
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 14번째 미니 프로젝트에서는 반도체 공정 분석을 실습해보았습니다. 반도체 공정에는 크게보면 4가지, 작게보면 8가지 단계로 진행이 됩니다. 그 중에서 크게 보았을 때 2번째인 Etching/CLN 단계를 분석에 집중했습니다.
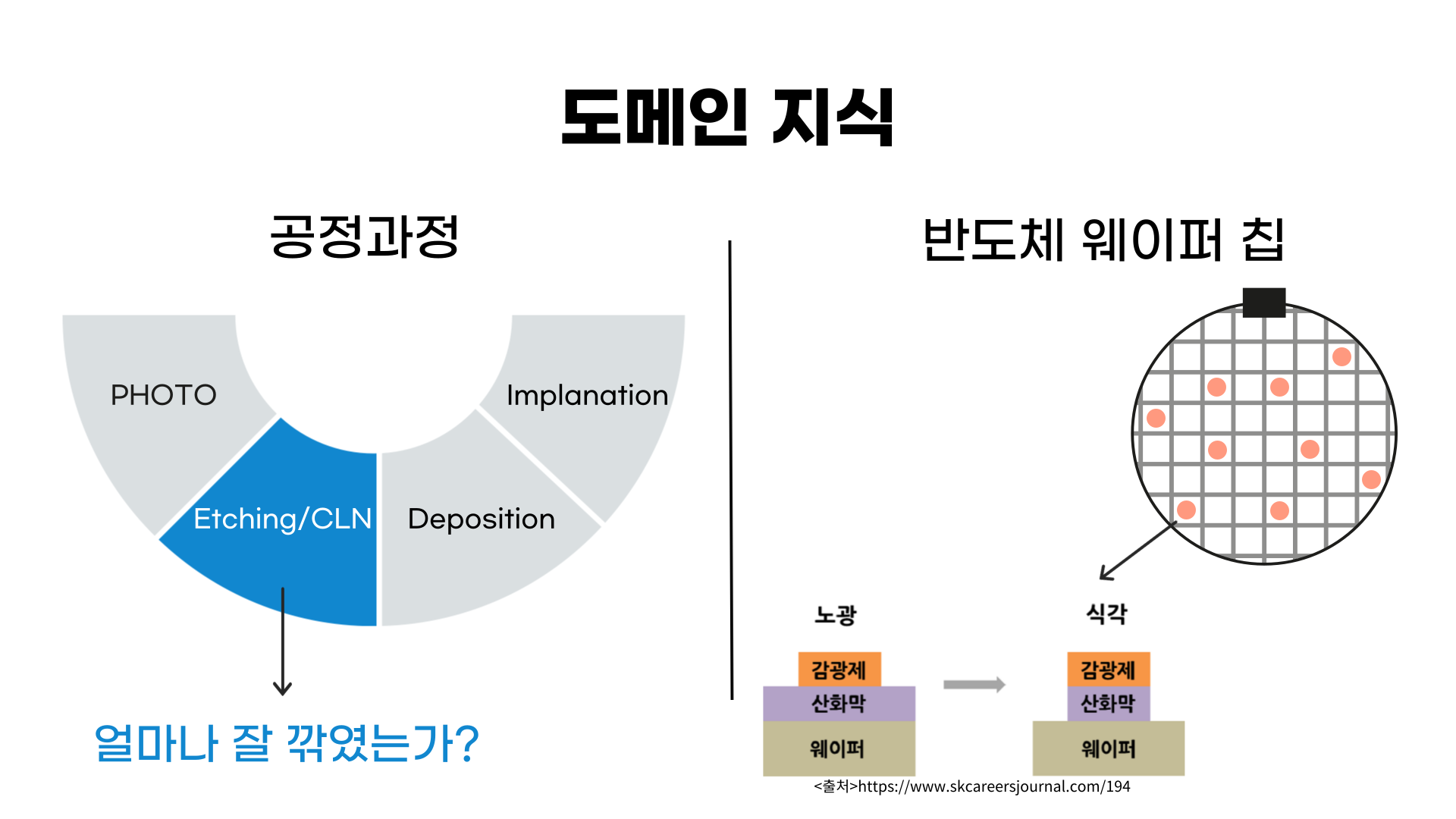
2번째 단계를 한마디로 표현하면 얼마나 잘 깎였는가?입니다. 오른쪽에 있는 이미지가 웨이퍼에 해당하는데, 식각을 통하여 필요한 부분만 남기고 불필요한 부분은 깎아냅니다.
반도체 산업 특성상 굉장히 미세한 마이크로 단위의 공정이기 때문에 품질을 계측하는데 시간과 비용이 많이 소요된다고 합니다. 그리고 웨이퍼 하나에 여러개의 칩이 들어가 있어 모든 칩들의 품질을 계측하는데는 어려움이 있다고 합니다.
