은 제가 향후에 일을 할 때 필요한 기법이었습니다.
Feature Extraction을 수행할 때 3가지 모델을 사용했습니다. 첫번째로 AutoEncoder를 사용했는데, 해당 모델은 딥러닝에서 입력 데이터를 최대한 압축하여 가장 의미있는 데이터를 뽑는 과정입니다. 실습을 할 때는 간단하게 4개 (가지고 있는 변수 개수)의 뉴런 갯수를 가진 레이어를 시작으로 2개, 1개 (latent vector)로 구성된 인코더를 만든 후, 다시 입력을 출력을 변환하는 디코더를 만들었습니다. 그 다음 해당 모델을 학습을 시킨 뒤 인코더 부분만 가져와 사용했습니다.
두번째로 LOF (Local Outlier Factor)를 사용했습니다. 해당 모델은 이상치 데이터의 경우 다른 주변 이웃들의 데이터들보다 더 멀리 떨어져 있어 주변의 밀도가 작을 것이라는 아이디어에서 착안한 모델입니다. LOF 모델을 사용하여 fit, predict을 하게 되면 lof 점수가 나오는데, 해당 점수가 feature extraction을 위한 변수가 됩니다.
마지막으로 IF (Isolation Forest)를 통해 모델링을 했습니다. 해당 모델에서 이상치 데이터는 앙상블 기반으로 비정상 데이터라면 의사결정나무에서 가장 가까운 깊이에서 고립되는 노드 (데이터)입니다. IF 모델의 경우도 4개의 변수를 사용하여 fit, predict를 하면 점수가 나오는데, LOF와 마찬가지로 Feature Extraction된 변수로 활용이 가능합니다.
모델링에 사용된 데이터에는 687개의 데이터 중 11개의 이상 거래 데이터가 있었는데, 해당 모델들이 얼마나 잘 맞췄는지 확인해보겠습니다.
06. Model Evaluation
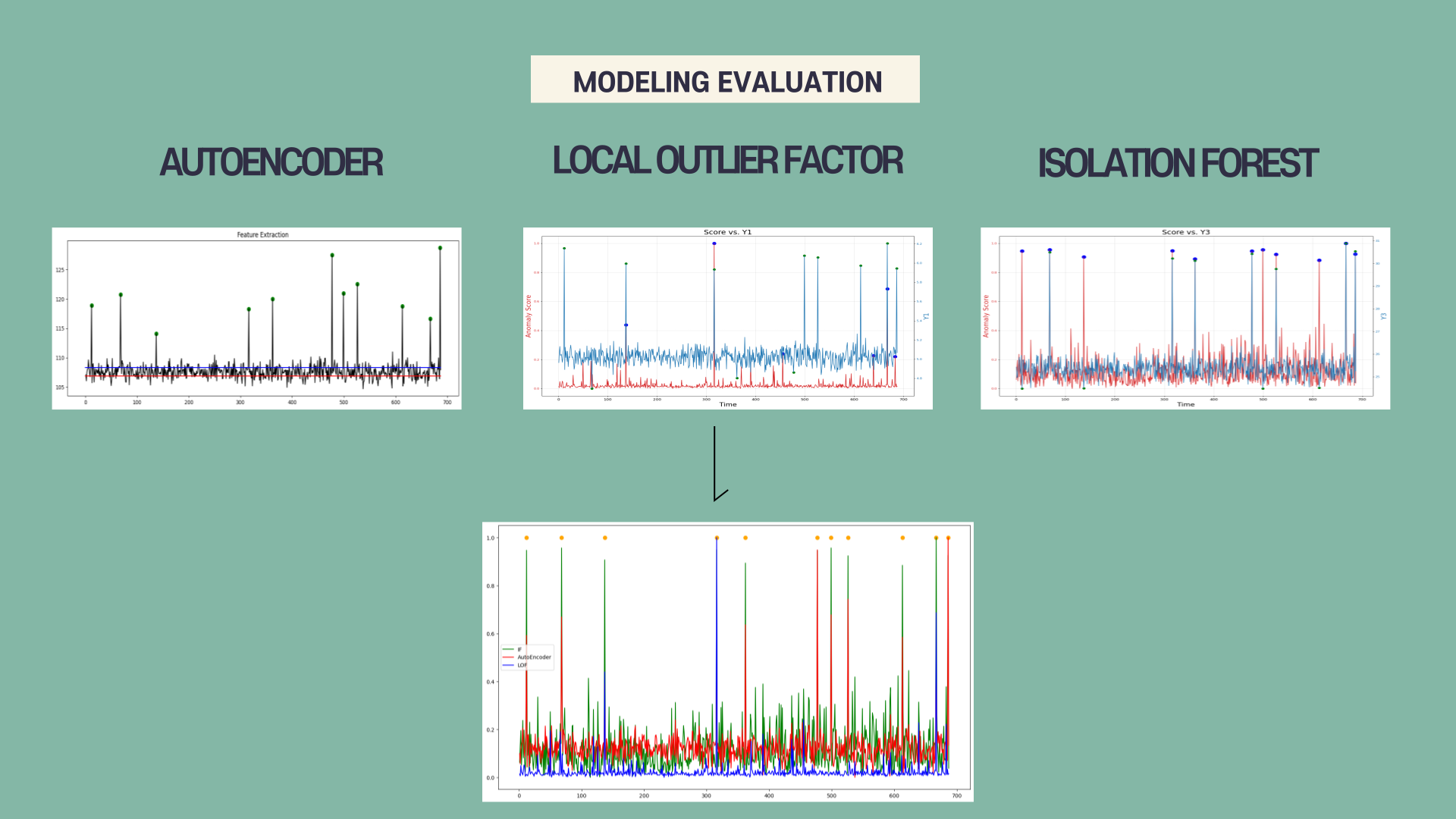
3개 모델 총평을 하면, AutoEncoder의 경우 11개의 이상치 값을 모두 잡아냈습니다. IF 모델 또한 11개의 이상치 값을 모두 잡아냈지만, LOF 모델은 6개의 이상치 값을 잡아내지 못했습니다. 해당 데이터 분포는 AutoEncoder와 IF를 사용하기에는 적합했지만 LOF를 사용하기에는 적합하지 않은 데이터임을 알 수 있었습니다.
LOF의 경우 (맨 아래 그래프에서 파란색 선) 가장 안정적인 분산을 보여주기는 했으나 해당 데이터의 이상치를 잘 잡아내기는 어려웠던 것으로 보입니다.
07. 마무리하며
이번 시간에는 이전에 배웠던 이상치 탐지 알고리즘을 직접 데이터에 적용해보는 시간이었습니다. 이상치 탐지의 경우 부서가 따로 있을 정도로 매우 중요한 태스크를 담당하고 있다는 것을 들었습니다. 제가 나중에 그 부서에 들어가지 않는다면 잘 사용하지 않을 수도 있겠지만, 제가 이후에 일할 분야에서도 사용할 수 있는 가능성이 있기에 다시 한번 복습하는 시간을 가져야 될 것 같습니다.
많이 부족하지만 읽어주신 분들께 감사드립니다. 피드백은 언제나 환영입니다:)