그래서 모든 칩을 다 검사할 수 없어, 주요 area의 칩만 검사하는데 이번 미니 프로젝트에서는 9개의 주요 area의 칩을 샘플링한 데이터로 분석을 진행했습니다.
이번 글의 목차는 다음과 같습니다.
- 프로젝트 진행과정
- 데이터 확인
- 모델링
- 해석
그럼 먼저 프로젝트 진행과정을 간략하게 설명드리겠습니다.
02. 프로젝트 진행과정
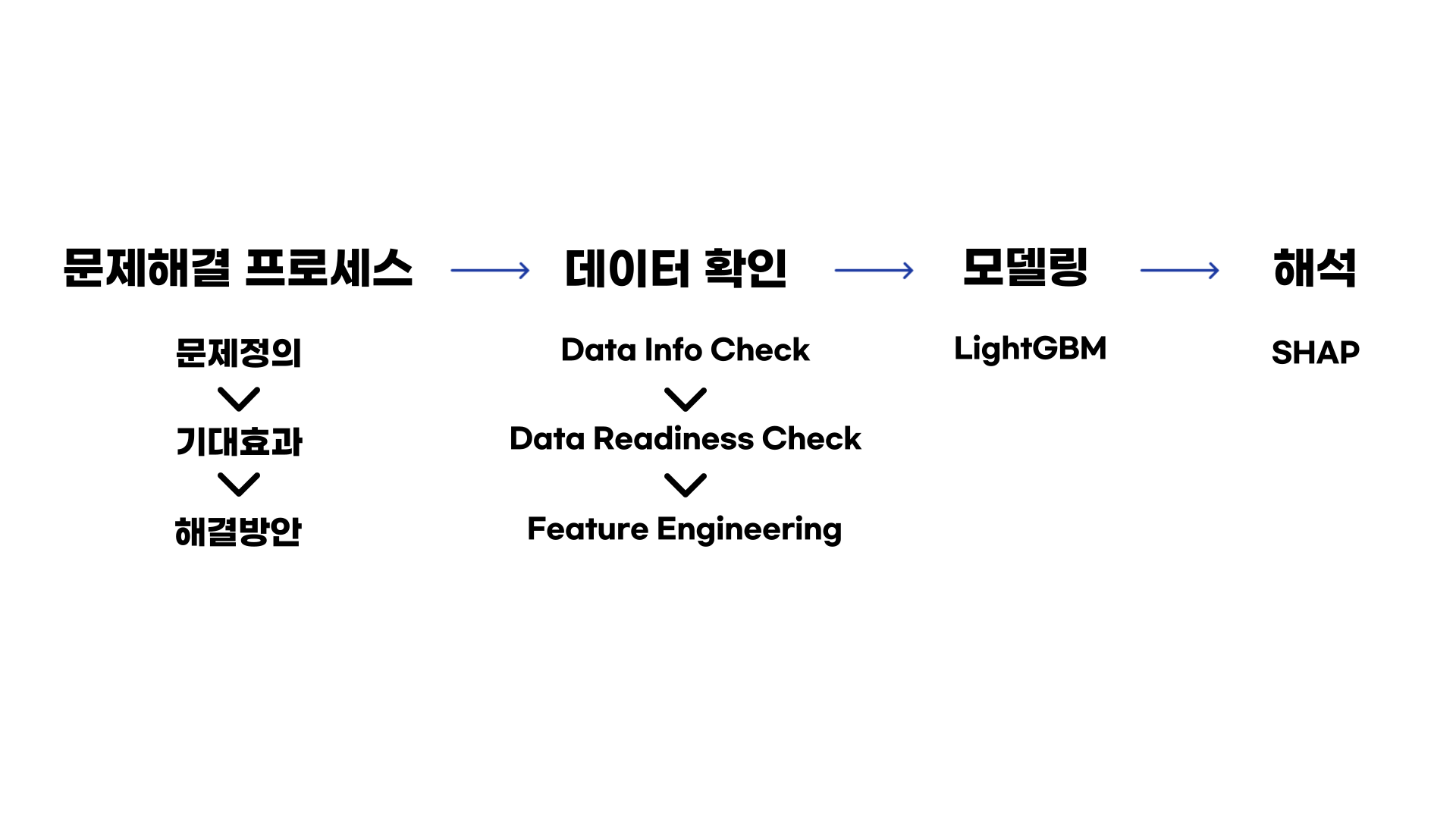
첫번째로 문제해결 프로세스를 정의했습니다. 풀고자 하는 문제가 무엇인지, 문제를 해결하여 얻는 기대효과는 무엇인지, 그리고 어떻게 문제를 해결할 것인지에 대한 해결방안으로 구성되어있습니다.
다음으로 데이터 확인 단계를 거쳤습니다. 제일 중요한 데이터를 확인하며 데이터의 형태, 타입 등을 확인했고 시각화를 하며 타겟 변수의 분포를 확인했습니다. 그 다음으로는 Feature Engineering 단계에서는 한개의 웨이퍼 칩당 주요 9개 area의 칩을 샘플링했기 때문에 타겟 변수가 한개가 아닌 9개의 타겟 변수가 생성됩니다. 그렇다면 9개의 타겟 변수 각각 모델을 따로 만들어야 할까요? 이렇게 되면 9개의 모델이 생겨 메모리를 많이 잡아먹게 되고 효율적이지 않게 됩니다. 그래서 9개의 타겟변수를 1개로 타겟변수로 만드는 작업을 진행했습니다.
세번째로 LightGBM 모델로 모델링을 하며 어떤 변수가 중요한 변수인지 Feature Importance를 뽑아냈습니다. 하지만 해당 Feature Importance 만으로는 모델 및 변수에 대한 해석이 부족했습니다.
그래서 마지막으로 SHAP 라이브러리를 통해 모델을 해석하면 미니 프로젝트를 마무리지었습니다.
그럼 각각 단계를 어떻게 진행했는지 조금 더 자세히 설명드리겠습니다.
03. 문제해결 프로세스 정의
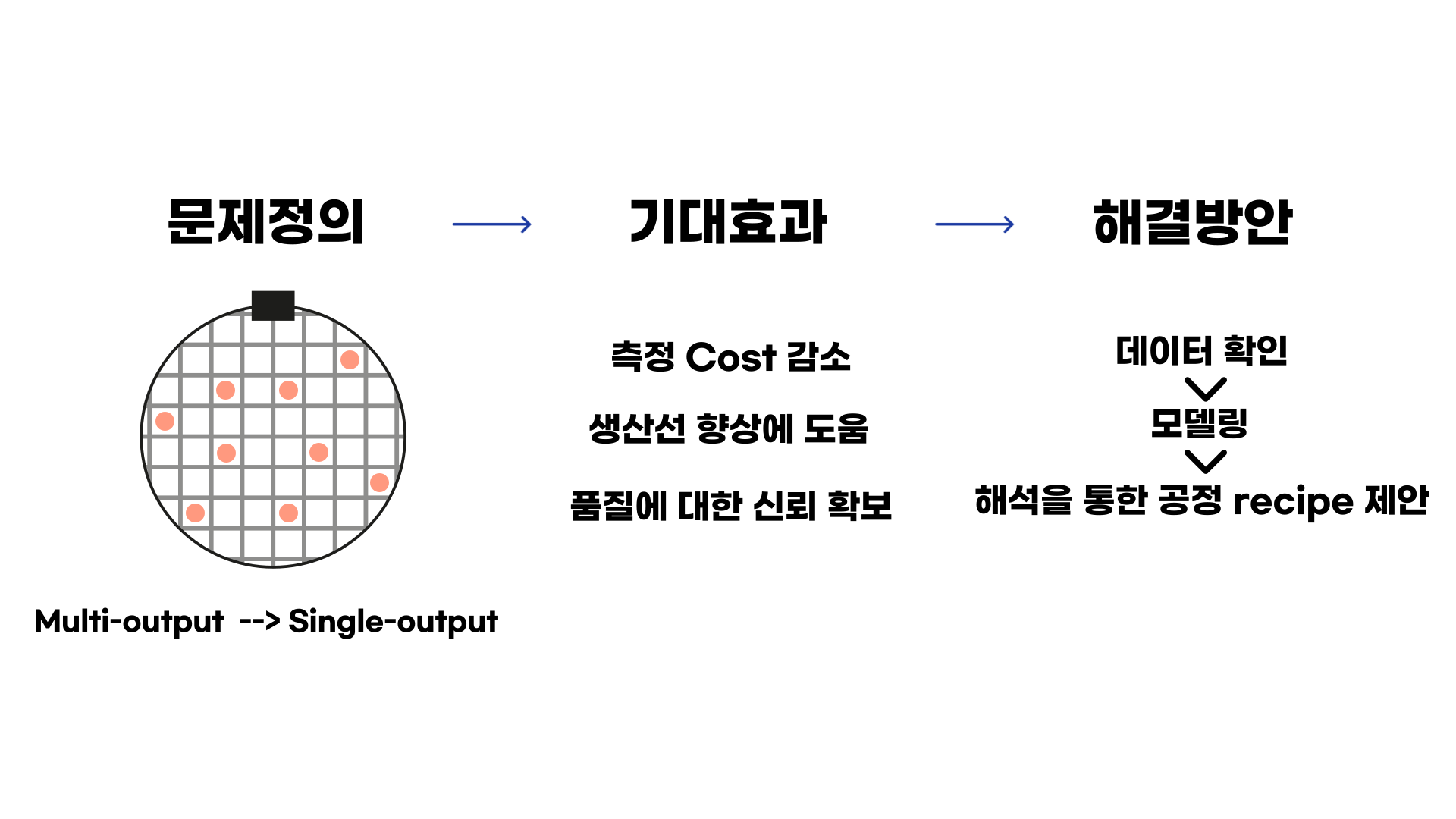
웨이퍼 칩을 생산하며 생기는 문제는 위에서 말씀드렸듯 품질계측에 상당한 비용이 소요됩니다. 웨이퍼를 물리적으로 측정하는 것은 여의도에서 500원짜리 동전 찾기와 같은 공수가 들어간다고 합니다. 그래서 물리적 측정을 수행하지 않고 제조 장비에 부착되어 있는 센서데이터에서 수집된 데이터를 설명변수로, 웨이퍼 칩들의 계측 값을 반응변수로 하여 분석을 진행했습니다.
하지만 하나의 웨이퍼에도 정말 많은 칩들이 들어가기 때문에 모든 칩들을 다 계측할 수는 없다는 것입니다. 그래서 주요 9개 area의 칩들의 계측값들만 가져왔습니다. 하지만, 이러한 9개의 계측값들을 종합하면 multi-output 분석을 해야합니다. 9개의 레이블을 따로따로 모델링을 하여 서비스를 하면 메모리를 많이 잡아먹기 때문에 single-output 문제로 변환하여 분석이 필요했습니다. (프로젝트 진행과정에서 설명드렸듯 해당 부분은 feature engineering에서 더 자세히 다루도록 하겠습니다.)
해당 문제를 해결하여 얻는 기대효과는 당연하게도 계측 비용의 감소입니다. 물리적 측정을 하지 않고 데이터 분석을 통해 진행을 하니 그 비용은 획기적으로 줄어들 것입니다. 또한 생산성 향상에 도움을 줄 수 있습니다. Etching 과정에서의 품질 안정성을 확보한다면 다음 공정에서의 안정성에 기여를 할 수 있기 때문입니다. 이후 전체적인 품질에 대한 신뢰까지 확보할 수 있을 것입니다.
해결방안으로는 먼저 수집된 데이터를 확인하고 모델링하며 가장 중요한 해석을 통해 공정 recipe (기법)에 대한 제안을 통해 더 나은 품질의 칩을 생산하는데 기여할 수 있을 것입니다.
04. 데이터 확인
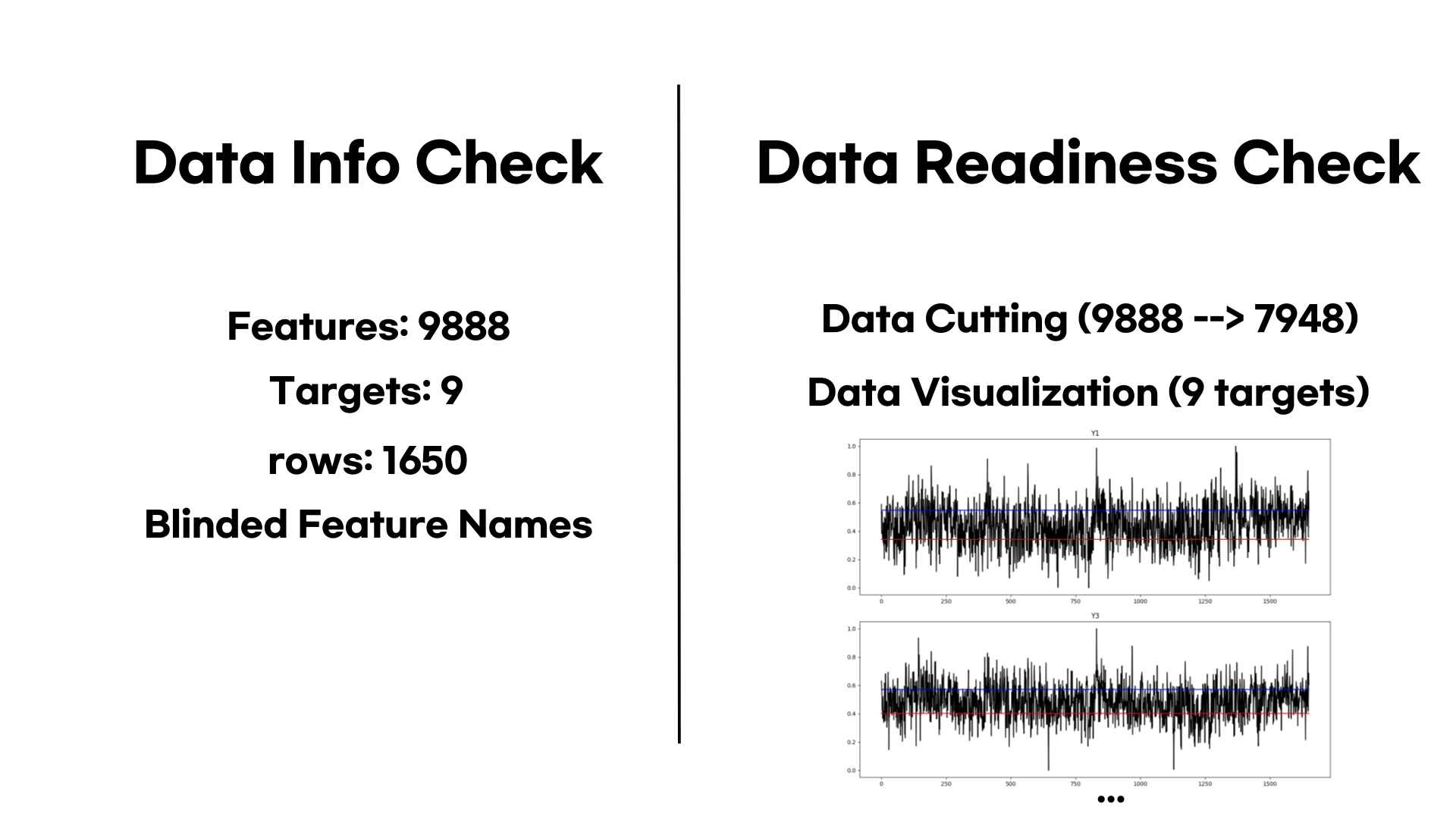
수집된 데이터의 형태의 경우 (1650, 9888)이었습니다. 정말 많은 변수가 있었습니다. 그리고 보안상의 문제로 변수들은 블라인드 처리가 되어있었습니다. 그리고 9개의 칩에서 계측값들을 받아왔기 때문에 9개의 타겟값이 있음을 확인했습니다.
Data Readiness Check 단계에서는 먼저 많은 변수들중 필요없는 변수 제거를 해주었습니다. np.unique를 활용하여 유니크한 값이 1이하인 값들은 모두 제거해주었습니다. 해당 변수들은 분석에 의미가 없고 메모리만 잡아먹기 때문입니다. 그리고 9개의 Y값들의 분포를 시각화하며 대략적인 분포를 확인했습니다.
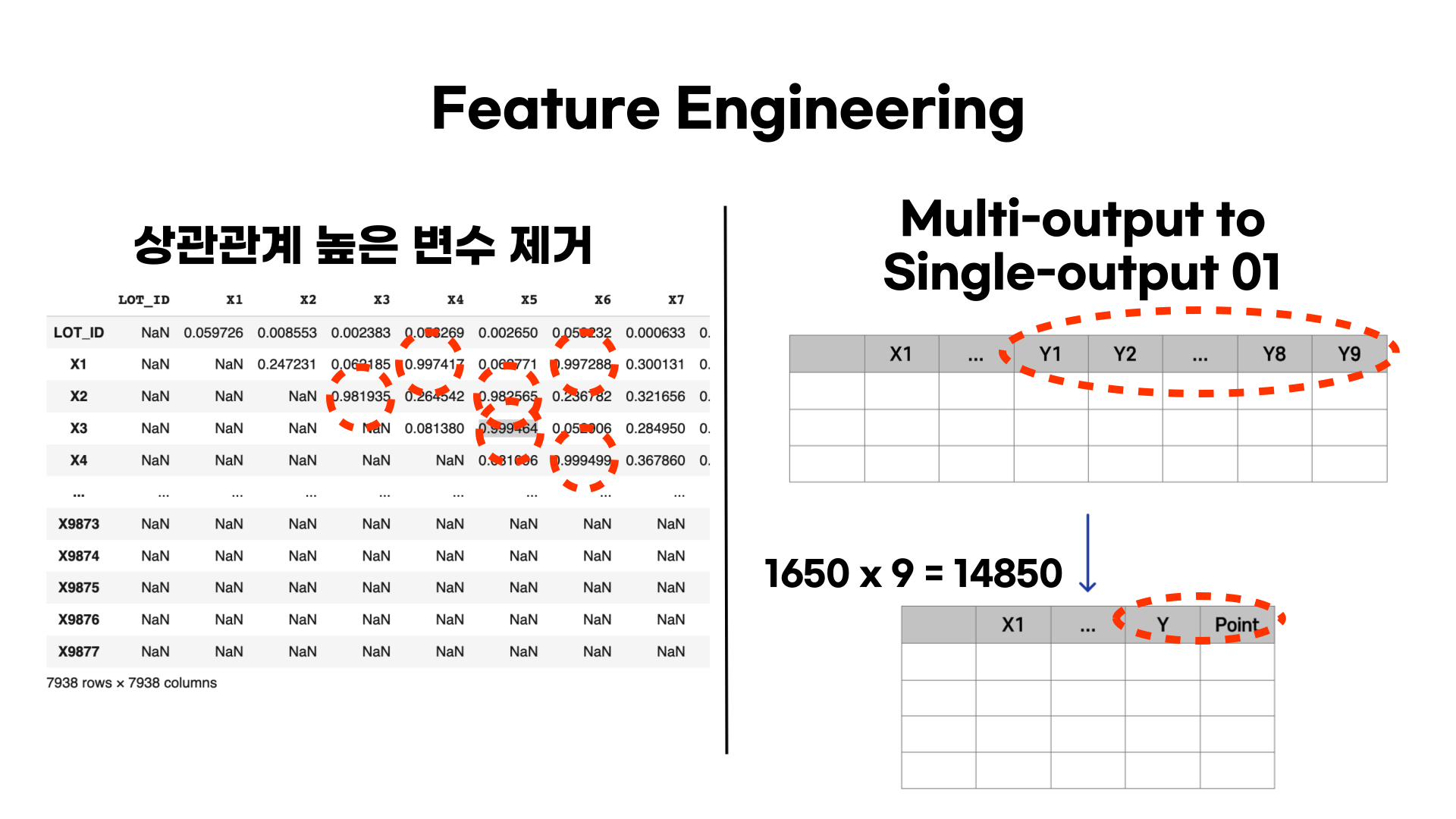
다음으로 Feature Engineering을 진행했습니다.
여전히 많은 변수 (7948) 들이 존재했기 때문에, 상관관계를 확인하여 다중공선성이 높다고 판단되는 (0.9이상) 변수들은 제거했습니다.
그리고 9개의 타켓변수를 1개의 타겟변수로 줄여주는 작업을 진행했습니다. 먼저 기존 변수들의 열과 타겟 Y 하나씩의 열을 따로 떼서 각각 1650개 행의 데이터를 만들었습니다. 그러면 각각의 Y에 따라 1650개 행을 가지는 데이터 프레임이 생기는데, 이 데이터 프레임들을 pd.concat을 통해 모두 합쳐주었습니다. 그렇게 되면 1650 x 9 = 14850 행의 데이터가 생깁니다. 하지만 모든 데이터를 합쳐준뒤 타겟변수를 Y로 통일했기 때문에 각각의 행이 어떤 Y 타겟을 나타내는지 알 수 없게 됩니다. 그래서 'Point'라는 변수를 통해 각각을 구분할 수 있도록 했습니다. (Y1에서 온 행들이라면 Point는 1입니다.)
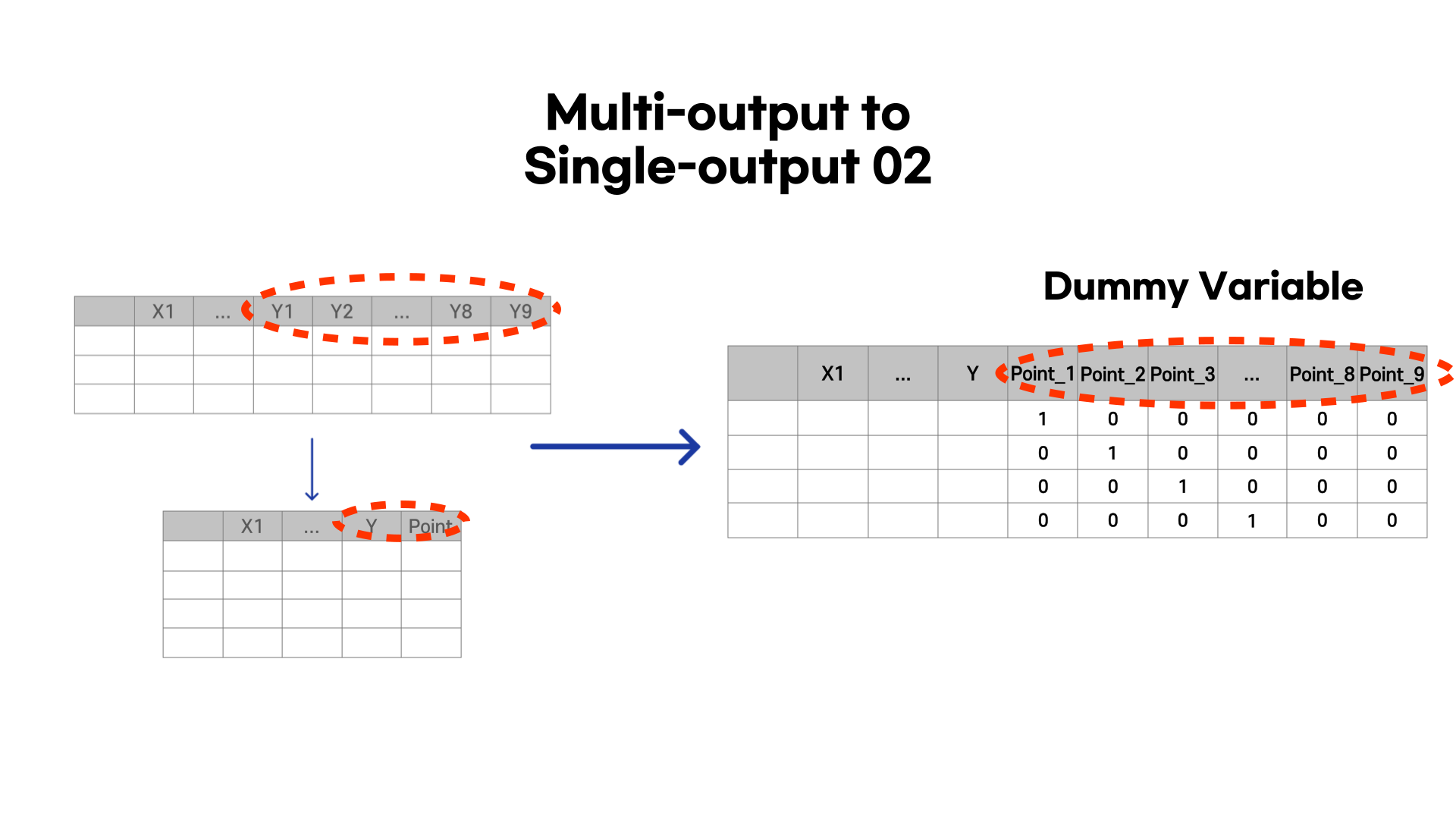
하지만 해당 'Point' 컬럼을 변수로 사용할 수 없습니다. 왜냐하면 'Point' 컬럼은 단지 행들이 어떤 Y 타겟에서 왔는지 단순히 구분지어주는 역할을 하는데, 모델은 이를 순서가 있는 변수로 받아들일 수 있기 때문입니다. 그래서 pd.get_dummies를 통해 더미 변수로 만들어주었습니다 (원핫인코딩).
그러면 이제 모델링을 할 준비가 되었습니다!
05. 모델링
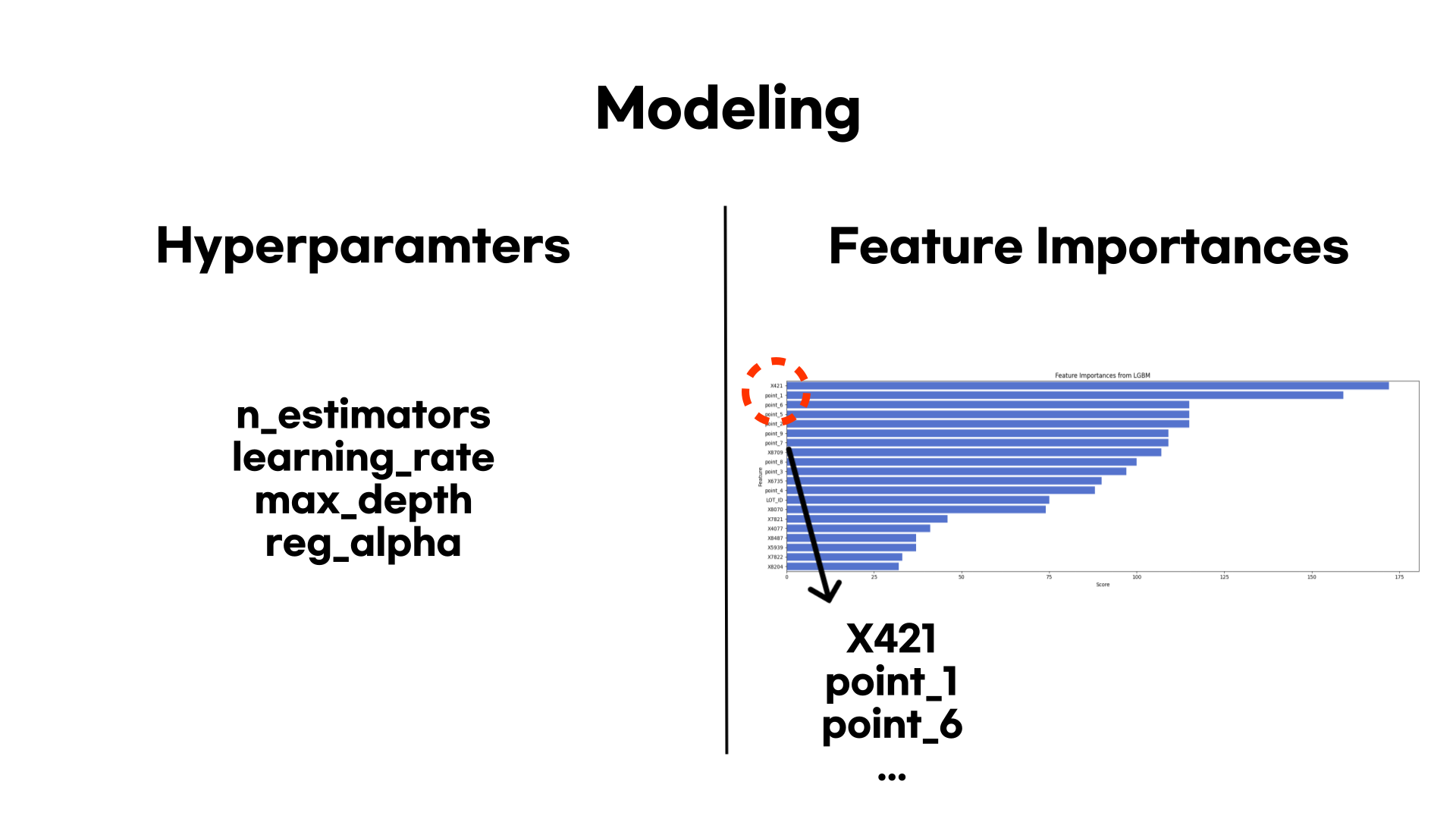
여러 다른 모델들이 있었지만, 빠르게 돌려볼 수 있는 LightGBM으로 모델링 실습을 진행했습니다. 하이퍼파라미터 조정을 하며 모델링을 한 결과 test 데이터에 대해서 r2 score가 0.7759가 나오는 모델이 베스트 모델이었습니다.
다음으로 해당 모델을 통해 Feature Importance를 시각화했습니다. 상위 20개의 중요 변수를 뽑았을 때 dummy variable로 만든 'Point' 변수들이 다수 포함되어있었습니다. 하지만 Feature Importance 만으로는 변수가 어떻게 영향을 끼치는지 등의 해석이 불가능합니다.
그래서 SHAP 라이브러리를 통해 변수들이 어떻게 Y에 영향을 끼치고 있는지 분석해보았습니다.
06. 해석
왼쪽은 SHAP의 summary_plot으로 전체 모델에 대한 중요한 변수 순서대로 나열이 되었습니다. 해당 순서는 LightGBM 모델의 Feature Importance와 조금씩 달랐습니다.
가장 중요한 변수로 선정된 'Point_2'를 보면 값이 높을 수록 예측값이 커지고 (식각된, 잘린 부분이 커지고) 이고 값이 낮아질수록 예측값이 작아진다는 (식각된, 잘린 부분이 작아진다는) 것을 알 수 있습니다. 하지만 이전 미니 프로젝트에서 SHAP을 이용하여 해석한 방식으로 해당 모델을 해석하면 안될 것입니다.
'Point_2'의 경우 값이 1,0 밖에 없습니다 (dummy variable)이기 때문입니다. 그렇다면 'Point_2' area에서 생산되는 칩들은 잘린 부분이 크다는 뜻이고 그렇지 않은 부분들은 잘린 부분이 작다는 것을 짐작해볼 수 있습니다. 하지만 식각 과정을 통해 잘리는 부분은 일정해야 합니다. 즉, 어떤 변수에 따라 잘린 부분들의 분산이 평균에 더 가깝게 모이지 않는다면 해당 칩의 품질을 보장할 수 없을 것입니다. 다른 말로 최대한 일정하게 잘려야 하는 식각 과정이 변수에 따라 크거나 작게 되면 안정된 품질의 칩을 생산할 수 없는 것입니다!
때문에 이전 미니 프로젝트에서 SHAP을 통해 해석할 때는, '어떤 변수가 변할 때 Y값은 ~ 변하는 구나'라고 할 수 있지만, 해당 미니 프로젝트에서는 최대한 변화폭이 좁아야 좋은 결론을 낼 수 있습니다. 따라서 현재 데이터로 봤을 때 식각 과정은 좋지 않은 결과를 내고 있습니다.
때문에 상위에 랭크되어있는 변수들은 미세하고 섬세하게 관리하여 분산이 최대한 평균에 가까워지도록 관리해주어야 합니다. 그래서 공정 recipe를 제안할 때는 해당 변수들을 어떻게 관리해주어야 하는지 알려주는 것이 좋을 것입니다.
다음으로 Point별로는 어떤 변수들이 중요한지 알아보기 위해 Point별로 나누었습니다. 위 이미지는 그중에서 2번째 area (Point_2)에서 나온 값으로 시각화를 했습니다. Point 2 위치는 X6735 등의 변수들의 변화에 따라 잘린 부위의 크기가 많이 변화하는 것을 알 수 있습니다. 때문에 Point 2의 경우 해당 변수들을 조정하여 공정 기법을 바꾸는 것을 제안할 수 있습니다.
07. 마무리하며
이번 미니 프로젝트 실습을 진행하며 어려웠던 부분은 잘 몰랐던 부분의 도메인을 이해하는 것이었고 (구글링을 좀 했습니다..!) 그 다음으로는 SHAP을 해석하는 방식이 다르다는 것을 이해하는 것이었습니다.
또한 Feature Engineering 부분에서 multi-output을 single-output으로 변환하는 과정도 이전에는 본적이 없던 부분이었기 때문에 이해하는데 시간이 조금 걸렸습니다.
하지만 한번이 어렵지 두번은 어렵지 않..진 않겠지만 복습을 통해 나중에 비슷한 문제 마주했을 때 해당 분석 방법을 적용하여 문제를 해결하기를 희망합니다..!
부족하지만 읽어주신 분들께 감사드립니다:) 피드백은 언제나 환영입니다:)
